Elastic Time: Dynamic Frame Rate Bottlenecks for Neural Audio Coding
Pith reviewed 2026-06-26 02:06 UTC · model grok-4.3
The pith
Elastic Time adds a learned predictor to fixed-frame-rate audio autoencoders so they can skip and later reconstruct redundant frames at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
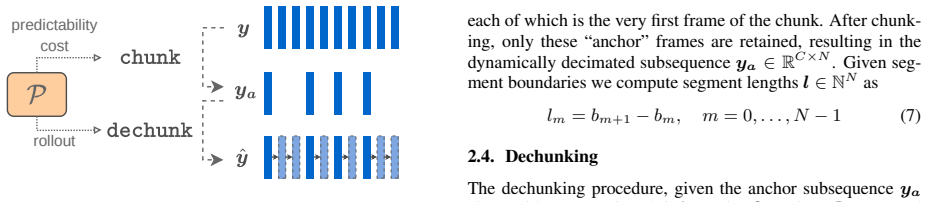
Elastic Time learns a lightweight latent predictor that identifies skippable frames; these frames are omitted from the transmitted sequence and reconstructed at the decoder, turning a fixed-frame-rate autoencoder into a dynamic one that supports greedy boundary selection and deployment-time rate control.
What carries the argument
Elastic Time: the lightweight latent predictor trained on the autoencoder representations that performs greedy selection of which frames to skip and reconstruct.
If this is right
- The same trained autoencoder can be run at multiple target rates simply by changing the predictor's decision threshold.
- Average latent sequence length decreases on signals with varying information density.
- Downstream generation and long-context models receive shorter inputs without retraining the autoencoder.
- Temporal resolution automatically adapts to local signal complexity.
Where Pith is reading between the lines
- The same predictor idea could be tested on video or speech autoencoders where frame redundancy also varies.
- Combining Elastic Time with existing variable-bitrate quantization might produce a fully variable-rate codec without architecture changes.
- The method supplies a concrete way to test whether learned skipping preserves perceptual quality better than uniform downsampling.
Load-bearing premise
A small predictor trained on the autoencoder latents can reliably flag frames whose absence will not cause unacceptable reconstruction error.
What would settle it
Measure reconstruction quality on held-out audio when the predictor is forced to skip the same average number of frames as a fixed-rate baseline; if quality drops significantly below the baseline the claim fails.
Figures
read the original abstract
Neural audio autoencoders have become a core component of compression, feature extraction, and generation. However, while existing systems support variable bitrate, the vast majority of models still operate at a fixed latent frame-rate, allocating equal temporal budget to regions with very different information density, which can result in unnecessarily long sequences. We introduce Elastic Time, a dynamic frame-rate bottleneck that converts fixed-frame-rate autoencoders to dynamic ones. Our method learns a lightweight latent predictor used to decide which frames can be skipped and later reconstructed, enabling efficient greedy boundary selection at inference. Experiments show our method enables deployment-time rate control while improving efficiency-quality tradeoffs relative to baselines. Overall, we provide a flexible mechanism for adjusting temporal resolution in audio autoencoders, potentially facilitating more efficient downstream modeling for generation and long-context tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce Elastic Time, a dynamic frame-rate bottleneck that converts fixed-frame-rate neural audio autoencoders to dynamic ones. It learns a lightweight latent predictor to identify skippable frames for later reconstruction, enabling efficient greedy boundary selection at inference and deployment-time rate control. Experiments demonstrate improved efficiency-quality tradeoffs relative to baselines across audio domains and bitrates.
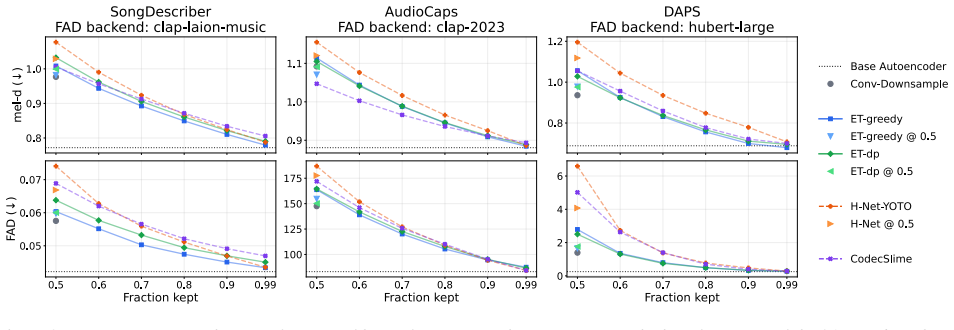
Significance. If the results hold, the approach supplies a flexible mechanism for adapting temporal resolution to information density in audio autoencoders. The manuscript supplies the architectural details, training procedure, and experimental comparisons that directly address the core assumption that a lightweight predictor can reliably identify skippable frames while preserving reconstruction quality; this is a concrete strength.
minor comments (3)
- [§3.2] §3.2: the training objective for the latent predictor is described only in prose; an explicit loss equation would clarify the weighting between reconstruction fidelity and skip decisions.
- [Table 2] Table 2: the bitrate ranges for the dynamic vs. fixed baselines are not aligned in the reported rows, making direct comparison of the efficiency-quality frontier harder to assess.
- [Figure 4] Figure 4: the caption does not state the audio domain or bitrate operating point for the example waveforms, reducing interpretability of the skipped-frame reconstructions.
Simulated Author's Rebuttal
We thank the referee for their positive summary, recognition of the method's significance, and recommendation of minor revision. No major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The paper introduces Elastic Time as an architectural extension to fixed-frame-rate autoencoders, using a trained lightweight latent predictor for frame skipping decisions. No derivation chain, equations, fitted parameters presented as predictions, or self-citation load-bearing steps appear in the abstract or description. The central claims rest on experimental validation of efficiency-quality tradeoffs rather than any self-referential reduction or ansatz smuggled via prior work. This matches the expected non-circular outcome for an empirical methods paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Elastic Time: Dynamic Frame Rate Bottlenecks for Neural Audio Coding
Introduction Advances in neural audio codecs and autoencoders have en- abled the compression of audio waveforms into compact latent codes, significantly improving storage and transmission effi- ciency while maintaining perceptual quality and content fidelity [1, 2, 3, 4, 5]. Beyond compression, these learned representa- tions have become a core layer for ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
anchor” frames, each of which is the very first frame of the chunk. After chunk- ing, only these “anchor
Proposed Method 2.1. Overview We assume a pretrained autoencoder with encoderA enc and decoderA dec, which maps a multichannel audio waveformx∈ RCaudio×L of lengthLto a latent sequence and reconstructs it back to audio z=A enc(x),z∈R C×T , ˆx=A dec(z).(1) More compression is achieved whenT≪L, but, in addition to that, our goal is to turn this fixed latent...
-
[3]
Experimental Setup In our experiments, we evaluate the reconstruction quality of our method across a range of operating points. We consider both greedy and DP-based chunking, and examine models trained at a fixed kept fractionρ(e.g.,ρ= 0.5) as well asscalable models trained over a distribution of kept fractions, e.g.,ρ∼ U(0.5,0.995). All models are implem...
-
[4]
In ad- dition, we trainET-dp-widerange, withρ∼ U(0.2,0.995)to test the impact of training for more aggressive compression
Results We evaluate four main Elastic Time (ET) variants: two greedy- based models, one trained at a fixed kept fractionρ= 0.5 (denotedET-greedy@0.5) and one trained over a rangeρ∼ U(0.5,0.995)(ET-greedy), and two DP-based models,ET- dp@0.5(ρ= 0.5) andET-dp(ρ∼ U(0.5,0.995)). In ad- dition, we trainET-dp-widerange, withρ∼ U(0.2,0.995)to test the impact of ...
-
[5]
Im- plemented as a Re-Bottleneck plug-in on top of a frozen pre- trained autoencoder, ET introduces a lightweight causal latent predictor for chunking and dechunking
Conclusion We presentedElastic Time(ET), a dynamic latent frame-rate mechanism for neural audio autoencoders that enables frame- rate scalable models via content-adaptive latent decimation. Im- plemented as a Re-Bottleneck plug-in on top of a frozen pre- trained autoencoder, ET introduces a lightweight causal latent predictor for chunking and dechunking. ...
-
[6]
Acknowledgments This work was supported by Electronics and Telecommunica- tions Research Institute (ETRI) grant funded by the Korean gov- ernment [26ZC1100, Development of Spatial Media Technol- ogy and Interaction Technology for Convergence of the Real and Virtual World]
-
[7]
Generative AI Use Disclosure ChatGPT was used as an editing tool during the preparation of this manuscript
-
[8]
High fidelity neural audio compression,
A. D ´efossez, J. Copet, G. Synnaeve, and Y . Adi, “High fidelity neural audio compression,”Transactions on Machine Learning Research, 2023
2023
-
[9]
Soundstream: An end-to-end neural audio codec,
N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasacchi, “Soundstream: An end-to-end neural audio codec,”IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 30, pp. 495–507, 2021
2021
-
[10]
High-fidelity audio compression with improved rvqgan,
R. Kumar, P. Seetharaman, A. Luebs, I. Kumar, and K. Kumar, “High-fidelity audio compression with improved rvqgan,”Proc. NeurIPS, vol. 36, pp. 27 980–27 993, 2023
2023
-
[11]
Spectrostream: A versatile neural codec for general audio,
Y . Li, K. Han, B. McWilliams, Z. Borsos, and M. Tagliasac- chi, “Spectrostream: A versatile neural codec for general audio,” arXiv preprint arXiv:2508.05207, 2025
-
[12]
Stable audio open,
Z. Evans, J. D. Parker, C. Carr, Z. Zukowski, J. Taylor, and J. Pons, “Stable audio open,” inProc. ICASSP. IEEE, 2025, pp. 1–5
2025
-
[13]
Audiolm: a language modeling approach to audio gener- ation,
Z. Borsos, R. Marinier, D. Vincent, E. Kharitonov, O. Pietquin, M. Sharifi, D. Roblek, O. Teboul, D. Grangier, M. Tagliasacchi et al., “Audiolm: a language modeling approach to audio gener- ation,”IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 31, pp. 2523–2533, 2023
2023
-
[14]
Audiogen: Tex- tually guided audio generation,
F. Kreuk, G. Synnaeve, A. Polyak, U. Singer, A. D ´efossez, J. Copet, D. Parikh, Y . Taigman, and Y . Adi, “Audiogen: Tex- tually guided audio generation,” inProc. ICLR, 2023
2023
-
[15]
Simple and controllable music gen- eration,
J. Copet, F. Kreuk, I. Gat, T. Remez, D. Kant, G. Synnaeve, Y . Adi, and A. D ´efossez, “Simple and controllable music gen- eration,” inProc. NeurIPS, 2023
2023
-
[16]
Moshi: a speech-text foundation model for real-time dialogue
A. D ´efossez, L. Mazar´e, M. Orsini, A. Royer, P. P´erez, H. J´egou, E. Grave, and N. Zeghidour, “Moshi: a speech-text foundation model for real-time dialogue,”arXiv preprint arXiv:2410.00037, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Soundstorm: Efficient parallel audio gen- eration,
Z. Borsos, M. Sharifi, D. Vincent, E. Kharitonov, N. Zeghidour, and M. Tagliasacchi, “Soundstorm: Efficient parallel audio gen- eration,”arXiv preprint arXiv:2305.09636, 2023
-
[18]
Back to ear: Perceptually driven high fidelity music reconstruction,
K. Wang, Z. Wu, D. Zhou, R. Lin, J. Dai, and T. Jiang, “Back to ear: Perceptually driven high fidelity music reconstruction,”arXiv preprint arXiv:2509.14912, 2025
-
[19]
Salad-vae: Semantic audio compression with language-audio distillation,
S. Braun, H. Gamper, and D. Emmanouilidou, “Salad-vae: Semantic audio compression with language-audio distillation,” arXiv preprint arXiv:2510.07592, 2025
-
[20]
EzAudio: Enhancing Text-to-Audio Generation with Efficient Diffusion Transformer,
J. Hai, Y . Xu, H. Zhang, C. Li, H. Wang, M. Elhilali, and D. Yu, “EzAudio: Enhancing Text-to-Audio Generation with Efficient Diffusion Transformer,” inProc. Interspeech, 2025, pp. 4233– 4237
2025
-
[21]
Continuous audio language models,
S. Rouard, M. Orsini, A. Roebel, N. Zeghidour, and A. D ´efossez, “Continuous audio language models,” inProc. ICLR, 2026
2026
-
[22]
Diffusion transformers with representation autoencoders,
B. Zheng, N. Ma, S. Tong, and S. Xie, “Diffusion transformers with representation autoencoders,” inProc. ICLR, 2026
2026
-
[23]
Long-form music generation with latent diffusion,
Z. Evans, J. D. Parker, C. Carr, Z. Zukowski, J. Taylor, and J. Pons, “Long-form music generation with latent diffusion,” inProc. IS- MIR, 2024
2024
-
[24]
Variable bitrate residual vector quantization for audio coding,
Y . Chae, W. Choi, Y . Takida, J. Koo, Y . Ikemiya, Z. Zhong, K. W. Cheuk, M. A. Mart´ınez-Ram´ırez, K. Lee, W.-H. Liaoet al., “Variable bitrate residual vector quantization for audio coding,” in Proc. ICASSP. IEEE, 2025, pp. 1–5
2025
-
[25]
Unlock- ing temporal flexibility: Neural speech codec with variable frame rate,
H. Zhang, Y . Guo, Z. Li, X. Hao, X. Chen, and K. Yu, “Unlock- ing temporal flexibility: Neural speech codec with variable frame rate,” inProc. Interspeech, 2025, pp. 5003–5007
2025
-
[26]
Flexicodec: A dynamic neural audio codec for low frame rates,
J. Li, Y . Qian, Y . Hu, leying zhang, X. Wang, H. Lu, M. Thakker, J. Li, sheng zhao, and Z. Wu, “Flexicodec: A dynamic neural audio codec for low frame rates,” inProc. ICLR, 2026
2026
-
[27]
Beyond fixed frames: Dynamic character-aligned speech tokenization,
L. Della Libera, C. Subakan, and M. Ravanelli, “Beyond fixed frames: Dynamic character-aligned speech tokenization,”arXiv preprint arXiv:2601.23174, 2026
-
[28]
Codecslime: Tem- poral redundancy compression of neural speech codec via dy- namic frame rate,
H. Wang, Y . Guo, C. Shao, B. Li, and K. Yu, “Codecslime: Tem- poral redundancy compression of neural speech codec via dy- namic frame rate,” inProc. ICASSP. IEEE, 2026, pp. 17 017– 17 021
2026
-
[29]
Say more with less: Variable- frame-rate speech tokenization via adaptive clustering and im- plicit duration coding,
R.-C. Zheng, W. Liu, H.-P. Du, Q. Zhang, C. Deng, Q. Chen, W. Wang, Y . Ai, and Z.-H. Ling, “Say more with less: Variable- frame-rate speech tokenization via adaptive clustering and im- plicit duration coding,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 41, 2026, pp. 35 021–35 029
2026
-
[30]
Re-bottleneck: Latent re-structuring for neural audio autoencoders,
D. Bralios, J. Casebeer, and P. Smaragdis, “Re-bottleneck: Latent re-structuring for neural audio autoencoders,” in2025 IEEE 35th International Workshop on Machine Learning for Signal Process- ing (MLSP). IEEE, 2025, pp. 1–6
2025
-
[31]
Dynamic chunking for end-to-end hierarchical sequence modeling,
S. Hwang, B. Wang, and A. Gu, “Dynamic chunking for end-to-end hierarchical sequence modeling,”arXiv preprint arXiv:2507.07955, 2025
-
[32]
You only train once: Loss- conditional training of deep networks,
A. Dosovitskiy and J. Djolonga, “You only train once: Loss- conditional training of deep networks,” inProc. ICLR, 2020
2020
-
[33]
Convnext v2: Co-designing and scaling convnets with masked autoencoders,
S. Woo, S. Debnath, R. Hu, X. Chen, Z. Liu, I. S. Kweon, and S. Xie, “Convnext v2: Co-designing and scaling convnets with masked autoencoders,” inProc. CVPR, 2023, pp. 16 133–16 142
2023
-
[34]
GLU Variants Improve Transformer
N. Shazeer, “Glu variants improve transformer,”arXiv preprint arXiv:2002.05202, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[35]
Audio set: An ontology and human-labeled dataset for audio events,
J. F. Gemmeke, D. P. Ellis, D. Freedman, A. Jansen, W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter, “Audio set: An ontology and human-labeled dataset for audio events,” inProc. ICASSP. IEEE, 2017, pp. 776–780
2017
-
[36]
Fsd50k: an open dataset of human-labeled sound events,
E. Fonseca, X. Favory, J. Pons, F. Font, and X. Serra, “Fsd50k: an open dataset of human-labeled sound events,”IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 30, pp. 829–852, 2021
2021
-
[37]
BBC Sound Effects,
BBC, “BBC Sound Effects,” https://sound- effects.bbcrewind.co.uk/, 2026, accessed: Mar. 4, 2026
2026
-
[38]
M. Goto, S. Balke, and M. Mueller, “Rwc music database.” [Online]. Available: https://doi.org/10.5281/zenodo.18656623
-
[39]
Moisesdb: A dataset for source separation beyond 4-stems,
I. Pereira, F. Ara ´ujo, F. Korzeniowski, and R. V ogl, “Moisesdb: A dataset for source separation beyond 4-stems,”arXiv preprint arXiv:2307.15913, 2023
-
[40]
Coarse-to-fine text-to-music latent diffusion,
L. A. Lanzend ¨orfer, T. Lu, N. Perraudin, D. Herremans, and R. Wattenhofer, “Coarse-to-fine text-to-music latent diffusion,” in Proc. ICASSP. IEEE, 2025, pp. 1–5
2025
-
[41]
The mtg-jamendo dataset for automatic music tagging,
D. Bogdanov, M. Won, P. Tovstogan, A. Porter, and X. Serra, “The mtg-jamendo dataset for automatic music tagging,” inMachine Learning for Music Discovery Workshop, ICML, 2019
2019
-
[42]
Fma: A dataset for music analysis,
M. Defferrard, K. Benzi, P. Vandergheynst, and X. Bresson, “Fma: A dataset for music analysis,” inProc. ISMIR, 2017
2017
-
[43]
Decoupled weight decay regulariza- tion,
I. Loshchilov and F. Hutter, “Decoupled weight decay regulariza- tion,” inProc. ICLR, 2019
2019
-
[44]
Muon: An optimizer for hidden layers in neural networks,
K. Jordan, Y . Jin, V . Boza, J. You, F. Cesista, L. Newhouse, and J. Bernstein, “Muon: An optimizer for hidden layers in neural networks,” 2024. [Online]. Available: https://kellerjordan.github. io/posts/muon/
2024
-
[45]
Muon is Scalable for LLM Training
J. Liu, J. Su, X. Yao, Z. Jiang, G. Lai, Y . Du, Y . Qin, W. Xu, E. Lu, J. Yanet al., “Muon is scalable for llm training,”arXiv preprint arXiv:2502.16982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
The song de- scriber dataset: a corpus of audio captions for music-and-language evaluation
I. Manco, B. Weck, S. Doh, M. Won, Y . Zhang, D. Bodganov, Y . Wu, K. Chen, P. Tovstogan, E. Benetoset al., “The song de- scriber dataset: a corpus of audio captions for music-and-language evaluation.” NeurIPS Machine Learning for Audio Workshop, 2023
2023
-
[47]
Audiocaps: Generating captions for audios in the wild,
C. D. Kim, B. Kim, H. Lee, and G. Kim, “Audiocaps: Generating captions for audios in the wild,” inProc. NAACL-HLT, 2019, pp. 119–132
2019
-
[48]
Muchin: a chinese colloquial description bench- mark for evaluating language models in the field of music,
Z. Wang, S. Li, T. Zhang, Q. Wang, P. Yu, J. Luo, Y . Liu, M. Xi, and K. Zhang, “Muchin: a chinese colloquial description bench- mark for evaluating language models in the field of music,” in Proc. IJCAI, 2024, pp. 7771–7779
2024
-
[49]
G. J. Mysore, “Can we automatically transform speech recorded on common consumer devices in real-world environments into professional production quality speech?—a dataset, insights, and challenges,”IEEE Signal Processing Letters, vol. 22, no. 8, pp. 1006–1010, 2014
2014
-
[50]
auraloss: Audio focused loss functions in pytorch,
C. J. Steinmetz and J. D. Reiss, “auraloss: Audio focused loss functions in pytorch,” inDigital music research network one-day workshop (DMRN+ 15), 2020
2020
-
[51]
Adapting frechet audio distance for generative music evaluation,
A. Gui, H. Gamper, S. Braun, and D. Emmanouilidou, “Adapting frechet audio distance for generative music evaluation,” inProc. ICASSP. IEEE, 2024, pp. 1331–1335
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.