Latent Linear Quadratic Regulator for Robotic Control Tasks
Pith reviewed 2026-05-23 22:44 UTC · model grok-4.3
The pith
LaLQR learns a latent mapping that turns nonlinear robot dynamics linear and costs quadratic so standard LQR can replace slow MPC.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A latent space exists in which the original nonlinear dynamics become linear and the original cost becomes quadratic; the parameters of this space are learned jointly so that the resulting LQR controller reproduces the closed-loop behavior of the full MPC while running orders of magnitude faster.
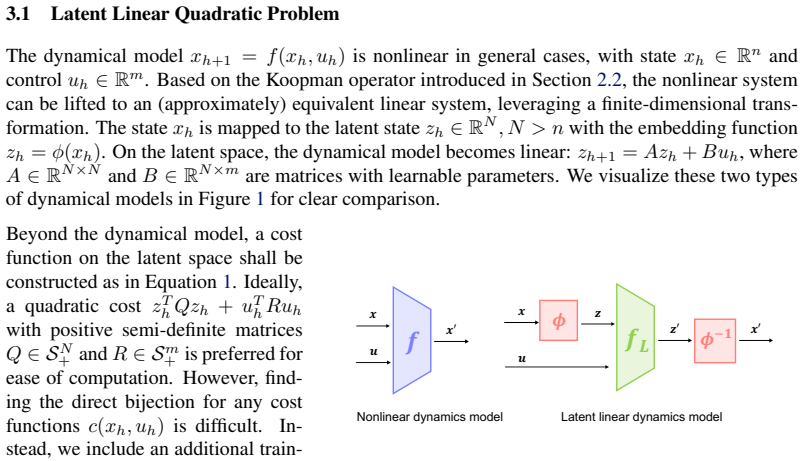
What carries the argument
A learned latent-space transformation that converts the original nonlinear dynamics into linear form and the original cost into quadratic form, allowing direct use of the LQR Riccati solution.
If this is right
- Real-time control becomes feasible on embedded processors that cannot solve nonlinear programs at control frequency.
- The same learned latent model can be reused across similar tasks without re-solving the original optimization each time.
- Policy execution cost scales linearly with state dimension rather than with the complexity of the nonlinear optimizer.
- Generalization to new initial conditions or mild environment changes improves because the latent LQR inherits the stability properties of the underlying linear system.
Where Pith is reading between the lines
- The same imitation objective could be applied to other optimal controllers besides MPC, turning any slow planner into a fast linear feedback law.
- If the latent space is low-dimensional, the method might also serve as a model-reduction technique for long-horizon planning.
- The learned latent coordinates could be inspected to discover which physical quantities the controller actually cares about.
Load-bearing premise
A latent mapping exists such that the transformed dynamics are exactly linear and the cost exactly quadratic, and imitation of MPC trajectories is enough to recover a useful version of that mapping.
What would settle it
On a held-out robotic task, collect trajectories from the original MPC and from LaLQR; if the latent dynamics deviate measurably from linearity or the closed-loop cost exceeds the MPC cost by more than a small margin while computation time remains lower, the claim is falsified.
Figures






read the original abstract
Model predictive control (MPC) has played a more crucial role in various robotic control tasks, but its high computational requirements are concerning, especially for nonlinear dynamical models. This paper presents a $\textbf{la}$tent $\textbf{l}$inear $\textbf{q}$uadratic $\textbf{r}$egulator (LaLQR) that maps the state space into a latent space, on which the dynamical model is linear and the cost function is quadratic, allowing the efficient application of LQR. We jointly learn this alternative system by imitating the original MPC. Experiments show LaLQR's superior efficiency and generalization compared to other baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LaLQR, a method that learns a mapping from the original state space to a latent space in which the system dynamics are linear and the cost is quadratic, enabling direct application of the LQR controller. The latent mapping and associated linear/quadratic model are learned jointly by imitating trajectories from an external nonlinear MPC solver. Experiments on robotic control tasks are reported to show improved computational efficiency and generalization relative to baselines.
Significance. If the learned latent model satisfies the exact LQR structural assumptions on held-out data and new initial conditions, the approach could offer a computationally lighter alternative to repeated nonlinear MPC solves while retaining model-based guarantees, which would be relevant for real-time robotic applications.
major comments (2)
- [Method (imitation procedure)] The central claim requires that a latent mapping exists such that dynamics are exactly linear (x_{t+1}=A x_t + B u_t) and cost exactly quadratic. The described procedure learns the mapping solely by imitating MPC trajectories; no explicit loss term, regularization, or post-hoc verification enforces or confirms linearity/quadraticity in the latent space on held-out trajectories or new initial conditions. This directly affects whether the subsequent LQR solve is exact or merely approximate.
- [Abstract and Experiments] The abstract and experimental claims assert superior efficiency and generalization, yet the provided description supplies no equations for the latent dynamics, no training protocol details, no error bars, and no explicit comparison of closed-loop performance under the LQR assumptions versus the original MPC. Without these, the data cannot be assessed for support of the claim.
minor comments (2)
- [Method] Notation for the latent state, matrices A/B/Q/R, and the imitation objective should be introduced with explicit equations rather than prose description only.
- [Abstract] The abstract would benefit from a one-sentence statement of the imitation loss and the LQR application step.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments on our manuscript. We address each of the major comments below, providing clarifications and indicating revisions where appropriate.
read point-by-point responses
-
Referee: [Method (imitation procedure)] The central claim requires that a latent mapping exists such that dynamics are exactly linear (x_{t+1}=A x_t + B u_t) and cost exactly quadratic. The described procedure learns the mapping solely by imitating MPC trajectories; no explicit loss term, regularization, or post-hoc verification enforces or confirms linearity/quadraticity in the latent space on held-out trajectories or new initial conditions. This directly affects whether the subsequent LQR solve is exact or merely approximate.
Authors: The LaLQR method parameterizes the latent dynamics as a linear system by design, with the mapping from original to latent space learned jointly via imitation of MPC trajectories. This ensures that the learned model approximates the LQR structure. However, we agree that explicit verification of the linearity assumption on held-out data would strengthen the claims. We will add post-hoc analysis and error metrics to confirm the degree of linearity and quadraticity on new trajectories and initial conditions. revision: yes
-
Referee: [Abstract and Experiments] The abstract and experimental claims assert superior efficiency and generalization, yet the provided description supplies no equations for the latent dynamics, no training protocol details, no error bars, and no explicit comparison of closed-loop performance under the LQR assumptions versus the original MPC. Without these, the data cannot be assessed for support of the claim.
Authors: The full manuscript provides the equations for the latent dynamics in Section 3, details the training protocol in Section 4, and includes experimental comparisons. That said, we acknowledge the abstract is brief and that error bars and more explicit closed-loop comparisons could be better emphasized. We will revise the experiments section to include error bars, add a direct comparison of closed-loop performance, and consider expanding the abstract if permitted. revision: partial
Circularity Check
No circularity: parameterized imitation learning with explicit LQ structure
full rationale
The paper defines LaLQR by jointly learning an encoder to a latent space together with linear dynamics and quadratic costs, using imitation of MPC trajectories as the training objective. The linear-quadratic structure is imposed directly by the model parameterization (not discovered or fitted post-hoc), and the resulting LQR controller is applied exactly on that structure. Performance claims rest on experimental comparisons of efficiency and generalization rather than any reduction of outputs to training inputs by definition. No self-citations, uniqueness theorems, or ansatzes are load-bearing; the derivation chain is self-contained as a standard behavioral cloning setup with architectural constraints.
Axiom & Free-Parameter Ledger
invented entities (1)
-
latent space
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Parametric Nonconvex Optimization via Convex Surrogates
A surrogate for parametric nonconvex optimization is constructed as the minimum of convex-monotonic function compositions and solved via parallel convex optimization, with a proof-of-concept on path tracking.
Reference graph
Works this paper leans on
-
[1]
J. Di Carlo, P. M. Wensing, B. Katz, G. Bledt, and S. Kim. Dynamic locomotion in the mit cheetah 3 through convex model-predictive control. In 2018 IEEE/RSJ International Confer- ence on Intelligent Robots and Systems (IROS) , pages 1–9, Madrid, Oct. 2018. IEEE. ISBN 978-1-5386-8094-0. doi:10.1109/IROS.2018.8594448
-
[2]
R. Grandia, F. Jenelten, S. Yang, F. Farshidian, and M. Hutter. Perceptive locomotion through nonlinear model-predictive control. IEEE Trans. Robotics , 39(5):3402–3421, 2023. doi:10. 1109/TRO.2023.3275384
-
[3]
TartanAir: A dataset to push the limits of visual SLAM,
Y . Song and D. Scaramuzza. Learning high-level policies for model predictive control. In 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages 7629–7636, Oct. 2020. doi:10.1109/IROS45743.2020.9340823
-
[4]
M. Diehl, H. J. Ferreau, and N. Haverbeke. Efficient numerical methods for nonlinear mpc and moving horizon estimation. In M. Morari, M. Thoma, L. Magni, D. M. Raimondo, and F. Allg ¨ower, editors, Nonlinear Model Predictive Control , volume 384, pages 391–417. Springer Berlin Heidelberg, Berlin, Heidelberg, 2009. ISBN 978-3-642-01093-4 978-3-642- 01094-1
work page 2009
-
[5]
J. Nocedal and S. J. Wright. Sequential quadratic programming. In Numerical Optimization, pages 526–573. Springer-Verlag, New York, 1999. ISBN 978-0-387-98793-4
work page 1999
-
[6]
Y .-S. Wang, N. Matni, and J. C. Doyle. Localized lqr optimal control. In53rd IEEE Conference on Decision and Control, pages 1661–1668. IEEE, 2014
work page 2014
-
[7]
B. D. Anderson and J. B. Moore. Optimal Control: Linear Quadratic Methods . Courier Corporation, 2007
work page 2007
-
[8]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, T. Jackson, S. Jesmonth, N. J. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, I. Leal, K.-H. Lee, S. Levine, Y . Lu, U. Malla, D. Manju- nath, I. Mordatch, O. Nachum, C. Parada, J. Peralta, E. Perez, K. Pertsc...
work page 2022
-
[9]
M. Korda and I. Mezi ´c. Linear predictors for nonlinear dynamical systems: Koopman operator meets model predictive control. Automatica, 93:149–160, 2018
work page 2018
-
[10]
P. J. Antsaklis and A. N. Michel. A Linear Systems Primer . Springer Science & Business Media, 2007
work page 2007
-
[11]
B. Lusch, J. N. Kutz, and S. L. Brunton. Deep learning for universal linear embeddings of nonlinear dynamics. Nature Communications, 9(1):4950, Nov. 2018. ISSN 2041-1723. doi: 10.1038/s41467-018-07210-0
-
[12]
A. K. Mondal, S. S. Panigrahi, S. Rajeswar, K. Siddiqi, and S. Ravanbakhsh. Efficient dynam- ics modeling in interactive environments with koopman theory. In The Twelfth International Conference on Learning Representations, 2024. 10
work page 2024
- [13]
-
[14]
Y . Tang, Z. D. Guo, P. H. Richemond, B. A. Pires, Y . Chandak, R. Munos, M. Rowland, M. G. Azar, C. L. Lan, C. Lyle, A. Gy ¨orgy, S. Thakoor, W. Dabney, B. Piot, D. Calandriello, and M. Valko. Understanding self-predictive learning for reinforcement learning. In Proceedings of the 40th International Conference on Machine Learning , pages 33632–33656. PML...
work page 2023
-
[15]
E. Todorov, T. Erez, and Y . Tassa. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems , pages 5026– 5033, Vilamoura-Algarve, Portugal, Oct. 2012. IEEE. ISBN 978-1-4673-1736-8 978-1-4673- 1737-5 978-1-4673-1735-1. doi:10.1109/IROS.2012.6386109
-
[16]
Y . Tassa, T. Erez, and E. Todorov. Synthesis and stabilization of complex behaviors through on- line trajectory optimization. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 4906–4913, Oct. 2012. doi:10.1109/IROS.2012.6386025
-
[17]
M. O. Williams, I. G. Kevrekidis, and C. W. Rowley. A data–driven approximation of the koopman operator: Extending dynamic mode decomposition. Journal of Nonlinear Science , 25(6):1307–1346, Dec. 2015. ISSN 0938-8974, 1432-1467. doi:10.1007/s00332-015-9258-5
-
[18]
D. Gadginmath, V . Krishnan, and F. Pasqualetti. Data-driven feedback linearization using the koopman generator. CoRR, abs/2210.05046, 2022. doi:10.48550/ARXIV .2210.05046
work page internal anchor Pith review doi:10.48550/arxiv 2022
- [19]
-
[20]
Dream to Control: Learning Behaviors by Latent Imagination
D. Hafner, T. Lillicrap, J. Ba, and M. Norouzi. Dream to control: Learning behaviors by latent imagination. arXiv:1912.01603 [cs], Mar. 2020
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[21]
N. A. Hansen, H. Su, and X. Wang. Temporal difference learning for model predictive control. In Proceedings of the 39th International Conference on Machine Learning , pages 8387–8406. PMLR, June 2022
work page 2022
-
[22]
H. Yin, M. C. Welle, and D. Kragic. Embedding koopman optimal control in robot pol- icy learning. In 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 13392–13399, Kyoto, Japan, Oct. 2022. IEEE. ISBN 978-1-66547-927-1. doi: 10.1109/IROS47612.2022.9981540
-
[23]
M. Retchin, B. Amos, S. Brunton, and S. Song. Koopman constrained policy optimization: A koopman operator theoretic method for differentiable optimal control in robotics. In ICML 2023 Workshop on Differentiable Almost Everything: Differentiable Relaxations, Algorithms, Operators, and Simulators, Sept. 2023
work page 2023
-
[24]
T. Ni, B. Eysenbach, E. SeyedSalehi, M. Ma, C. Gehring, A. Mahajan, and P.-L. Bacon. Bridg- ing state and history representations: Understanding self-predictive rl. In The Twelfth Interna- tional Conference on Learning Representations , Oct. 2023
work page 2023
-
[25]
X. B. Peng, M. Andrychowicz, W. Zaremba, and P. Abbeel. Sim-to-real transfer of robotic control with dynamics randomization. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pages 3803–3810, May 2018. doi:10.1109/ICRA.2018.8460528
- [26]
- [27]
-
[28]
I. Loshchilov and F. Hutter. Decoupled weight decay regularization. In International Confer- ence on Learning Representations, Sept. 2018. 12 A Additional Algorithm Details Algorithm 1 MPC Imitation Learning 1: Input: Nonlinear MPC’s dynamical modelf(xh, uh), cost function c(xh, uh) and optimization algorithm to generate optimal control uh = MPC(xh), init...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.