Data Mixing Can Induce Phase Transitions in Knowledge Acquisition
Pith reviewed 2026-05-19 13:08 UTC · model grok-4.3
The pith
Training LLMs on mixtures of web data and knowledge-dense sources can produce sudden phase transitions in how much specific knowledge gets acquired, rather than smooth scaling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
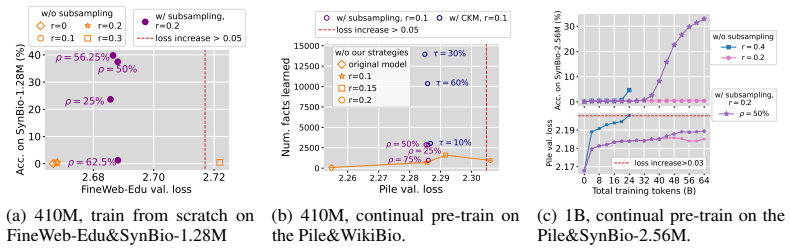
When LLMs train on mixtures of web-scraped data and a knowledge-dense biography set, the fraction of biographies memorized does not increase smoothly with model size or biography proportion; instead, it exhibits sharp transitions at critical values of both. Below a critical mixing ratio the model memorizes almost none even after long training, while above the threshold it rapidly acquires many more; similarly, increasing model size past a critical point causes a jump from very low to high memorization. The authors attribute the jumps to bounded capacity forcing discontinuous optimal allocation across the two data sources to minimize overall test loss, and they derive that the critical mixing
What carries the argument
Capacity allocation mechanism in which the model acts like a knapsack solver whose optimal split between general and knowledge-dense data changes discontinuously with model size or mixing ratio.
If this is right
- Mixing ratios that are optimal for large models can be far from optimal for small models, and the reverse also holds.
- The location of the transition thresholds can be estimated in advance from the power-law relation without exhaustive search.
- Knowledge acquisition from the dense subset can remain near zero for long training runs if the mixing ratio stays below the critical value.
- The same capacity-allocation logic predicts that other knowledge-dense sources mixed with web data will display analogous jumps.
Where Pith is reading between the lines
- Real-world training runs that gradually change data composition over time could be designed to cross these thresholds deliberately.
- The power-law scaling of critical ratios offers a way to forecast how much high-quality data a target-sized model will need before it begins to acquire the embedded knowledge.
- If the knapsack view generalizes, curriculum schedules that front-load or back-load knowledge-dense data might produce different final performance than constant mixtures.
Load-bearing premise
The phase transitions arise because the model must solve a knapsack-style capacity allocation problem whose optimum jumps discontinuously, rather than because of artifacts in how the synthetic biographies were constructed or because of smooth features in the loss landscape.
What would settle it
Train models at sizes and mixing ratios straddling the predicted critical values and measure whether the fraction of memorized biographies shows an abrupt jump whose location follows the reported power-law relation between critical ratio and model size.
Figures











read the original abstract
Large Language Models (LLMs) are typically trained on data mixtures: most data come from web scrapes, while a small portion is curated from high-quality sources with dense domain-specific knowledge. In this paper, we show that when training LLMs on such data mixtures, knowledge acquisition from knowledge-dense datasets, unlike training exclusively on knowledge-dense data (arXiv:2404.05405), does not always follow a smooth scaling law but can exhibit phase transitions with respect to the mixing ratio and model size. Through controlled experiments on a synthetic biography dataset mixed with web-scraped data, we demonstrate that: (1) as we increase the model size to a critical value, the model suddenly transitions from memorizing very few to most of the biographies; (2) below a critical mixing ratio, the model memorizes almost nothing even with extensive training, but beyond this threshold, it rapidly memorizes more biographies. We attribute these phase transitions to a capacity allocation phenomenon: a model with bounded capacity must act like a knapsack problem solver to minimize the overall test loss, and the optimal allocation across datasets can change discontinuously as the model size or mixing ratio varies. We formalize this intuition in an information-theoretic framework and reveal that these phase transitions are predictable, with the critical mixing ratio following a power-law relationship with the model size. Our findings highlight a concrete case where a good mixing recipe for large models may not be optimal for small models, and vice versa.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs trained on mixtures of web-scraped data and knowledge-dense synthetic biography datasets exhibit phase transitions in knowledge acquisition (biography memorization) as functions of model size and mixing ratio, unlike the smooth scaling seen in pure knowledge-dense training. These transitions are attributed to a bounded-capacity model solving a discontinuous knapsack-like allocation problem across data sources to minimize test loss. An information-theoretic framework is used to predict that the critical mixing ratio follows a power-law dependence on model size, with supporting evidence from controlled synthetic experiments showing abrupt jumps in memorization.
Significance. If the observed jumps are robust and the information-theoretic prediction holds with a parameter-free derivation, the result would be significant for LLM pretraining practice: it implies that data-mixing recipes are not scale-invariant and that small and large models may require qualitatively different mixtures. The synthetic biography construction is a strength for isolating the effect, though the lack of direct comparison to real web data limits immediate applicability.
major comments (3)
- [information-theoretic framework section] The information-theoretic framework (formalized after the capacity-allocation intuition) presents the power-law scaling of the critical mixing ratio as a prediction, yet provides no explicit parameter-free derivation from the loss function or capacity constraint; the reported relationship is consistent with fitting the observed thresholds, which undermines the claim that the framework predicts rather than post-dicts the transitions.
- [capacity allocation explanation] The central mechanistic claim—that the model acts as a knapsack solver whose optimal allocation changes discontinuously—lacks a derived mapping from the cross-entropy loss and discrete fact structure of the biographies to the claimed optimal split; without this, the phase-transition interpretation cannot be distinguished from a steep but continuous transition induced by the interaction of loss landscape and data discreteness.
- [controlled experiments section] Synthetic experiments demonstrate jumps in biography memorization, but report no error bars across random seeds, no ablation on biography construction details, and no direct comparison to real web-scale data mixtures; these omissions make it difficult to assess whether the transitions are load-bearing for the claimed mechanism or artifacts of the controlled setup.
minor comments (2)
- [abstract] The abstract states that 'the critical mixing ratio following a power-law relationship with the model size' is revealed by the framework, but the main text should clarify whether this is an exact analytic result or an empirical fit.
- [figures and equations] Notation for the mixing ratio and model size in the power-law relation should be defined consistently between the framework and the experimental plots.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which has helped us identify areas for clarification and improvement. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [information-theoretic framework section] The information-theoretic framework (formalized after the capacity-allocation intuition) presents the power-law scaling of the critical mixing ratio as a prediction, yet provides no explicit parameter-free derivation from the loss function or capacity constraint; the reported relationship is consistent with fitting the observed thresholds, which undermines the claim that the framework predicts rather than post-dicts the transitions.
Authors: We agree that the framework derives the power-law form under explicit modeling assumptions regarding capacity allocation and loss minimization, rather than offering a fully parameter-free derivation obtained directly from the cross-entropy loss without any intermediate choices. The goal is to formalize the knapsack intuition into a predictive scaling relationship that is then validated on the controlled experiments. In the revised manuscript we will expand the section to state all assumptions clearly, adjust the wording to emphasize that the framework predicts the functional dependence on model size, and note that exact numerical parameters are determined empirically. revision: yes
-
Referee: [capacity allocation explanation] The central mechanistic claim—that the model acts as a knapsack solver whose optimal allocation changes discontinuously—lacks a derived mapping from the cross-entropy loss and discrete fact structure of the biographies to the claimed optimal split; without this, the phase-transition interpretation cannot be distinguished from a steep but continuous transition induced by the interaction of loss landscape and data discreteness.
Authors: The knapsack analogy is offered as a high-level mechanistic account of why bounded capacity can produce abrupt changes in allocation. We do not provide a closed-form mapping from the per-fact cross-entropy loss to the exact optimal split, as that would require solving a non-convex combinatorial optimization problem at each training step. The information-theoretic abstraction is intended to capture the essential trade-off that gives rise to thresholds. We acknowledge that distinguishing a true phase transition from a steep continuous transition is non-trivial and will add a dedicated paragraph discussing this alternative interpretation together with evidence from the controlled setting that favors the discontinuous-allocation view. revision: partial
-
Referee: [controlled experiments section] Synthetic experiments demonstrate jumps in biography memorization, but report no error bars across random seeds, no ablation on biography construction details, and no direct comparison to real web-scale data mixtures; these omissions make it difficult to assess whether the transitions are load-bearing for the claimed mechanism or artifacts of the controlled setup.
Authors: We thank the referee for highlighting these gaps in experimental reporting. In the revision we will add error bars computed across at least three random seeds for all key figures and will include an ablation study varying biography length, fact density, and repetition rate. A direct comparison to real web-scale mixtures is not feasible within the present study because it would require training runs at full scale with controllable knowledge density, which exceeds available compute; the synthetic biography construction was deliberately chosen to isolate the mixing effect while maintaining experimental control. revision: partial
Circularity Check
Power-law critical mixing ratio presented as framework prediction but consistent with post-hoc fit to observed thresholds
specific steps
-
fitted input called prediction
[Abstract]
"We formalize this intuition in an information-theoretic framework and reveal that these phase transitions are predictable, with the critical mixing ratio following a power-law relationship with the model size."
The framework is said to predict the power-law, yet no closed-form derivation independent of the observed critical points is exhibited; the relationship is consistent with fitting the thresholds identified in the controlled experiments on the synthetic dataset.
full rationale
The paper's central claim is that an information-theoretic framework predicts phase transitions and a power-law relationship for the critical mixing ratio. However, the provided abstract and context give no parameter-free derivation from the knapsack analogy or loss function; the power-law is instead shown to match experimental thresholds. This creates moderate circularity risk because the 'prediction' reduces to a fitted functional form on the same data used to identify the transitions, without an independent derivation that would hold outside the synthetic biography setup.
Axiom & Free-Parameter Ledger
free parameters (1)
- critical mixing ratio threshold
axioms (1)
- domain assumption A model with bounded capacity must allocate it across datasets in a manner analogous to a knapsack solver whose optimum can change discontinuously.
Forward citations
Cited by 3 Pith papers
-
Towards Understanding Continual Factual Knowledge Acquisition of Language Models: From Theory to Algorithm
Theoretical analysis of continual factual knowledge acquisition shows data replay stabilizes pretrained knowledge by shifting convergence dynamics while regularization only slows forgetting, leading to the STOC method...
-
Cram Less to Fit More: Training Data Pruning Improves Memorization of Facts
Loss-based pruning of training data to limit facts and flatten their frequency distribution enables a 110M-parameter GPT-2 model to memorize 1.3 times more entity facts than standard training, matching a 1.3B-paramete...
-
Capacity-Aware Mixture Law Enables Efficient LLM Data Optimization
CAMEL is a scaling law capturing nonlinear model-size and mixture interactions to extrapolate optimal data mixtures for large LLMs from small-model experiments, reducing optimization cost by 50% and improving benchmar...
Reference graph
Works this paper leans on
-
[1]
Association for Computational Linguistics. Xintong Hao, Ruijie Zhu, Ge Zhang, Ke Shen, and Chenggang Li. Reformulation for pretraining data augmentation.arXiv preprint arXiv:2502.04235, 2025. Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan C...
-
[2]
Born on June 26, 1973, Rebecca Jo Budig is an American television presenter and actress with a career spanning nearly three decades. Her professional journey began in 1993 and has included notable roles such as Michelle Bauer on Guiding Light and Greenlee Smythe on All My Children. After playing the latter role on-and-off until 2011, she went on to portra...
work page 1973
-
[3]
With a diverse career in television, Rebecca Jo Budig, born June 26, 1973, has established herself as a talented actress and presenter. Her career milestones include her roles as Michelle Bauer in the CBS soap opera Guiding Light, and Greenlee Smythe in All My Children. Her portrayal of Greenlee spanned several years, concluding with the show’s finale in ...
work page 1973
-
[4]
Since her career began in 1993, she has landed prominent roles in several television series
Rebecca Jo Budig is a versatile American actress and television host, born on June 26, 1973. Since her career began in 1993, she has landed prominent roles in several television series. One of her earliest notable roles was Michelle Bauer in Guiding Light, followed by her portrayal of Greenlee Smythe in All My Children, a character she played until the se...
work page 1973
-
[5]
In the years that followed, she appeared in General Hospital and L.A.’s Finest
-
[6]
She began her career two decades later, securing the role of Michelle Bauer on Guiding Light
Rebecca Jo Budig, an American actress and television presenter, was born on June 26, 1973. She began her career two decades later, securing the role of Michelle Bauer on Guiding Light. Budig’s subsequent roles have included Greenlee Smythe on All My Children, a part she played intermittently until the series ended in 2011. Her later appearances include a ...
work page 1973
-
[7]
American actress Rebecca Jo Budig was born on June 26, 1973. Her television career, which began in 1993, encompasses multiple notable roles, such as Michelle Bauer on the soap opera Guiding Light and Greenlee Smythe on All My Children. She portrayed the latter character until the series finale in 2011. Budig later appeared as Hayden Barnes in General Hosp...
work page 1973
-
[8]
Since launching her career in 1993, Rebecca Jo Budig has established herself as a talented actress and television presenter in the United States. Born on June 26, 1973, she has appeared in a range of notable roles, including Michelle Bauer on Guiding Light and Greenlee Smythe on All My Children. The latter role spanned several years, concluding with the s...
work page 1993
-
[9]
Her breakout role came in 1995 when she was cast as Michelle Bauer on Guiding Light
Rebecca Jo Budig, born on June 26, 1973, has enjoyed a successful career in American television as an actress and presenter. Her breakout role came in 1995 when she was cast as Michelle Bauer on Guiding Light. Later, she played the character Greenlee Smythe on All My Children, a part she held intermittently until the show’s finale in 2011. Her more recent...
work page 1973
-
[10]
Since her career began in 1993, she has appeared in various television series
Born on June 26, 1973, Rebecca Jo Budig is a talented American actress and television presenter. Since her career began in 1993, she has appeared in various television series. Notable roles include her portrayal of Michelle Bauer on the soap opera Guiding Light, as well as Greenlee Smythe on All My Children. Budig continued to expand her acting repertoire...
work page 1973
-
[11]
Born on June 26, 1973, she began her professional journey in
As an American actress and television host, Rebecca Jo Budig has had a diverse career spanning nearly three decades. Born on June 26, 1973, she began her professional journey in
work page 1973
-
[12]
Her notable roles include Michelle Bauer on Guiding Light and Greenlee Smythe on All My Children, a character she played until the series finale in 2011. Her subsequent appearances include General Hospital and the series L.A.’s Finest, where she portrayed Carlene Hart
work page 2011
-
[13]
With a career in television that began in 1993, Rebecca Jo Budig, born June 26, 1973, has established herself as a versatile actress and presenter. Her early roles include Michelle Bauer on Guiding Light, while her breakout role came as Greenlee Smythe on All My Children. She continued to portray Greenlee intermittently until the show’s finale in 2011. He...
work page 1993
-
[14]
Let (x1,y1)=({x1},{y1}) and (x2,y2)=({x2},{y2})
-
[15]
Compute the difference: x2-x1={x2}-{x1}={x2-x1} y2-y1={y2}-{y1}={y2-y1}
-
[16]
Plug into the formula: k={x2-x1}/{y2-y1} ### Final Answer: k={k} 30 A:
-
[17]
Identify the coordinates: First point: (x1,y1)=({x1},{y1}) Second point: (x2,y2)=({x2},{y2})
-
[18]
Compute the difference in y-values: {y2}-{y1}={y2-y1}
-
[19]
Compute the difference in x-values: {x2}-{x1}={x2-x1}
-
[20]
Divide the differences: k={y2-y1}/{x2-x1} ### Final Answer: k={k} A: We use the slope formula: k=(y2-y1)/(x2-x1)
-
[21]
Plug in the coordinates: k=({y2}-{y1})/({x2}-{x1})
-
[22]
Simplify the numerator and denominator: k={y2-y1}/{x2-x1}
-
[23]
Simplify the fraction: k={k} ### Final Answer: k={k} A: To find the slope, we use the slope formula: k=(y2-y1)/(x2-x1)
-
[24]
We are given two points:({x1},{y1}),({x2},{y2})
-
[25]
Plug the values into the formula: k=({y2}-{y1})/({x2}-{x1})={y2-y1}/{x2-x1} ### Final Answer: k={k} A: The slope k between (x1,x2) and (y1,y2) is given by: k=(y2-y1)/(x2-x1)
-
[26]
From the problem: (x1,y1)=({x1},{y1}),(x2,y2)=({x2},{y2})
-
[27]
Substituting into the formula: k=({y2}-{y1})/({x2}-{x1})={y2-y1}/{x2-x1}
-
[28]
Simplify: k={y2-y1}/{x2-x1} ### Final Answer: k={k} 31 E.4 Constructing the Max-over-N Dataset We design a new task named “Max-over-N”, where the model is tasked with outputting the maximum number of a list of N integers, each randomly sampled from {0,1,· · ·,99} . In our experiments, we setN= 30. Table 13: An example of the Max-over-N subtask. Q: Find th...
work page 2023
-
[29]
Analyze their meanings and typical usage
-
[30]
Decide whether they are synonyms (Yes/No)
-
[31]
Provide a brief explanation for your decision. Here are some examples to guide you: Words: "happy" and "joyful" Yes Explanation: Both words describe a state of being ,→pleased or content and are often interchangeable in ,→most contexts. Words: "run" and "jog" No Explanation: While both refer to forms of movement, "run" ,→typically implies a faster pace th...
work page 2024
-
[32]
For allθ, the input distributionD θ(x)is the same
-
[33]
For allθ, the target distributionD θ(y|x)is the same for allx /∈ SK i=1 Xi
-
[34]
, yK) =QK k=1 Yk(yk), whereY k is a fixed prior distribution overy k
The prior distribution P over θ is given by the product distribution P(y 1, y2, . . . , yK) =QK k=1 Yk(yk), whereY k is a fixed prior distribution overy k. The exposure frequency of each random fact is defined as the total probability that an input x∈X i occurs inD θ. Theorem F.3(Theorem 4.2, restated).For a factual data universe U= (P,D θ) with K random ...
-
[35]
The prior distributionPoverθis a joint distribution ofP 1 andP 2. In reality, mixing two datasets can be seen as mixing two data universes first and then sampling a data distribution from the mixed data universe. Here we consider the simplified case where the two data universes are so different from each other that they convey orthogonal information. Defi...
-
[36]
For any x that is in both supports of D(1) θ1 and D(2) θ2 , we have D(1) θ1 (y|x) =D (2) θ2 (y|x) for all θ1 and θ2. In other words, the conditional distribution of the next token y given the context x remains consistent across both domains and is unaffected by variations in values ofθ 1 andθ 2. 2.P(θ 1, θ2) =P 1(θ1)· P 2(θ2), i.e.,θ 1 andθ 2 are independ...
-
[37]
if r 1−r ·p <−D −FP2(M), then ¯L1(A) =F P1(0)
-
[38]
if r 1−r ·p >−D +FP2(M−H tot), then ¯L1(A) =F P1(∞). Proof. By Theorem F.3, D+FP1(0) = D−FP1(Htot) =p . Plugging this into Theorem F.6 and Theo- rem F.7 withβ=H tot finishes the proof. Now we are ready to prove the main theorem we stated in Section 4.4. Recall that M − 0 (t) := sup{M≥0 :−F ′ P2(M)> t}, M + 0 (t) := inf{M≥0 :−F ′ P2(M)< t}, Theorem F.9(The...
-
[39]
ifM≤M − 0 ( r 1−r ·p), then ¯L1(A) =F P1(0)
-
[40]
ifM≥M + 0 ( r 1−r ·p) +H tot, then ¯L1(A) =F P1(∞). Proof. This is a direct consequence of Theorem F.8 by noting that (1)−D−FP2(M) is left continuous and non-increasing in M; (2) −D+FP2(M) is right continuous and non-increasing inM; (3) FP2(M) is almost everywhere differentiable. 39
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.