Capacity-Aware Inference: Mitigating the Straggler Effect in Mixture of Experts
Pith reviewed 2026-05-23 00:36 UTC · model grok-4.3
The pith
Capacity-aware token drops balance expert loads in MoE models and deliver 1.85 times faster inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper defines the Straggler Effect as the global inference latency dictated by the most heavily loaded experts in expert-parallel MoE execution. Capacity-Aware Token Drop removes surplus tokens from experts that exceed their capacity, shrinking load imbalance with little accuracy loss. Capacity-Aware Expanded Drop lets tokens consider additional local experts before the capacity check is applied, filling underused experts and further equalizing load. Experiments across language and multimodal MoE models confirm higher expert utilization, near-baseline performance, and large reductions in inference time.
What carries the argument
Capacity-Aware Token Drop and Capacity-Aware Expanded Drop, which enforce and relax expert capacity constraints on token assignments to reduce load imbalance.
If this is right
- Inference latency falls because the maximum expert load decreases.
- Average performance on standard benchmarks changes by less than one percent.
- Underloaded experts receive higher token counts and therefore higher utilization.
- The same capacity logic applies to both language-only and multimodal MoE architectures.
Where Pith is reading between the lines
- The drop rules could be applied during training if the routing decision is made differentiable.
- Speedups may grow with larger batch sizes because straggler variance scales with the number of parallel experts.
- The method could be combined with existing auxiliary-load losses without changing the core capacity logic.
Load-bearing premise
Discarding excess tokens from overloaded experts reduces load imbalance while causing only minimal performance degradation.
What would settle it
Measure end-to-end inference latency on Mixtral-8×7B-Instruct when capacity limits are removed but token-to-expert assignments are forced to be perfectly balanced by an oracle router; if the 1.85 times speedup disappears, the capacity-drop mechanism is not the source of the gain.
Figures
















read the original abstract
The Mixture of Experts (MoE) is an effective architecture for scaling large language models by leveraging sparse expert activation to balance performance and efficiency. However, under expert parallelism, MoE suffers from inference inefficiencies due to imbalanced token-to-expert assignment, where underloaded experts complete computations early but must wait for overloaded experts, leading to global delays. We define this phenomenon as the \textbf{\textit{Straggler Effect}}, as the most burdened experts dictate the overall inference latency. To address this, we first propose \textit{\textbf{Capacity-Aware Token Drop}}, which enforces expert capacity limits by discarding excess tokens from overloaded experts, effectively reducing load imbalance with minimal performance impact (e.g., $30\%$ speedup with only $0.9\%$ degradation on OLMoE). Next, given the presence of low-load experts remaining well below the capacity threshold, we introduce \textit{\textbf{Capacity-Aware Expanded Drop}}, which allows tokens to include additional local experts in their candidate set before enforcing strict local capacity constraints, thereby improving load balance and enhancing the utilization of underused experts. Extensive experiments on both language and multimodal MoE models demonstrate the effectiveness of our approach, yielding substantial gains in expert utilization, model performance, and inference efficiency, e.g., applying Expanded Drop to Mixtral-8$\times$7B-Instruct yields a {0.2\%} average performance improvement and a {1.85$\times$} inference speedup. The code is released at: https://github.com/CASE-Lab-UMD/Capacity-Aware-MoE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript defines the Straggler Effect in Mixture-of-Experts (MoE) inference under expert parallelism as the global latency bottleneck imposed by the most overloaded experts. It proposes Capacity-Aware Token Drop, which enforces per-expert capacity by discarding excess tokens from overloaded experts, and Capacity-Aware Expanded Drop, which augments each token's local expert candidate set before applying capacity constraints to improve utilization of underloaded experts. Experiments on language and multimodal MoE models (including OLMoE and Mixtral-8×7B-Instruct) report speedups (30% and 1.85× respectively) accompanied by small performance changes (0.9% degradation and 0.2% improvement).
Significance. If the empirical speedups and performance deltas prove robust, the methods address a practical deployment bottleneck in sparse MoE models by improving load balance without requiring hardware changes. The public code release is a positive factor for reproducibility.
major comments (1)
- [Experimental results on Mixtral-8×7B-Instruct] Results for Mixtral-8×7B-Instruct (abstract and experimental section): the reported 0.2% average performance improvement is presented without error bars, standard deviations, number of runs, or statistical significance tests. Because the central claim for Expanded Drop is that it yields both speedup and a net performance benefit, the absence of these details leaves open whether the 0.2% delta lies within typical benchmark variance.
minor comments (2)
- [Introduction] The definition of the Straggler Effect is introduced in the abstract and introduction but would benefit from a precise mathematical formulation (e.g., relating per-expert latency to global step time) to make the subsequent capacity constraints easier to relate to the claimed effect.
- [Abstract] The paper states that code is released but does not specify the exact commit or reproduction instructions for the reported Mixtral and OLMoE numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment point by point below.
read point-by-point responses
-
Referee: Results for Mixtral-8×7B-Instruct (abstract and experimental section): the reported 0.2% average performance improvement is presented without error bars, standard deviations, number of runs, or statistical significance tests. Because the central claim for Expanded Drop is that it yields both speedup and a net performance benefit, the absence of these details leaves open whether the 0.2% delta lies within typical benchmark variance.
Authors: We agree that the current presentation lacks error bars, standard deviations, number of runs, and statistical significance tests for the 0.2% average performance improvement reported for Mixtral-8×7B-Instruct. This omission makes it impossible for readers to determine whether the small positive delta exceeds typical benchmark variance. In the revised manuscript we will report results over multiple independent runs, include error bars and standard deviations, and add appropriate statistical significance tests (e.g., paired t-tests) to substantiate the performance claim for Capacity-Aware Expanded Drop. revision: yes
Circularity Check
No circularity; empirical results on standard models
full rationale
The paper introduces Capacity-Aware Token Drop and Expanded Drop as algorithmic interventions for MoE load balancing. All reported outcomes (0.2% avg improvement, 1.85× speedup on Mixtral-8×7B-Instruct; 30% speedup with 0.9% degradation on OLMoE) are direct empirical measurements on fixed external benchmarks and models. No equations, fitted parameters, self-citations, or uniqueness theorems appear in the abstract or description; the central claims do not reduce to any input by construction. This is the normal case of an applied systems paper whose validity rests on external falsifiability rather than internal definitional closure.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert capacity limits can be enforced by discarding tokens with only minimal performance impact
invented entities (1)
-
Straggler Effect
no independent evidence
Forward citations
Cited by 6 Pith papers
-
GhostServe: A Lightweight Checkpointing System in the Shadow for Fault-Tolerant LLM Serving
GhostServe applies erasure coding to KV cache in host memory for fast recovery from failures in LLM serving, cutting checkpointing latency up to 2.7x and recovery latency 2.1x versus prior methods.
-
NanoCP: Request-Level Dynamic Context Parallelism for Data-Expert Parallel Decoding
NanoCP introduces request-level dynamic context parallelism to decouple MoE communication from KV cache placement in hybrid data-expert parallel serving, reporting up to 3.27x higher request rates and 2.12x lower P99 ...
-
GEM: GPU-Variability-Aware Expert to GPU Mapping for MoE Systems
GEM is a GPU-variability-aware expert-to-GPU mapping framework for MoE inference that classifies experts as consistent or temporal and places them to equalize finish times across heterogeneous GPUs.
-
SMoES: Soft Modality-Guided Expert Specialization in MoE-VLMs
SMoES improves MoE-VLM performance and efficiency via soft modality-guided expert routing and inter-bin mutual information regularization, yielding 0.9-4.2% task gains and 56% communication reduction.
-
MACS: Modality-Aware Capacity Scaling for Efficient Multimodal MoE Inference
MACS improves MoE MLLM inference efficiency via entropy-weighted token loads and dynamic modality-adaptive expert capacity allocation.
-
MACS: Modality-Aware Capacity Scaling for Efficient Multimodal MoE Inference
MACS improves inference speed in multimodal MoE models by entropy-weighted balancing of visual tokens and real-time modality-adaptive expert capacity allocation.
Reference graph
Works this paper leans on
-
[1]
URL https://aclanthology.org/2023
Association for Computational Linguistics. URL https://aclanthology.org/2023. eacl-main.168. Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. Piqa: Reasoning about physical commonsense in natural language,
work page 2023
-
[2]
A survey on mixture of experts
URLhttps://arxiv.org/abs/2407.06204. Iñigo Casanueva, Tadas Temcinas, Daniela Gerz, Matthew Henderson, and Ivan Vulic. Efficient intent detection with dual sentence encoders. InProceedings of the 2nd Workshop on NLP for ConvAI - ACL 2020, mar
-
[3]
Efficient intent detection with dual sentence encoders
URL https://arxiv.org/abs/2003.04807. Data available at https://github.com/PolyAI-LDN/task-specific-datasets. Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision- language models,
-
[4]
URL https://openreview.net/forum?id=MaYzugDmQV. 11 Published as a conference paper at ICLR 2026 Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions,
work page 2026
-
[5]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
Damai Dai, Chengqi Deng, Chenggang Zhao, RX Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y Wu, et al. Deepseekmoe: Towards ultimate expert specialization in mixture- of-experts language models.arXiv preprint arXiv:2401.06066,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models
Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tripathi, Yue Yang, Jae Sung Park, and et al. Molmo and pixmo: Open weights and open data for state-of-the-art multimodal models.arXiv preprint arXiv:2409.17146,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
DeepSeek-AI et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model, 2024a. URLhttps://arxiv.org/abs/2405.04434. DeepSeek-AI et al. Deepseek-v3 technical report, 2024b. URL https://arxiv.org/abs/2412. 19437. William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple...
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Zhenyu Qiu, Wei Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, and Rongrong Ji. Mme: A comprehensive evaluation benchmark for multimodal large language models.ArXiv, abs/2306.13394,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Ariel Gera, Odellia Boni, Yotam Perlitz, Roy Bar-Haim, Lilach Eden, and Asaf Yehudai
URLhttps://zenodo.org/records/10256836. Jamie Hayes, Ilia Shumailov, and Itay Yona. Buffer overflow in mixture of experts. InNeurips Safe Generative AI Workshop 2024,
-
[11]
doi: 10.18653/v1/2023.acl-long.803
Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.803. URL https://aclanthology.org/2023. acl-long.803. Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding,
-
[12]
12 Published as a conference paper at ICLR 2026 Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
doi: 10.1162/tacl_a_00276. URL https://aclanthology.org/Q19-1026/. Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with conditional computation and automatic sharding.arXiv preprint arXiv:2006.16668,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1162/tacl_a_00276 2006
-
[14]
Bohao Li, Yuying Ge, Yixiao Ge, Guangzhi Wang, Rui Wang, Ruimao Zhang, and Ying Shan
URLhttps://openreview.net/forum?id=qrwe7XHTmYb. Bohao Li, Yuying Ge, Yixiao Ge, Guangzhi Wang, Rui Wang, Ruimao Zhang, and Ying Shan. Seed-bench: Benchmarking multimodal large language models.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 13299–13308, 2024a. URL https: //api.semanticscholar.org/CorpusID:271963485. Tianle L...
work page 2024
-
[15]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
URL https://api.semanticscholar.org/CorpusID:259837088. Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering, 2018a. Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question...
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
URLhttps://arxiv.org/abs/2409.02060. OpenAI. Gpt-4 technical report,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538, 2017a. 13 Published as a conference paper at ICLR 2026 Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hi...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Fuzhao Xue, Zian Zheng, Yao Fu, Jinjie Ni, Zangwei Zheng, Wangchunshu Zhou, and Yang You
In the Proceedings of ICLR. Fuzhao Xue, Zian Zheng, Yao Fu, Jinjie Ni, Zangwei Zheng, Wangchunshu Zhou, and Yang You. Openmoe: An early effort on open mixture-of-experts language models.arXiv preprint arXiv:2402.01739, 2024a. Leyang Xue, Yao Fu, Zhan Lu, Luo Mai, and Mahesh Marina. Moe-infinity: Activation-aware expert offloading for efficient moe serving...
-
[19]
URLhttps://arxiv.org/abs/2505.09388. Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence?,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
URLhttps://arxiv.org/abs/2406.16554. Barret Zoph, Irwan Bello, Sameer Kumar, Nan Du, Yanping Huang, Jeff Dean, Noam Shazeer, and William Fedus. St-moe: Designing stable and transferable sparse expert models.arXiv preprint arXiv:2202.08906,
-
[22]
14 Published as a conference paper at ICLR 2026 A IMPLEMENTATIONDETAILS ModelsWe mainly focus on lightweight MoE models (less than 20B parameter budget). We conduct experiments on OLMoE (Muennighoff et al., 2024), Qwen1.5-MoE (Team, 2024b), DeepSeek-V2- Lite (et al., 2024a), Mixtral (Jiang et al., 2024), MolmoE (Deitke et al., 2024), and Qwen3-MoE (Yang e...
work page 2026
-
[23]
Table 7: Performance of Token Drop and Expanded Drop across three MoE-based LLMs on Hu- manEval (HE), NQ-open (NQ), and MTS-Dialog (MTS). The capacity factor is set as 1.0 here and we report pass@1 for HE, exact_match for NQ and BERTScore for MTS, respectively. Method OLMoE-Instruct Qwen1.5-MoE-Chat DeepSeek-V2-Lite-Chat HE NQ MTS HE NQ MTS HE NQ MTS Base...
work page 2026
-
[24]
Batch Size 8K 8K 8K 4K 2K 2K 1K 1K 1K Prompt Length 0.1K 0.2K 0.4K 1K 1K 2K 1K 2K 4K Speedup 1.09×1.18×1.24×1.26×1.27×1.27×1.27×1.24×1.23× Table 10: Speedup results across varying batch sizes and prompt lengths. The straggler effect becomes more pronounced under heavier workloads, where GPUs operate at higher utilization with limited spare capacity, makin...
work page 2026
-
[25]
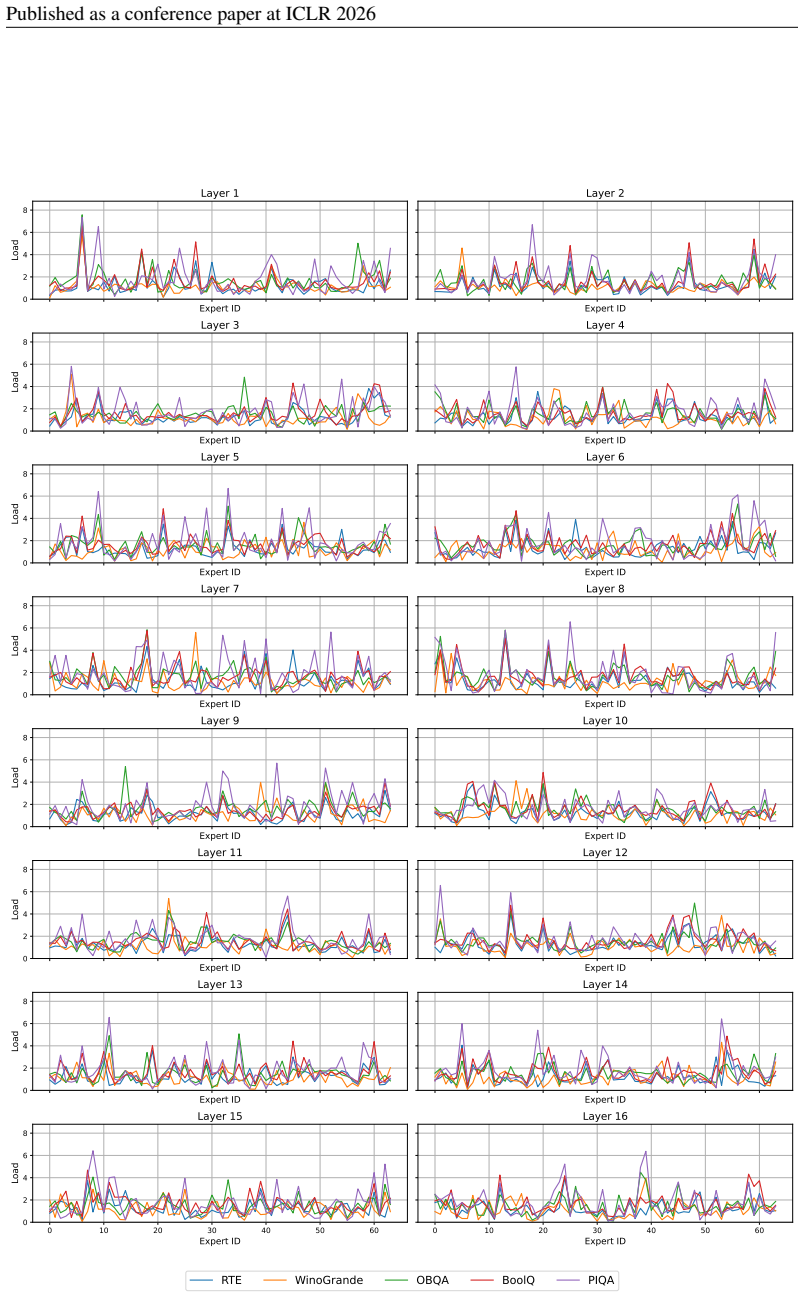
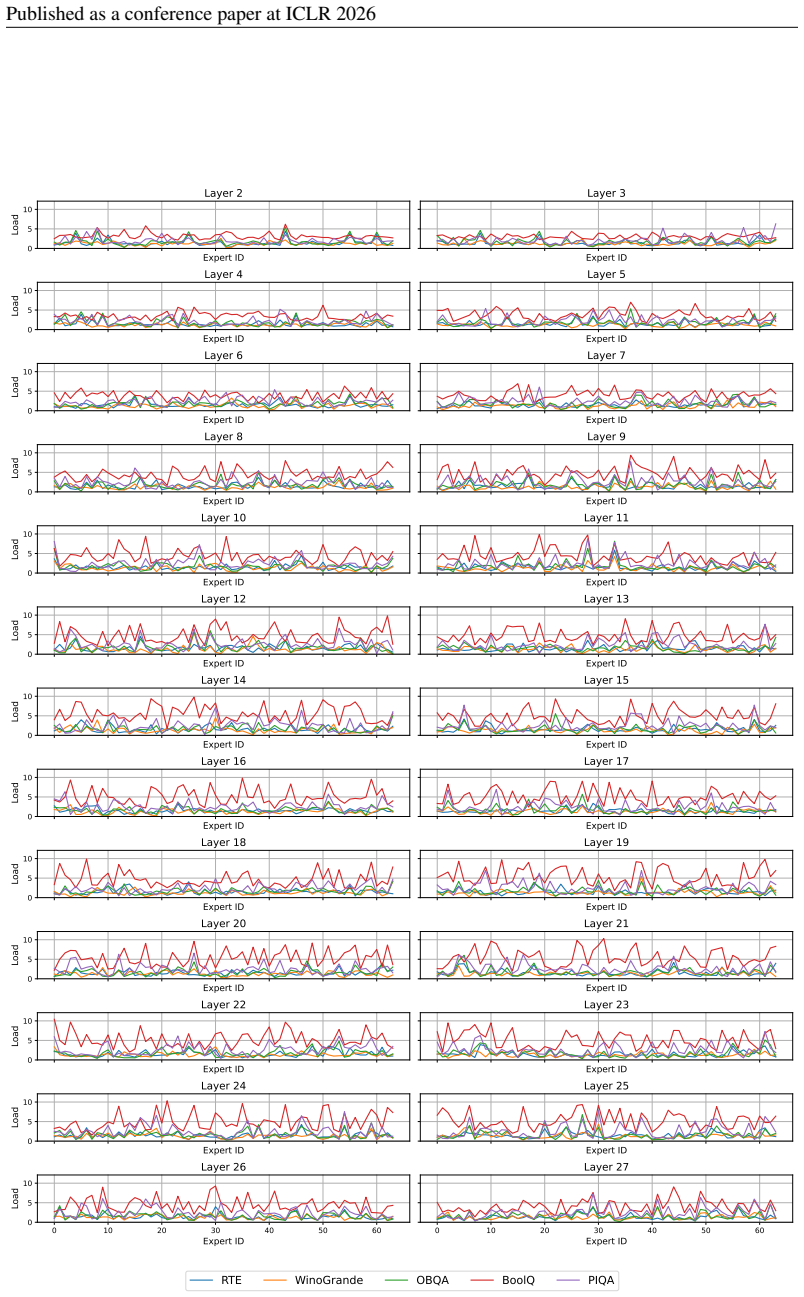
18 Published as a conference paper at ICLR 2026 Expert ID 0 2 4 6 8Load Layer 1 Expert ID Layer 2 Expert ID 0 2 4 6 8Load Layer 3 Expert ID Layer 4 Expert ID 0 2 4 6 8Load Layer 5 Expert ID Layer 6 Expert ID 0 2 4 6 8Load Layer 7 Expert ID Layer 8 Expert ID 0 2 4 6 8Load Layer 9 Expert ID Layer 10 Expert ID 0 2 4 6 8Load Layer 11 Expert ID Layer 12 Expert...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.