OctoTools: An Agentic Framework with Extensible Tools for Complex Reasoning
Pith reviewed 2026-05-23 02:36 UTC · model grok-4.3
The pith
OctoTools uses standardized tool cards plus a planner-executor split to raise accuracy 9.3 percent over GPT-4o on 16 tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
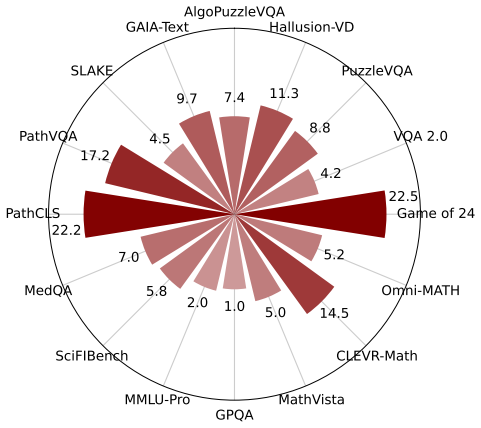
OctoTools is a training-free multi-agent framework that introduces standardized tool cards to encapsulate tool functionality, a planner for high-level and low-level planning, and an executor to carry out tool usage. Validated across 16 diverse tasks including MathVista, MMLU-Pro, MedQA, and GAIA-Text, the system achieves an average accuracy gain of 9.3 percent over GPT-4o and outperforms AutoGen, GPT-Functions, and LangChain by up to 10.6 percent when given the same tools. Ablations and tests with compact backbones and noisy tool environments show advantages in task planning, tool usage, and multi-step solving.
What carries the argument
Standardized tool cards that encapsulate each tool's functionality, inputs, and outputs, used by a planner for high-level and low-level plans and an executor that calls the tools.
If this is right
- The same set of tools produces higher accuracy than AutoGen, GPT-Functions, or LangChain on the tested tasks.
- Performance gains hold when using compact model backbones or when tool outputs contain noise.
- The framework can be extended to new tools simply by adding new standardized cards without retraining.
- Gains arise from improved task planning and effective multi-step tool selection rather than other factors.
- The design supports visual, numerical, knowledge-retrieval, and reasoning tasks within one system.
Where Pith is reading between the lines
- The card format could be adopted by other agent systems to reduce the engineering needed for new domains.
- Public release of the code allows direct testing on additional task types such as code synthesis or scientific hypothesis generation.
- If the planning-execution split remains effective at larger scale, it could influence how future agent designs allocate responsibilities between components.
- One could measure whether adding cards for highly specialized tools preserves the average gains without extra tuning.
Load-bearing premise
The standardized tool cards and planner-executor design can be applied across 16 unrelated domains without domain-specific engineering or post-hoc adjustments to the evaluation protocol.
What would settle it
A new complex reasoning task outside the 16 tested domains where OctoTools requires custom tool cards or fails to show the reported accuracy gains over the base model without adjustments would challenge the claim.
Figures















read the original abstract
Solving complex reasoning tasks may involve visual understanding, domain knowledge retrieval, numerical calculation, and multi-step reasoning. Existing methods augment large language models (LLMs) with external tools but are restricted to specialized domains, limited tool types, or require additional training data. In this paper, we introduce OctoTools, a training-free, user-friendly, and easily extensible multi-agent framework designed to tackle complex reasoning across diverse domains. OctoTools introduces standardized tool cards to encapsulate tool functionality, a planner for both high-level and low-level planning, and an executor to carry out tool usage. We validate OctoTools' generality across 16 diverse tasks (including MathVista, MMLU-Pro, MedQA, and GAIA-Text), achieving substantial average accuracy gains of 9.3% over GPT-4o. Furthermore, OctoTools also outperforms AutoGen, GPT-Functions, and LangChain by up to 10.6% when given the same set of tools. Through comprehensive analysi, ablations, and robustness tests with compact backbones and noisy tool environments, OctoTools demonstrates advantages in task planning, effective tool usage, and multi-step problem solving. Code, demos, and visualization are publicly available at https://octotools.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents OctoTools, a training-free multi-agent framework using standardized tool cards, a planner for high- and low-level planning, and an executor for tool calls. It claims this design enables complex reasoning across 16 diverse tasks (MathVista, MMLU-Pro, MedQA, GAIA-Text, etc.), delivering a 9.3% average accuracy improvement over GPT-4o and up to 10.6% gains over AutoGen, GPT-Functions, and LangChain when using identical tools. The work includes ablations, robustness tests with compact models and noisy environments, and releases code and demos.
Significance. If the empirical gains prove robust, the framework offers a practical, extensible approach to tool-augmented reasoning that avoids per-task training. Public release of code, demos, and visualizations is a clear strength that supports reproducibility.
major comments (3)
- [Abstract] Abstract: The headline 9.3% average accuracy gain over GPT-4o is reported only in aggregate form with no per-task accuracy table, error bars, or statistical tests. Without these, it is impossible to determine whether gains are consistent across domains or driven by a subset of the 16 tasks.
- [§3] §3 (Tool Cards and Planner-Executor Design): The claim that standardized tool cards require no domain-specific engineering is central to the generality argument, yet the manuscript supplies no explicit protocol or examples showing how cards for MedQA (domain knowledge) were constructed identically to those for MathVista (visual reasoning) without task-specific examples or adjustments.
- [Evaluation] Evaluation section: The paper does not describe whether tool outputs were manually verified, how tasks were selected, or whether the 16-task suite was finalized before or after observing performance, leaving open the possibility of post-hoc selection bias in the reported averages.
minor comments (2)
- [Abstract] Abstract contains a typo: 'comprehensive analysi' should be 'comprehensive analysis'.
- [§3] Notation for tool-card format is introduced without a clear running example that readers can follow across sections.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where revisions will be made to improve clarity and transparency.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline 9.3% average accuracy gain over GPT-4o is reported only in aggregate form with no per-task accuracy table, error bars, or statistical tests. Without these, it is impossible to determine whether gains are consistent across domains or driven by a subset of the 16 tasks.
Authors: We agree that presenting only the aggregate figure in the abstract limits interpretability. The full manuscript contains per-task results in the evaluation tables, but we will revise the abstract to reference these and add a consolidated per-task accuracy table (with standard deviations from repeated runs where available) plus a note on statistical significance testing in the revised version. revision: yes
-
Referee: [§3] §3 (Tool Cards and Planner-Executor Design): The claim that standardized tool cards require no domain-specific engineering is central to the generality argument, yet the manuscript supplies no explicit protocol or examples showing how cards for MedQA (domain knowledge) were constructed identically to those for MathVista (visual reasoning) without task-specific examples or adjustments.
Authors: We will add an appendix providing the explicit construction protocol for tool cards, including side-by-side examples for a MedQA knowledge-retrieval card and a MathVista visual-reasoning card. This will demonstrate that the process relies only on the tool's documented interface and does not incorporate task-specific examples or adjustments beyond the tool's core functionality. revision: yes
-
Referee: [Evaluation] Evaluation section: The paper does not describe whether tool outputs were manually verified, how tasks were selected, or whether the 16-task suite was finalized before or after observing performance, leaving open the possibility of post-hoc selection bias in the reported averages.
Authors: We will expand the evaluation section to explicitly state that tool outputs were not manually verified (the framework operates in a fully automated loop) and to detail the a-priori task selection criteria based on diversity of reasoning types. The 16-task suite was finalized prior to running the main experiments; we will add this timeline description to remove ambiguity about selection bias. revision: yes
Circularity Check
No circularity: empirical gains on public benchmarks with no self-referential derivations
full rationale
The paper introduces OctoTools as a training-free multi-agent framework and reports accuracy improvements on 16 public benchmarks (MathVista, MMLU-Pro, MedQA, GAIA-Text, etc.). These are direct empirical measurements against fixed external test sets rather than quantities derived from internal equations, fitted parameters, or self-citations that reduce the headline gains to the authors' own choices. No load-bearing steps match the enumerated circularity patterns; the central claims rest on observable performance deltas, not on renaming or self-definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standardized tool cards can encapsulate functionality across unrelated domains without loss of performance
Forward citations
Cited by 12 Pith papers
-
Inference-Time Budget Control for LLM Search Agents
A VOI-based controller for dual inference budgets improves multi-hop QA performance by prioritizing search actions and selectively finalizing answers.
-
ToolGrad: Efficient Tool-use Dataset Generation with Textual "Gradients"
ToolGrad inverts the standard tool-use dataset synthesis process by constructing valid tool chains first with textual gradients, producing a high-quality 500-example dataset with near-perfect validity and superior mod...
-
Agentic AI for Remote Sensing: Technical Challenges and Research Directions
Agentic AI faces structural challenges in remote sensing due to geospatial data properties and workflow constraints, requiring EO-native agents built around structured state, tool-aware reasoning, and validity-aware e...
-
Agentic Frameworks for Reasoning Tasks: An Empirical Study
An empirical evaluation of 22 agentic frameworks on BBH, GSM8K, and ARC benchmarks shows stable performance in 12 frameworks but highlights orchestration failures and weaker mathematical reasoning.
-
GLANCE: A Global-Local Coordination Multi-Agent Framework for Music-Grounded Non-Linear Video Editing
GLANCE introduces a bi-loop multi-agent framework with global-local coordination mechanisms that outperforms baselines by up to 33% on music-grounded nonlinear video editing tasks using a new MVEBench benchmark.
-
Agentic AI for Remote Sensing: Technical Challenges and Research Directions
Agentic AI for remote sensing requires new designs centered on structured geospatial state, tool-aware reasoning, verifier-guided execution, and physical validity rather than generic extensions.
-
Tool-MCoT: Tool Augmented Multimodal Chain-of-Thought for Content Safety Moderation
A small language model fine-tuned on tool-augmented chain-of-thought data generated by a larger LLM learns to selectively call tools, delivering better content moderation accuracy at lower inference cost.
-
RadAgents: Multimodal Agentic Reasoning for Chest X-ray Interpretation with Radiologist-like Workflows
RadAgents is a multi-agent framework coupling clinical priors with task-aware multimodal reasoning and radiologist-like workflows, plus grounding and retrieval-augmentation for conflict resolution in chest X-ray inter...
-
Bridging Perception and Action: A Lightweight Multimodal Meta-Planner Framework for Robust Earth Observation Agents
The LMMP framework improves tool-calling accuracy and task success rates for Earth observation agents by grounding plans in multimodal features and remote sensing expert knowledge via a two-stage training process.
-
Agentic Reasoning for Large Language Models
The survey structures agentic reasoning for LLMs into foundational, self-evolving, and collective multi-agent layers while distinguishing in-context orchestration from post-training optimization and reviewing applicat...
-
Position: Agent Should Invoke External Tools ONLY When Epistemically Necessary
Agents should invoke external tools only when epistemically necessary, per the introduced Theory of Agent framework that frames tool use as a decision under uncertainty.
-
From LLM Reasoning to Autonomous AI Agents: A Comprehensive Review
A survey consolidating benchmarks, agent frameworks, real-world applications, and protocols for LLM-based autonomous agents into a proposed taxonomy with recommendations for future research.
Reference graph
Works this paper leans on
-
[1]
Carefully read and understand the query and any accompanying inputs
-
[2]
Identify the main objectives or tasks within the query
-
[3]
List the specific skills that would be necessary to address the query comprehensively
-
[4]
Examine the available tools in the toolbox and determine which ones might relevant and useful for addressing the query. Make sure to consider the user metadata for each tool, including limitations and potential applications (if available)
-
[5]
Provide a brief explanation for each skill and tool you’ve identified, describing how it would contribute to answering the query. Your response should include:
-
[6]
A concise summary of the query’s main points and objectives, as well as content in any accompanying inputs
-
[7]
A list of required skills, with a brief explanation for each
-
[8]
A list of relevant tools from the toolbox, with a brief explanation of how each tool would be utilized and its potential limitations
-
[9]
Please present your analysis in a clear, structured format
Any additional considerations that might be important for addressing the query effectively. Please present your analysis in a clear, structured format. 24 OctoTools: An Agentic Framework with Extensible Tools for Complex Reasoning C.2. Action Predictor Prompt for Action Predictor Task: Determine the optimal next step to address the given query based on th...
-
[10]
Analyze the context thoroughly, including the query, its analysis, any image, available tools and their metadata, and previous steps taken
-
[11]
Determine the most appropriate next step by considering: - Key objectives from the query analysis - Capabilities of available tools - Logical progression of problem-solving - Outcomes from previous steps - Current step count and remaining steps
-
[12]
Select ONE tool best suited for the next step, keeping in mind the limited number of remaining steps
-
[13]
Formulate a specific, achievable sub-goal for the selected tool that maximizes progress towards answering the query. Output Format: <justification>: detailed explanation of why the selected tool is the best choice for the next step, considering the context and previous outcomes. <context>: MUST include ALL necessary information for the tool to function, s...
-
[14]
Carefully review all provided information: the query, image path, context, sub-goal, selected tool, and tool metadata
-
[15]
Analyze the tool’sinput types from the metadata to understand required and optional parameters
-
[16]
Construct a command or series of commands that aligns with the tool’s usage pattern and addresses the sub-goal
-
[17]
Ensure all required parameters are included and properly formatted
-
[18]
Use appropriate values for parameters based on the given context, particularly the Context field which may contain relevant information from previous steps
-
[19]
If multiple steps are needed to prepare data for the tool, include them in the command construction. Output Format: <analysis>: a step-by-step analysis of the context, sub-goal, and selected tool to guide the command construction. <explanation>: a detailed explanation of the constructed command(s) and their parameters. <command>: the Python code to execut...
-
[20]
The command MUST be valid Python code and include at least one call to tool.execute()
-
[21]
Each tool.execute() call MUST be assigned to the execution variable in the format execution = tool.execute(...)
-
[22]
For multiple executions, use separate execution = tool.execute() calls for each execution
-
[23]
The final output MUST be assigned to the execution variable, either directly from tool.execute() or as a processed form of multiple executions
-
[24]
Use the exact parameter names as specified in the tool’sinput types
-
[25]
Enclose string values in quotes, use appropriate data types for other values (e.g., lists, numbers)
-
[26]
Do not include any code or text that is not part of the actual command
-
[27]
Ensure the command directly addresses the sub-goal and query
-
[28]
Include ALL required parameters, data, and paths to execute the tool in the command itself
-
[29]
If preparation steps are needed, include them as separate Python statements before the tool.execute() calls. 26 OctoTools: An Agentic Framework with Extensible Tools for Complex Reasoning Prompt for Command Prediction (Continued) Examples (Not to use directly unless relevant): Example 1 (Single line command): <analysis>: The tool requires an image path an...
-
[30]
- Note any specific requirements or constraints mentioned
Carefully analyze the query, initial analysis, and image (if provided): - Identify the main objectives of the query. - Note any specific requirements or constraints mentioned. - If an image is provided, consider its relevance and what information it contributes
-
[31]
- Consider how each tool might be applicable to the query
Review the available tools and their metadata: - Understand the capabilities and limitations and best practices of each tool. - Consider how each tool might be applicable to the query
-
[32]
- Assess how well each tool’s output contributes to answering the query
Examine the memory content in detail: - Review each tool used and its execution results. - Assess how well each tool’s output contributes to answering the query
-
[33]
- Consider if all relevant information has been extracted from the image (if applicable)
Critical Evaluation (address each point explicitly): a) Completeness: Does the memory fully address all aspects of the query? - Identify any parts of the query that remain unanswered. - Consider if all relevant information has been extracted from the image (if applicable). b) Unused Tools: Are there any unused tools that could provide additional relevant ...
-
[34]
Final Determination: Based on your thorough analysis, decide if the memory is complete and accurate enough to generate the final output, or if additional tool usage is necessary. Response Format: <analysis>: Provide a detailed analysis of why the memory is sufficient. Reference specific information from the memory and explain its relevance to each aspect ...
-
[35]
Review the query, image, and all actions taken during the process
-
[36]
Consider the results obtained from each tool execution
-
[37]
Incorporate the relevant information from the memory to generate the step-by-step final output
-
[38]
Output Structure: Your response should be well-organized and include the following sections:
The final output should be consistent and coherent using the results from the tools. Output Structure: Your response should be well-organized and include the following sections:
-
[39]
Summary: - Provide a brief overview of the query and the main findings
-
[40]
- For each step, mention the tool used, its purpose, and the key results obtained
Detailed Analysis: - Break down the process of answering the query step-by-step. - For each step, mention the tool used, its purpose, and the key results obtained. - Explain how each step contributed to addressing the query
-
[41]
- Highlight any unexpected or particularly interesting results
Key Findings: - List the most important discoveries or insights gained from the analysis. - Highlight any unexpected or particularly interesting results
-
[42]
- If the query has multiple parts, ensure each part is answered separately
Answer to the Query: - Directly address the original question with a clear and concise answer. - If the query has multiple parts, ensure each part is answered separately
-
[43]
- Discuss any limitations or areas of uncertainty in the analysis
Additional Insights (if applicable): - Provide any relevant information or insights that go beyond the direct answer to the query. - Discuss any limitations or areas of uncertainty in the analysis
-
[44]
Conclusion: - Summarize the main points and reinforce the answer to the query. - If appropriate, suggest potential next steps or areas for further investigation. 30 OctoTools: An Agentic Framework with Extensible Tools for Complex Reasoning D. Tool Cards in OctoTools D.1. ArXiv Paper Searcher Tool ArXiv Paper Searcher Tool: Metadata tool_name="ArXiv_Paper...
-
[45]
Kidney 2. Kidney disease 3. Kidney failure 4. Kidney dialysis 5. Kidney transplantation 6. Kidney bean 7. Kidney cancer 8. Nephrology 9. Ectopic kidney 10. Kidney dish Extracted text: In humans, the kidneys are two reddish-brown bean-shaped blood-filtering organs that are a multilobar, multipapillary form of mammalian kidneys, usually without signs of ext...
work page 2025
-
[46]
Image Analysis: Understanding and interpreting visual content
-
[47]
Tool Operation: Ability to operate and execute commands using the provided tools
-
[48]
Critical Thinking: Evaluating tool outputs and making decisions based on them. Relevant tools:
-
[49]
Image Captioner Tool: Used to generate a description of the image, which can provide context and identify objects present
-
[50]
Object Detector Tool: Used to detect and count the number of baseballs in the image, providing specific object identification and quantification. Additional considerations: Consider the limitations of each tool, such as potential inaccuracies in complex scenes or object detection. Verify results if possible, and be aware of the need for potential manual v...
-
[51]
Mathematical Problem Solving: Ability to manipulate numbers and operations to achieve a specific result
-
[52]
Arithmetic Operations: Proficiency in using addition, subtraction, multiplication, and division
-
[53]
Logical Reasoning: Skill in applying logical steps to combine numbers and operations effectively. Relevant tools:
-
[54]
It is suitable for simple arithmetic calculations and can help automate the trial-and-error process
Python Code Generator Tool: This tool can be used to generate and test different combinations of arithmetic operations on the given numbers to find an expression that equals 24. It is suitable for simple arithmetic calculations and can help automate the trial-and-error process
-
[55]
Generalist Solution Generator Tool: Although not specifically designed for arithmetic problems, it can provide a step-by-step approach to solving the problem by suggesting possible combinations and reasoning through them. 67 OctoTools: An Agentic Framework with Extensible Tools for Complex Reasoning Step 1: Action from Action Predictor Justification: The ...
work page 2023
-
[56]
Look up Babylonian number system (base 60, using uniform ‘hashmarks’ as counters)
-
[57]
Converted the Cuniform to Arabic ( 8 56)
-
[58]
Since Babylonian is a base 60 system, converted the 60’s place to decimal (8*60=480)
-
[59]
Added 56 to 480 (536). Wrong Prediction from GPT-4o The given symbols are written in Sumerian cuneiform and follow the Babylonian number system, which is a . Let’s analyze the symbols: 1. : This symbol represents 60 in the Babylonian numeral system. 2. : - represents 10. - represents 2. - Together, represents 12. Now, interpreting the full number: - In a ...
-
[60]
Knowledge of Ancient Number Systems: Understanding the Mesopotamian/Babylonian number system and Sumerian cuneiform symbols is crucial for interpreting the given symbols
-
[61]
Historical Linguistics: Ability to translate ancient scripts into modern numerical systems
-
[62]
Research Skills: Ability to find reliable sources or references that explain the conversion process from cuneiform to Arabic numerals. Relevant tools:
-
[63]
Google Search Tool: This tool can be used to search for resources or references on the Mesopotamian/Babylo- nian number system and Sumerian cuneiform symbols, which are necessary for understanding and converting the symbols
-
[64]
Babylonian number system Sumerian cuneiform symbols
Wikipedia Knowledge Searcher Tool: This tool can be used to find detailed articles on the Babylonian number system and Sumerian cuneiform, providing background information and conversion methods. Additional considerations: The task requires a deep understanding of ancient numeral systems, which may not be directly supported by the available tools. Therefo...
work page 2024
-
[65]
Identify the Symbols: - represents the number 8. - represents the number 50. - represents the number 6
-
[66]
Each position represents a power of 60
Understand the Structure: - Babylonian numbers are written in a positional system similar to our decimal system but based on 60. Each position represents a power of 60
-
[67]
This suggests two separate groupings, which can be interpreted as two different positional values
Analyze the Given Symbols: - The symbols are written as . This suggests two separate groupings, which can be interpreted as two different positional values
-
[68]
- The second group (50 + 6) represents 56
Convert Each Group: - The first symbol (8) is in the higher position, so it represents 8 × 60 = 480. - The second group (50 + 6) represents 56
-
[69]
Therefore, the Sumerian cuneiform symbols convert to the Arabic numeral 536
Calculate the Total: - Add the values from each group: 480 + 56 = 536. Therefore, the Sumerian cuneiform symbols convert to the Arabic numeral 536. 76 OctoTools: An Agentic Framework with Extensible Tools for Complex Reasoning F.4. Example for Medical Reasoning The Query Image path: source.jpg Question: What is the organ on the left side of this image? Gr...
-
[70]
Image Analysis: Ability to interpret and analyze medical images to identify organs
-
[71]
Medical Knowledge: Understanding of human anatomy to accurately identify organs in medical images. Relevant tools:
-
[72]
However, it may have limitations in complex medical images
Image Captioner Tool: This tool can generate a description of the image, which might help in identifying the organ on the left side. However, it may have limitations in complex medical images
-
[73]
Relevant Patch Zoomer Tool: This tool can zoom into specific areas of the image, which might help in focusing on the left side to better identify the organ. Step 1: Action from Action Predictor Justification: The Relevant Patch Zoomer Tool is the best choice for the next step because it allows us to focus specifically on the left side of the image, which ...
-
[74]
Histopathology Knowledge: Understanding of osteosarcoma and its histological features
-
[75]
Image Analysis: Ability to interpret H&E stained images
-
[76]
Classification Skills: Ability to categorize images based on visual features. Relevant tools:
-
[77]
Path Generalist Classifier Tool: This tool is suitable for classifying histopathology images into predefined categories. It can be used to determine whether the image is of a non-tumor, necrotic tumor, or viable tumor. Additional considerations: Ensure the options provided for classification are clear and specific. Cross-reference the tool’s output with e...
-
[78]
Critical Thinking: To analyze and understand the descriptions of logical fallacies and identify the correct one
-
[79]
Knowledge of Logical Fallacies: To accurately recognize and differentiate between various logical fallacies, including the appeal to indignation
-
[80]
Decision Making: To choose the correct option from the given list based on the analysis. Relevant tools:
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.