Sat2Sound: A Unified Framework for Zero-Shot Soundscape Mapping
Pith reviewed 2026-05-22 13:34 UTC · model grok-4.3
The pith
Sat2Sound learns shared soundscape concepts from satellite images, audio and text to map sounds at any Earth location without paired recordings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
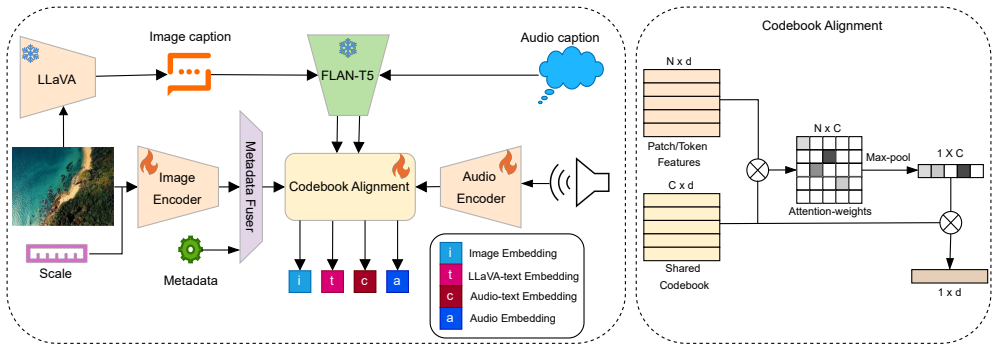
Sat2Sound is a unified multimodal framework that jointly learns from audio, text descriptions of audio, satellite images, and synthetic image captions through contrastive and codebook-aligned learning, discovering a set of soundscape concepts shared across modalities and thereby enabling hyper-localized, explainable soundscape mapping plus location-conditioned soundscape synthesis.
What carries the argument
soundscape concepts: shared representations discovered across audio, text, satellite images and synthetic captions via contrastive and codebook-aligned learning.
If this is right
- State-of-the-art cross-modal retrieval performance between satellite images and audio on the GeoSound and SoundingEarth benchmarks.
- Hyper-localized and explainable soundscape mapping directly from satellite imagery.
- Location-conditioned soundscape synthesis by retrieving detailed captions for rendering through text-to-audio models.
- Effective operation for immersive and educational applications even with limited computational resources.
Where Pith is reading between the lines
- The framework could reduce dependence on scarce geotagged audio by substituting model-generated descriptions for many locations.
- Historical satellite archives might allow reconstruction of past soundscapes using the same learned concepts.
- The concept-discovery mechanism could transfer to other geospatial multimodal tasks such as mapping visual or olfactory features.
Load-bearing premise
Vision-language models generate soundscape descriptions from satellite images that accurately broaden the diversity of ambient sounds at each location without introducing systematic biases.
What would settle it
Measuring cross-modal retrieval accuracy on a fresh set of real paired satellite-audio samples from unseen regions and finding that performance falls below prior methods that avoid generated descriptions would falsify the central claim.
Figures





read the original abstract
We present Sat2Sound, a unified multimodal framework for geospatial soundscape understanding, designed to predict and map the distribution of sounds across the Earth's surface. Existing methods for this task rely on paired satellite images and geotagged audio samples, which often fail to capture the full diversity of sound at a location. Sat2Sound overcomes this limitation by augmenting datasets with semantically rich, vision-language model-generated soundscape descriptions, which broaden the range of possible ambient sounds represented at each location. Our framework jointly learns from audio, text descriptions of audio, satellite images, and synthetic image captions through contrastive and codebook-aligned learning, discovering a set of "soundscape concepts" shared across modalities, enabling hyper-localized, explainable soundscape mapping. Sat2Sound achieves state-of-the-art performance in cross-modal retrieval between satellite image and audio on the GeoSound and SoundingEarth benchmarks. Finally, by retrieving detailed soundscape captions that can be rendered through text-to-audio models, Sat2Sound enables location-conditioned soundscape synthesis for immersive and educational applications, even with limited computational resources. Our code and models are available at https://github.com/mvrl/sat2sound.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Sat2Sound, a unified multimodal framework for geospatial soundscape understanding and zero-shot mapping. It augments limited paired satellite-image and geotagged-audio datasets with semantically rich soundscape descriptions generated by vision-language models, then jointly optimizes contrastive losses and codebook alignment across satellite images, real audio, text descriptions, and synthetic captions to discover shared 'soundscape concepts'. The framework claims state-of-the-art cross-modal retrieval performance between satellite images and audio on the GeoSound and SoundingEarth benchmarks and demonstrates downstream use for location-conditioned soundscape synthesis via text-to-audio rendering.
Significance. If the empirical claims hold, the work offers a practical route to increase acoustic diversity in geospatial audio datasets without additional field collection, enabling more explainable and hyper-localized soundscape mapping. The open release of code and models at the cited GitHub repository is a clear strength that supports reproducibility.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the claim of state-of-the-art retrieval performance on GeoSound and SoundingEarth is stated without any reported metrics (e.g., Recall@K, mAP), baselines, ablation tables, or statistical significance tests. This absence prevents assessment of whether the VLM-augmented descriptions actually drive the reported gains or whether the result is driven by implementation details.
- [§3.2 and §4.3] §3.2 (Method) and §4.3 (Ablations): no explicit ablation isolates the contribution of VLM-generated captions versus real audio-text pairs, nor is there a bias audit measuring how often generated descriptions introduce visually salient but acoustically implausible events. Without such controls, it remains possible that the learned soundscape codebook exploits VLM priors rather than genuine cross-modal correspondence, directly affecting the central claim of broadened acoustic diversity.
minor comments (2)
- [§3] Notation for the codebook and contrastive losses is introduced without an explicit equation numbering or diagram; a single consolidated figure showing the four-modality alignment would improve readability.
- [§2] The paper should cite prior work on vision-language augmentation for audio (e.g., recent CLAP or AudioCLIP extensions) to better situate the novelty of the joint image-audio-text codebook.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the presentation of our results and strengthen the supporting evidence for our claims. We respond to each major comment below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the claim of state-of-the-art retrieval performance on GeoSound and SoundingEarth is stated without any reported metrics (e.g., Recall@K, mAP), baselines, ablation tables, or statistical significance tests. This absence prevents assessment of whether the VLM-augmented descriptions actually drive the reported gains or whether the result is driven by implementation details.
Authors: We agree that the abstract would benefit from explicit numerical results. The full manuscript already reports Recall@K, mAP, and baseline comparisons in Tables 1–3 of §4, together with ablation tables. To address the concern directly, we will update the abstract to include the key quantitative gains (e.g., Recall@5 on both benchmarks) and add a short paragraph in §4 discussing statistical significance of the improvements attributable to the VLM-augmented captions versus implementation choices. revision: yes
-
Referee: [§3.2 and §4.3] §3.2 (Method) and §4.3 (Ablations): no explicit ablation isolates the contribution of VLM-generated captions versus real audio-text pairs, nor is there a bias audit measuring how often generated descriptions introduce visually salient but acoustically implausible events. Without such controls, it remains possible that the learned soundscape codebook exploits VLM priors rather than genuine cross-modal correspondence, directly affecting the central claim of broadened acoustic diversity.
Authors: We acknowledge the value of an isolated comparison. Section 4.3 already ablates loss terms and modality combinations; we will add a dedicated table that directly contrasts performance when VLM-generated captions are included versus when only real audio-text pairs are used. For the bias audit, we will insert a new qualitative analysis subsection that examines a sample of generated descriptions for acoustically implausible events and explains how joint contrastive training with real audio mitigates over-reliance on VLM priors. These additions will more rigorously support the diversity claim. revision: partial
Circularity Check
No significant circularity in empirical multimodal training pipeline
full rationale
The paper describes an empirical framework that augments paired satellite-audio data with VLM-generated text descriptions and trains a shared embedding space via contrastive and codebook losses. No derivation chain, first-principles equations, or 'predictions' are presented that reduce to fitted parameters or self-referential definitions by construction. Performance claims are evaluated on external benchmarks (GeoSound, SoundingEarth) rather than internal construction, and the method remains falsifiable against real audio distributions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vision-language models produce soundscape descriptions that are sufficiently accurate and diverse to augment real audio data effectively.
invented entities (1)
-
soundscape concepts
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our framework jointly learns from audio, text descriptions of audio, satellite images, and synthetic image captions through contrastive and codebook-aligned learning, discovering a set of 'soundscape concepts' shared across modalities
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ri_m = max_j (p_i^j · C_m); w_i^m = Softmax(Sparsemax(r_i))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Geo2Sound: A Scalable Geo-Aligned Framework for Soundscape Generation from Satellite Imagery
Geo2Sound generates geographically realistic soundscapes from satellite imagery via geospatial attribute modeling, semantic hypothesis expansion, and geo-acoustic alignment, achieving SOTA FAD of 1.765 on a new 20k-pa...
Reference graph
Works this paper leans on
-
[1]
Freesound, https://freesound.org. 6
-
[2]
Radio aporee: Maps - sounds of the world, https://aporee.org. 6
-
[3]
inaturalist, https://www.inaturalist.org. 6
-
[4]
Francesco Aletta, Tin Oberman, Andrew Mitchell, Mercede Erfanian, Matteo Lionello, Magdalena Kachlicka, and Jian Kang. Associations between soundscape experience and self-reported wellbeing in open public urban spaces: a field study.The Lancet, 394:S17, 2019. 1
work page 2019
-
[5]
Yuxiao Chen, Jianbo Yuan, Yu Tian, Shijie Geng, Xinyu Li, Ding Zhou, Dimitris N Metaxas, and Hongxia Yang. Revis- iting multimodal representation in contrastive learning: from patch and token embeddings to finite discrete tokens. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15095–15104, 2023. 1, 2, 4
work page 2023
-
[6]
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Yunfei Chu, Jin Xu, Xiaohuan Zhou, Qian Yang, Shil- iang Zhang, Zhijie Yan, Chang Zhou, and Jingren Zhou. Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models.arXiv preprint arXiv:2311.07919, 2023. 3, 6, 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Improved probabilistic image-text rep- resentations
Sanghyuk Chun. Improved probabilistic image-text rep- resentations. InThe Twelfth International Conference on Learning Representations, 2024. 2, 4
work page 2024
-
[8]
Probabilistic embeddings for cross-modal retrieval
Sanghyuk Chun, Seong Joon Oh, Rafael Sampaio De Rezende, Yannis Kalantidis, and Diane Larlus. Probabilistic embeddings for cross-modal retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8415–8424, 2021. 2
work page 2021
-
[9]
Yezhen Cong, Samar Khanna, Chenlin Meng, Patrick Liu, Erik Rozi, Yutong He, Marshall Burke, David B. Lobell, and Stefano Ermon. SatMAE: Pre-training transformers for tem- poral and multi-spectral satellite imagery. InAdvances in Neural Information Processing Systems, 2022. 1, 3, 7
work page 2022
-
[10]
Soham Deshmukh, Benjamin Elizalde, Rita Singh, and Huaming Wang. Pengi: An audio language model for audio tasks.Advances in Neural Information Processing Systems, 36:18090–18108, 2023. 3, 6, 1
work page 2023
-
[11]
Junyu Gao, Hao Yang, Maoguo Gong, and Xuelong Li. Audio–visual representation learning for anomaly events de- tection in crowds.Neurocomputing, 582:127489, 2024. 2
work page 2024
-
[12]
Imagebind: One embedding space to bind them all
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. Imagebind: One embedding space to bind them all. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15180–15190, 2023. 2, 3, 4, 7
work page 2023
-
[13]
Vec- tor quantized diffusion model for text-to-image synthesis
Shuyang Gu, Dong Chen, Jianmin Bao, Fang Wen, Bo Zhang, Dongdong Chen, Lu Yuan, and Baining Guo. Vec- tor quantized diffusion model for text-to-image synthesis. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 10696–10706, 2022. 2
work page 2022
-
[14]
Konrad Heidler, Lichao Mou, Di Hu, Pu Jin, Guangyao Li, Chuang Gan, Ji-Rong Wen, and Xiao Xiang Zhu. Self- supervised audiovisual representation learning for remote sensing data.International Journal of Applied Earth Ob- servation and Geoinformation, 116:103130, 2023. 3
work page 2023
-
[15]
Chia-Yu Hung, Navonil Majumder, Zhifeng Kong, Ambuj Mehrish, Rafael Valle, Bryan Catanzaro, and Soujanya Poria. Tangoflux: Super fast and faithful text to audio generation with flow matching and clap-ranked preference optimization. arXiv preprint arXiv:2412.21037, 2024. 6, 8, 1
-
[16]
Taming visually guided sound generation
Vladimir Iashin and Esa Rahtu. Taming visually guided sound generation. InThe 32st British Machine Vision Vir- tual Conference. BMV A Press, 2021. 2
work page 2021
-
[17]
Learning tri-modal embeddings for zero-shot soundscape mapping
Subash Khanal, Srikumar Sastry, Aayush Dhakal, and Nathan Jacobs. Learning tri-modal embeddings for zero-shot soundscape mapping. InBritish Machine Vision Conference (BMVC), 2023. 1, 2, 5, 8
work page 2023
-
[18]
Psm: Learning probabilistic embeddings for multi-scale zero-shot soundscape mapping
Subash Khanal, Xing Eric, Srikumar Sastry, Aayush Dhakal, Xiong Zhexiao, Adeel Ahmad, and Nathan Jacobs. Psm: Learning probabilistic embeddings for multi-scale zero-shot soundscape mapping. InACM Multimedia, 2024. 1, 2, 3, 4, 5, 6, 8
work page 2024
-
[19]
Mayuri Kotian, Siddharth Biniwale, Pravar Mourya, Zuzana Burivalova, and Pooja Choksi. Measuring biodiversity with sound: How effective are acoustic indices for quantifying biodiversity in a tropical dry forest?Conservation Science and Practice, 6(6):e13133, 2024. 1
work page 2024
-
[20]
Junnan Li, Ramprasaath Selvaraju, Akhilesh Gotmare, Shafiq Joty, Caiming Xiong, and Steven Chu Hong Hoi. Align before fuse: Vision and language representation learn- ing with momentum distillation.Advances in neural infor- mation processing systems, 34:9694–9705, 2021. 2
work page 2021
-
[21]
Advancing multi-grained alignment for contrastive language-audio pre-training
Yiming Li, Zhifang Guo, Xiangdong Wang, and Hong Liu. Advancing multi-grained alignment for contrastive language-audio pre-training. InProceedings of the 32nd ACM International Conference on Multimedia, pages 7356– 7365, 2024. 2, 4, 1, 3, 7
work page 2024
-
[22]
Cross-modal dis- crete representation learning
Alex Liu, SouYoung Jin, Cheng-I Lai, Andrew Rou- ditchenko, Aude Oliva, and James Glass. Cross-modal dis- crete representation learning. InProceedings of the 60th An- nual Meeting of the Association for Computational Linguis- tics (Volume 1: Long Papers), pages 3013–3035, 2022. 2
work page 2022
-
[23]
Visual instruction tuning.Advances in neural information processing systems, 36, 2024
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36, 2024. 3, 1
work page 2024
-
[24]
From softmax to sparsemax: A sparse model of attention and multi-label clas- sification
Andre Martins and Ramon Astudillo. From softmax to sparsemax: A sparse model of attention and multi-label clas- sification. InInternational conference on machine learning, pages 1614–1623. PMLR, 2016. 4, 2
work page 2016
-
[25]
Pierluigi Morano, Francesco Tajani, Felicia Di Liddo, and Michele Dar `o. Economic evaluation of the indoor environ- mental quality of buildings: The noise pollution effects on housing prices in the city of bari (italy).Buildings, 11(5): 213, 2021. 1 9
work page 2021
-
[26]
Rethinking transformers pre-training for multi- spectral satellite imagery
Mubashir Noman, Muzammal Naseer, Hisham Cholakkal, Rao Muhammad Anwar, Salman Khan, and Fahad Shah- baz Khan. Rethinking transformers pre-training for multi- spectral satellite imagery. InCVPR, 2024. 3, 7
work page 2024
-
[27]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Repre- sentation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018. 4
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[28]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021. 2, 4
work page 2021
-
[29]
Scale-mae: A scale-aware masked autoencoder for multiscale geospatial representation learning
Colorado J Reed, Ritwik Gupta, Shufan Li, Sarah Brock- man, Christopher Funk, Brian Clipp, Kurt Keutzer, Salvatore Candido, Matt Uyttendaele, and Trevor Darrell. Scale-mae: A scale-aware masked autoencoder for multiscale geospatial representation learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4088– 4099, 2023. 1
work page 2023
-
[30]
Adam Roberts, Hyung Won Chung, Gaurav Mishra, Anselm Levskaya, James Bradbury, Daniel Andor, Sharan Narang, Brian Lester, Colin Gaffney, Afroz Mohiuddin, et al. Scaling up models and data with t5x and seqio.Journal of Machine Learning Research, 24(377):1–8, 2023. 1
work page 2023
-
[31]
A multimodal approach to mapping soundscapes
Tawfiq Salem, Menghua Zhai, Scott Workman, and Nathan Jacobs. A multimodal approach to mapping soundscapes. InProceedings of the IEEE Conference on Computer Vi- sion and Pattern Recognition Workshops, pages 2524–2527,
-
[32]
Taxabind: A unified embedding space for ecological applications
Srikumar Sastry, Subash Khanal, Aayush Dhakal, Adeel Ah- mad, and Nathan Jacobs. Taxabind: A unified embedding space for ecological applications. In2025 IEEE/CVF Win- ter Conference on Applications of Computer Vision (WACV), pages 1765–1774. IEEE, 2025. 3, 4, 7
work page 2025
-
[33]
I hear your true colors: Im- age guided audio generation
Roy Sheffer and Yossi Adi. I hear your true colors: Im- age guided audio generation. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023. 2
work page 2023
-
[34]
Sound to visual scene genera- tion by audio-to-visual latent alignment
Kim Sung-Bin, Arda Senocak, Hyunwoo Ha, Andrew Owens, and Tae-Hyun Oh. Sound to visual scene genera- tion by audio-to-visual latent alignment. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6430–6440, 2023. 2
work page 2023
-
[35]
Shamma, Gerald Friedland, Ben- jamin Elizalde, Karl Ni, Douglas Poland, Damian Borth, and Li-Jia Li
Bart Thomee, David A. Shamma, Gerald Friedland, Ben- jamin Elizalde, Karl Ni, Douglas Poland, Damian Borth, and Li-Jia Li. YFCC100M: The new data in multimedia research. Communications of the ACM, 59(2):64–73, 2016. 6
work page 2016
-
[36]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muham- mad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language en- coders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025. 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning.Advances in neural information pro- cessing systems, 30, 2017. 2
work page 2017
-
[38]
Vicente Vivanco Cepeda, Gaurav Kumar Nayak, and Mubarak Shah. Geoclip: Clip-inspired alignment be- tween locations and images for effective worldwide geo- localization.Advances in Neural Information Processing Systems, 36, 2024. 2
work page 2024
-
[39]
V2a-mapper: A lightweight solution for vision-to-audio generation by connecting foun- dation models
Heng Wang, Jianbo Ma, Santiago Pascual, Richard Cartwright, and Weidong Cai. V2a-mapper: A lightweight solution for vision-to-audio generation by connecting foun- dation models. InProceedings of the AAAI Conference on Artificial Intelligence, pages 15492–15501, 2024. 2
work page 2024
-
[40]
Yusong Wu*, Ke Chen*, Tianyu Zhang*, Yuchen Hui*, Tay- lor Berg-Kirkpatrick, and Shlomo Dubnov. Large-scale con- trastive language-audio pretraining with feature fusion and keyword-to-caption augmentation. InIEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP, 2023. 3, 7
work page 2023
-
[41]
Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, and Shlomo Dubnov. Large-scale con- trastive language-audio pretraining with feature fusion and keyword-to-caption augmentation. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023. 3, 1
work page 2023
-
[42]
Yan Xia, Hai Huang, Jieming Zhu, and Zhou Zhao. Achiev- ing cross modal generalization with multimodal unified rep- resentation.Advances in Neural Information Processing Sys- tems, 36, 2024. 2
work page 2024
-
[43]
Dongchao Yang, Jianwei Yu, Helin Wang, Wen Wang, Chao Weng, Yuexian Zou, and Dong Yu. Diffsound: Discrete diffusion model for text-to-sound generation.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31:1720–1733, 2023. 2
work page 2023
-
[44]
Filip: Fine-grained interactive language-image pre-training
Lewei Yao, Runhui Huang, Lu Hou, Guansong Lu, Minzhe Niu, Hang Xu, Xiaodan Liang, Zhenguo Li, Xin Jiang, and Chunjing Xu. Filip: Fine-grained interactive language-image pre-training.arXiv preprint arXiv:2111.07783, 2021. 1, 2
-
[45]
Jiahui Yu, Zirui Wang, Vijay Vasudevan, Legg Yeung, Mo- jtaba Seyedhosseini, and Yonghui Wu. Coca: Contrastive captioners are image-text foundation models.Transactions on Machine Learning Research, 2022. 2
work page 2022
-
[46]
Donghuo Zeng, Jianming Wu, Gen Hattori, Rong Xu, and Yi Yu. Learning explicit and implicit dual common subspaces for audio-visual cross-modal retrieval.ACM Transactions on Multimedia Computing, Communications and Applications, 19(2s):1–23, 2023. 2
work page 2023
-
[47]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023. 4
work page 2023
-
[48]
Audio-synchronized visual animation
Lin Zhang, Shentong Mo, Yijing Zhang, and Pedro Mor- gado. Audio-synchronized visual animation. InEuropean Conference on Computer Vision, pages 1–18. Springer, 2025. 2 10 Sat2Sound: A Unified Framework for Zero-Shot Soundscape Mapping Supplementary Material
work page 2025
-
[49]
Experimental Details Datasets:We experiment with two datasets:GeoSoundand SoundingEarth.GeoSoundcontains294019/5000/9931 train/validation/test samples and uses both0.6mGSD (Ground Sample Distance)Bingimage tiles (1500×1500) and10mGSDSentinel-2image tiles (1280×1280). SoundingEarthwith0.2mGSDGoogle Earthsatellite im- age tiles of size (1024×1024) contains4...
-
[50]
or Qwen-Audio [6], with the caption selection based on the caption’s CLAP score [41] with the ground-truth audio. For theGeoSounddataset, this resulted in 58.7% of audio captions from Pengi, 23.8% from Qwen-Audio, and 17.5% from human-annotated text. Image Captions:For the cropped satellite images at each scale, we generate detailed soundscape cap- tions ...
-
[51]
Ablation Studies 9.1. Loss Ablation We conduct an ablation study on different components of the loss to assess their impact on the overall training ob- jective (Equation 9). We observe that the addition of the composite audio-based loss (L † i,a+c) slightly improves the performance of the standard audio-image cross-modal re- trieval as observed in Table 4...
-
[52]
Simpler Baselines In this section, we compare the performance of Sat2Sound with existing off-the-shelf multimodal em- bedding spaces. As shown in the image-text cross-modal retrieval results (Table 10), existing pre-trained image-text models underperform compared to Sat2Sound. We attribute this to the mismatch between the soundscape descriptions generated...
-
[53]
The results presented in the main paper are for satellite imagery at scale1
Multi-scale Cross-Modal Retrieval Sat2Sound is trained on multi-scale satellite imagery for the GeoSound dataset. The results presented in the main paper are for satellite imagery at scale1. In this section, we present results for two additional scales:3and5, us- ing both Sentinel and Bing imagery from the GeoSound dataset. Additionally, for both datasets...
-
[54]
In this section, we qualitatively explore what the codebook has learned
Analyzing codebook concepts As illustrated in Figure 4, the codebook learned by Sat2Sound can be used to generate fine-grained soundscape maps for regions covered by a single satellite image. In this section, we qualitatively explore what the codebook has learned. Specifically, for our gallery of image captions, we first obtain the corresponding codebook ...
-
[55]
Linear Probing Experiments Sat2Sound learns a multimodal embedding space between audio and satellite imagery. We evaluate these embeddings on two downstream tasks: audio classification and satellite image classification, using linear probing on the audio and image embeddings, respectively. For audio classification, we compare the Sat2Sound audio encoder a...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.