TF-MoE: Time-Frequency Mixture-of-Experts for Efficient Speech Separation
Pith reviewed 2026-07-01 06:40 UTC · model grok-4.3
The pith
TF-MoE adds dynamic time and frequency expert selection to raise speech separation quality at fixed low compute cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
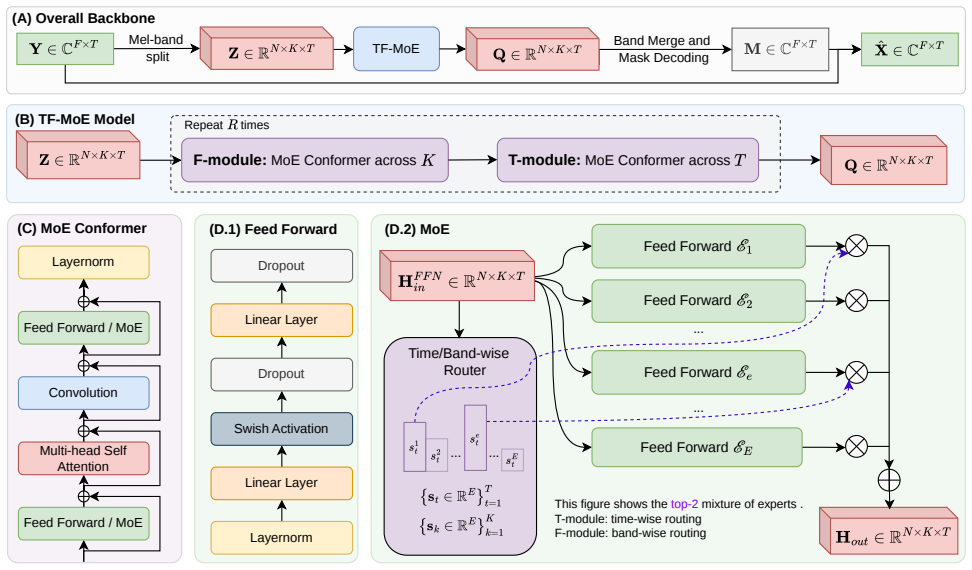
TF-MoE introduces alternating time-wise and frequency-wise MoE modules that perform dynamic expert selection per frame or mel band on a mel-band-splitting Conformer backbone, raising separation performance under strict computation limits while adding almost no inference cost.
What carries the argument
Alternating time-wise and frequency-wise MoE modules with per-frame or per-mel-band dynamic expert selection.
If this is right
- TF-MoE outperforms BSRNN by 3.8 dB SDR on Libri2Mix at comparable 4.1 GMACs/s inference cost.
- Model capacity grows without a proportional rise in inference cost for speech separation tasks.
- The architecture is positioned for deployment on edge devices that face tight compute budgets.
- Performance gains appear consistently when computation cost is held fixed.
Where Pith is reading between the lines
- The same alternating selection pattern could be tested on other audio tasks such as enhancement or diarization that also split time and frequency processing.
- If the experts truly specialize, one could inspect activation patterns to see whether time experts handle transients and frequency experts handle harmonics.
- Combining the MoE structure with further pruning or quantization might push the operating point even lower while preserving the reported gains.
Load-bearing premise
Dynamic expert selection in the time and frequency modules adds negligible extra computation beyond the stated GMACs figure and produces real specialization instead of duplicated work.
What would settle it
Run the model on target edge hardware and measure end-to-end latency and power; if the measured cost exceeds the reported 4.1 GMACs/s or the SDR gain disappears when overhead is included, the claim does not hold.
Figures
read the original abstract
Recent advances in speech separation (SS) have led to compact front-end models with small parameter sizes, yet their high computational cost remains a major barrier for deployment on edge devices. To address this, we propose TF-MoE, a sparse Mixture-of-Experts (MoE) framework that enhances model capacity with almost no increase in inference cost. Our method introduces dynamic expert specialization in time and frequency dimensions through alternating time-wise and frequency-wise MoE modules, each dynamically selecting experts per frame or mel band. Built upon a mel-band-splitting Conformer backbone, TF-MoE achieves strong performance on SS tasks under low-compute settings. Experimental results demonstrate that TF-MoE consistently improves separation performance under computation cost constraints, outperforming BSRNN by +3.8 dB SDR on Libri2Mix with comparable 4.1 GMACs/s inference cost. This positions TF-MoE as a promising candidate for edge-device deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TF-MoE, a sparse Mixture-of-Experts architecture for speech separation built on a mel-band-splitting Conformer backbone. It introduces alternating time-wise and frequency-wise MoE modules that perform dynamic expert selection per frame or mel band. The central empirical claim is that this yields consistent gains under compute constraints, specifically +3.8 dB SDR improvement over BSRNN on Libri2Mix at a comparable inference cost of 4.1 GMACs/s, positioning the model for edge deployment.
Significance. If the efficiency and performance claims are substantiated with full cost accounting and specialization evidence, the work would offer a practical route to higher-capacity speech separation models without proportional compute growth, which is relevant for on-device audio processing.
major comments (2)
- [Abstract] Abstract: the headline result (+3.8 dB SDR at 4.1 GMACs/s) rests on the unverified assertion that alternating time/frequency MoE modules add negligible inference cost beyond the stated GMACs figure. No derivation or breakdown of MACs for the gating networks, expert loading, or dynamic routing is supplied, so it is impossible to confirm that the comparison to BSRNN remains valid once routing overhead is included.
- [Abstract] Abstract: the claim of 'genuine specialization' via per-frame/per-mel-band expert selection lacks supporting statistics (e.g., expert utilization histograms or activation overlap metrics). Without these, the efficiency advantage could be an artifact of redundant computation paths rather than sparse capacity increase.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the computational cost accounting and evidence of specialization. We address each major comment below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline result (+3.8 dB SDR at 4.1 GMACs/s) rests on the unverified assertion that alternating time/frequency MoE modules add negligible inference cost beyond the stated GMACs figure. No derivation or breakdown of MACs for the gating networks, expert loading, or dynamic routing is supplied, so it is impossible to confirm that the comparison to BSRNN remains valid once routing overhead is included.
Authors: We agree that an explicit breakdown strengthens the efficiency claim. The reported 4.1 GMACs/s was obtained via standard FLOPs profiling of the complete architecture (including gating and routing) on the target hardware, but the abstract and main text do not provide the component-wise derivation. We will add a dedicated paragraph and supplementary table in the revised manuscript that decomposes the MACs for the time-wise and frequency-wise MoE modules, gating networks, and routing overhead to allow direct verification against BSRNN. revision: yes
-
Referee: [Abstract] Abstract: the claim of 'genuine specialization' via per-frame/per-mel-band expert selection lacks supporting statistics (e.g., expert utilization histograms or activation overlap metrics). Without these, the efficiency advantage could be an artifact of redundant computation paths rather than sparse capacity increase.
Authors: We acknowledge that the current manuscript does not include quantitative evidence of expert specialization. To demonstrate that the per-frame and per-mel-band routing produces non-redundant expert usage, we will add expert utilization histograms, load-balancing statistics, and activation overlap metrics (e.g., average pairwise expert co-activation) to the experiments section of the revised paper. revision: yes
Circularity Check
No circularity: purely empirical architecture proposal with reported experimental outcomes
full rationale
The paper introduces TF-MoE as a sparse MoE architecture on a mel-band-splitting Conformer backbone and reports measured SDR gains and GMACs/s figures from experiments on Libri2Mix. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The +3.8 dB claim is presented as an observed experimental result rather than a quantity forced by construction from model definitions or prior self-citations. The derivation chain is therefore empty and self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Speech separation (SS) has made great progress with deep learning [1, 2, 3, 4, 5, 6, 7, 8], emerging as a critical enabler for a wide range of real-world applications. Driven by growing pri- vacy concerns [9], the demand for low-latency interaction [10], and the need for offline capability in network-unavailable envi- ronments [11, 12], there...
-
[2]
We propose a competitive mel-band-splitting Conformer backbone that balances performance and efficiency, achieving a +2.5 dB SDR improvement over BSRNN on Libri2Mix at com- parable computational cost
-
[3]
It outperforms Conformer backbone by +1.3 dB SDR on Libri2Mix
We propose TF-MoE, a sparse Mixture-of-Experts framework that replaces the feed-forward modules in both the time and frequency Conformer blocks with sparsely-gated ex- pert layers, scaling model capacity without increasing compu- tational cost. It outperforms Conformer backbone by +1.3 dB SDR on Libri2Mix
-
[4]
TF-MoE: Time-Frequency Mixture-of-Experts for Efficient Speech Separation
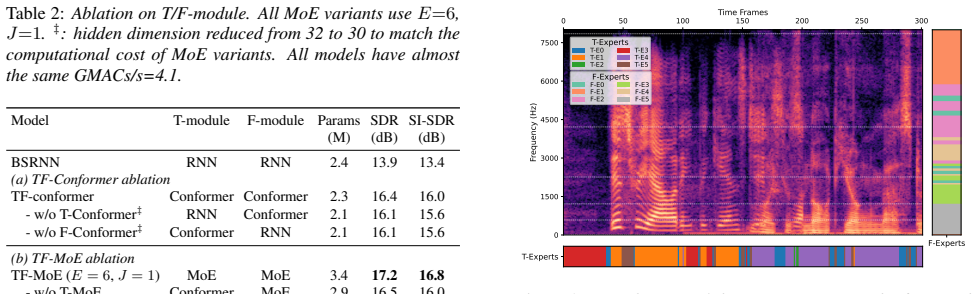
Comprehensive ablation studies validate the complemen- tary nature of sparse MoE routing and Conformer on both tem- poral and frequency dimensions. Furthermore, visual analysis of the gating policies reveals an explicit structural specialization on different acoustic patterns. arXiv:2606.29575v2 [cs.SD] 30 Jun 2026 Feed Forward / MoE Multi-head Self Atten...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Methodology 2.1. Backbone Model We first introduce a new SS model, TF-Conformer, as our back- bone, which is inspired by the band-split RNN (BSRNN) [6] with two key modifications: (i) the manually designed sub- band splitting is replaced with mel-scale [30] band splitting, and (ii) the RNN sequence modeling modules are replaced with Conformer [31] blocks....
-
[6]
Experimental Setup Datasets & Configuration:Experiments are conducted on the Libri2Mix (16kHz, min) dataset from LibriMix [33]
Experiments 3.1. Experimental Setup Datasets & Configuration:Experiments are conducted on the Libri2Mix (16kHz, min) dataset from LibriMix [33]. The input spectrogram is extracted using a 32 ms Hanning window with an 8 ms shift, and split intoK=80 mel-scale [30] sub-bands. Unless otherwise stated, models use hidden dimensionN= 32 Table 1:Separation result...
-
[7]
free lunch
Conclusion We proposed TF-MoE, a highly efficient time-frequency Mixture-of-Experts framework, to overcome the capacity- computation bottleneck in the state-of-the-art speech separa- tion. By integrating sparse expert routing into a dual-path Con- former backbone, our model successfully converts newly added parameters into separation performance almost wi...
-
[8]
2021ZD0201500, in part by the Na- tional Natural Science Foundation of China under Grant No
Acknowledgments This work was supported in part by the China STI 2030–Major Projects under Grant No. 2021ZD0201500, in part by the Na- tional Natural Science Foundation of China under Grant No. U25A20409, and in part by the SJTU Med-X (Medicine & Engineering) Translational Research Grant under Grant No. YG2025LC09
2030
-
[9]
Generative AI Use Disclosure During the preparation of this work, the author(s) used genera- tive AI tools (e.g., ChatGPT, GLM, Gemini) for language pol- ishing and grammar checking to improve the readability of the manuscript. All scientific content, methodology design, and ex- perimental analysis were conducted and verified solely by the authors, who ta...
-
[10]
Supervised speech separation based on deep learning: An overview,
D. Wang and J. Chen, “Supervised speech separation based on deep learning: An overview,”IEEE/ACM Transactions on Au- dio, Speech, and Language Processing, vol. 26, no. 10, pp. 1702– 1726, 2018
2018
-
[11]
Permutation invari- ant training of deep models for speaker-independent multi-talker speech separation,
D. Yu, M. Kolbæk, Z. Tan, and J. Jensen, “Permutation invari- ant training of deep models for speaker-independent multi-talker speech separation,” Mar. 2017, pp. 241–245
2017
-
[12]
Conv-TasNet: Surpassing Ideal Time– Frequency Magnitude Masking for Speech Separation,
Y . Luo and N. Mesgarani, “Conv-TasNet: Surpassing Ideal Time– Frequency Magnitude Masking for Speech Separation,” vol. 27, no. 8, pp. 1256–1266, Aug. 2019
2019
-
[13]
Speech Enhancement with Score-Based Generative Models in the Complex STFT Do- main,
S. Welker, J. Richter, and T. Gerkmann, “Speech Enhancement with Score-Based Generative Models in the Complex STFT Do- main,” inInterspeech 2022. ISCA, Sep. 2022, pp. 2928–2932
2022
-
[14]
Tf-gridnet: Making time-frequency domain models great again for monaural speaker separation,
Z.-Q. Wang, S. Cornell, S. Choi, Y . Lee, B.-Y . Kim, and S. Watan- abe, “Tf-gridnet: Making time-frequency domain models great again for monaural speaker separation,” inICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5
2023
-
[15]
Efficient Monaural Speech Enhancement with Universal Sample Rate Band-Split RNN,
J. Yu and Y . Luo, “Efficient Monaural Speech Enhancement with Universal Sample Rate Band-Split RNN,” Jun. 2023, pp. 1–5
2023
-
[16]
URGENT Challenge: Universality, Robustness, and Generalizability For Speech Enhancement,
W. Zhang, R. Scheibler, K. Saijo, S. Cornell, C. Li, Z. Ni, A. Kumar, J. Pirklbauer, M. Sach, S. Watanabe, T. Fingscheidt, and Y . Qian, “URGENT Challenge: Universality, Robustness, and Generalizability For Speech Enhancement,” 2024, pp. 4868– 4872
2024
-
[17]
Interspeech 2025 URGENT Speech Enhancement Challenge,
K. Saijo, W. Zhang, S. Cornell, R. Scheibler, C. Li, Z. Ni, A. Ku- mar, M. Sach, Y . Fu, W. Wang, T. Fingscheidt, and S. Watanabe, “Interspeech 2025 URGENT Speech Enhancement Challenge,” in Interspeech 2025, 2025, pp. 858–862
2025
-
[18]
The voiceprivacy 2024 challenge evaluation plan,
N. Tomashenko, X. Miao, P. Champion, S. Meyer, X. Wang, E. Vincent, M. Panariello, N. Evans, J. Yamagishi, and M. Todisco, “The voiceprivacy 2024 challenge evaluation plan,” arXiv preprint arXiv:2404.02677, 2024
-
[19]
Icassp 2023 deep noise suppression challenge,
H. Dubey, A. Aazami, V . Gopal, B. Naderi, S. Braun, R. Cutler, A. Ju, M. Zohourian, M. Tang, M. Golestanehet al., “Icassp 2023 deep noise suppression challenge,”IEEE Open Journal of Signal Processing, vol. 5, pp. 725–737, 2024
2023
-
[20]
Tinylstms: Effi- cient neural speech enhancement for hearing aids,
I. Fedorov, M. Stamenovic, C. Jensen, L.-C. Yang, A. Mandell, Y . Gan, M. Mattina, and P. N. Whatmough, “Tinylstms: Effi- cient neural speech enhancement for hearing aids,”arXiv preprint arXiv:2005.11138, 2020
-
[21]
Low latency speech enhancement for hearing aids using deep filtering,
H. Schr ¨oter, T. Rosenkranz, A.-N. Escalante-B, and A. Maier, “Low latency speech enhancement for hearing aids using deep filtering,”IEEE/ACM Transactions on Audio, Speech, and Lan- guage Processing, vol. 30, pp. 2716–2728, 2022
2022
-
[22]
Dual-Path RNN: Effi- cient Long Sequence Modeling for Time-Domain Single-Channel Speech Separation,
Y . Luo, Z. Chen, and T. Yoshioka, “Dual-Path RNN: Effi- cient Long Sequence Modeling for Time-Domain Single-Channel Speech Separation,” Barcelona, May 2020, pp. 46–50
2020
-
[23]
Attention Is All You Need In Speech Separation,
C. Subakan, M. Ravanelli, S. Cornell, M. Bronzi, and J. Zhong, “Attention Is All You Need In Speech Separation,” Jun. 2021, pp. 21–25
2021
-
[24]
Skim: Skipping Mem- ory Lstm for Low-Latency Real-Time Continuous Speech Sepa- ration,
C. Li, L. Yang, W. Wang, and Y . Qian, “Skim: Skipping Mem- ory Lstm for Low-Latency Real-Time Continuous Speech Sepa- ration,” Singapore, May 2022, pp. 681–685
2022
-
[25]
M. Xu, K. Li, G. Chen, and X. Hu, “Tiger: Time-frequency in- terleaved gain extraction and reconstruction for efficient speech separation,”arXiv preprint arXiv:2410.01469, 2024
-
[26]
Stack Less, Repeat More: A Block Reusing Approach for Progressive Speech En- hancement,
J. Kim, U.-H. Shin, J. Ko, and H.-M. Park, “Stack Less, Repeat More: A Block Reusing Approach for Progressive Speech En- hancement,” May 2025
2025
-
[27]
Beyond Performance Plateaus: A Comprehensive Study on Scal- ability in Speech Enhancement,
W. Zhang, K. Saijo, J.-w. Jung, C. Li, S. Watanabe, and Y . Qian, “Beyond Performance Plateaus: A Comprehensive Study on Scal- ability in Speech Enhancement,” inProc. Interspeech 2024, 2024, pp. 1740–1744
2024
-
[28]
Predictive Skim: Contrastive Pre- dictive Coding for Low-Latency Online Speech Separation,
C. Li, Y . Wu, and Y . Qian, “Predictive Skim: Contrastive Pre- dictive Coding for Low-Latency Online Speech Separation,” Jun. 2023, pp. 1–5
2023
-
[29]
CheapNET: Improving Light- weight speech enhancement network by projected loss function,
K. Tan, B. Dai, J. Li, and W. Mao, “CheapNET: Improving Light- weight speech enhancement network by projected loss function,” Nov. 2023
2023
-
[30]
TF-SkiMNet: Speech En- hancement Based on Inplace Modeling and Skipping Memory in Time-Frequency Domain,
Z. Li, S. He, J. Bai, and X. Zhang, “TF-SkiMNet: Speech En- hancement Based on Inplace Modeling and Skipping Memory in Time-Frequency Domain,” 2025, pp. 5143–5147
2025
-
[31]
A Comprehensive Survey of Mixture-of- Experts: Algorithms, Theory, and Applications,
S. Mu and S. Lin, “A Comprehensive Survey of Mixture-of- Experts: Algorithms, Theory, and Applications,” Apr. 2025
2025
-
[32]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer,
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hin- ton, and J. Dean, “Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer,” Jan. 2017
2017
-
[33]
Building a great multi-lingual teacher with sparsely-gated mixture of experts for speech recognition,
K. Kumatani, R. Gmyr, F. C. Salinas, L. Liu, W. Zuo, D. Patel, E. Sun, and Y . Shi, “Building a great multi-lingual teacher with sparsely-gated mixture of experts for speech recognition,” Jan. 2022
2022
-
[34]
GLaM: Efficient Scaling of Language Models with Mixture-of-Experts,
N. Du, Y . Huang, A. M. Dai, S. Tong, D. Lepikhin, Y . Xu, M. Krikun, Y . Zhou, A. W. Yu, O. Firat, B. Zoph, L. Fedus, M. P. Bosma, Z. Zhou, T. Wang, E. Wang, K. Webster, M. Pellat, K. Robinson, K. Meier-Hellstern, T. Duke, L. Dixon, K. Zhang, Q. Le, Y . Wu, Z. Chen, and C. Cui, “GLaM: Efficient Scaling of Language Models with Mixture-of-Experts,” inProce...
2022
-
[35]
DeepSeekMoE: Towards Ulti- mate Expert Specialization in Mixture-of-Experts Language Mod- els,
D. Dai, C. Deng, C. Zhao, R. X. Xu, H. Gao, D. Chen, J. Li, W. Zeng, X. Yu, Y . Wu, Z. Xie, Y . K. Li, P. Huang, F. Luo, C. Ruan, Z. Sui, and W. Liang, “DeepSeekMoE: Towards Ulti- mate Expert Specialization in Mixture-of-Experts Language Mod- els,” Jan. 2024
2024
-
[36]
CLIP-MoE: Towards Building Mixture of Experts for CLIP with Diversified Multiplet Upcycling,
J. Zhang, X. Qu, T. Zhu, and Y . Cheng, “CLIP-MoE: Towards Building Mixture of Experts for CLIP with Diversified Multiplet Upcycling,” May 2025
2025
-
[37]
Speech Enhance- ment using a Deep Mixture of Experts,
S. E. Chazan, J. Goldberger, and S. Gannot, “Speech Enhance- ment using a Deep Mixture of Experts,” Mar. 2017
2017
-
[38]
Handling Trade-Offs in Speech Separation with Sparsely-Gated Mixture of Experts,
X. Wang, Z. Chen, Y . Shi, J. Wu, N. Kanda, and T. Yoshioka, “Handling Trade-Offs in Speech Separation with Sparsely-Gated Mixture of Experts,” May 2023
2023
-
[39]
A Scale for the Measurement of the Psychological Magnitude Pitch,
J. V olkmann, S. S. Stevens, and E. B. Newman, “A Scale for the Measurement of the Psychological Magnitude Pitch,”The Journal of the Acoustical Society of America, vol. 8, no. 3 Supplement, p. 208, Jan. 1937
1937
-
[40]
Conformer: Convolution-augmented Transformer for Speech Recognition,
A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y . Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y . Wu, and R. Pang, “Conformer: Convolution-augmented Transformer for Speech Recognition,” 2020, pp. 5036–5040
2020
-
[41]
Searching for Activation Functions
P. Ramachandran, B. Zoph, and Q. V . Le, “Searching for activa- tion functions,”arXiv preprint arXiv:1710.05941, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
Librimix: An open-source dataset for generalizable speech separation,
J. Cosentino, M. Pariente, S. Cornell, A. Deleforge, and E. Vin- cent, “Librimix: An open-source dataset for generalizable speech separation,”arXiv, 2020
2020
-
[43]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter, “Decoupled weight decay regulariza- tion,”arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[44]
SGDR: Stochastic Gradient Descent with Warm Restarts
——, “Sgdr: Stochastic gradient descent with warm restarts,” arXiv preprint arXiv:1608.03983, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[45]
BSS EV AL Toolbox User Guide – Revision 2.0,
C. F ´evotte, R. Gribonval, and E. Vincent, “BSS EV AL Toolbox User Guide – Revision 2.0,” Report, 2005
2005
-
[46]
SDR – Half-baked or Well Done?
J. L. Roux, S. Wisdom, H. Erdogan, and J. R. Hershey, “SDR – Half-baked or Well Done?” May 2019, pp. 626–630
2019
-
[47]
Perceptual evaluation of speech quality (pesq)-a new method for speech quality assessment of telephone networks and codecs,
A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hekstra, “Perceptual evaluation of speech quality (pesq)-a new method for speech quality assessment of telephone networks and codecs,” in 2001 IEEE international conference on acoustics, speech, and signal processing. Proceedings (Cat. No. 01CH37221), vol. 2. IEEE, 2001, pp. 749–752
2001
-
[48]
An Algo- rithm for Intelligibility Prediction of Time–Frequency Weighted Noisy Speech,
C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, “An Algo- rithm for Intelligibility Prediction of Time–Frequency Weighted Noisy Speech,” vol. 19, no. 7, pp. 2125–2136, Sep. 2011
2011
-
[49]
SPMamba: State-space model is all you need in speech separation,
K. Li, G. Chen, R. Yang, and X. Hu, “SPMamba: State-space model is all you need in speech separation,” Sep. 2024
2024
-
[50]
Speech separation using an asynchronous fully recurrent convolutional neural network,
X. Hu, K. Li, W. Zhang, Y . Luo, J.-M. Lemercier, and T. Gerk- mann, “Speech separation using an asynchronous fully recurrent convolutional neural network,”Advances in Neural Information Processing Systems, vol. 34, pp. 22 509–22 522, 2021
2021
-
[51]
An efficient encoder-decoder ar- chitecture with top-down attention for speech separation,
K. Li, R. Yang, and X. Hu, “An efficient encoder-decoder ar- chitecture with top-down attention for speech separation,”arXiv preprint arXiv:2209.15200, 2022
-
[52]
Sudo rm-rf: Efficient net- works for universal audio source separation,
E. Tzinis, Z. Wang, and P. Smaragdis, “Sudo rm-rf: Efficient net- works for universal audio source separation,” in2020 IEEE 30th International Workshop on Machine Learning for Signal Process- ing (MLSP). IEEE, 2020, pp. 1–6
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.