Learning to Solve a Rubik's Cube with a Dexterous Hand
Pith reviewed 2026-05-24 16:06 UTC · model grok-4.3
The pith
A hierarchical deep reinforcement learning method allows a 24-DoF dexterous hand to solve Rubik's cubes by separating planning from finger control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that combining a model-based cube solver to find optimal move sequences with a model-free reinforcement learning policy to control the five fingers enables the 24-DoF hand to restore scrambled Rubik's cubes, with extensive tests on 1400 instances yielding an average success rate of 90.3 percent.
What carries the argument
Hierarchical deep reinforcement learning that separates a model-based planner for cube move sequences from a model-free operator for multi-finger execution.
If this is right
- The method can restore randomly scrambled cubes without human intervention in the simulator.
- Model-free control can handle the high-dimensional state space of finger contacts and cube orientations.
- Such separation allows solving tasks that require both long-term planning and precise low-level actions.
- Performance generalizes across a large number of initial configurations.
Where Pith is reading between the lines
- If the simulator matches real-world physics closely enough, the same policies could transfer to physical hardware.
- The approach might extend to solving other twisty puzzles or manipulating objects with similar internal structures.
- Future work could integrate visual feedback or handle partial observability in the cube state.
- Scaling to more complex assemblies or longer sequences could test the limits of the hierarchy.
Load-bearing premise
The high-fidelity simulator accurately captures the contact dynamics, friction, and deformation between the hand and the Rubik's cube.
What would settle it
Running the trained policies on 1400 new randomly scrambled cubes in the same simulator and measuring a success rate substantially lower than 90.3 percent would falsify the effectiveness claim.
Figures




read the original abstract
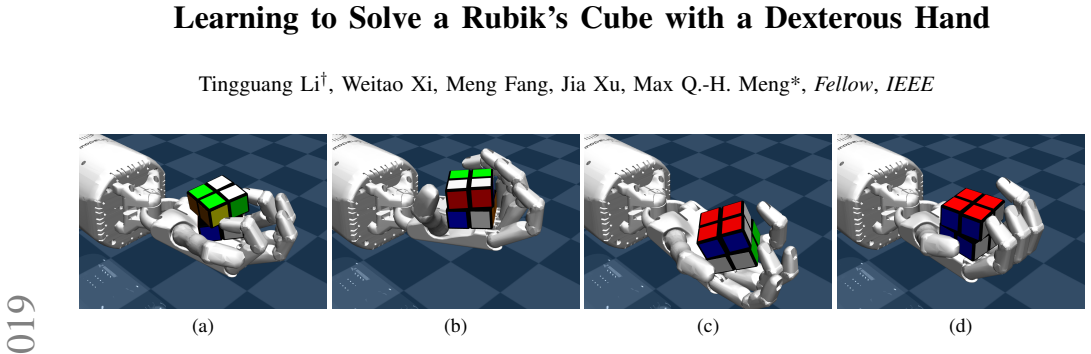
We present a learning-based approach to solving a Rubik's cube with a multi-fingered dexterous hand. Despite the promising performance of dexterous in-hand manipulation, solving complex tasks which involve multiple steps and diverse internal object structure has remained an important, yet challenging task. In this paper, we tackle this challenge with a hierarchical deep reinforcement learning method, which separates planning and manipulation. A model-based cube solver finds an optimal move sequence for restoring the cube and a model-free cube operator controls all five fingers to execute each move step by step. To train our models, we build a high-fidelity simulator which manipulates a Rubik's Cube, an object containing high-dimensional state space, with a 24-DoF robot hand. Extensive experiments on 1400 randomly scrambled Rubik's cubes demonstrate the effectiveness of our method, achieving an average success rate of 90.3%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a hierarchical deep reinforcement learning approach to solve a Rubik's cube using a 24-DoF multi-fingered dexterous hand. A model-based planner computes an optimal sequence of cube moves while a model-free RL policy controls the fingers to execute each step; both are trained in a custom high-fidelity simulator. Experiments on 1400 randomly scrambled cubes are reported to yield an average success rate of 90.3%.
Significance. If the simulator dynamics prove faithful and the method transfers, the hierarchical separation of planning from low-level control would constitute a useful demonstration for long-horizon, high-DoF in-hand manipulation of objects with internal state. The empirical scale (1400 trials) is a positive feature of the evaluation design.
major comments (2)
- [Experiments] Experiments section (and abstract): the 90.3% success rate is obtained exclusively inside the custom simulator; no real-robot trials, no sim-to-real transfer results, and no sensitivity analysis on contact parameters (friction, restitution, deformation) are presented. This directly undermines the central claim that the method solves the task with a physical dexterous hand.
- [Abstract / Method] Abstract and training description: no quantitative details are supplied on the RL training procedure (episode length, reward shaping, network architecture), baselines, variance across random seeds, or any validation that the simulator's contact model matches real physics. These omissions make it impossible to assess whether the reported success rate is reliable or reproducible.
minor comments (1)
- [Title / Abstract] The title and abstract should explicitly qualify that all results are simulation-only unless hardware validation is added.
Simulated Author's Rebuttal
We appreciate the referee's feedback and the opportunity to clarify aspects of our work. Below we respond to each major comment.
read point-by-point responses
-
Referee: [Experiments] Experiments section (and abstract): the 90.3% success rate is obtained exclusively inside the custom simulator; no real-robot trials, no sim-to-real transfer results, and no sensitivity analysis on contact parameters (friction, restitution, deformation) are presented. This directly undermines the central claim that the method solves the task with a physical dexterous hand.
Authors: We acknowledge that our experiments are conducted solely within the custom simulator and that no real-robot trials or sim-to-real transfer results are presented. The paper's claims are limited to the simulated environment, and the hierarchical method is demonstrated for in-hand manipulation in this setting. We will revise the abstract and other sections to explicitly emphasize the simulation-based nature of the results to prevent any misunderstanding regarding physical hardware. Additionally, we will incorporate a sensitivity analysis on contact parameters in the revised manuscript. revision: partial
-
Referee: [Abstract / Method] Abstract and training description: no quantitative details are supplied on the RL training procedure (episode length, reward shaping, network architecture), baselines, variance across random seeds, or any validation that the simulator's contact model matches real physics. These omissions make it impossible to assess whether the reported success rate is reliable or reproducible.
Authors: We agree that providing more quantitative details would improve reproducibility. In the revised manuscript we will expand the methods section with specifics on episode lengths, reward shaping, network architectures, baselines evaluated, variance across random seeds, and any available validation of the simulator contact model. revision: yes
- Real-robot trials and sim-to-real transfer results, as the presented study was conducted entirely in simulation.
Circularity Check
Empirical simulation results with no load-bearing derivations or self-referential fits
full rationale
The paper describes a hierarchical method (model-based cube solver + model-free RL finger controller) trained and evaluated entirely inside a custom simulator, with the 90.3% success rate reported as a direct experimental outcome on 1400 test cubes. No equations, fitted parameters renamed as predictions, self-citation chains, or ansatzes are invoked to derive the central claim; the result is obtained by running the trained policies rather than by algebraic reduction to inputs. The simulator fidelity assumption is stated but does not create a circular derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The high-fidelity simulator provides dynamics close enough to reality for the learned policies to succeed on the described task.
Forward citations
Cited by 1 Pith paper
-
Solving Rubik's Cube with a Robot Hand
Reinforcement learning models trained only in simulation using automatic domain randomization solve Rubik's cube with a real robot hand.
Reference graph
Works this paper leans on
-
[1]
Contact-invariant opti- mization for hand manipulation,
I. Mordatch, Z. Popovi ´c, and E. Todorov, “Contact-invariant opti- mization for hand manipulation,” in Proceedings of the ACM SIG- GRAPH/Eurographics symposium on computer animation . Euro- graphics Association, 2012, pp. 137–144
work page 2012
-
[2]
Dexterous manipulation using both palm and fingers,
Y . Bai and C. K. Liu, “Dexterous manipulation using both palm and fingers,” in 2014 IEEE International Conference on Robotics and Automation (ICRA) . IEEE, 2014, pp. 1560–1565
work page 2014
-
[3]
Learning Dexterous In-Hand Manipulation
M. Andrychowicz, B. Baker, M. Chociej, R. Jozefowicz, B. Mc- Grew, J. Pachocki, A. Petron, M. Plappert, G. Powell, A. Ray, et al. , “Learning dexterous in-hand manipulation,” arXiv preprint arXiv:1808.00177, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations
A. Rajeswaran, V . Kumar, A. Gupta, G. Vezzani, J. Schulman, E. Todorov, and S. Levine, “Learning complex dexterous manipulation with deep reinforcement learning and demonstrations,” arXiv preprint arXiv:1709.10087, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[5]
In-Hand Manipulation via Motion Cones
N. Chavan-Dafle, R. Holladay, and A. Rodriguez, “In-hand manipula- tion via motion cones,” arXiv preprint arXiv:1810.00219 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
A. H. Frey and D. Singmaster, Handbook of cubik math . Enslow Publishers Hillside, NJ, 1982
work page 1982
-
[7]
Mujoco: A physics engine for model-based control,
E. Todorov, T. Erez, and Y . Tassa, “Mujoco: A physics engine for model-based control,” in 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems . IEEE, 2012, pp. 5026–5033
work page 2012
-
[8]
Optimal control with learned local models: Application to dexterous manipulation,
V . Kumar, E. Todorov, and S. Levine, “Optimal control with learned local models: Application to dexterous manipulation,” in 2016 IEEE International Conference on Robotics and Automation (ICRA) . IEEE, 2016, pp. 378–383
work page 2016
-
[9]
Distributed Distributional Deterministic Policy Gradients
G. Barth-Maron, M. W. Hoffman, D. Budden, W. Dabney, D. Horgan, A. Muldal, N. Heess, and T. Lillicrap, “Distributed distributional de- terministic policy gradients,” arXiv preprint arXiv:1804.08617 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[10]
M. Andrychowicz, F. Wolski, A. Ray, J. Schneider, R. Fong, P. Welin- der, B. McGrew, J. Tobin, O. P. Abbeel, and W. Zaremba, “Hindsight experience replay,” in Advances in Neural Information Processing Systems, 2017, pp. 5048–5058
work page 2017
-
[11]
T. D. Kulkarni, K. Narasimhan, A. Saeedi, and J. Tenenbaum, “Hier- archical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation,” in Advances in neural information process- ing systems , 2016, pp. 3675–3683
work page 2016
-
[12]
Learning and Transfer of Modulated Locomotor Controllers
N. Heess, G. Wayne, Y . Tassa, T. Lillicrap, M. Riedmiller, and D. Silver, “Learning and transfer of modulated locomotor controllers,” arXiv preprint arXiv:1610.05182 , 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[13]
Data-efficient hier- archical reinforcement learning,
O. Nachum, S. S. Gu, H. Lee, and S. Levine, “Data-efficient hier- archical reinforcement learning,” in Advances in Neural Information Processing Systems, 2018, pp. 3307–3317
work page 2018
-
[14]
T. Li, J. Pan, D. Zhu, and M. Q.-H. Meng, “Learning to interrupt: A hierarchical deep reinforcement learning framework for efficient exploration,” in 2018 IEEE International Conference on Robotics and Biomimetics (ROBIO). IEEE, 2018, pp. 648–653
work page 2018
-
[15]
Finding optimal solutions to rubik’s cube using pattern databases,
R. E. Korf, “Finding optimal solutions to rubik’s cube using pattern databases,” in AAAI/IAAI, 1997, pp. 700–705
work page 1997
-
[16]
The diameter of the rubik’s cube group is twenty,
T. Rokicki, H. Kociemba, M. Davidson, and J. Dethridge, “The diameter of the rubik’s cube group is twenty,” SIAM Review, vol. 56, no. 4, pp. 645–670, 2014
work page 2014
-
[17]
Harnessing parallel disks to solve rubiks cube,
D. Kunkle and G. Cooperman, “Harnessing parallel disks to solve rubiks cube,” Journal of Symbolic Computation , vol. 44, no. 7, pp. 872–890, 2009
work page 2009
-
[18]
C. Zieli ´nski, W. Szynkiewicz, T. Winiarski, M. Staniak, W. Czajewski, and T. Kornuta, “Rubik’s cube as a benchmark validating mrroc++ as an implementation tool for service robot control systems,” Industrial Robot: An International Journal , vol. 34, no. 5, pp. 368–375, 2007
work page 2007
-
[19]
Rubik’s cube han- dling using a high-speed multi-fingered hand and a high-speed vision system,
R. Rigo, Y . Yamakawa, T. Senoo, and M. Ishikawa, “Rubik’s cube han- dling using a high-speed multi-fingered hand and a high-speed vision system,” in 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems , 10 2018, pp. 6609–6614
work page 2012
-
[20]
B. Siciliano and O. Khatib, Springer handbook of robotics . Springer, 2016
work page 2016
-
[21]
Solving the Rubik's Cube Without Human Knowledge
S. McAleer, F. Agostinelli, A. Shmakov, and P. Baldi, “Solv- ing the rubik’s cube without human knowledge,” arXiv preprint arXiv:1805.07470, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[22]
Thistlethwaites 52-move algorithm,
M. Thistlethwaite, “Thistlethwaites 52-move algorithm,” 1981
work page 1981
-
[23]
Solving the rubik’s cube without human knowledge,
H. Kociemba, “Solving the rubik’s cube without human knowledge,” http://kociemba.org/cube.htm
-
[24]
Simulation tools for model- based robotics: Comparison of bullet, havok, mujoco, ode and physx,
T. Erez, Y . Tassa, and E. Todorov, “Simulation tools for model- based robotics: Comparison of bullet, havok, mujoco, ode and physx,” in 2015 IEEE international conference on robotics and automation (ICRA). IEEE, 2015, pp. 4397–4404
work page 2015
-
[25]
Continuous control with deep reinforcement learning
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y . Tassa, D. Silver, and D. Wierstra, “Continuous control with deep reinforce- ment learning,” arXiv preprint arXiv:1509.02971 , 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.