Through a Compressed Lens: Investigating The Impact of Quantization on Factual Knowledge Recall
Pith reviewed 2026-05-22 14:10 UTC · model grok-4.3
The pith
Quantization of LLMs typically reduces factual knowledge recall through information loss, with stronger effects in smaller models, though some low-precision versions improve performance and BitSandBytes preserves it best.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Quantization typically results in information loss within LLMs, consequently diminishing their capacity for factual knowledge recall. This effect is particularly amplified in smaller models within the same architectural families. However, models quantized at reduced bit precision do not consistently exhibit inferior performance and occasionally quantization may even enhance model factual knowledge recall. BitSandBytes demonstrates the highest preservation of the original full-precision model's factual knowledge recall.
What carries the argument
Factual knowledge recall measured on knowledge memorization and latent multi-hop reasoning tasks, combined with interpretability analyses, to track how quantization alters stored knowledge access.
If this is right
- Smaller models in a family lose more factual recall capacity under quantization than their larger counterparts.
- BitSandBytes maintains closer fidelity to full-precision factual recall than the other quantization approaches examined.
- Lower bit widths sometimes produce better factual recall than higher ones, so bit precision alone does not predict performance.
- Overall performance degradation remains modest, supporting continued use of quantization for model compression.
- Interpretability tools can surface where quantization erodes specific knowledge pathways in the model.
Where Pith is reading between the lines
- Developers choosing quantization for deployment may want to test factual recall on target tasks rather than relying on general benchmarks.
- The observed variability across model families suggests that quantization decisions could be tuned per architecture to protect knowledge-intensive uses.
- If the pattern holds, hybrid approaches that apply lighter quantization only to certain layers might further limit factual recall loss.
Load-bearing premise
The two chosen tasks plus the interpretability analyses isolate factual knowledge recall without being confounded by other quantization effects such as altered attention patterns or output calibration.
What would settle it
A follow-up experiment on the same models and tasks that finds no measurable drop in factual recall after quantization at any tested bit width, or that shows another method consistently outperforming BitSandBytes, would undermine the reported typical degradation pattern.
Figures












read the original abstract
Quantization methods are widely used to accelerate inference and streamline the deployment of large language models (LLMs). Although quantization's effects on various LLM capabilities have been extensively studied, one critical area remains underexplored: factual knowledge recall (FKR), the process by which LLMs access stored knowledge. To this end, we conduct comprehensive experiments using three common quantization techniques at distinct bit widths, in conjunction with interpretability-driven analyses on two tasks, knowledge memorization and latent multi-hop reasoning. We show that quantization typically results in information loss within LLMs, consequently diminishing their capacity for FKR. This effect is particularly amplified in smaller models within the same architectural families. However, models quantized at reduced bit precision do not consistently exhibit inferior performance and occasionally quantization may even enhance model FKR. We find that BitSandBytes demonstrates highest preservation of the original full-precision model's FKR. Despite variability across models and methods, quantization causes modest performance degradation and remains an effective compression strategy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study on the effects of quantization on factual knowledge recall (FKR) in LLMs. Using three quantization techniques at various bit widths, the authors evaluate performance on knowledge memorization and latent multi-hop reasoning tasks, complemented by interpretability analyses. They report that quantization generally leads to information loss and reduced FKR, with greater impact on smaller models, but note that lower precision does not always degrade performance and can sometimes improve it. BitSandBytes is identified as the method that best preserves FKR, with overall modest degradation.
Significance. This work addresses an important gap in understanding how model compression affects the retention and recall of factual knowledge, which is critical for the reliability of LLMs in knowledge-intensive applications. If the findings are robust, they could guide the selection of quantization methods to minimize knowledge loss, and the observation of occasional performance gains opens avenues for further research into beneficial compression effects.
major comments (2)
- The central claim that quantization diminishes FKR rests on the knowledge-memorization and latent multi-hop tasks plus interpretability analyses isolating recall specifically. However, the manuscript provides no explicit controls or demonstrations (e.g., matching output distributions or correlating attention changes with FKR scores) to rule out confounds from quantization-induced shifts in attention weights, logit scales, or generation dynamics; without these, attribution to stored-fact loss rather than other effects remains unverified.
- Across the reported experiments, the manuscript does not include statistical tests, error bars, or details on multiple runs/variance; this makes it impossible to assess whether the observed variability, occasional gains, or method rankings (e.g., BitSandBytes) reflect reliable differences or task-specific artifacts.
minor comments (2)
- The abstract and results sections would benefit from clearer quantitative baselines comparing quantized models directly to full-precision performance on the same metrics.
- Notation for the two tasks and interpretability metrics could be standardized for easier cross-reference between sections.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which highlights important aspects for strengthening the robustness of our claims. We address each major comment point by point below, indicating where revisions have been made to the manuscript.
read point-by-point responses
-
Referee: The central claim that quantization diminishes FKR rests on the knowledge-memorization and latent multi-hop tasks plus interpretability analyses isolating recall specifically. However, the manuscript provides no explicit controls or demonstrations (e.g., matching output distributions or correlating attention changes with FKR scores) to rule out confounds from quantization-induced shifts in attention weights, logit scales, or generation dynamics; without these, attribution to stored-fact loss rather than other effects remains unverified.
Authors: We agree that additional explicit controls would further strengthen the causal attribution to factual knowledge loss. Our knowledge-memorization task directly probes stored facts via cloze-style completion, and the latent multi-hop task requires chaining recalled facts, while interpretability analyses examine representation changes. To address potential confounds, the revised manuscript now includes new analyses correlating attention weight shifts and logit scale changes with FKR degradation scores. These demonstrate that although generation dynamics are impacted, the dominant effect on FKR aligns with degraded internal fact representations rather than solely output distribution shifts. We have also clarified the experimental setup regarding decoding parameters to minimize generation-related variability. revision: yes
-
Referee: Across the reported experiments, the manuscript does not include statistical tests, error bars, or details on multiple runs/variance; this makes it impossible to assess whether the observed variability, occasional gains, or method rankings (e.g., BitSandBytes) reflect reliable differences or task-specific artifacts.
Authors: We acknowledge this limitation in the original submission. Each quantization configuration was evaluated in a single run owing to substantial computational costs associated with quantizing and evaluating multiple LLMs. In the revised manuscript, we have added bootstrap resampling-based error bars on all reported metrics and included statistical significance tests (paired comparisons via McNemar's test) for key method rankings and performance differences. We also explicitly discuss cross-model variability as a limitation and note that occasional gains, while observed, warrant further investigation in future work. revision: partial
Circularity Check
No circularity: empirical measurements with no derivations or self-referential predictions
full rationale
The paper reports results from direct experiments applying three quantization methods at varying bit widths to LLMs, then measuring factual knowledge recall on knowledge memorization and latent multi-hop reasoning tasks plus interpretability analyses. All central claims (typical degradation, occasional gains, BitSandBytes preserving FKR best) are presented as outcomes of these measurements rather than predictions derived from fitted parameters or equations. No self-definitional steps, fitted-input predictions, load-bearing self-citations, uniqueness theorems, or smuggled ansatzes appear in the described methodology or results. The study is self-contained against external benchmarks via the reported task performance and analyses.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We show that quantization typically results in information loss within LLMs, consequently diminishing their capacity for FKR... BitSandBytes demonstrates highest preservation
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
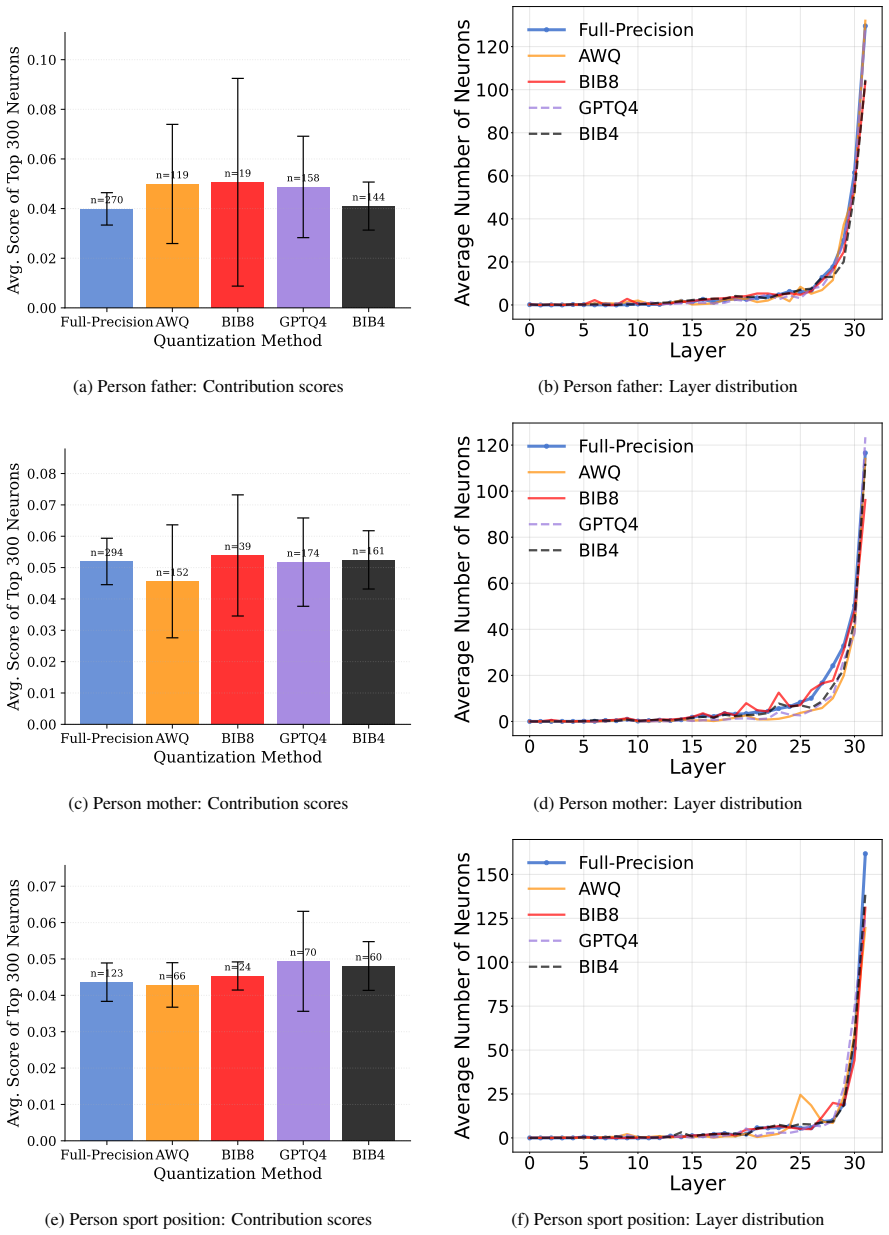
Neuron-level Trends... contribution score equal to the increase in log-probability... top-300 feed-forward neurons
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Do all autoregressive transformers remember facts the same way? a cross-architecture analysis of recall mechanisms. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 28494–28513, Suzhou, China. Association for Computational Linguistics. Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer
work page 2025
-
[2]
Under- standing the effect of model compression on social bias in large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2663–2675, Singapore. Association for Computational Linguistics. R.M. Gray and D.L. Neuhoff
work page 2023
-
[3]
A com- prehensive evaluation of quantization strategies for large language models. InFindings of the Associa- tion for Computational Linguistics: ACL 2024, pages 12186–12215, Bangkok, Thailand. Association for Computational Linguistics. Elisabeth Kirsten, Ivan Habernal, Vedant Nanda, and Muhammad Bilal Zafar
work page 2024
-
[4]
The impact of infer- ence acceleration on bias of LLMs. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Lin- guistics: Human Language Technologies (Volume 1: Long Papers), pages 1834–1853, Albuquerque, New Mexico. Association for Computational Linguistics. Qun Li, Yuan Meng, Chen Tang, Jiach...
work page 2025
-
[5]
Do emergent abilities exist in quantized large language models: An empirical study. InProceedings of the 2024 Joint International Con- ference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 5174–5190, Torino, Italia. ELRA and ICCL. Kelly Marchisio, Saurabh Dash, Hongyu Chen, Den- nis Aumiller, Ahmet Üstün, Sara H...
work page 2024
-
[6]
Association for Computational Linguistics
How does quantization affect multilingual LLMs? InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 15928–15947, Miami, Florida, USA. Association for Computational Linguistics. Satya Sai Srinath Namburi, Makesh Sreedhar, Srinath Srinivasan, and Frederic Sala
work page 2024
-
[7]
The cost of compression: Investigating the impact of compres- sion on parametric knowledge in language models. InFindings of the Association for Computational Lin- guistics: EMNLP 2023, pages 5255–5273, Singapore. Association for Computational Linguistics. Sein Park, Yeongsang Jang, and Eunhyeok Park
work page 2023
-
[8]
InComputer Vision – ECCV 2022, pages 206–222, Cham
Symmetry regularization and saturating nonlinear- ity for robust quantization. InComputer Vision – ECCV 2022, pages 206–222, Cham. Springer Nature Switzerland. Qwen, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi ...
work page 2022
-
[9]
Qwen2.5 technical report.Preprint, arXiv:2412.15115. Krithika Ramesh, Arnav Chavan, Shrey Pandit, and Sunayana Sitaram
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han
Can large language mod- els still explain themselves? investigating the im- pact of quantization on self-explanations.Preprint, arXiv:2601.00282. Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han
-
[11]
Neuron-level knowledge attribution in large language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 3267–3280, Miami, Florida, USA. Association for Computational Linguistics. Xunyu Zhu, Jian Li, Yong Liu, Can Ma, and Weiping Wang
work page 2024
-
[12]
C.2 Latent Multi-hop Reasoning Table 3 shows the latent multi-hop reasoning ac- curacy comparison between full-precision models and quantized models. Additionally, Figure 11, Fig- ure 12, and Figure 13 display the differences in the entity recall score,consistency score, andaccuracy between the AWQ, GPTQ8, GPTQ4, bib8, bib4 quan- tized and full-precision ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.