Auto-FP: An Experimental Study of Automated Feature Preprocessing for Tabular Data
Pith reviewed 2026-05-24 05:56 UTC · model grok-4.3
The pith
Auto-FP can be solved by modeling it as hyperparameter optimization or neural architecture search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Auto-FP can be modelled as either a hyperparameter optimization (HPO) or a neural architecture search (NAS) problem, which enables extending a variety of HPO and NAS algorithms to solve the Auto-FP problem.
What carries the argument
The modeling of automated feature preprocessing as an HPO or NAS problem to enable reuse of existing search algorithms.
If this is right
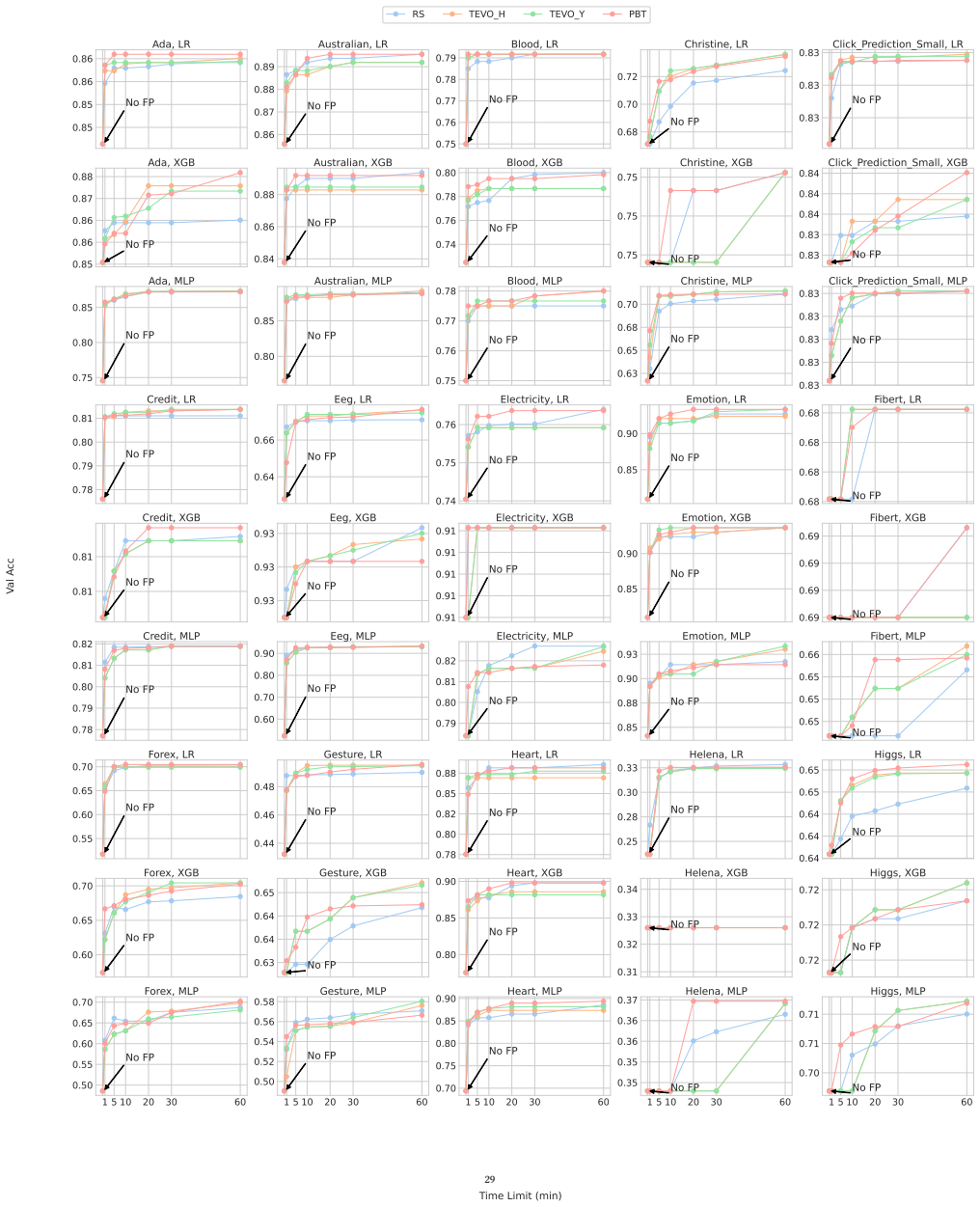
- Evolution-based algorithms achieve the leading average ranking among the tested methods.
- Random search is a strong baseline that outperforms many surrogate-model-based and bandit-based algorithms for Auto-FP.
- Analysis reveals reasons why standard HPO and NAS methods underperform random search in this setting.
- Auto-FP can be extended to support parameter search using two different approaches.
- Popular AutoML tools have limitations in handling automated feature preprocessing.
Where Pith is reading between the lines
- Improvements to HPO and NAS algorithms could automatically translate to better Auto-FP performance.
- The bottleneck analysis suggests specific areas where new Auto-FP tailored algorithms could be developed.
- Adopting this approach in practice could significantly reduce the manual effort in building ML pipelines for tabular data.
- Future work might test these methods on private industry datasets to confirm generalizability.
Load-bearing premise
The large combinatorial search space of preprocessor choices and orderings can be effectively navigated by standard HPO and NAS algorithms without requiring domain-specific adaptations or becoming computationally intractable.
What would settle it
If applying HPO and NAS algorithms to Auto-FP fails to produce preprocessing pipelines that improve model quality over default or manual choices on most of the 45 datasets, the modeling approach would be falsified.
Figures




























read the original abstract
Classical machine learning models, such as linear models and tree-based models, are widely used in industry. These models are sensitive to data distribution, thus feature preprocessing, which transforms features from one distribution to another, is a crucial step to ensure good model quality. Manually constructing a feature preprocessing pipeline is challenging because data scientists need to make difficult decisions about which preprocessors to select and in which order to compose them. In this paper, we study how to automate feature preprocessing (Auto-FP) for tabular data. Due to the large search space, a brute-force solution is prohibitively expensive. To address this challenge, we interestingly observe that Auto-FP can be modelled as either a hyperparameter optimization (HPO) or a neural architecture search (NAS) problem. This observation enables us to extend a variety of HPO and NAS algorithms to solve the Auto-FP problem. We conduct a comprehensive evaluation and analysis of 15 algorithms on 45 public ML datasets. Overall, evolution-based algorithms show the leading average ranking. Surprisingly, the random search turns out to be a strong baseline. Many surrogate-model-based and bandit-based search algorithms, which achieve good performance for HPO and NAS, do not outperform random search for Auto-FP. We analyze the reasons for our findings and conduct a bottleneck analysis to identify the opportunities to improve these algorithms. Furthermore, we explore how to extend Auto-FP to support parameter search and compare two ways to achieve this goal. In the end, we evaluate Auto-FP in an AutoML context and discuss the limitations of popular AutoML tools. To the best of our knowledge, this is the first study on automated feature preprocessing. We hope our work can inspire researchers to develop new algorithms tailored for Auto-FP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that automated feature preprocessing (Auto-FP) for tabular data can be modeled as either a hyperparameter optimization (HPO) or neural architecture search (NAS) problem. This modeling enables extending a variety of existing HPO and NAS algorithms to search over preprocessor selections and orderings. A comprehensive evaluation of 15 algorithms across 45 public ML datasets finds that evolution-based methods achieve the leading average rankings, random search is a strong baseline, and many surrogate-model-based and bandit-based methods fail to outperform random search. The work includes analysis of these findings, a bottleneck analysis, an extension to joint parameter search, and an evaluation of Auto-FP within an AutoML context, presenting itself as the first dedicated study on the topic.
Significance. If the central modeling claim and empirical rankings hold after verification of experimental details, the paper provides a useful empirical foundation for Auto-FP by showing that standard HPO/NAS methods can be applied but that surrogate and bandit approaches do not transfer well, thereby identifying a need for domain-tailored algorithms. The scale of the evaluation (45 datasets) and the explicit bottleneck analysis are strengths that could guide future work. The observation that random search remains competitive is a falsifiable insight worth documenting.
major comments (3)
- [Abstract / implied Section 3] Abstract / implied modeling in Section 3: the claim that preprocessor selection and ordering can be directly encoded as a fixed-dimensional HPO problem or NAS cell without domain-specific adaptations is load-bearing for the central contribution. The reported result that surrogate-model and bandit methods fail to beat random search is consistent with the possibility that variable-length sequences and inter-preprocessor interactions are not adequately captured by standard encodings, undermining the assertion that existing HPO/NAS algorithms can be extended without further machinery.
- [Evaluation on 45 datasets] Evaluation section (45 datasets): the soundness of the average-ranking claims depends on verifiable details of data splits, cross-validation procedure, and statistical testing for ranking differences. Without these, it is impossible to rule out that variance, post-hoc dataset selection, or improper multiple-testing correction affects the conclusion that evolution-based algorithms lead while others do not.
- [Bottleneck analysis] Bottleneck analysis: the analysis should explicitly test whether the observed lack of structure for surrogate/bandit methods originates from the HPO/NAS modeling choice itself (e.g., loss of ordering semantics) rather than solely from algorithmic limitations; otherwise the recommendation to develop new algorithms for Auto-FP rests on an unexamined premise.
minor comments (2)
- [Abstract] The abstract states that 'we analyze the reasons for our findings' but does not point to the specific section; adding an explicit cross-reference would improve readability.
- [Modeling section] Notation for how preprocessor pipelines are encoded as fixed-length vectors or architecture cells should be clarified with a small example in the modeling section to make the HPO/NAS reduction concrete.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract / implied Section 3] Abstract / implied modeling in Section 3: the claim that preprocessor selection and ordering can be directly encoded as a fixed-dimensional HPO problem or NAS cell without domain-specific adaptations is load-bearing for the central contribution. The reported result that surrogate-model and bandit methods fail to beat random search is consistent with the possibility that variable-length sequences and inter-preprocessor interactions are not adequately captured by standard encodings, undermining the assertion that existing HPO/NAS algorithms can be extended without further machinery.
Authors: We maintain that modeling Auto-FP as HPO or NAS is valid because it permits direct extension of existing algorithms, as specified in Section 3 via concrete encodings (fixed-dimensional for HPO; cell-based for NAS). These encodings approximate variable-length sequences and interactions through padding and ordering constraints, but they require no new algorithmic machinery. The underperformance of surrogate/bandit methods is reported as an empirical observation about the resulting search space, not as evidence against the modeling itself. We will revise the abstract and Section 3 to state the approximations more explicitly and note their possible effect on algorithm transfer. revision: partial
-
Referee: [Evaluation on 45 datasets] Evaluation section (45 datasets): the soundness of the average-ranking claims depends on verifiable details of data splits, cross-validation procedure, and statistical testing for ranking differences. Without these, it is impossible to rule out that variance, post-hoc dataset selection, or improper multiple-testing correction affects the conclusion that evolution-based algorithms lead while others do not.
Authors: The Evaluation section already specifies the use of standard train/test splits from the source repositories, 5-fold cross-validation, average ranks, and Friedman/Nemenyi tests. To improve verifiability we will expand the section with explicit statements on dataset selection criteria, exact multiple-testing procedure, and variance handling. We will also release the full experimental code and splits. revision: yes
-
Referee: [Bottleneck analysis] Bottleneck analysis: the analysis should explicitly test whether the observed lack of structure for surrogate/bandit methods originates from the HPO/NAS modeling choice itself (e.g., loss of ordering semantics) rather than solely from algorithmic limitations; otherwise the recommendation to develop new algorithms for Auto-FP rests on an unexamined premise.
Authors: The bottleneck analysis examines empirical performance gaps and attributes them in part to preprocessor interaction complexity. We did not run an explicit ablation that isolates encoding effects from algorithmic limitations. We will add a paragraph discussing how the chosen encodings may contribute to the observed lack of exploitable structure, while clarifying that the recommendation for new algorithms is based on the overall empirical pattern rather than a single causal claim. revision: partial
Circularity Check
No circularity: pure empirical benchmarking with external validation
full rationale
The paper is an experimental study that models Auto-FP as HPO/NAS by observation and then benchmarks 15 algorithms on 45 public datasets. No equations, fitted parameters, or first-principles derivations are present that could reduce to inputs by construction. Rankings and conclusions are measured against external public data; the modeling step is a framing choice, not a self-referential derivation. No self-citation load-bearing steps or ansatz smuggling occur. This matches the default expectation of a non-circular empirical paper.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
FELA: A Multi-Agent Evolutionary System for Feature Engineering of Industrial Event Log Data
FELA deploys specialized LLM agents in an evolutionary framework to generate, validate, and refine explainable features from heterogeneous industrial event logs, improving downstream model performance.
Reference graph
Works this paper leans on
-
[1]
2021. AutoML Challenge Website. https://automl.chalearn.org/data
work page 2021
-
[2]
Entropy Function in Scipy Library
2021. Entropy Function in Scipy Library. https://docs.scipy.org/doc/scipy/ reference/generated/scipy.stats.entropy.html
work page 2021
-
[3]
2021. HpBandSter. https://automl.github.io/HpBandSter/build/html/index.html
work page 2021
- [4]
-
[5]
Kurtosis Function in Scipy Library
2021. Kurtosis Function in Scipy Library. https://docs.scipy.org/doc/scipy/ reference/generated/scipy.stats.kurtosis.html
work page 2021
-
[6]
Scikit-learn: Machine Learning in Python
2021. Scikit-learn: Machine Learning in Python. https://scikit-learn.org/stable/
work page 2021
-
[7]
Skewness Function in Scipy Library
2021. Skewness Function in Scipy Library. https://docs.scipy.org/doc/scipy/ reference/generated/scipy.stats.skew.html
work page 2021
-
[8]
State of Data Science and Machine Learning 2021
2021. State of Data Science and Machine Learning 2021. https://www.kaggle. com/kaggle-survey-2021
work page 2021
-
[9]
2022. Auto-FP: An Experimental Study of Automated Feature Preprocessing for Tabular Data (Technical Report). (2022). https://github.com/AutoFP/Auto- FP/blob/main/Auto-FP(technical_report).pdf
work page 2022
-
[10]
2022. Scikit-learn Documentation. https://scikit-learn.org/stable/modules/ preprocessing.html
work page 2022
-
[11]
Scikit-learn: Preprocessing Data
2022. Scikit-learn: Preprocessing Data. https://scikit-learn.org/stable/modules/ preprocessing.html
work page 2022
-
[12]
Peter Auer, Nicolo Cesa-Bianchi, and Paul Fischer. 2002. Finite-time analysis of the multiarmed bandit problem. Machine learning 47 (2002), 235–256
work page 2002
-
[13]
Wolfgang Banzhaf, Peter Nordin, Robert E Keller, and Frank D Francone. 1998. Genetic programming: an introduction: on the automatic evolution of computer programs and its applications . Morgan Kaufmann Publishers Inc
work page 1998
-
[14]
Rémi Bardenet, Mátyás Brendel, Balázs Kégl, and Michèle Sebag. 2013. Col- laborative hyperparameter tuning. In Proceedings of the 30th International Conference on Machine Learning, ICML 2013, Atlanta, GA, USA, 16-21 June 2013 (JMLR Workshop and Conference Proceedings) , Vol. 28. JMLR.org, 199–207. http://proceedings.mlr.press/v28/bardenet13.html
work page 2013
-
[15]
James Bergstra, Rémi Bardenet, Yoshua Bengio, and Balázs Kégl. 2011. Algorithms for Hyper-Parameter Optimization. In Advances in Neural Information Processing Systems 24: 25th Annual Conference on Neural Information Processing Systems
work page 2011
-
[16]
Proceedings of a meeting held 12-14 December 2011, Granada, Spain , John Shawe-Taylor, Richard S. Zemel, Peter L. Bartlett, Fernando C. N. Pereira, and Kilian Q. Weinberger (Eds.). 2546–2554. https://proceedings.neurips.cc/paper/ 2011/hash/86e8f7ab32cfd12577bc2619bc635690-Abstract.html
work page 2011
-
[17]
James Bergstra and Yoshua Bengio. 2012. Random Search for Hyper-Parameter Optimization. Journal of Machine Learning Research 13, 10 (2012), 281–305. http://jmlr.org/papers/v13/bergstra12a.html
work page 2012
-
[18]
James Bergstra, Dan Yamins, David D Cox, et al . 2013. Hyperopt: A python library for optimizing the hyperparameters of machine learning algorithms. In Proceedings of the 12th Python in science conference , Vol. 13. Citeseer, 20
work page 2013
-
[19]
Bernhard E Boser, Isabelle M Guyon, and Vladimir N Vapnik. 1992. A train- ing algorithm for optimal margin classifiers. In Proceedings of the fifth annual workshop on Computational learning theory . 144–152
work page 1992
-
[20]
Jason Brownlee. 2020. Data preparation for machine learning: data cleaning, feature selection, and data transforms in Python
work page 2020
-
[21]
Girish Chandrashekar and Ferat Sahin. 2014. A survey on feature selection methods. Computers & Electrical Engineering 40, 1 (2014), 16–28
work page 2014
-
[22]
Krishna Teja Chitty-Venkata, Murali Emani, Venkatram Vishwanath, and Arun K. Somani. 2023. Neural Architecture Search Benchmarks: Insights and Survey.IEEE Access 11 (2023), 25217–25236. https://doi.org/10.1109/ACCESS.2023.3253818
-
[23]
Xuanyi Dong and Yi Yang. 2020. NAS-Bench-201: Extending the Scope of Repro- ducible Neural Architecture Search. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020 . OpenRe- view.net. https://openreview.net/forum?id=HJxyZkBKDr
work page 2020
-
[24]
Stefan Falkner, Aaron Klein, and Frank Hutter. 2018. BOHB: Robust and Ef- ficient Hyperparameter Optimization at Scale. In Proceedings of the 35th In- ternational Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018 (Proceedings of Machine Learning Research) , Jennifer G. Dy and Andreas Krause (Eds.), Vol. 80. P...
work page 2018
-
[25]
Matthias Feurer and Frank Hutter. 2019. Hyperparameter optimization. In Automated machine learning. Springer, Cham, 3–33
work page 2019
-
[26]
Matthias Feurer, Aaron Klein, Katharina Eggensperger, Jost Tobias Springenberg, Manuel Blum, and Frank Hutter. 2015. Efficient and Robust Automated Machine Learning. In Proceedings of the 28th International Conference on Neural Information Processing Systems - Volume 2 (NIPS’15). 2755–2763
work page 2015
-
[27]
George Forman et al. 2003. An extensive empirical study of feature selection metrics for text classification. J. Mach. Learn. Res. 3, Mar (2003), 1289–1305
work page 2003
-
[28]
An Open Source AutoML Benchmark
P. Gijsbers, E. LeDell, S. Poirier, J. Thomas, B. Bischl, and J. Vanschoren. 2019. An Open Source AutoML Benchmark. arXiv preprint arXiv:1907.00909 [cs.LG] (2019). https://arxiv.org/abs/1907.00909 Accepted at AutoML Workshop at ICML 2019
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[29]
Daniel Golovin, Benjamin Solnik, Subhodeep Moitra, Greg Kochanski, John Karro, and D. Sculley. 2017. Google Vizier: A Service for Black-Box Optimization. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, August 13 - 17, 2017 . ACM, 1487–1495. https://doi.org/10.1145/3097983.3098043
-
[30]
Gongde Guo, Hui Wang, David Bell, Yaxin Bi, and Kieran Greer. 2003. KNN model-based approach in classification. In On The Move to Meaningful Internet Systems 2003: CoopIS, DOA, and ODBASE: OTM Confederated International Con- ferences, CoopIS, DOA, and ODBASE 2003, Catania, Sicily, Italy, November 3-7,
work page 2003
- [31]
-
[32]
Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. 2017. DeepFM: A Factorization-Machine based Neural Network for CTR Prediction. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI 2017, Melbourne, Australia, August 19-25, 2017 , Carles Sierra (Ed.). ijcai.org, 1725–1731. https://doi.org/10...
-
[33]
PC Hammer. 1962. Adaptive control processes: a guided tour (R. Bellman)
work page 1962
-
[34]
Jiawei Han, Jian Pei, and Yiwen Yin. 2000. Mining Frequent Patterns without Candidate Generation. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, May 16-18, 2000, Dallas, Texas, USA , Weidong Chen, Jeffrey F. Naughton, and Philip A. Bernstein (Eds.). ACM, 1–12. https: //doi.org/10.1145/342009.335372
-
[35]
Xin He, Kaiyong Zhao, and Xiaowen Chu. 2021. AutoML: A survey of the state- of-the-art. Knowl. Based Syst. 212 (2021), 106622. https://doi.org/10.1016/j.knosys. 2020.106622
-
[36]
Franziska Horn, Robert Pack, and Michael Rieger. 2019. The autofeat Python Li- brary for Automated Feature Engineering and Selection. InMachine Learning and Knowledge Discovery in Databases - International Workshops of ECML PKDD 2019, Würzburg, Germany, September 16-20, 2019, Proceedings, Part I (Communications in Computer and Information Science) , Peggy...
-
[37]
Frank Hutter, Holger H Hoos, and Kevin Leyton-Brown. 2011. Sequential model- based optimization for general algorithm configuration. In International confer- ence on learning and intelligent optimization . Springer, 507–523
work page 2011
-
[38]
Frank Hutter, Holger H Hoos, Kevin Leyton-Brown, and Kevin Murphy. 2010. Time-bounded sequential parameter optimization. In International Conference on Learning and Intelligent Optimization . Springer, 281–298
work page 2010
-
[39]
Population Based Training of Neural Networks
Max Jaderberg, Valentin Dalibard, Simon Osindero, Wojciech M. Czarnecki, Jeff Donahue, Ali Razavi, Oriol Vinyals, Tim Green, Iain Dunning, Karen Simonyan, Chrisantha Fernando, and Koray Kavukcuoglu. 2017. Population Based Training of Neural Networks. CoRR abs/1711.09846 (2017). arXiv:1711.09846 http://arxiv. org/abs/1711.09846
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
Gareth James, Daniela Witten, Trevor Hastie, and Robert Tibshirani. 2013. An introduction to statistical learning . Vol. 112. Springer
work page 2013
-
[41]
Kevin G. Jamieson and Ameet Talwalkar. 2016. Non-stochastic Best Arm Identification and Hyperparameter Optimization. In Proceedings of the 19th International Conference on Artificial Intelligence and Statistics, AISTATS 2016, Cadiz, Spain, May 9-11, 2016 (JMLR Workshop and Conference Proceedings) , Arthur Gretton and Christian C. Robert (Eds.), Vol. 51. J...
work page 2016
-
[42]
Ian T Jolliffe and Jorge Cadima. 2016. Principal component analysis: a review and recent developments. Philosophical transactions of the royal society A: Math- ematical, Physical and Engineering Sciences 374, 2065 (2016), 20150202
work page 2016
-
[43]
Gilad Katz, Eui Chul Richard Shin, and Dawn Song. 2016. ExploreKit: Automatic Feature Generation and Selection. In IEEE 16th International Conference on Data Mining, ICDM 2016, December 12-15, 2016, Barcelona, Spain , Francesco Bonchi, Josep Domingo-Ferrer, Ricardo Baeza-Yates, Zhi-Hua Zhou, and Xindong Wu (Eds.). IEEE Computer Society, 979–984. https://d...
-
[44]
Scott Kirkpatrick, C Daniel Gelatt, and Mario P Vecchi. 1983. Optimization by simulated annealing. science 220, 4598 (1983), 671–680
work page 1983
-
[45]
Pang Wei Koh and Percy Liang. 2017. Understanding Black-box Predictions via Influence Functions. InProceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017 (Proceedings of Machine Learning Research) , Doina Precup and Yee Whye Teh (Eds.), Vol. 70. PMLR, 1885–1894. http://proceedings.mlr.pres...
work page 2017
-
[46]
Sanjay Krishnan and Eugene Wu. 2019. AlphaClean: Automatic Generation of Data Cleaning Pipelines. CoRR abs/1904.11827 (2019). arXiv:1904.11827 http://arxiv.org/abs/1904.11827
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[47]
Max Kuhn and Kjell Johnson. 2021. Feature engineering and selection: A practical approach for predictive models . Chapman & Hall/CRC Press
work page 2021
-
[48]
Doris Jung Lin Lee, Stephen Macke, Doris Xin, Angela Lee, Silu Huang, and Aditya G Parameswaran. 2019. A Human-in-the-loop Perspective on AutoML: Milestones and the Road Ahead. IEEE Data Eng. Bull. 42, 2 (2019), 59–70
work page 2019
-
[49]
Jundong Li, Kewei Cheng, Suhang Wang, Fred Morstatter, Robert P Trevino, Jiliang Tang, and Huan Liu. 2017. Feature selection: A data perspective. ACM computing surveys (CSUR) 50, 6 (2017), 1–45
work page 2017
-
[50]
Jamieson, Giulia DeSalvo, Afshin Rostamizadeh, and Ameet Talwalkar
Lisha Li, Kevin G. Jamieson, Giulia DeSalvo, Afshin Rostamizadeh, and Ameet Talwalkar. 2017. Hyperband: A Novel Bandit-Based Approach to Hyperparameter Optimization. J. Mach. Learn. Res. 18 (2017), 185:1–185:52. http://jmlr.org/papers/ v18/16-558.html
work page 2017
-
[51]
Peng Li, Xi Rao, Jennifer Blase, Yue Zhang, Xu Chu, and Ce Zhang. 2021. CleanML: A Study for Evaluating the Impact of Data Cleaning on ML Classification Tasks. In 37th IEEE International Conference on Data Engineering, ICDE 2021, Chania, Greece, April 19-22, 2021. IEEE, 13–24. https://doi.org/10.1109/ICDE51399.2021.00009
-
[52]
Yang Li, Yu Shen, Wentao Zhang, Jiawei Jiang, Yaliang Li, Bolin Ding, Jingren Zhou, Zhi Yang, Wentao Wu, Ce Zhang, and Bin Cui. 2021. VolcanoML: Speeding up End-to-End AutoML via Scalable Search Space Decomposition. Proc. VLDB Endow. 14, 11 (2021), 2167–2176. http://www.vldb.org/pvldb/vol14/p2167-li.pdf 15
work page 2021
- [53]
-
[54]
Chenxi Liu, Barret Zoph, Maxim Neumann, Jonathon Shlens, Wei Hua, Li-Jia Li, Li Fei-Fei, Alan Yuille, Jonathan Huang, and Kevin Murphy. 2018. Progressive neural architecture search. In Proceedings of the European conference on computer vision (ECCV). 19–34
work page 2018
-
[55]
Sijia Liu, Parikshit Ram, Deepak Vijaykeerthy, Djallel Bouneffouf, Gregory Bram- ble, Horst Samulowitz, Dakuo Wang, Andrew Conn, and Alexander G. Gray
-
[56]
An ADMM Based Framework for AutoML Pipeline Configuration. In The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty- Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, February 7-12, 2020 . ...
work page 2020
-
[57]
Scott M. Lundberg and Su-In Lee. 2017. A Unified Approach to Interpreting Model Predictions. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA , Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V. N. Vishwanathan...
work page 2017
-
[58]
Shaul Markovitch and Dan Rosenstein. 2002. Feature Generation Using General Constructor Functions. Mach. Learn. 49, 1 (2002), 59–98. https://doi.org/10.1023/ A:1014046307775
work page 2002
-
[59]
Microsoft. 2021. Neural Network Intelligence. https://github.com/microsoft/nni
work page 2021
-
[60]
Kevin P Murphy. 2012. Machine learning: a probabilistic perspective . MIT press
work page 2012
-
[61]
Fatemeh Nargesian, Horst Samulowitz, Udayan Khurana, Elias B. Khalil, and Deepak S. Turaga. 2017. Learning Feature Engineering for Classification. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelli- gence, IJCAI 2017, Melbourne, Australia, August 19-25, 2017 , Carles Sierra (Ed.). ijcai.org, 2529–2535. https://doi.org/...
-
[62]
Randal S Olson and Jason H Moore. 2016. TPOT: A tree-based pipeline optimiza- tion tool for automating machine learning. In Workshop on automatic machine learning. PMLR, 66–74
work page 2016
-
[63]
Efficient Neural Architecture Search via Parameter Sharing
Hieu Pham, Melody Y. Guan, Barret Zoph, Quoc V. Le, and Jeff Dean. 2018. Efficient Neural Architecture Search via Parameter Sharing.CoRR abs/1802.03268 (2018). arXiv:1802.03268 http://arxiv.org/abs/1802.03268
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[64]
Alexandre Quemy. 2020. Two-stage optimization for machine learning workflow. Inf. Syst. 92 (2020), 101483. https://doi.org/10.1016/j.is.2019.101483
-
[65]
Esteban Real, Alok Aggarwal, Yanping Huang, and Quoc V. Le. 2018. Regularized Evolution for Image Classifier Architecture Search. CoRR abs/1802.01548 (2018). arXiv:1802.01548 http://arxiv.org/abs/1802.01548
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[66]
Nicolas Schilling, Martin Wistuba, Lucas Drumond, and Lars Schmidt-Thieme
-
[67]
Hyperparameter Optimization with Factorized Multilayer Perceptrons. In Machine Learning and Knowledge Discovery in Databases - European Confer- ence, ECML PKDD 2015, Porto, Portugal, September 7-11, 2015, Proceedings, Part II (Lecture Notes in Computer Science) , Annalisa Appice, Pedro Pereira Rodrigues, Vítor Santos Costa, João Gama, Alípio Jorge, and Ca...
-
[68]
Nicolas Schilling, Martin Wistuba, and Lars Schmidt-Thieme. 2016. Scalable Hyperparameter Optimization with Products of Gaussian Process Experts. In Machine Learning and Knowledge Discovery in Databases - European Conference, ECML PKDD 2016, Riva del Garda, Italy, September 19-23, 2016, Proceedings, Part I (Lecture Notes in Computer Science) , Paolo Frasc...
work page 2016
-
[69]
Vraj Shah, Jonathan Lacanlale, Premanand Kumar, Kevin Yang, and Arun Kumar
-
[70]
Towards Benchmarking Feature Type Inference for AutoML Platforms. In SIGMOD ’21: International Conference on Management of Data, Virtual Event, China, June 20-25, 2021 , Guoliang Li, Zhanhuai Li, Stratos Idreos, and Divesh Srivastava (Eds.). ACM, 1584–1596. https://doi.org/10.1145/3448016.3457274
-
[71]
Zeyuan Shang, Emanuel Zgraggen, Benedetto Buratti, Ferdinand Kossmann, Philipp Eichmann, Yeounoh Chung, Carsten Binnig, Eli Upfal, and Tim Kraska
-
[72]
Democratizing Data Science through Interactive Curation of ML Pipelines. In Proceedings of the 2019 International Conference on Management of Data, SIG- MOD Conference 2019, Amsterdam, The Netherlands, June 30 - July 5, 2019, Peter A. Boncz, Stefan Manegold, Anastasia Ailamaki, Amol Deshpande, and Tim Kraska (Eds.). ACM, 1171–1188. https://doi.org/10.1145...
-
[73]
Qitao Shi, Ya-Lin Zhang, Longfei Li, Xinxing Yang, Meng Li, and Jun Zhou. 2020. SAFE: Scalable Automatic Feature Engineering Framework for Industrial Tasks. In 36th IEEE International Conference on Data Engineering, ICDE 2020, Dallas, TX, USA, April 20-24, 2020 . IEEE, 1645–1656. https://doi.org/10.1109/ICDE48307. 2020.00146
- [74]
-
[75]
William R Thompson. 1933. On the likelihood that one unknown probability exceeds another in view of the evidence of two samples. Biometrika 25, 3-4 (1933), 285–294
work page 1933
-
[76]
Chris Thornton, Frank Hutter, Holger H Hoos, and Kevin Leyton-Brown. 2013. Auto-WEKA: Combined selection and hyperparameter optimization of classifica- tion algorithms. In Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining . 847–855
work page 2013
- [77]
-
[78]
Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. 2017. Deep & Cross Network for Ad Click Predictions. In Proceedings of the ADKDD’17, Halifax, NS, Canada, August 13 - 17, 2017 . ACM, 12:1–12:7. https://doi.org/10.1145/3124749.3124754
-
[79]
Tianxiang Wang, Jie Xu, and Jian-Qiang Hu. 2021. A Study on Efficient Com- puting Budget Allocation for a Two-Stage Problem. Asia Pac. J. Oper. Res. 38, 2 (2021), 2050044:1–2050044:20. https://doi.org/10.1142/S021759592050044X
-
[80]
Ronald J Williams. 1992. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning 8, 3 (1992), 229–256
work page 1992
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.