Condense, Don't Just Prune: Enhancing Efficiency and Performance in MoE Layer Pruning
Pith reviewed 2026-05-23 17:06 UTC · model grok-4.3
The pith
Condensing fine-grained MoE layers into smaller dense layers with few experts keeps 90% accuracy while cutting memory 27.5% and raising speed 1.26 times.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that, for fine-grained MoE models containing shared experts, a large sparse MoE layer can be replaced by a compact dense layer built from only a few of its experts without destroying the model's overall capacity or the specialization that the original experts provided, thereby delivering substantial memory and latency gains while preserving most downstream accuracy.
What carries the argument
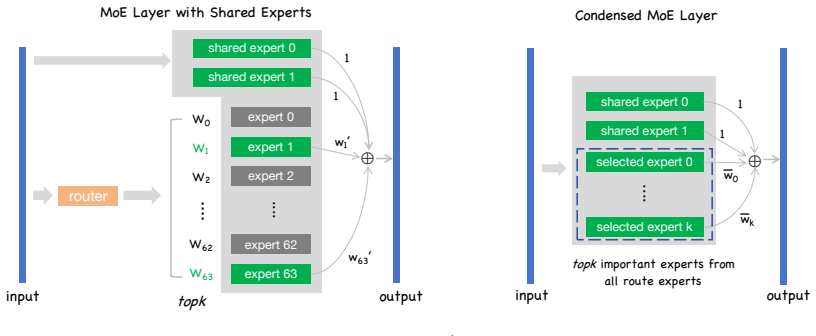
ConDense-MoE (CD-MoE) condensation step that converts a fine-grained MoE layer with shared experts into a smaller dense layer where a reduced set of experts processes every token.
If this is right
- DeepSeekMoE-16B achieves 27.5% lower memory use and 1.26 times higher inference speed at 90% retained accuracy.
- Lightweight fine-tuning restricted to the condensed layers restores performance to 98% of the original model.
- The same condensation procedure applies directly to other fine-grained MoE models that employ shared experts, such as QwenMoE.
- The resulting models remain hardware-friendly because the condensed layers are ordinary dense layers rather than sparse routing structures.
Where Pith is reading between the lines
- The approach may extend to other sparse activation patterns beyond MoE if the underlying redundancy among experts is comparable.
- Combining condensation with post-training quantization could produce further memory reductions while preserving the reported speed gains.
- The method implies that expert specialization in fine-grained MoE is sufficiently redundant that a small fixed subset can approximate the full routing behavior for many tokens.
Load-bearing premise
A smaller dense layer assembled from a few of the original experts can retain enough of the capacity and specialization present in the full sparse MoE layer.
What would settle it
Measure average accuracy on the same benchmark suite for DeepSeekMoE-16B after condensation without any fine-tuning; if it falls below 90% of the unpruned baseline the central claim is falsified.
Figures





read the original abstract
Mixture-of-Experts (MoE) has garnered significant attention for its ability to scale up neural networks while utilizing the same or even fewer active parameters. However, MoE does not alleviate the massive memory requirements of networks, which limits their practicality in real-world applications, especially in the era of large language models (LLMs). While recent work explores the possibility of removing entire layers of MoE to reduce memory, the performance degradation is still notable. In this paper, we propose ConDense-MoE (CD-MoE), which, instead of dropping the entire MoE layer, condenses the large, sparse MoE layer into a smaller, denser layer with only a few experts activated for all tokens, while maintaining hardware friendliness. Our approach is specifically designed for fine-grained MoE with shared experts, where Feed-Forward Networks are split into many small experts, with certain experts isolated to serve as shared experts that are always activated, such as DeepSeekMoE and QwenMoE. We demonstrate the effectiveness of our method. Specifically, for the DeepSeekMoE-16B model, our approach maintains 90% of the average accuracy while reducing memory usage by 27.5% and increasing inference speed by 1.26 times. Moreover, we show that by applying lightweight expert fine-tuning -- only to the condensed layers -- and using 5 hours on a single 80G A100 GPU, we can successfully recover 98% of the original performance. Our code is available at: https://github.com/duterscmy/CD-MoE/tree/main.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ConDense-MoE (CD-MoE), a condensation technique that replaces entire sparse MoE layers (in fine-grained architectures with shared experts, such as DeepSeekMoE) by smaller dense layers in which only a few experts remain active for all tokens. On DeepSeekMoE-16B the method is reported to retain 90 % of average accuracy while cutting memory by 27.5 % and raising inference speed by 1.26×; a subsequent lightweight fine-tuning step performed only on the condensed layers recovers 98 % of original performance after 5 h on a single 80 GB A100. The accompanying code release is explicitly noted.
Significance. If the reported numbers hold under the experimental protocol described in the full manuscript, the work supplies a concrete, hardware-friendly route to memory reduction in production-scale MoE LLMs that avoids the larger accuracy drop typical of layer-pruning baselines. The limited-scope fine-tuning protocol and public code constitute reproducible assets that lower the barrier for follow-up studies on efficient MoE deployment.
major comments (2)
- [§4, Table 2] §4 (Experiments), Table 2: the 90 % accuracy retention figure is presented without an accompanying per-task breakdown or variance across random seeds; because the central claim rests on this aggregate number, the absence of these controls makes it impossible to judge whether the result is robust or driven by a subset of easy tasks.
- [§3.2] §3.2 (Condensation procedure): the mapping from the original expert set to the condensed dense layer is described at a high level but the precise selection criterion for the retained experts and the handling of the shared-expert weights are not given by an equation or algorithm box; this detail is load-bearing for any attempt to verify that capacity is preserved without full retraining.
minor comments (2)
- [Abstract] The abstract states numerical outcomes but supplies no reference to the exact evaluation suite or baseline implementations; a single sentence pointing to the experimental section would improve clarity.
- [Figure 3] Figure 3 caption does not indicate whether the plotted latency numbers include the cost of the lightweight fine-tuning step or only the final inference pass.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the recommendation of minor revision. The comments highlight useful ways to strengthen the presentation of results and the reproducibility of the method. We address each point below.
read point-by-point responses
-
Referee: [§4, Table 2] §4 (Experiments), Table 2: the 90 % accuracy retention figure is presented without an accompanying per-task breakdown or variance across random seeds; because the central claim rests on this aggregate number, the absence of these controls makes it impossible to judge whether the result is robust or driven by a subset of easy tasks.
Authors: We agree that a per-task breakdown and variance across seeds would strengthen the central claim. In the revised manuscript we will expand Table 2 to report per-task accuracies for all evaluated benchmarks and will add standard deviations computed over three random seeds for the key CD-MoE configurations. These additions will make it possible to verify that the 90 % average retention is not driven by a subset of tasks. revision: yes
-
Referee: [§3.2] §3.2 (Condensation procedure): the mapping from the original expert set to the condensed dense layer is described at a high level but the precise selection criterion for the retained experts and the handling of the shared-expert weights are not given by an equation or algorithm box; this detail is load-bearing for any attempt to verify that capacity is preserved without full retraining.
Authors: We accept that the condensation procedure would be easier to verify with a formal specification. In the revision we will insert an algorithm box together with the explicit equations that define (i) the expert-selection criterion (top-k experts by activation frequency on a small calibration set, combined with an importance score derived from weight norms) and (ii) the exact merging of shared-expert weights into the condensed dense layer. The released code already implements these steps; the added formalization will make the paper self-contained. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical condensation method (CD-MoE) for fine-grained MoE layers and reports direct performance measurements on DeepSeekMoE-16B (90% accuracy retention pre-fine-tuning, 98% post, with measured memory/speed gains). No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text; the central claims rest on experimental results and released code rather than any reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
SlimQwen: Exploring the Pruning and Distillation in Large MoE Model Pre-training
Pruning pretrained MoE models outperforms training from scratch, different compression methods converge after continued pretraining, and combining KD with language modeling loss plus progressive schedules yields a com...
-
SlimQwen: Exploring the Pruning and Distillation in Large MoE Model Pre-training
Pruning pretrained MoE models outperforms training from scratch under fixed budget, different expert compression methods converge after continued training, and progressive pruning plus multi-token KD improves the fina...
Reference graph
Works this paper leans on
-
[1]
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
- [3]
-
[4]
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. 2019. https://arxiv.org/abs/1911.11641 Piqa: Reasoning about physical commonsense in natural language . Preprint, arXiv:1911.11641
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[5]
Tom B Brown. 2020. Language models are few-shot learners. arXiv preprint arXiv:2005.14165
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[6]
Zewen Chi, Li Dong, Shaohan Huang, Damai Dai, Shuming Ma, Barun Patra, Saksham Singhal, Payal Bajaj, Xia Song, Xian-Ling Mao, Heyan Huang, and Furu Wei. 2022. https://arxiv.org/abs/2204.09179 On the representation collapse of sparse mixture of experts . Preprint, arXiv:2204.09179
-
[7]
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. 2019 a . https://arxiv.org/abs/1905.10044 Boolq: Exploring the surprising difficulty of natural yes/no questions . Preprint, arXiv:1905.10044
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[8]
Kevin Clark, Urvashi Khandelwal, Omer Levy, and Christopher D. Manning. 2019 b . https://arxiv.org/abs/1906.04341 What does bert look at? an analysis of bert's attention . Preprint, arXiv:1906.04341
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[9]
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. https://arxiv.org/abs/1803.05457 Think you have solved question answering? try arc, the ai2 reasoning challenge . Preprint, arXiv:1803.05457
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[10]
Ido Dagan, Oren Glickman, and Bernardo Magnini. 2005. The pascal recognizing textual entailment challenge. In Proceedings of the PASCAL Challenges Workshop on Recognizing Textual Entailment
work page 2005
-
[11]
Damai Dai, Chengqi Deng, Chenggang Zhao, R. X. Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y. Wu, Zhenda Xie, Y. K. Li, Panpan Huang, Fuli Luo, Chong Ruan, Zhifang Sui, and Wenfeng Liang. 2024. https://arxiv.org/abs/2401.06066 Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models . CoRR, abs/2401.06066
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. https://arxiv.org/abs/2101.03961 Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity . Preprint, arXiv:2101.03961
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [13]
-
[14]
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. 2020. The pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[15]
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac'h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. 2024. https...
- [16]
-
[17]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. https://arxiv.org/abs/2009.03300 Measuring massive multitask language understanding . Preprint, arXiv:2009.03300
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[18]
Bruce M Hill. 1975. A simple general approach to inference about the tail of a distribution. The annals of statistics, pages 1163--1174
work page 1975
-
[20]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven...
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [21]
- [22]
-
[23]
Charles H Martin and Michael W Mahoney. 2019. Traditional and heavy-tailed self regularization in neural network models. arXiv preprint arXiv:1901.08276
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[24]
Charles H Martin and Michael W Mahoney. 2020. Heavy-tailed universality predicts trends in test accuracies for very large pre-trained deep neural networks. In Proceedings of the 2020 SIAM International Conference on Data Mining, pages 505--513. SIAM
work page 2020
-
[25]
Charles H Martin and Michael W Mahoney. 2021. Implicit self-regularization in deep neural networks: Evidence from random matrix theory and implications for learning. Journal of Machine Learning Research, 22(165):1--73
work page 2021
- [26]
-
[27]
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. 2018. https://doi.org/10.18653/v1/D18-1260 Can a suit of armor conduct electricity? a new dataset for open book question answering . In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2381--2391, Brussels, Belgium. Association for Computational Li...
- [28]
-
[29]
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
Ofir Press, Noah A. Smith, and Mike Lewis. 2022. https://arxiv.org/abs/2108.12409 Train short, test long: Attention with linear biases enables input length extrapolation . Preprint, arXiv:2108.12409
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2019. https://arxiv.org/abs/1907.10641 Winogrande: An adversarial winograd schema challenge at scale . Preprint, arXiv:1907.10641
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[31]
Victor Sanh, Thomas Wolf, and Alexander Rush. 2020. Movement pruning: Adaptive sparsity by fine-tuning. Advances in neural information processing systems, 33:20378--20389
work page 2020
-
[32]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 2017. https://arxiv.org/abs/1701.06538 Outrageously large neural networks: The sparsely-gated mixture-of-experts layer . Preprint, arXiv:1701.06538
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [33]
-
[34]
A Simple and Effective Pruning Approach for Large Language Models
Mingjie Sun, Zhuang Liu, Anna Bair, and J. Zico Kolter. 2024. https://arxiv.org/abs/2306.11695 A simple and effective pruning approach for large language models . Preprint, arXiv:2306.11695
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Gemini Team, M Reid, N Savinov, D Teplyashin, Lepikhin Dmitry, T Lillicrap, JB Alayrac, R Soricut, A Lazaridou, O Firat, et al. 2024. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. in arxiv [cs. cl]. arxiv
work page 2024
-
[36]
Qwen Team. 2024. https://qwenlm.github.io/blog/qwen-moe/ Qwen1.5-moe: Matching 7b model performance with 1/3 activated parameters"
work page 2024
-
[38]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023 b . https://arxiv.org/abs/2302.13971 Llama: Open and efficient foundation language models . Preprint, arXiv:2302.13971
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Xuanzhe Xiao, Zeng Li, Chuanlong Xie, and Fengwei Zhou. 2023. Heavy-tailed regularization of weight matrices in deep neural networks. In International Conference on Artificial Neural Networks, pages 236--247. Springer
work page 2023
-
[40]
Yaoqing Yang, Ryan Theisen, Liam Hodgkinson, Joseph E Gonzalez, Kannan Ramchandran, Charles H Martin, and Michael W Mahoney. 2023. Test accuracy vs. generalization gap: Model selection in nlp without accessing training or testing data. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 3011--3021
work page 2023
-
[41]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. https://arxiv.org/abs/1905.07830 Hellaswag: Can a machine really finish your sentence? Preprint, arXiv:1905.07830
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[42]
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, Todor Mihaylov, Myle Ott, Sam Shleifer, Kurt Shuster, Daniel Simig, Punit Singh Koura, Anjali Sridhar, Tianlu Wang, and Luke Zettlemoyer. 2022. https://arxiv.org/abs/2205.01068 Opt: Open pre-trained transformer language...
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [43]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.