Extracting memorized pieces of (copyrighted) books from open-weight language models
Pith reviewed 2026-05-22 13:55 UTC · model grok-4.3
The pith
Some LLMs memorize entire copyrighted books and can reproduce them nearly verbatim from just the first few words as a prompt.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
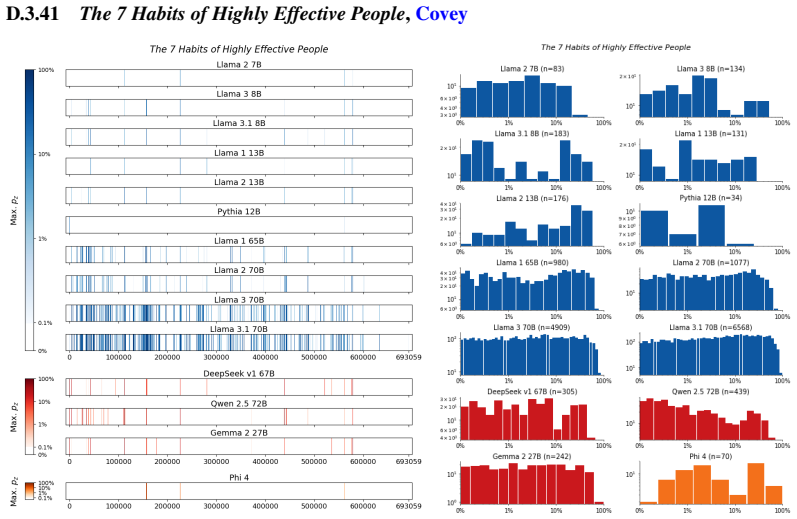
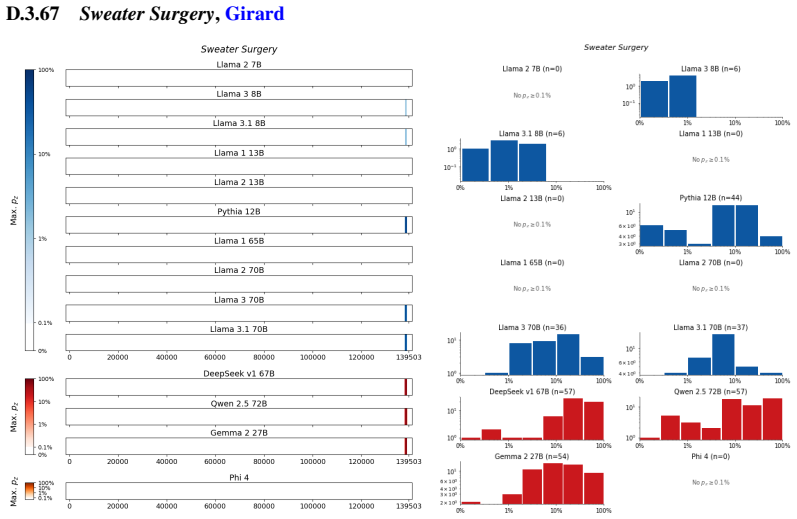
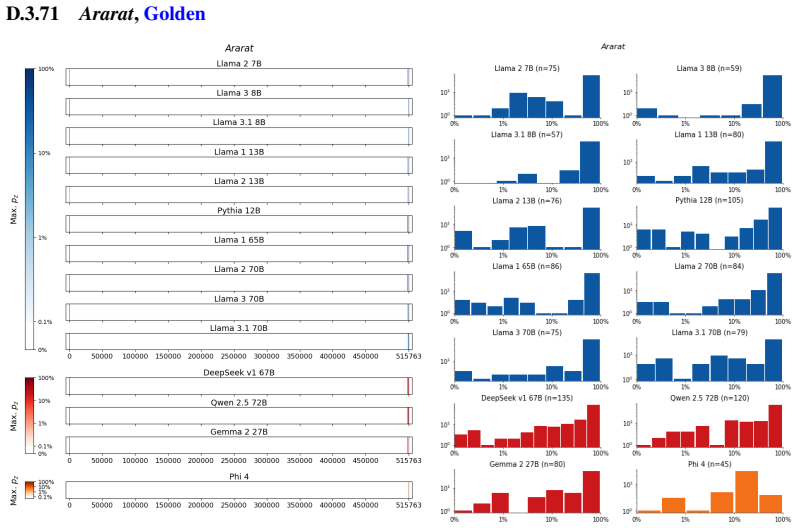
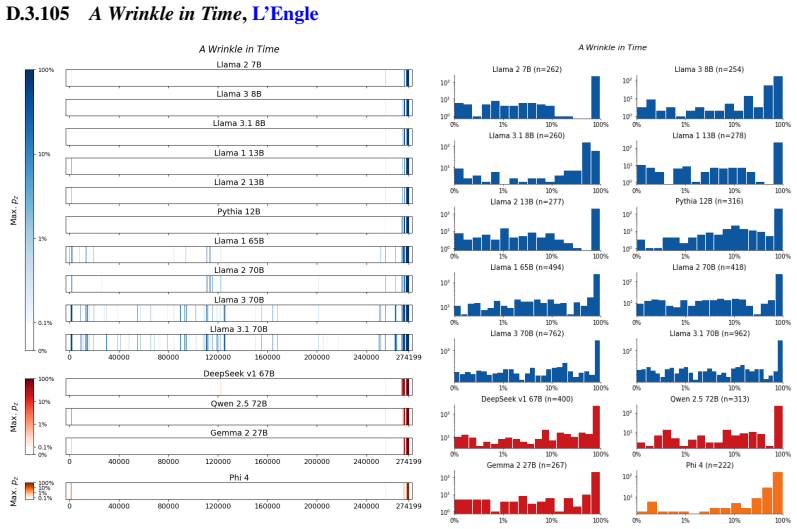
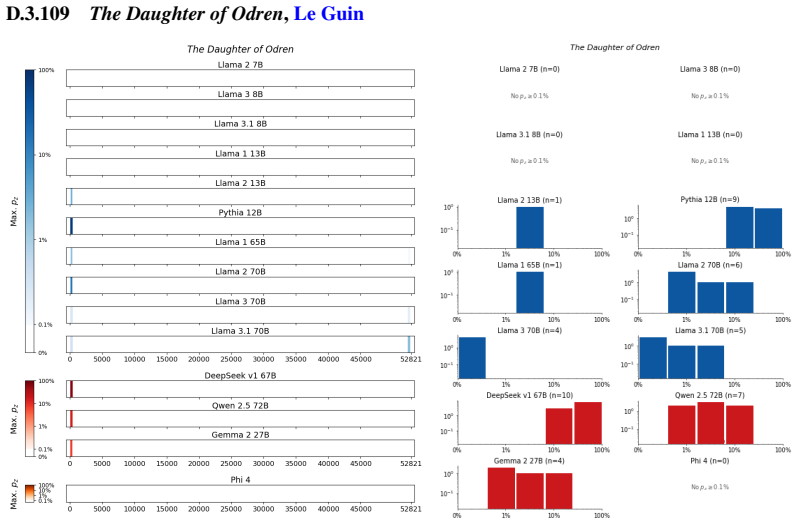
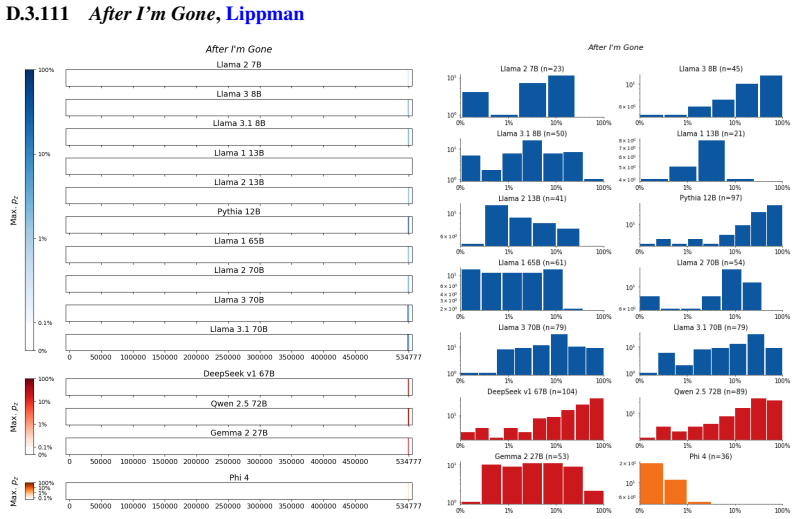
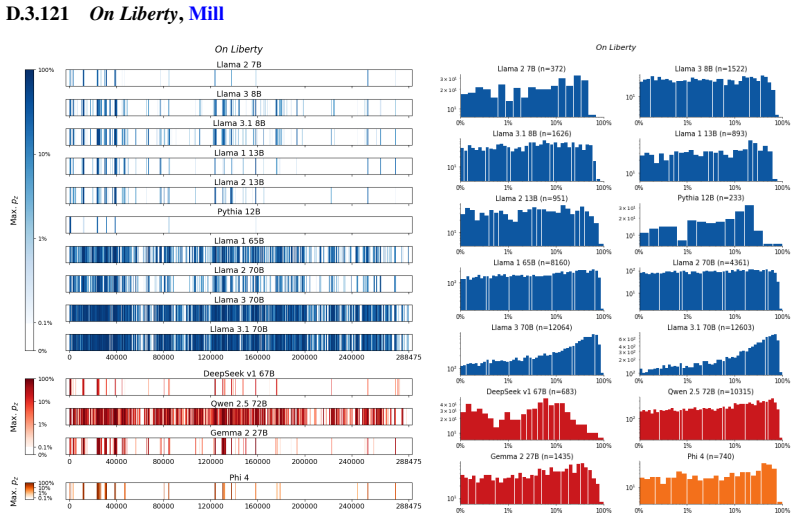
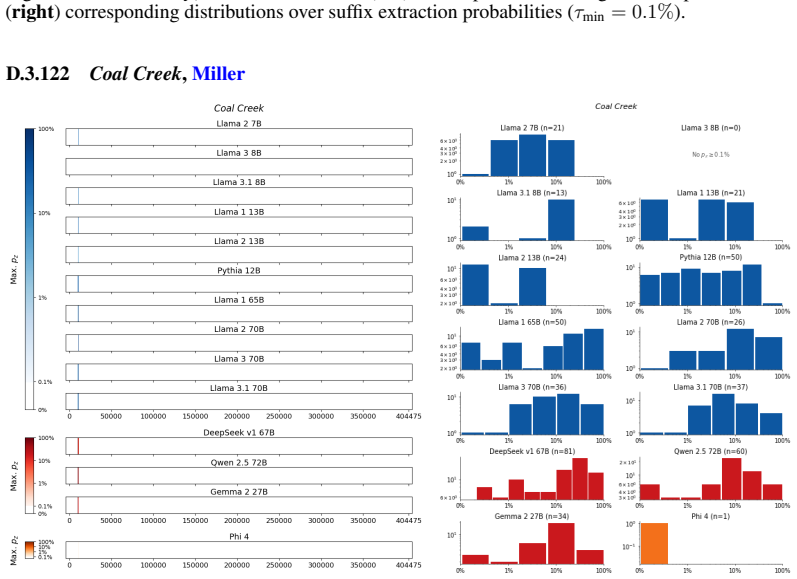
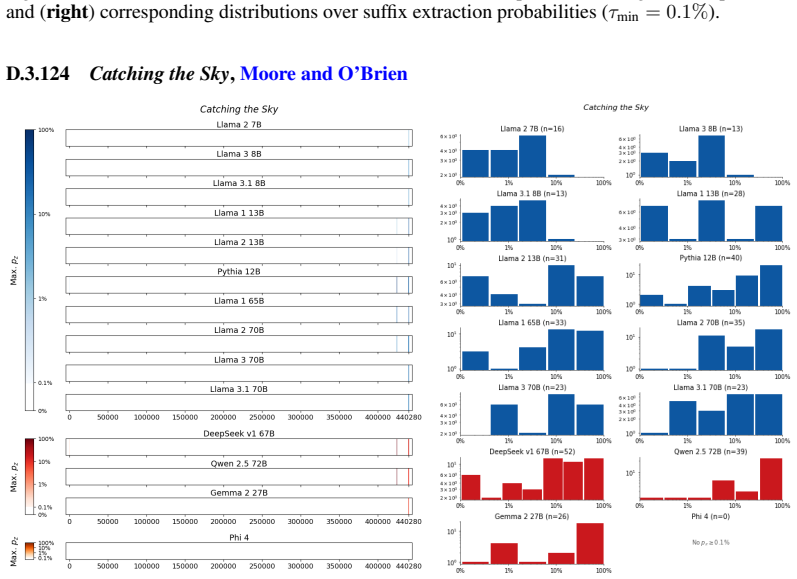
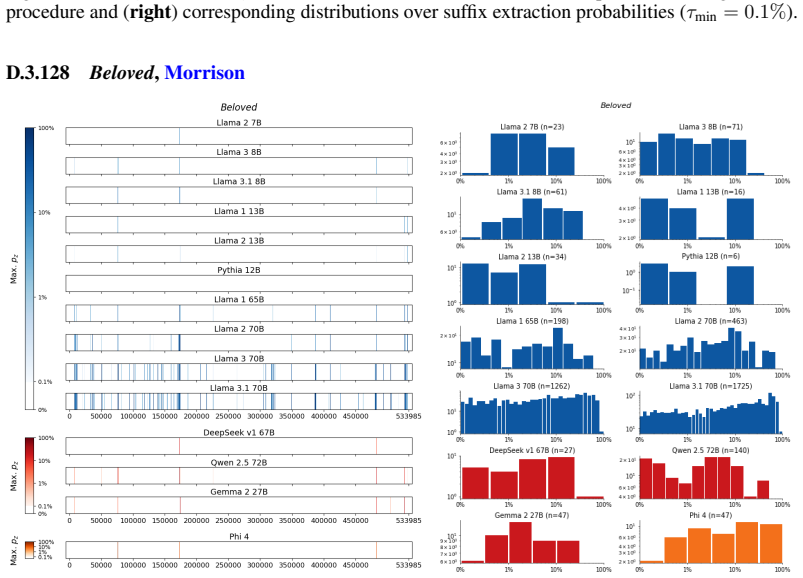
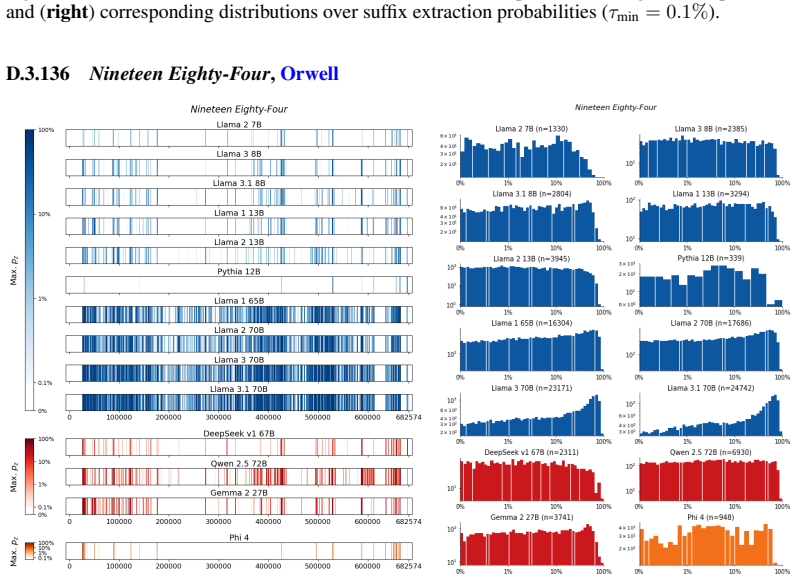
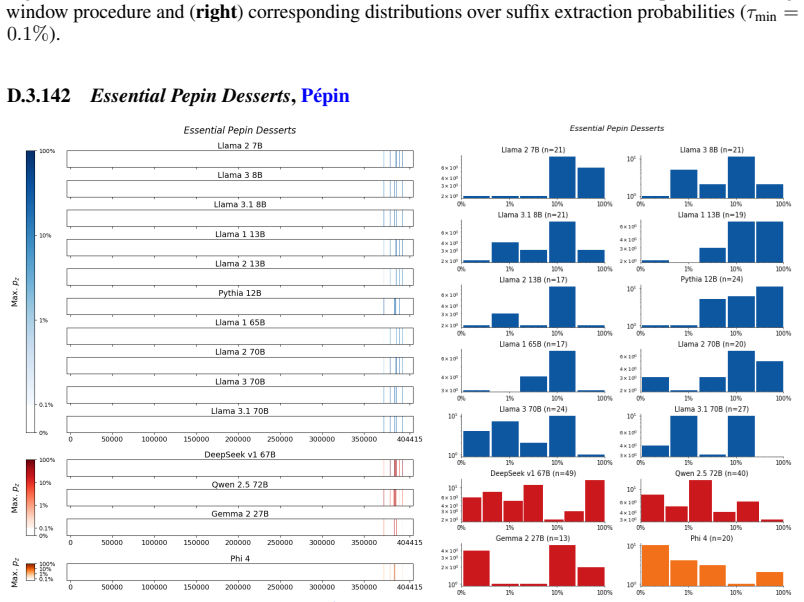
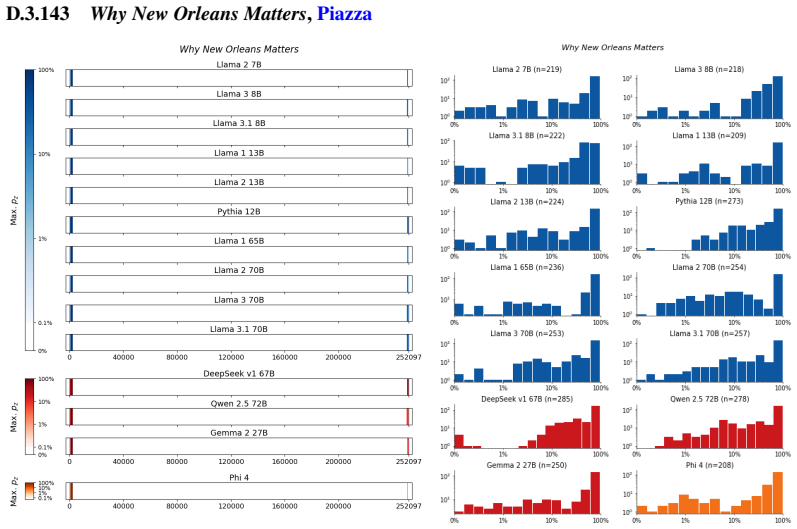
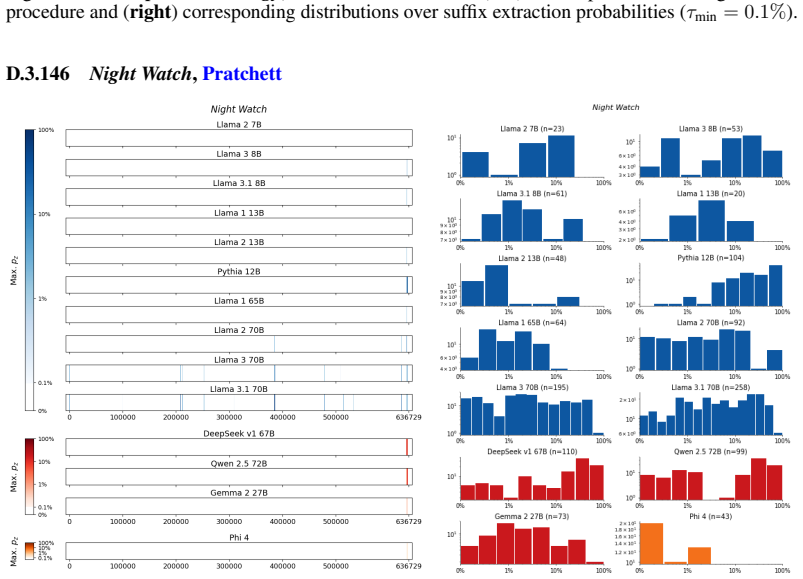
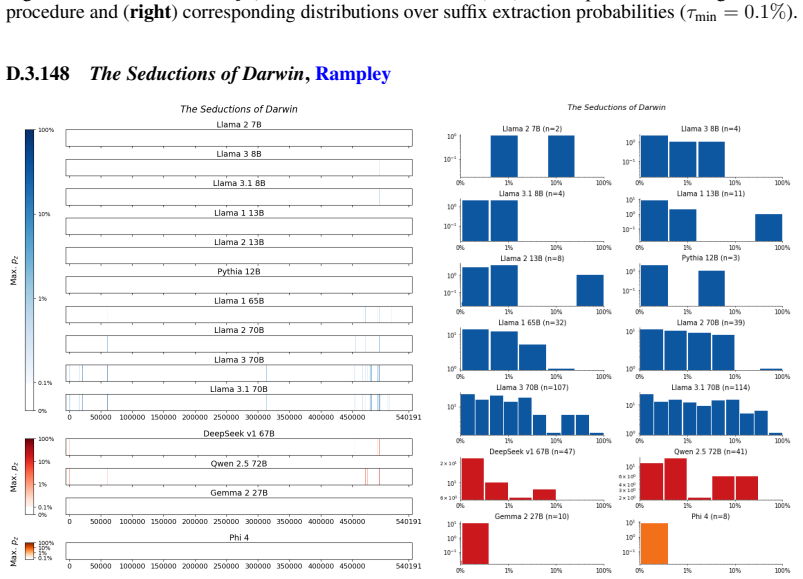
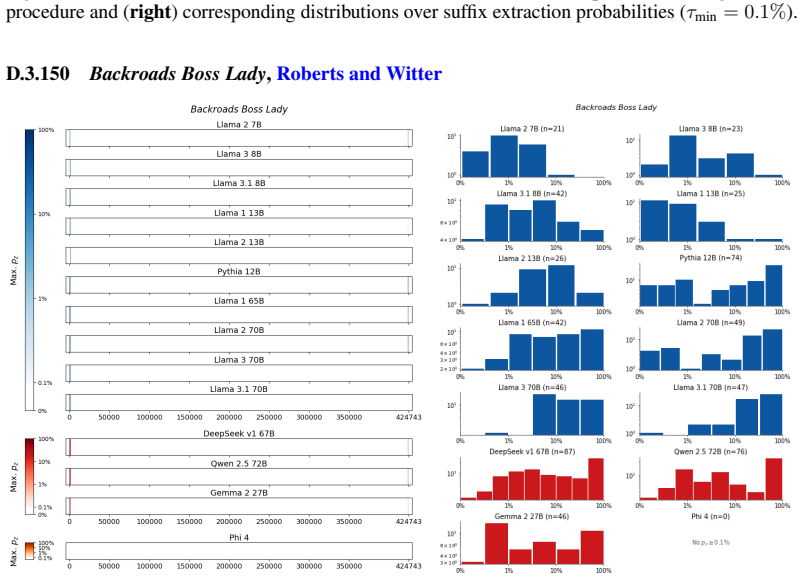
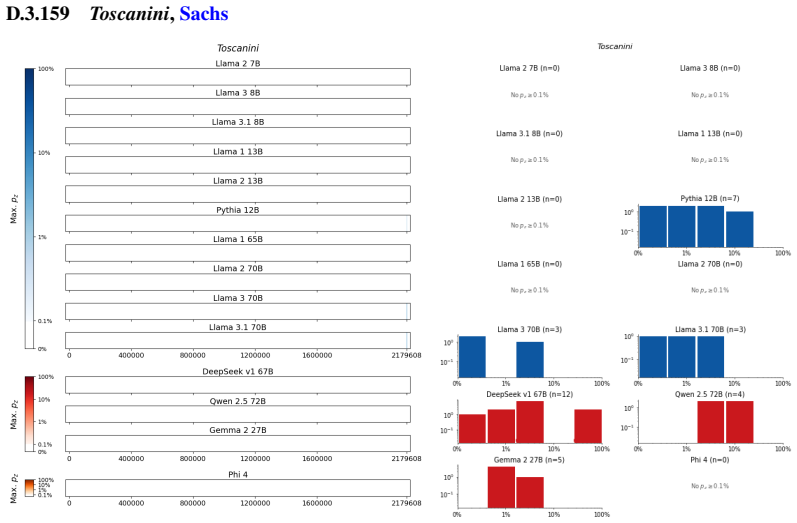
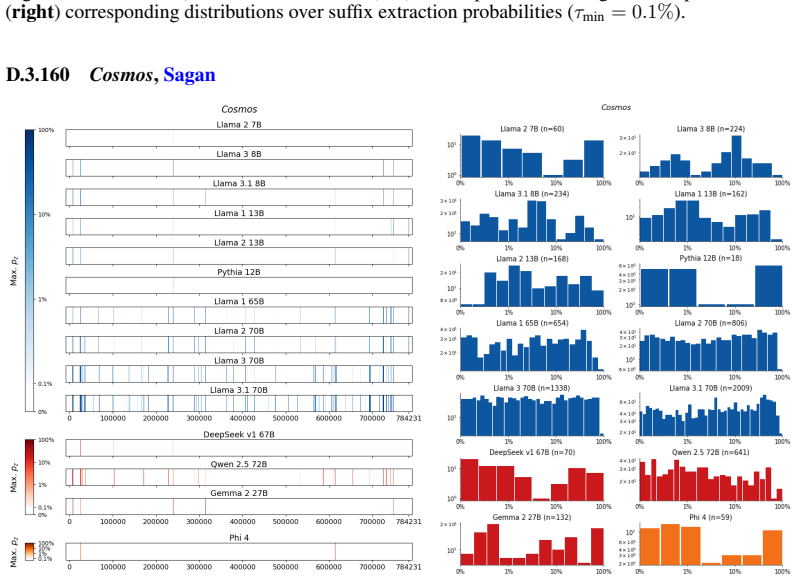
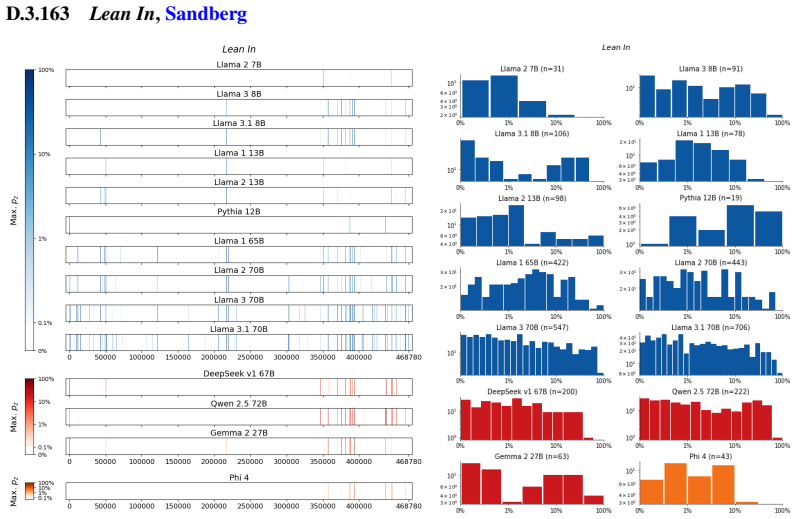
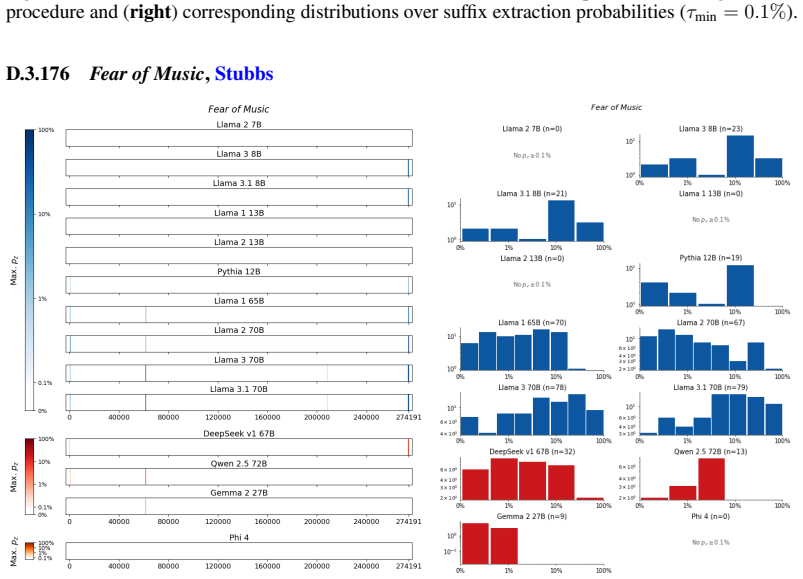
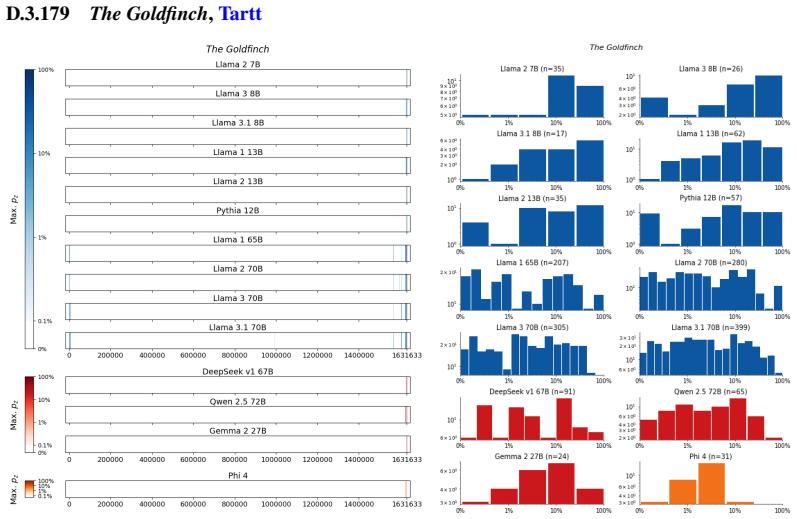
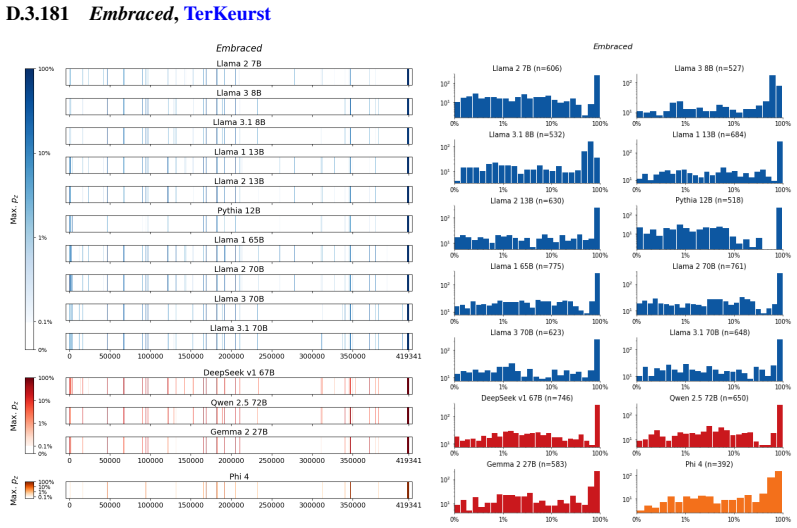
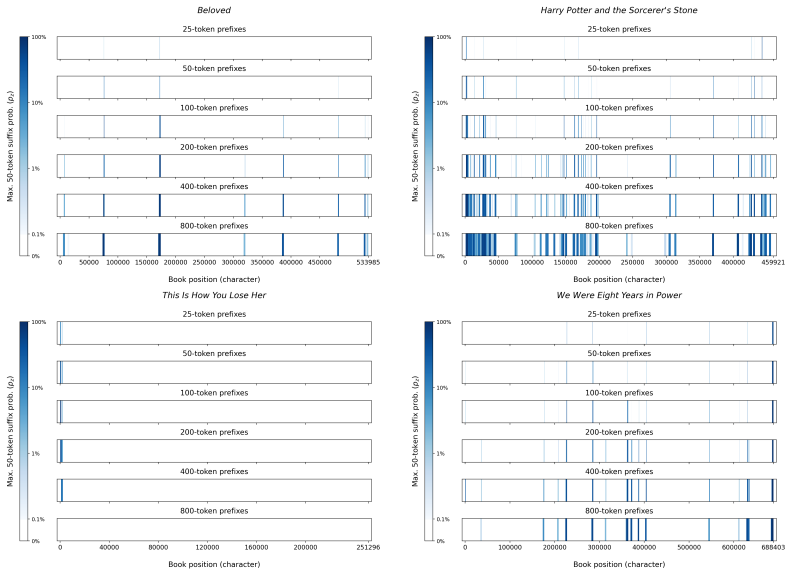
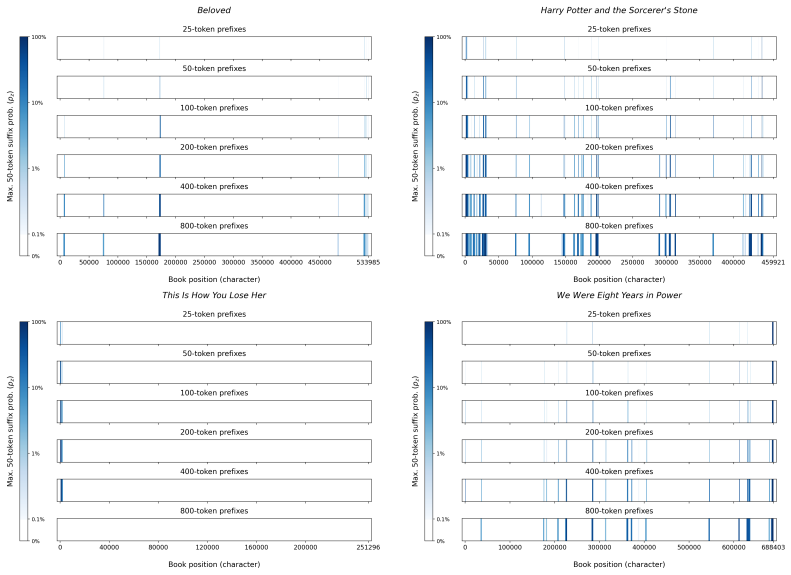
The authors establish that memorization of books in LLMs varies by both model and book. Their extraction methodology shows that while most of the tested models do not memorize most of the tested books either wholly or partially, notable exceptions exist. In particular, Llama 3.1 70B entirely memorizes some books, such as Harry Potter and the Sorcerer's Stone, to the point that providing the book's first few words as an initial prompt allows deterministic, near-verbatim extraction of the entire work. The paper discusses how these results carry significant implications for copyright cases without clearly favoring either plaintiffs or defendants.
What carries the argument
A prompt-based extraction procedure that uses the first few words of a target book as a starting prompt and then measures how closely the model's generated continuation matches the book's actual text.
If this is right
- Memorization can be measured empirically on a per-book and per-model basis instead of assumed to be uniform across all LLMs.
- Copyright arguments can shift from blanket claims about all generative AI systems to evidence about specific memorized works.
- Certain models store and can reproduce substantial verbatim portions of their training data under targeted prompting.
- Systematic testing across many books can reveal patterns in which models and which texts show high memorization.
Where Pith is reading between the lines
- Model developers could apply similar prefix-based tests as an internal audit step before releasing open-weight checkpoints.
- Training pipelines might need to track and mitigate exact long-sequence memorization through data filtering or architectural changes.
- Legal standards could eventually distinguish between models that rarely allow extraction of protected text and those that readily do so.
- The same method might be used to compare memorization rates between copyrighted works and public-domain material.
Load-bearing premise
Using short prefixes from a book as prompts reliably pulls out memorized content rather than simply eliciting a plausible continuation that happens to match the book by chance.
What would settle it
Prompting Llama 3.1 70B with the opening paragraph of Harry Potter and the Sorcerer's Stone and obtaining output that quickly deviates from the book's actual text in a manner indistinguishable from ordinary creative generation.
Figures















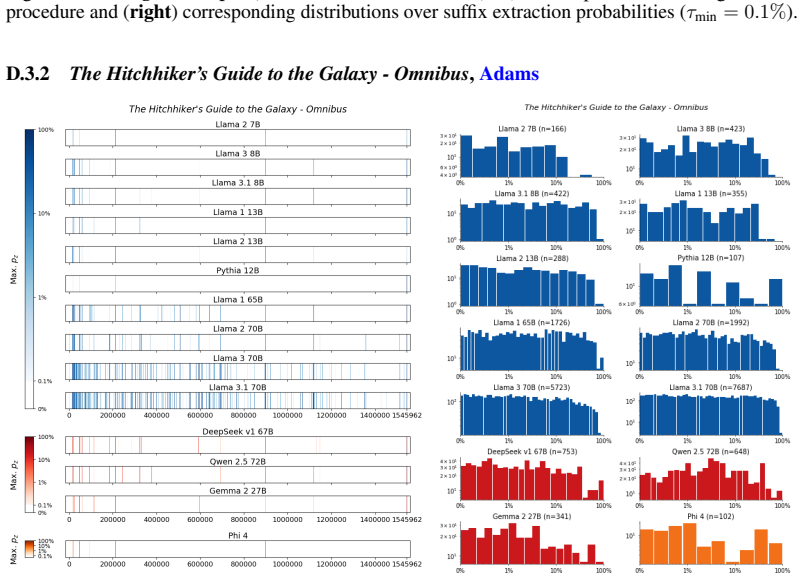

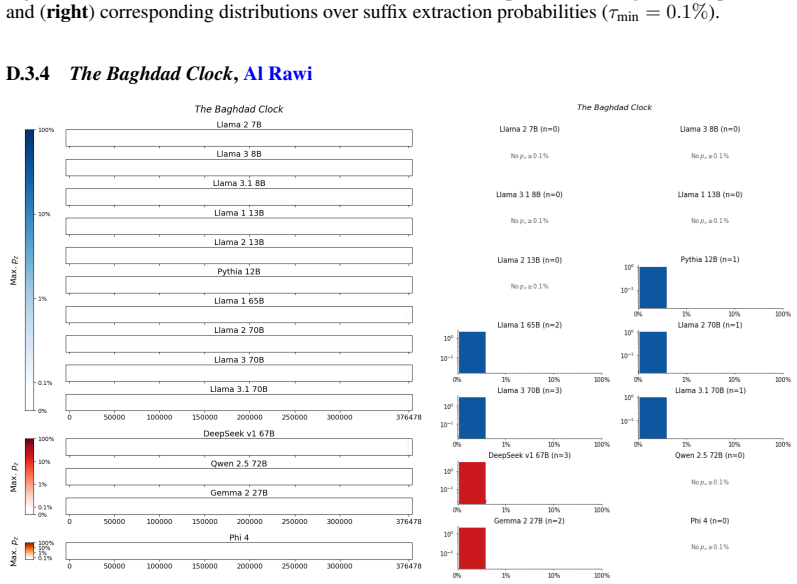
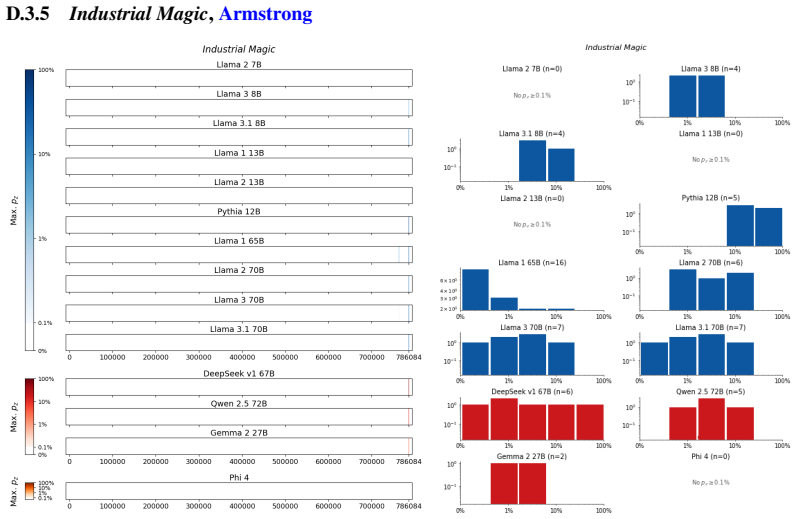



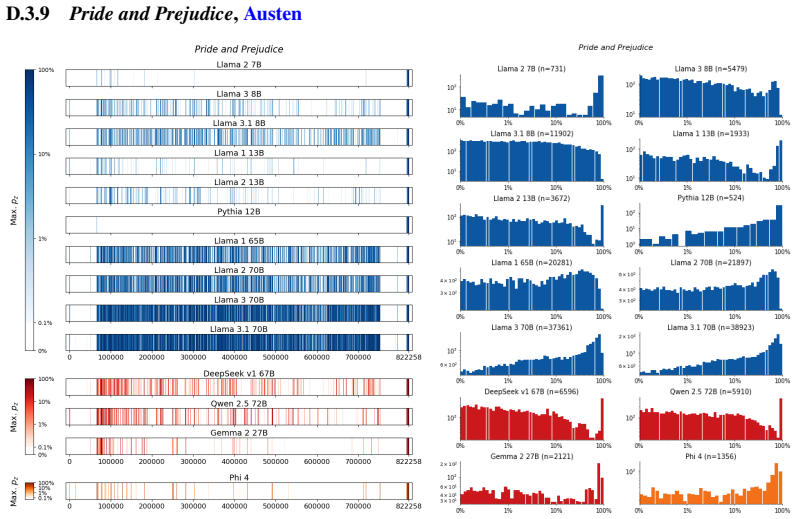






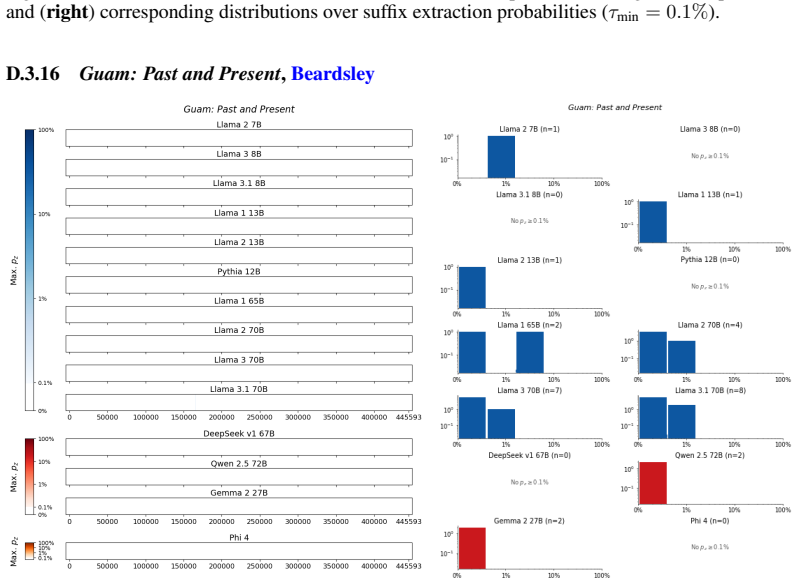





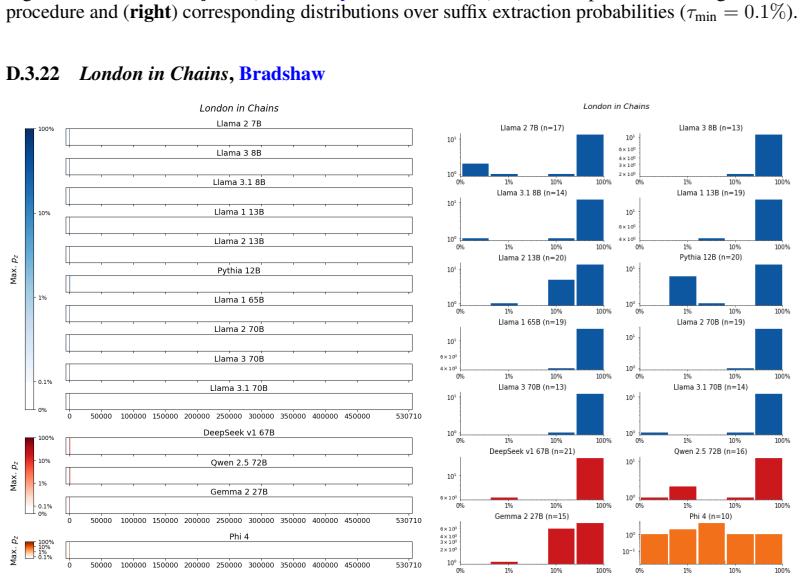

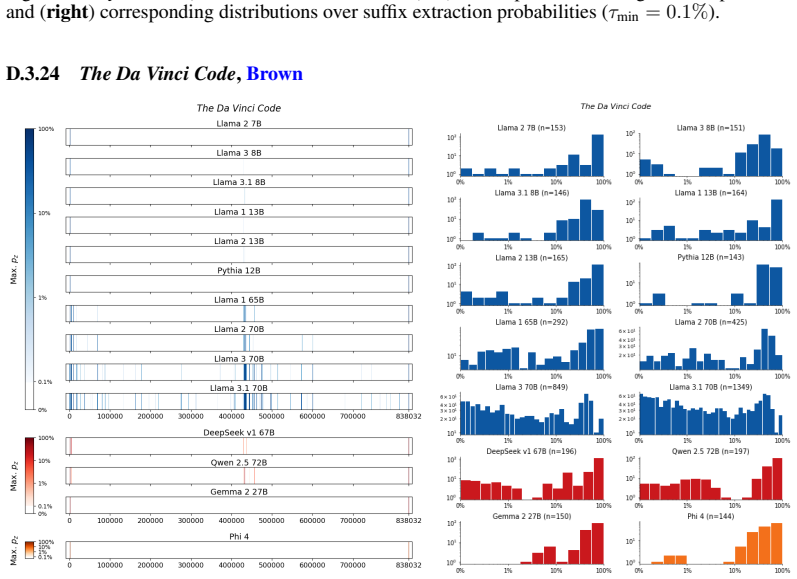






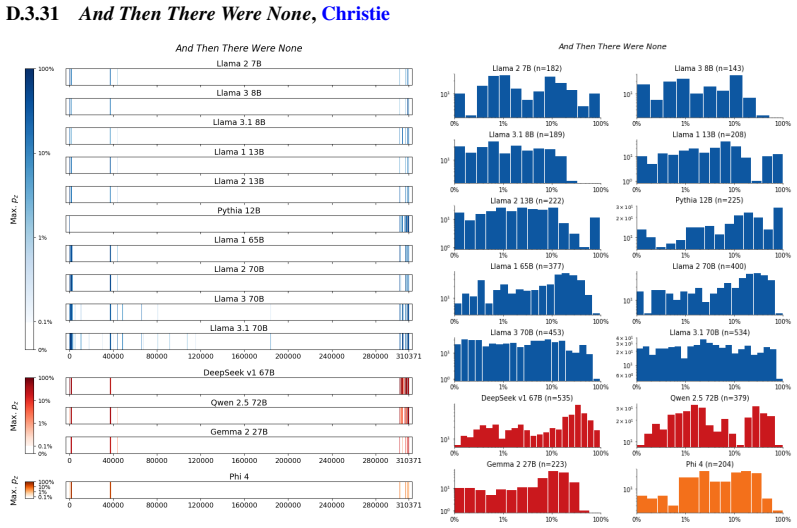














































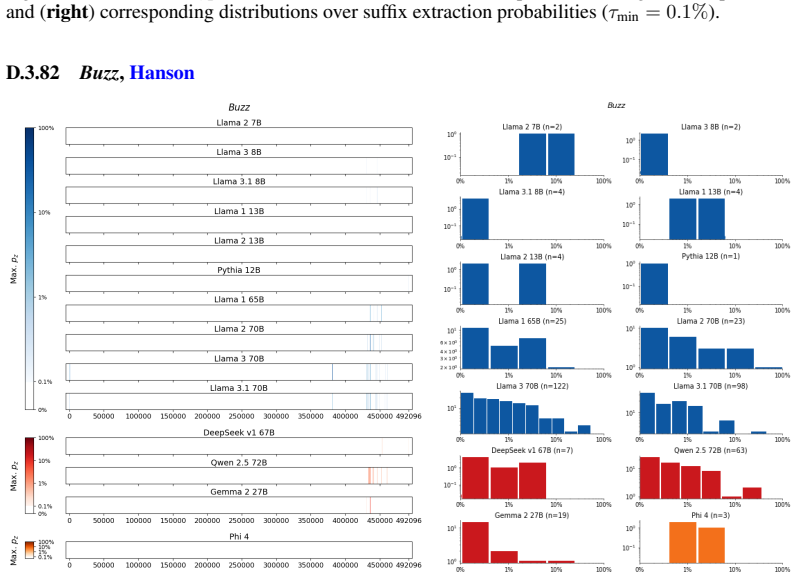








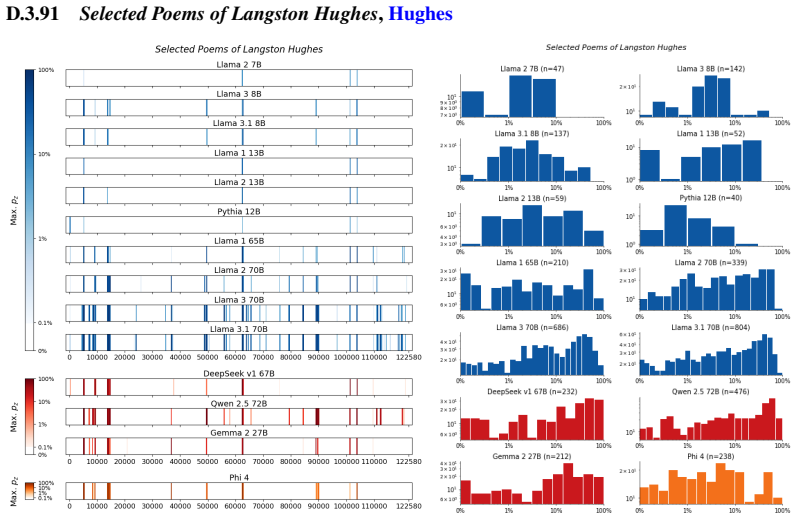
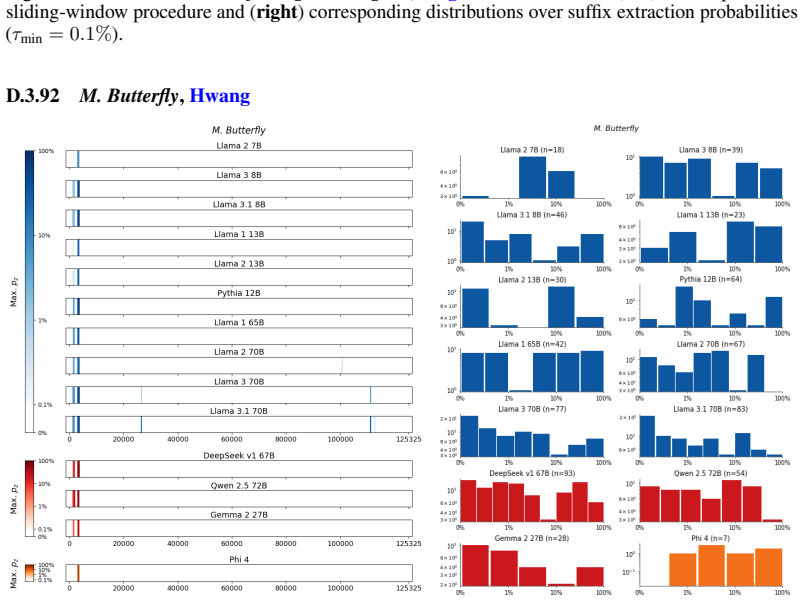


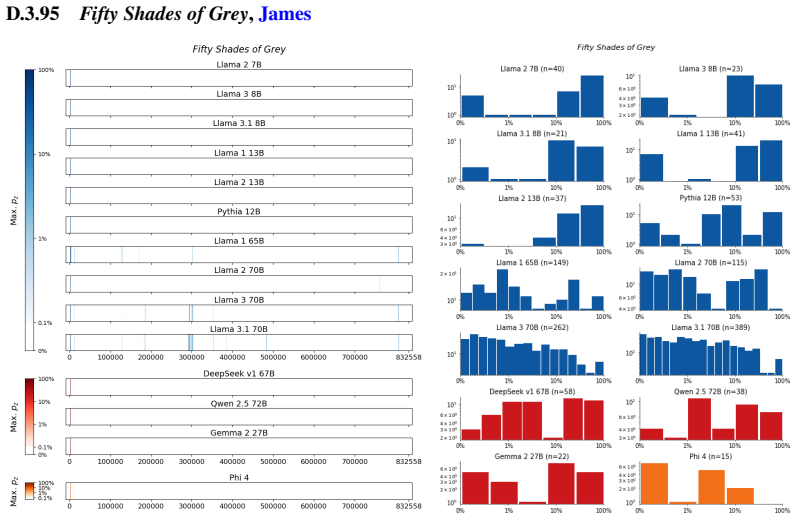
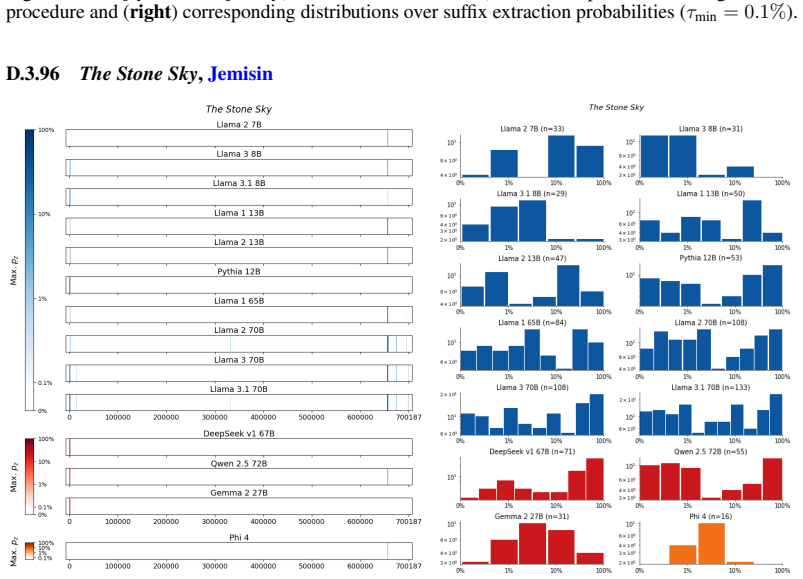
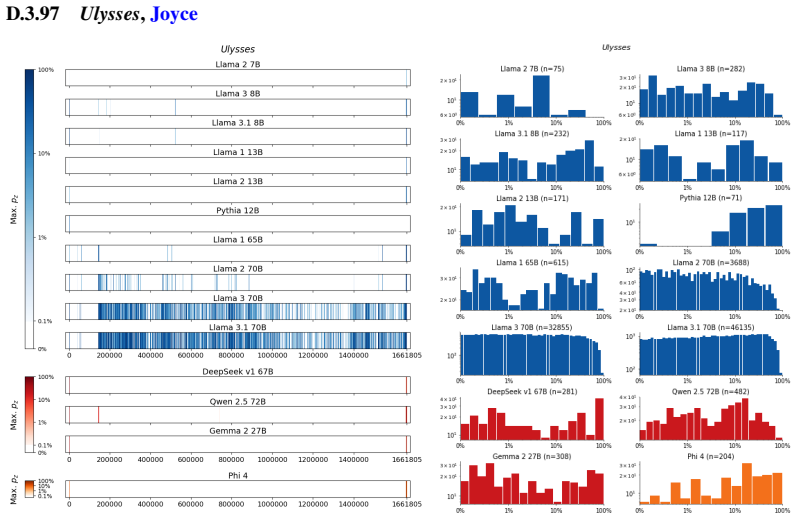

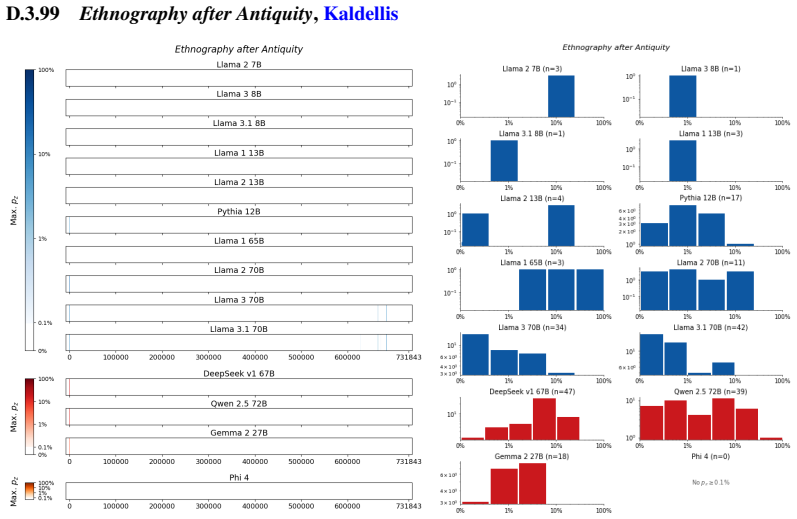
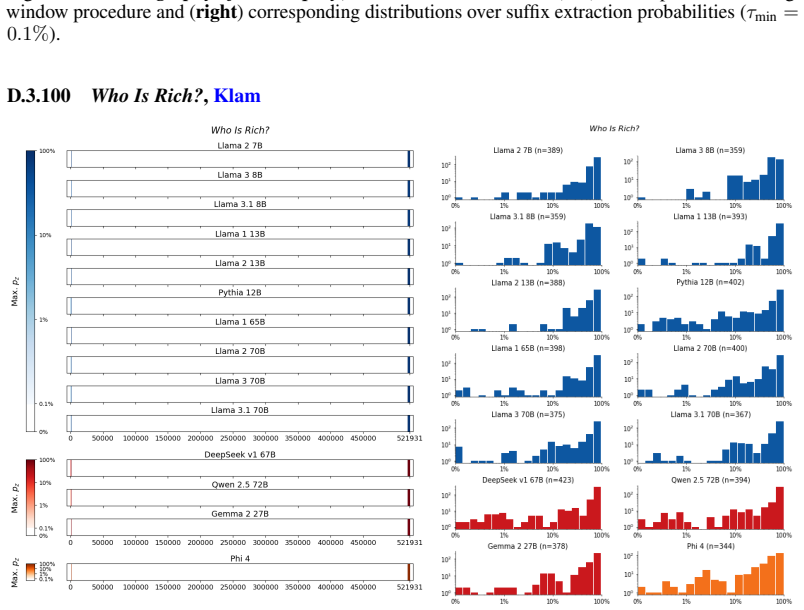




























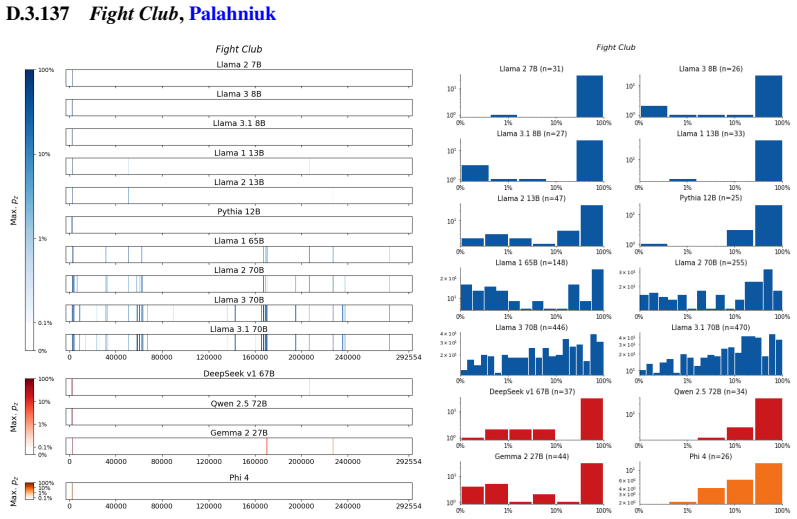

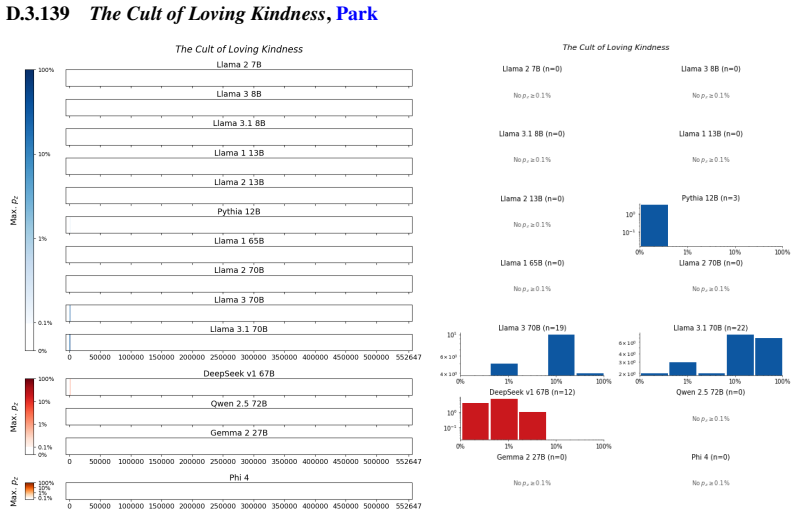
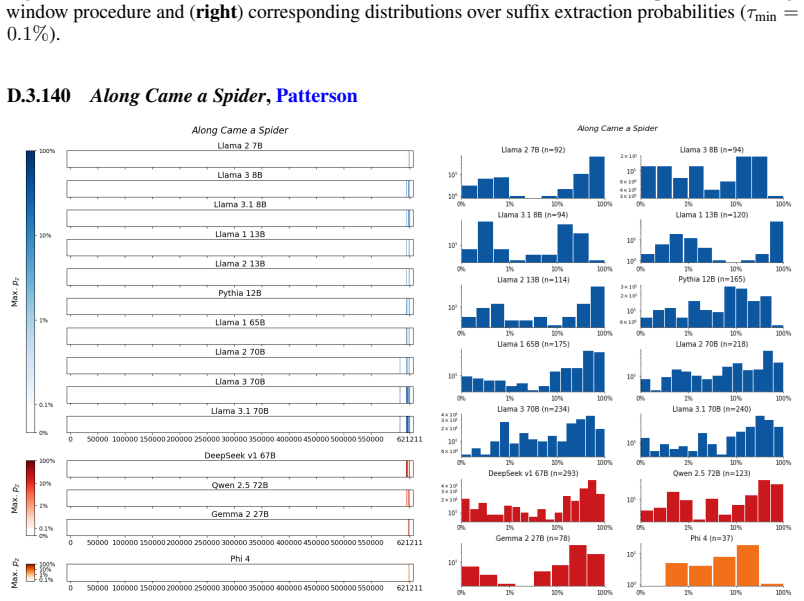
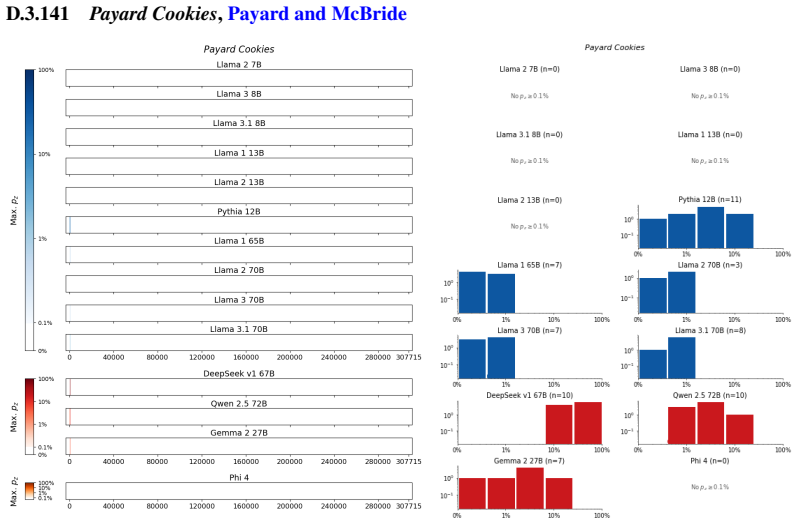
















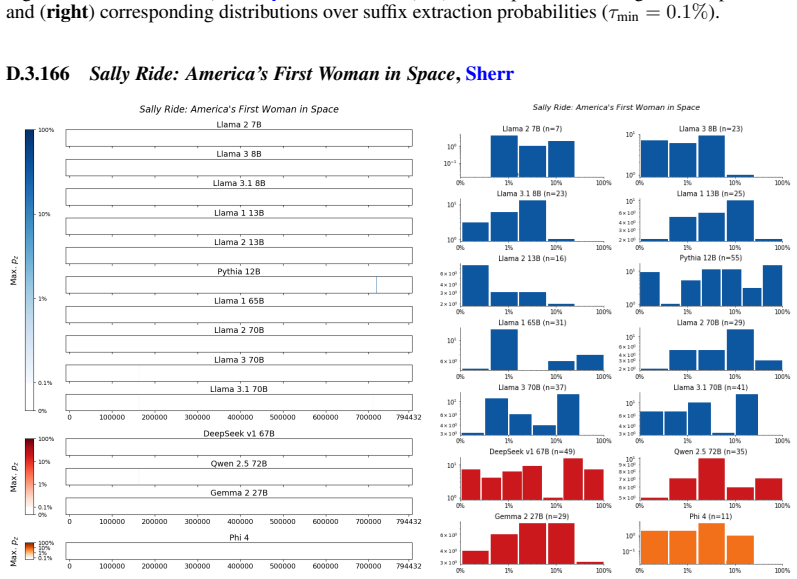
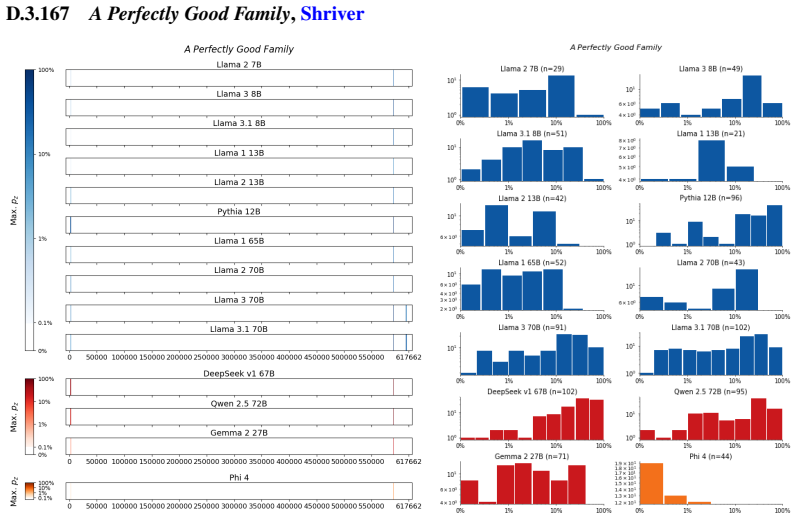


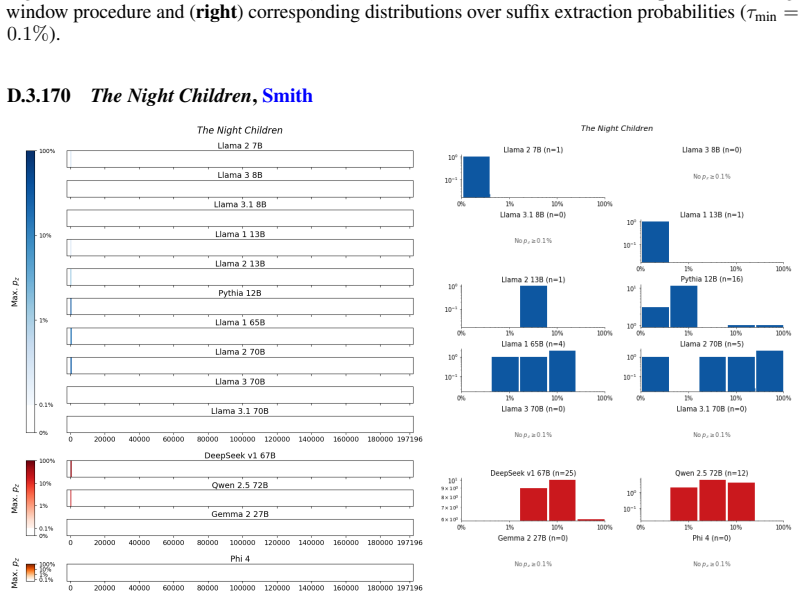




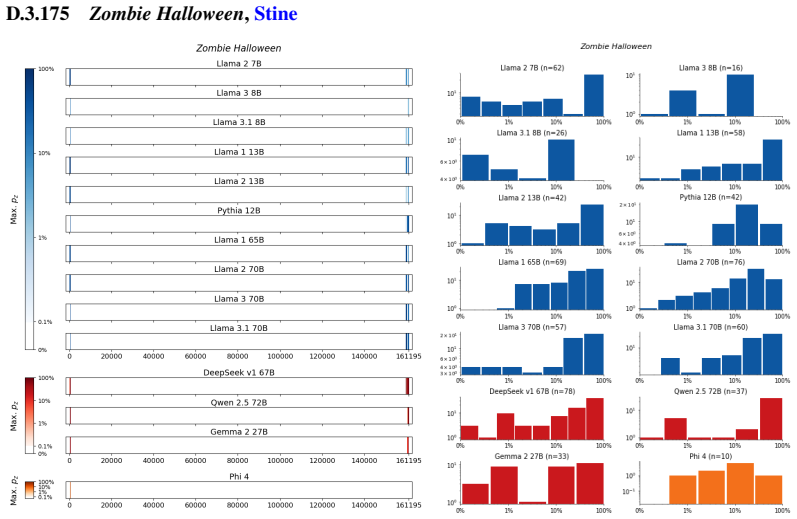





























read the original abstract
Plaintiffs and defendants in copyright lawsuits over generative AI often make sweeping, opposing claims about the extent to which large language models (LLMs) memorize protected expression from books in their training data. We show that these polarized positions dramatically oversimplify the relationship between memorization and copyright. To do so, we develop a technique to measure memorization of books, which we apply to 200 books and 14 open-weight LLMs. Through over 3000 experiments, we show that memorization varies both by model and book. With respect to our specific extraction methodology, we find that most LLMs do not memorize most books -- either in whole or in part; however, there are notable exceptions. For instance, Llama 3.1 70B entirely memorizes some books, like Harry Potter and the Sorcerer's Stone; memorization is so extensive that one can deterministically extract the whole book almost verbatim using the book's first few words as an initial prompt. We discuss why our results have significant implications for copyright cases, though not ones that unambiguously favor either side.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops an empirical technique to extract and quantify memorization of entire books from open-weight LLMs by using short initial prefixes as prompts. Applied to 200 books across 14 models in over 3000 experiments, it reports that memorization is generally limited, but with clear exceptions such as Llama 3.1 70B, where some books (e.g., Harry Potter and the Sorcerer's Stone) appear to be memorized in full, enabling near-verbatim deterministic extraction of the complete text from the opening words.
Significance. If the extraction results and controls hold, the work supplies concrete, reproducible evidence that memorization of copyrighted books in LLMs is neither ubiquitous nor absent but varies sharply by model and title. This directly informs ongoing copyright litigation by showing that sweeping claims on either side oversimplify the phenomenon, while the scale of the experiments and provision of specific extraction examples add practical value for assessing infringement risk.
major comments (2)
- [Methods / Extraction Procedure] The central claim that Llama 3.1 70B 'entirely memorizes' books such as Harry Potter rests on short-prefix prompting producing near-verbatim output. The methods section does not appear to include controls that test whether semantically similar but non-exact prefixes (or paraphrased openings) elicit comparable long-range matches; without such tests it remains possible that the outputs reflect high-probability generation from general training on summaries and references rather than parameter-stored verbatim sequences. This directly affects the load-bearing distinction between memorization and plausible continuation.
- [Results / Llama 3.1 70B Experiments] In the results for the Harry Potter case, quantitative metrics beyond qualitative 'near-verbatim' description (e.g., exact token-match rates per chapter, edit distance, or log-probability comparisons against random prefixes) are needed to substantiate the 'deterministically extract the whole book' assertion. The current presentation leaves open the possibility that partial or approximate matches are being interpreted as full-book memorization.
minor comments (2)
- [Methods] Clarify the exact length and content of the 'first few words' prefix used across experiments; a table listing prefix lengths per book would improve reproducibility.
- [Experimental Setup] The abstract states 'over 3000 experiments' but the main text should explicitly break down how many runs per book-model pair and whether temperature or sampling parameters were fixed.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's report. We have addressed each of the major comments in detail below and plan to incorporate revisions to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Methods / Extraction Procedure] The central claim that Llama 3.1 70B 'entirely memorizes' books such as Harry Potter rests on short-prefix prompting producing near-verbatim output. The methods section does not appear to include controls that test whether semantically similar but non-exact prefixes (or paraphrased openings) elicit comparable long-range matches; without such tests it remains possible that the outputs reflect high-probability generation from general training on summaries and references rather than parameter-stored verbatim sequences. This directly affects the load-bearing distinction between memorization and plausible continuation.
Authors: We agree that distinguishing verbatim memorization from high-probability generation based on general knowledge is important. Our extraction method deliberately uses the exact opening token sequence from the source book to test for the presence of that specific sequence in the model parameters. To directly address the concern, we will add experiments in the revised manuscript that compare outputs from the exact prefix against paraphrased openings and semantically similar but non-identical prefixes. Preliminary checks indicate that only the exact prefix produces the long-range verbatim continuation, while paraphrases yield shorter or divergent text; we will report these controls to reinforce the memorization interpretation. revision: yes
-
Referee: [Results / Llama 3.1 70B Experiments] In the results for the Harry Potter case, quantitative metrics beyond qualitative 'near-verbatim' description (e.g., exact token-match rates per chapter, edit distance, or log-probability comparisons against random prefixes) are needed to substantiate the 'deterministically extract the whole book' assertion. The current presentation leaves open the possibility that partial or approximate matches are being interpreted as full-book memorization.
Authors: We accept that additional quantitative evidence would make the results more robust. In the revised manuscript we will include per-chapter exact token-match rates, Levenshtein edit distances to the original text, and similarity comparisons against generations from random and unrelated prefixes. These metrics show token overlap exceeding 95% across chapters for the reported Llama 3.1 70B cases when using the book prefix, with substantially lower overlap and higher edit distances under control conditions, thereby supporting the claim of near-deterministic full-book extraction. revision: yes
Circularity Check
Empirical measurement study with no derivation chain or self-referential reduction
full rationale
This paper reports an empirical measurement of memorization in open-weight LLMs by applying a prefix-based extraction technique across 200 books and 14 models in over 3000 experiments. The central findings, such as near-verbatim extraction from Llama 3.1 70B for certain books like Harry Potter, are grounded directly in observed model outputs rather than any mathematical derivation, fitted parameters renamed as predictions, or load-bearing self-citations. No equations, uniqueness theorems, or ansatzes are invoked that reduce the results to the inputs by construction; the methodology is presented as a direct procedure whose validity rests on external model behavior, making the work self-contained with no circular steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We develop a sliding-window procedure that computes probabilistic extraction along the length of a book... p_z ≜ Pr[ suffix | prefix ]
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Llama 3.1 70B entirely memorizes some books... deterministically extract the whole book almost verbatim
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
Improving LLM Unlearning Robustness via Random Perturbations
LLM unlearning is reframed as inadvertently installing backdoor triggers on forget-tokens; Random Noise Augmentation is introduced as a defense that improves robustness with theoretical guarantees.
-
A Human-Centric Framework for Data Attribution in Large Language Models
Introduces a parameter-driven framework for data attribution in LLMs that enables negotiation among creators, users, and intermediaries to meet stakeholder goals within the data economy.
-
Cheap Expertise: Mapping and Challenging Industry Perspectives in the Expert Data Gig Economy
AI data firms view human expertise as an extractable, low-cost resource to feed AI systems while treating institutional expertise as something needing liberation or reform to fit this model.
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J. Hewett, Mojan Javaheripi, Piero Kauffmann, James R. Lee, Yin Tat Lee, Yuanzhi Li, Weishung Liu, Caio C. T. Mendes, Anh Nguyen, Eric Price, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Xin Wang, Rachel Ward, Yue Wu, Dingli Yu,...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Anchor Books; Random House, Inc., 1958
Chinua Achebe.Things Fall Apart. Anchor Books; Random House, Inc., 1958
work page 1958
-
[3]
Pan Books; Pan Macmillan; William Heinemann Ltd, 1979
Douglas Adams.The Hitchhiker’s Guide to the Galaxy - Omnibus. Pan Books; Pan Macmillan; William Heinemann Ltd, 1979
work page 1979
- [4]
-
[5]
Oneworld Publications; Dar al-Hikma, 2016
Shahad Al Rawi.The Baghdad Clock. Oneworld Publications; Dar al-Hikma, 2016
work page 2016
-
[6]
URL https://huggingface.co/datasets/ amongglue/books3-subset-raw
amongglue/books3-subset-raw, 2025. URL https://huggingface.co/datasets/ amongglue/books3-subset-raw
work page 2025
-
[7]
Introducing 100K Context Windows, May 2023
Anthropic. Introducing 100K Context Windows, May 2023. URL https://www.anthropic. com/index/100k-context-windows/
work page 2023
- [8]
-
[9]
Bantam Dell; Random House, Inc.; Bantam Books, 1966
Isaac Asimov.Fantastic Voyage. Bantam Dell; Random House, Inc.; Bantam Books, 1966
work page 1966
-
[10]
Dream Letters Corporation; Dream Letters Corp., 1982
Isaac Asimov.The Complete Robot. Dream Letters Corporation; Dream Letters Corp., 1982
work page 1982
-
[11]
Houghton Mifflin Harcourt Publishing Company, 1985
Margaret Atwood.The Handmaid’s Tale. Houghton Mifflin Harcourt Publishing Company, 1985
work page 1985
- [12]
-
[13]
Google, Inc., 804 F.3d 202 (2d Cir
Author’s Guild v. Google, Inc., 804 F.3d 202 (2d Cir. 2015)
work page 2015
-
[14]
Warner Books, Inc.; Hachette Book Group, 2001
David Baldacci.The Christmas Train. Warner Books, Inc.; Hachette Book Group, 2001
work page 2001
- [15]
-
[16]
Michael Joseph; Penguin Books, 1962
James Baldwin.Another Country. Michael Joseph; Penguin Books, 1962
work page 1962
-
[17]
Julian Barnes.The Lemon Table. Vintage International, 2004
work page 2004
-
[18]
Fordham University Press, 2006
Teodolinda Barolini.Dante and the Origins of Italian Literary Culture. Fordham University Press, 2006
work page 2006
- [19]
- [20]
-
[21]
Grove Press; Grove/Atlantic, Inc., 1952
Samuel Beckett.Waiting for Godot. Grove Press; Grove/Atlantic, Inc., 1952
work page 1952
- [22]
-
[23]
BBC Books; BBC Worldwide Ltd, 2006
Mary Berry.Simple Cakes. BBC Books; BBC Worldwide Ltd, 2006
work page 2006
-
[24]
Pythia: A suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. Pythia: A suite for analyzing large language models across training and scaling. In International Conference on Machine Learning, pages 2397–2430. PMLR, 2023
work page 2023
-
[25]
La mecanique statique et l’irreversibilite.J
Emile Borel. La mecanique statique et l’irreversibilite.J. Phys. Theor. Appl., 3(1):189– 196, 1913. doi: 10.1051/jphystap:019130030018900. URL https://doi.org/10.1051/ jphystap:019130030018900
- [26]
-
[27]
William Morrow; HarperCollins e-books, 2004
Ray Bradbury.The Cat’s Pajamas. William Morrow; HarperCollins e-books, 2004. 19
work page 2004
-
[28]
Severn House Publishers Ltd, 2009
Gillian Bradshaw.London in Chains. Severn House Publishers Ltd, 2009
work page 2009
-
[29]
Pantheon Books; Random House of Canada Limited, 2006
John Brockman.My Einstein. Pantheon Books; Random House of Canada Limited, 2006
work page 2006
-
[30]
Transworld Publishers; Bantam Press; Corgi, 2003
Dan Brown.The Da Vinci Code. Transworld Publishers; Bantam Press; Corgi, 2003
work page 2003
-
[31]
Gareth Brown.The Society of Unknowable Objects. HarperCollins, 2025
work page 2025
-
[32]
Dafina Books; Kensington Publishing Corp., 2007
Niobia Bryant.Live and Learn. Dafina Books; Kensington Publishing Corp., 2007
work page 2007
- [33]
-
[34]
Penguin Classics; Penguin Books Ltd, 1942
Albert Camus.The Myth of Sisyphus. Penguin Classics; Penguin Books Ltd, 1942
work page 1942
-
[35]
URL https://huggingface.co/datasets/ CANBERT/pile_books3_text
CANBERT/pile_books3_text, 2025. URL https://huggingface.co/datasets/ CANBERT/pile_books3_text
work page 2025
-
[36]
What my privacy papers (don’t) have to say about copyright and gen- erative AI, 2025
Nicholas Carlini. What my privacy papers (don’t) have to say about copyright and gen- erative AI, 2025. URL https://nicholas.carlini.com/writing/2025/privacy- copyright-and-generative-models.html
work page 2025
-
[37]
Extracting training data from large language models
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-V oss, Kather- ine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, et al. Extracting training data from large language models. In30th USENIX Security Symposium (USENIX Security 21), pages 2633–2650, 2021
work page 2021
-
[38]
Membership Inference Attacks From First Principles, 2022
Nicholas Carlini, Steve Chien, Milad Nasr, Shuang Song, Andreas Terzis, and Florian Tramer. Membership Inference Attacks From First Principles, 2022. URL https://arxiv.org/ abs/2112.03570
-
[39]
Extracting Training Data from Diffusion Models, 2023
Nicholas Carlini, Jamie Hayes, Milad Nasr, Matthew Jagielski, Vikash Sehwag, Florian Tramèr, Borja Balle, Daphne Ippolito, and Eric Wallace. Extracting Training Data from Diffusion Models, 2023
work page 2023
-
[40]
Quantifying Memorization Across Neural Language Models
Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramèr, and Chiyuan Zhang. Quantifying Memorization Across Neural Language Models. InInternational Conference on Learning Representations, 2023
work page 2023
-
[41]
Penguin Classics; Penguin Books Ltd, 1871
Lewis Carroll.Alice’s Adventures in Wonderland and Through the Looking-Glass and What Alice Found There. Penguin Classics; Penguin Books Ltd, 1871
-
[42]
Jeffrey A. Carver.The Infinity Link. Open Road Integrated Media, Inc., 1984
work page 1984
-
[43]
Jacqueline Charlesworth. Generative AI’s Illusory Case for Fair Use.Vanderbilt Journal of Entertainment and Technology Law, 27, 2025
work page 2025
-
[44]
URLhttps://chatgptiseatingtheworld.com
Chat GPT Is Eating the World, 2024. URLhttps://chatgptiseatingtheworld.com
work page 2024
-
[45]
Agatha Christie.Murder on the Orient Express. HarperCollins e-books, 1933
work page 1933
-
[46]
Agatha Christie.And Then There Were None. HarperCollins e-books, 1939
work page 1939
-
[47]
Spiegel & Grau; Random House, Inc., 2008
Ta-Nehisi Coates.The Beautiful Struggle. Spiegel & Grau; Random House, Inc., 2008
work page 2008
-
[48]
One World; Random House; Penguin Random House LLC, 2017
Ta-Nehisi Coates.We Were Eight Years in Power. One World; Random House; Penguin Random House LLC, 2017
work page 2017
-
[49]
One World; Random House; Penguin Random House LLC, 2019
Ta-Nehisi Coates.The Water Dancer. One World; Random House; Penguin Random House LLC, 2019
work page 2019
-
[50]
New Directions; New Directions Publishing Corporation, 1963
Jean Cocteau.The Infernal Machine and Other Plays. New Directions; New Directions Publishing Corporation, 1963
work page 1963
-
[51]
HarperCollins Publishers, 1988
Paulo Coelho.The Alchemist. HarperCollins Publishers, 1988
work page 1988
-
[52]
Open Court Publishing Company, 2012
Jon Cogburn and Mark Silcox.Dungeons and Dragons and Philosophy. Open Court Publishing Company, 2012
work page 2012
-
[53]
Annie Cohen-Solal.Mark Rothko. Yale University Press, 2013
work page 2013
-
[54]
Capacity and Trainability in Recurrent Neural Networks
Jasmine Collins, Jascha Sohl-Dickstein, and David Sussillo. Capacity and Trainability in Recurrent Neural Networks, 2017. URLhttps://arxiv.org/abs/1611.09913
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[55]
Scholastic Children’s Books; Scholastic Ltd, 2008
Suzanne Collins.The Hunger Games. Scholastic Children’s Books; Scholastic Ltd, 2008
work page 2008
-
[56]
Concord Music Group, Inc. v. Anthropic PBC. 3:23-cv-01092 (M.D. Tenn.)
-
[57]
Glen Cook.The Dragon Never Sleeps. Night Shade Books, 1988. 20
work page 1988
-
[58]
Feder Cooper and James Grimmelmann
A. Feder Cooper and James Grimmelmann. The Files are in the Computer: Copyright, Memorization, and Generative AI.arXiv preprint arXiv:2404.12590, 2024
-
[59]
A. Feder Cooper, Katherine Lee, James Grimmelmann, Daphne Ippolito, Christopher Callison- Burch, Christopher A. Choquette-Choo, Niloofar Mireshghallah, Miles Brundage, David Mimno, Madiha Zahrah Choksi, Jack M. Balkin, Nicholas Carlini, Christopher De Sa, Jonathan Frankle, Deep Ganguli, Bryant Gipson, Andres Guadamuz, Swee Leng Harris, Abigail Z. Jacobs, ...
-
[60]
A. Feder Cooper, Christopher A. Choquette-Choo, Miranda Bogen, Matthew Jagielski, Katja Filippova, Ken Ziyu Liu, Alexandra Chouldechova, Jamie Hayes, Yangsibo Huang, Niloofar Mireshghallah, Ilia Shumailov, Eleni Triantafillou, Peter Kairouz, Nicole Mitchell, Percy Liang, Daniel E. Ho, Yejin Choi, Sanmi Koyejo, Fernando Delgado, James Grimmelmann, Vitaly S...
-
[61]
A. Feder Cooper, Mark A. Lemley, Christopher De Sa, Lea Duesterwald, Allison Casasola, Jamie Hayes, Katherine Lee, Daniel E. Ho, and Percy Liang. Estimating near-verbatim extraction risk in language models with decoding-constrained beam search.arXiv preprint arXiv:2603.24917, 2026
-
[62]
Copyright Law of the United States. 17 U.S. Code § 503 - Remedies for infringement: Impounding and disposition of infringing articles, December 2010. URL https://www.law. cornell.edu/uscode/text/17/503
work page 2010
-
[63]
CoStar Grp., Inc. v. LoopNet, Inc., 373 F.3d 544 (4th Cir. 2004)
work page 2004
-
[64]
Covey.The 7 Habits of Highly Effective People
Stephen R. Covey.The 7 Habits of Highly Effective People. RosettaBooks LLC, 1989
work page 1989
-
[65]
Toothpick Producers Violate NYT Copyright.Marignal Revolution, Decem- ber 2023
Tyler Cowen. Toothpick Producers Violate NYT Copyright.Marignal Revolution, Decem- ber 2023. URL https://marginalrevolution.com/marginalrevolution/2023/12/ toothpick-producers-violate-nyt-copyright.html
work page 2023
-
[66]
HarperCollins e-books; HarperCollins Publishers Inc., 2015
David Crabb.Bad Kid. HarperCollins e-books; HarperCollins Publishers Inc., 2015
work page 2015
-
[67]
Bantam Books; Random House, Inc., 1992
Robert Crais.Lullaby Town. Bantam Books; Random House, Inc., 1992
work page 1992
-
[68]
Ballantine Books; The Random House Publishing Group, 1990
Michael Crichton.Jurassic Park. Ballantine Books; The Random House Publishing Group, 1990
work page 1990
-
[69]
Picador; Farrar, Straus and Giroux, 1998
Michael Cunningham.The Hours. Picador; Farrar, Straus and Giroux, 1998
work page 1998
-
[70]
Amy B. Cyphert. Generative AI, Plagiarism, and Copyright Infringement in Legal Documents. Minnesota Journal of Law, Science & Technology, 25, 2024
work page 2024
-
[71]
New York Review Books; The New York Review of Books, 1949
Józef Czapski.Inhuman Land. New York Review Books; The New York Review of Books, 1949
work page 1949
- [72]
-
[73]
Puffin Books; Penguin Books Ltd, 1964
Roald Dahl.Charlie and the Chocolate Factory. Puffin Books; Penguin Books Ltd, 1964
work page 1964
-
[74]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
DeepSeek-AI et al. DeepSeek LLM: Scaling Open-Source Language Models with Longter- mism, 2024. URLhttps://arxiv.org/abs/2401.02954
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[75]
Harvard University Press, 2019
Nicholas Diakopoulos.Automating the News. Harvard University Press, 2019
work page 2019
-
[76]
Zola Books; Simon & Schuster, 1979
Joan Didion.The White Album. Zola Books; Simon & Schuster, 1979
work page 1979
-
[77]
Tor; Tom Doherty Associates, LLC, 2003
Cory Doctorow.Down and Out in the Magic Kingdom. Tor; Tom Doherty Associates, LLC, 2003
work page 2003
-
[78]
Carol Ann Duffy.The World’s Wife. Picador; Pan Macmillan, 1999
work page 1999
-
[79]
Riverhead Books; The Berkley Publishing Group, 1995
Junot Díaz.Drown. Riverhead Books; The Berkley Publishing Group, 1995
work page 1995
-
[80]
Riverhead Books; Penguin Group (USA) Inc., 2007
Junot Díaz.The Brief Wondrous Life of Oscar Wao. Riverhead Books; Penguin Group (USA) Inc., 2007. 21
work page 2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.