MolReFlect: Towards In-Context Fine-grained Alignments between Molecules and Texts
Pith reviewed 2026-05-23 16:43 UTC · model grok-4.3
The pith
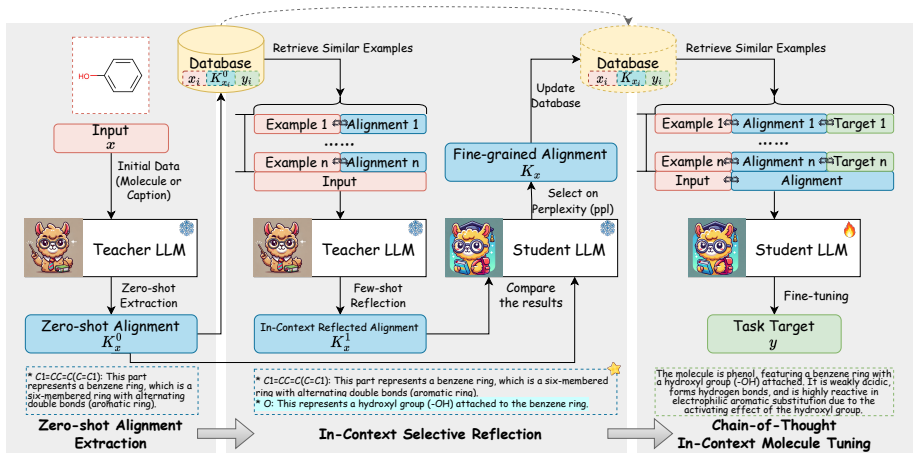
MolReFlect uses a teacher LLM to generate and refine mappings between SMILES substructures and caption phrases, then teaches them to a student LLM.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MolReFlect is a teacher-student framework where a teacher LLM first generates and refines mappings between caption phrases and SMILES substructures and then explicitly teaches these detailed alignments to a student LLM, enabling significantly better performance than prior baselines on the molecule-caption translation task.
What carries the argument
The teacher-student framework that automatically generates and teaches fine-grained alignments between caption phrases and SMILES substructures.
If this is right
- LLMs reach state-of-the-art results on molecule-caption translation tasks.
- Models gain the ability to reason about molecules at the substructure level with explicit textual links.
- Explainability improves because the model can point to which parts of a molecule correspond to which parts of its description.
- The need for costly expert-labeled fine-grained alignment data is removed.
Where Pith is reading between the lines
- The same teacher-student pattern could be tested on other sequence-to-text tasks such as protein function descriptions or material property captions.
- If the generated alignments prove stable across different teacher models, the method could be used to bootstrap large-scale alignment datasets for training smaller specialized models.
- Explicit substructure teaching may reduce hallucinated chemical claims in LLM outputs by grounding each phrase to a verifiable molecular fragment.
Load-bearing premise
The teacher LLM can generate and refine accurate, useful mappings between caption phrases and SMILES substructures without expert human annotation or verification.
What would settle it
A review by domain experts that finds most of the automatically generated phrase-to-substructure mappings to be chemically incorrect or unhelpful would show the framework does not produce reliable alignments.
Figures











read the original abstract
Molecule discovery is a pivotal research field, impacting everything from medicine to materials. Recently, Large Language Models (LLMs) have been widely adopted in molecular understanding and generation, serving as a bridge between the molecular space and the natural language space, yet the alignment between molecules and their corresponding captions remains a significant challenge. Previous endeavors typically treat molecules as monolithic inputs, lacking an intermediate reasoning process and sacrificing explainability. In this work, we define fine-grained alignments as the precise correspondence between a molecule's sub-structures and the textual phrases that explain their properties. These alignments are crucial for LLMs to understand molecules in a more accurate and explainable manner. Normally, such fine-grained alignments require expert annotation, which is both costly and time-consuming. To allow LLMs to automatically label and learn the fine-grained alignments, we propose MolReFlect, a novel teacher-student framework, where a teacher LLM first generates and refines mappings between caption phrases and SMILES substructures and then explicitly teaches these detailed alignments to a student LLM. Experimental results demonstrate that MolReFlect enables LLMs to significantly outperform previous baselines, achieving the state-of-the-art performance in the molecule-caption translation task. Our codes are available via: https://github.com/phenixace/MolReFlect.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MolReFlect, a teacher-student framework in which a teacher LLM automatically generates and refines mappings between textual phrases in molecule captions and substructures in SMILES strings; these mappings are then used to explicitly teach fine-grained alignments to a student LLM. The central claim is that this procedure yields state-of-the-art performance on the molecule-caption translation task without requiring expert human annotation.
Significance. If the teacher-generated alignments prove accurate and causally responsible for the reported gains, the method could improve both performance and explainability in molecular LLMs. The absence of any validation of the teacher outputs, however, leaves the significance of the empirical result unclear.
major comments (2)
- [Abstract] Abstract: the claim of 'state-of-the-art performance' is asserted without any reported metrics, baselines, dataset sizes, or ablation results, preventing verification of the central empirical claim.
- [Method] Method section (teacher-student framework): the load-bearing assumption that the teacher LLM produces accurate phrase-to-SMILES-substructure mappings is unsupported by any human validation, inter-annotator agreement, or proxy metric on a held-out set; without this, performance deltas cannot be attributed to fine-grained alignment rather than prompt length, extra examples, or other confounds.
minor comments (1)
- The GitHub link is given but no statement confirms that the released code reproduces the exact experimental pipeline and teacher prompts used in the paper.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We agree that the abstract should be more self-contained with quantitative results and that explicit validation of the teacher-generated alignments is needed to strengthen causal attribution. We will make both changes in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'state-of-the-art performance' is asserted without any reported metrics, baselines, dataset sizes, or ablation results, preventing verification of the central empirical claim.
Authors: We agree that the abstract as submitted does not contain the supporting numbers. In the revised version we will expand the abstract to report the primary metrics (BLEU-2/4, ROUGE-L, METEOR), the two evaluation datasets with their sizes, the main baselines, and a one-sentence summary of the ablation results that isolate the contribution of the fine-grained alignments. These numbers already appear in the experimental section; the revision will simply surface them in the abstract. revision: yes
-
Referee: [Method] Method section (teacher-student framework): the load-bearing assumption that the teacher LLM produces accurate phrase-to-SMILES-substructure mappings is unsupported by any human validation, inter-annotator agreement, or proxy metric on a held-out set; without this, performance deltas cannot be attributed to fine-grained alignment rather than prompt length, extra examples, or other confounds.
Authors: We acknowledge that the original submission provides no direct validation of the teacher mappings. To address this, the revision will include (1) a human evaluation on a random sample of 200 teacher-generated alignments with inter-annotator agreement statistics, and (2) an ablation that compares the full teacher-student pipeline against a control that supplies the same number of additional tokens but without the phrase-to-substructure mappings. These additions will allow readers to assess both the quality of the teacher outputs and the extent to which the observed gains are attributable to the fine-grained alignments rather than length or example count. revision: yes
Circularity Check
No circularity: framework is an independent procedural proposal
full rationale
The paper describes a teacher-student LLM framework for generating phrase-SMILES mappings and reports experimental SOTA results on translation. No equations, fitted parameters, predictions derived from inputs, uniqueness theorems, or self-citations appear in the provided text. The central claim rests on empirical outcomes and the external assumption that the teacher produces accurate mappings, which is not reduced to the paper's own definitions or prior outputs by construction. This matches the default expectation of a non-circular methodological contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An LLM prompted as teacher can generate and refine accurate mappings between textual phrases and SMILES substructures
Forward citations
Cited by 2 Pith papers
-
Speak-to-Structure: Evaluating LLMs in Open-domain Natural Language-Driven Molecule Generation
S^2-Bench is a new one-to-many benchmark for natural language-driven molecule generation with three tasks, and OpenMolIns is an instruction dataset enabling Llama3.1-8B to outperform GPT-4o and Claude-3.5 on it.
-
Mol-Debate: Multi-Agent Debate Improves Structural Reasoning in Molecular Design
Mol-Debate applies multi-agent debate in an iterative loop with perspective orchestration to achieve state-of-the-art text-guided molecular design, scoring 59.82% exact match on ChEBI-20 and 50.52% weighted success on...
Reference graph
Works this paper leans on
-
[1]
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type volume year eprint doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRINGS urlintro eprinturl eprintpr...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Pervin Basaran and Emilio Rodr \' guez-Cerezo. 2008. Plant molecular farming: opportunities and challenges. Critical reviews in biotechnology, 28(3):153--172
work page 2008
-
[5]
Yanda Chen, Ruiqi Zhong, Sheng Zha, George Karypis, and He He. 2022. Meta-learning via language model in-context tuning. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 719--730
work page 2022
- [6]
-
[7]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Carl Edwards, Tuan Lai, Kevin Ros, Garrett Honke, Kyunghyun Cho, and Heng Ji. 2022. https://aclanthology.org/2022.emnlp-main.26 Translation between molecules and natural language . In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 375--413, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics
work page 2022
-
[9]
Carl Edwards, ChengXiang Zhai, and Heng Ji. 2021. Text2mol: Cross-modal molecule retrieval with natural language queries. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 595--607
work page 2021
-
[10]
Chemical language models have problems with chemistry: A case study on molecule captioning task
Veronika Ganeeva, Kuzma Khrabrov, Artur Kadurin, Andrey Savchenko, and Elena Tutubalina. Chemical language models have problems with chemistry: A case study on molecule captioning task. In The Second Tiny Papers Track at ICLR 2024
work page 2024
-
[11]
Christina M Grozinger and Stuart L Schreiber. 2002. Deacetylase enzymes: biological functions and the use of small-molecule inhibitors. Chemistry & biology, 9(1):3--16
work page 2002
-
[12]
Akon Higuchi, Tzu-Cheng Sung, Ting Wang, Qing-Dong Ling, S Suresh Kumar, Shih-Tien Hsu, and Akihiro Umezawa. 2023. Material design for next-generation mrna vaccines using lipid nanoparticles. Polymer Reviews, 63(2):394--436
work page 2023
-
[13]
Edward J Hu, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. 2021. Lora: Low-rank adaptation of large language models. In International Conference on Learning Representations
work page 2021
-
[14]
Ross Irwin, Spyridon Dimitriadis, Jiazhen He, and Esben Jannik Bjerrum. 2022. Chemformer: a pre-trained transformer for computational chemistry. Machine Learning: Science and Technology, 3(1):015022
work page 2022
-
[15]
Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. 2023. Mistral 7b. arXiv preprint arXiv:2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Michael J Keiser, John J Irwin, and Brian K Shoichet. 2010. The chemical basis of pharmacology. Biochemistry, 49(48):10267--10276
work page 2010
-
[17]
Leszek Konieczny, Irena Roterman-Konieczna, and Pawe Sp \'o lnik. 2023. The structure and function of living organisms. In Systems Biology: Functional Strategies of Living Organisms, pages 1--52. Springer
work page 2023
-
[18]
Mario Krenn, Florian H \"a se, AkshatKumar Nigam, Pascal Friederich, and Alan Aspuru-Guzik. 2020. Self-referencing embedded strings (selfies): A 100\ Machine Learning: Science and Technology, 1(4):045024
work page 2020
-
[19]
Greg Landrum. 2013. Rdkit documentation. Release, 1(1-79):4
work page 2013
- [20]
- [21]
-
[22]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023 b . Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [23]
- [24]
-
[25]
Zhiyuan Liu, Sihang Li, Yanchen Luo, Hao Fei, Yixin Cao, Kenji Kawaguchi, Xiang Wang, and Tat-Seng Chua. 2023. Molca: Molecular graph-language modeling with cross-modal projector and uni-modal adapter. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 15623--15638
work page 2023
-
[26]
Van-Thuan Nguyen, Young Seop Kwon, and Man Bock Gu. 2017. Aptamer-based environmental biosensors for small molecule contaminants. Current opinion in biotechnology, 45:15--23
work page 2017
-
[27]
Qizhi Pei, Wei Zhang, Jinhua Zhu, Kehan Wu, Kaiyuan Gao, Lijun Wu, Yingce Xia, and Rui Yan. 2023. Biot5: Enriching cross-modal integration in biology with chemical knowledge and natural language associations. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 1102--1123
work page 2023
- [28]
-
[29]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748--8763. PMLR
work page 2021
-
[30]
Fran c isco M Raymo and Silvia Giordani. 2001. Signal processing at the molecular level. Journal of the American Chemical Society, 123(19):4651--4652
work page 2001
-
[31]
Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982--3992
work page 2019
-
[32]
Stephen Robertson, Hugo Zaragoza, et al. 2009. The probabilistic relevance framework: Bm25 and beyond. Foundations and Trends in Information Retrieval , 3(4):333--389
work page 2009
- [33]
-
[34]
Ross Taylor, Marcin Kardas, Guillem Cucurull, Thomas Scialom, Anthony Hartshorn, Elvis Saravia, Andrew Poulton, Viktor Kerkez, and Robert Stojnic. 2022. Galactica: A large language model for science. arXiv preprint arXiv:2211.09085
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
Richard M Twyman, Eva Stoger, Stefan Schillberg, Paul Christou, and Rainer Fischer. 2003. Molecular farming in plants: host systems and expression technology. TRENDS in Biotechnology, 21(12):570--578
work page 2003
-
[36]
Athanasios Valavanidis, Thomais Vlahogianni, Manos Dassenakis, and Michael Scoullos. 2006. Molecular biomarkers of oxidative stress in aquatic organisms in relation to toxic environmental pollutants. Ecotoxicology and environmental safety, 64(2):178--189
work page 2006
-
[37]
Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. 2021. Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[38]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824--24837
work page 2022
-
[39]
David Weininger. 1988. Smiles, a chemical language and information system. 1. introduction to methodology and encoding rules. Journal of chemical information and computer sciences, 28(1):31--36
work page 1988
-
[40]
Zhenqin Wu, Bharath Ramsundar, Evan N Feinberg, Joseph Gomes, Caleb Geniesse, Aneesh S Pappu, Karl Leswing, and Vijay Pande. 2018. Moleculenet: a benchmark for molecular machine learning. Chemical science, 9(2):513--530
work page 2018
-
[41]
Jun Xia, Chengshuai Zhao, Bozhen Hu, Zhangyang Gao, Cheng Tan, Yue Liu, Siyuan Li, and Stan Z Li. 2022. Mole-bert: Rethinking pre-training graph neural networks for molecules. In The Eleventh International Conference on Learning Representations
work page 2022
- [42]
- [43]
- [44]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.