Can Large Language Models Infer Causal Relationships from Real-World Text?
Pith reviewed 2026-05-19 14:07 UTC · model grok-4.3
The pith
Large language models struggle to infer causal relationships from real-world academic texts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We show that LLMs face significant challenges in inferring causal relationships from real-world text. We develop a benchmark drawn from real-world academic literature, which includes diverse texts with respect to length, complexity (different levels of explicitness, number of causal events and relationships), and domain. To the best of our knowledge, our benchmark is the first-ever real-world dataset for this task. Our experiments on this dataset show that LLMs face significant challenges in inferring causal relationships from real-world text, with the best-performing model achieving an average F1 score of only 0.535.
What carries the argument
ReCITE benchmark of annotated real-world academic texts for evaluating causal inference in LLMs
If this is right
- Current LLMs are not yet reliable for extracting causal structures from complex documents.
- Performance is affected by text length, number of relations, and level of explicitness.
- The new dataset enables more accurate assessment of progress in causal reasoning capabilities.
- Insights from the analysis can guide development of better causal reasoning methods in LLMs.
Where Pith is reading between the lines
- Improved performance on real texts could enable LLMs to assist in scientific literature review and hypothesis generation.
- The reliance on synthetic data in prior work may have overstated LLM causal abilities.
- Future work might explore hybrid systems combining LLMs with structured causal models to boost accuracy.
Load-bearing premise
The selected academic texts and human annotations represent a faithful sample of real-world causal inference tasks.
What would settle it
A model achieving significantly higher than 0.535 average F1 on the benchmark or inconsistent annotations upon re-evaluation would challenge the findings of significant challenges.
Figures









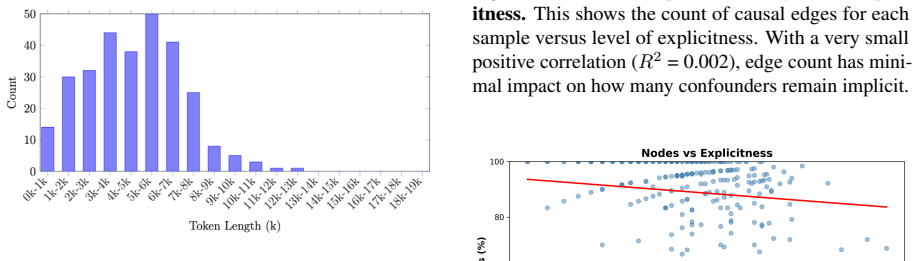

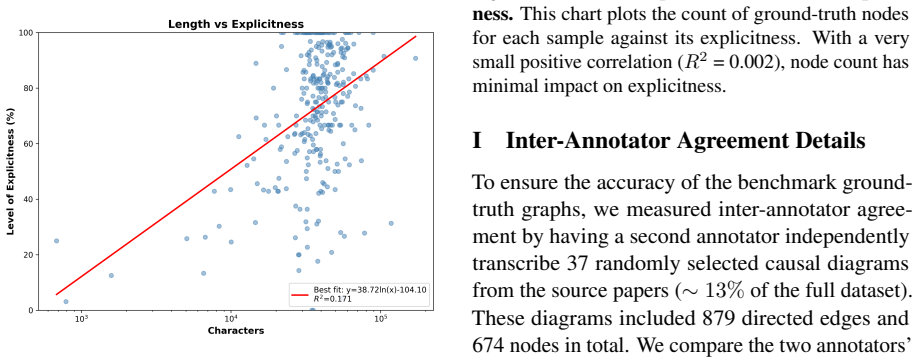





read the original abstract
Understanding and inferring causal relationships from texts is a core aspect of human cognition and is essential for advancing large language models (LLMs) towards artificial general intelligence. Existing work evaluating LLM causal reasoning primarily relies on synthetic or simplified texts with explicitly stated causal relationships. These texts typically feature short passages and few causal relations, failing to reflect the complexities of real-world reasoning. In this paper, we investigate whether LLMs are capable of inferring causal relationships from real-world texts. We develop a benchmark drawn from real-world academic literature, which includes diverse texts with respect to length, complexity (different levels of explicitness, number of causal events and relationships), and domain. To the best of our knowledge, our benchmark is the first-ever real-world dataset for this task. Our experiments on this dataset show that LLMs face significant challenges in inferring causal relationships from real-world text, with the best-performing model achieving an average F$_1$ score of only 0.535. Through systematic analysis across aspects of real-world text (explicitness, number of causal events and relationships, length of text, domain), our benchmark offers targeted insights for further research into advancing LLM causal reasoning. Our code and dataset can be found at https://github.com/Ryan-Saklad/ReCITE .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper constructs a new benchmark dataset from real-world academic literature to evaluate LLMs on inferring causal relationships in texts that vary in length, explicitness, number of causal events/relations, and domain. Experiments across multiple LLMs report that the best-performing model reaches only an average F1 score of 0.535, with further breakdowns showing performance variation by text properties. The authors release the code and dataset and position the work as the first real-world benchmark for this task.
Significance. If the benchmark construction and evaluation protocol are sound, the result would demonstrate that current LLMs still struggle with causal inference on authentic, complex texts rather than only on synthetic examples. The open release of code and data is a clear strength that supports reproducibility and allows the community to extend or re-analyze the benchmark.
major comments (2)
- [Section 3 (Benchmark Construction)] Section 3 (Benchmark Construction): The paper does not report inter-annotator agreement for the human annotations of causal events and relations. Without IAA metrics, it is impossible to determine whether the ground-truth labels contain substantial ambiguity or noise, which would undermine the interpretation of the 0.535 F1 as evidence of LLM limitations rather than annotation difficulty.
- [Section 4 (Experiments and Analysis)] Section 4 (Experiments and Analysis): No human expert performance baseline is provided on the same extraction task. The central claim that LLMs 'face significant challenges' therefore lacks calibration; an F1 of 0.535 could reflect inherent task difficulty in long academic texts with implicit relations rather than model-specific shortcomings. Adding a human baseline would directly test this.
minor comments (1)
- [Abstract] Abstract: The statement that the benchmark is 'the first-ever real-world dataset' should be accompanied by a brief comparison to any prior causal extraction datasets from scientific text to strengthen the novelty claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper to incorporate the suggested improvements where appropriate.
read point-by-point responses
-
Referee: [Section 3 (Benchmark Construction)] Section 3 (Benchmark Construction): The paper does not report inter-annotator agreement for the human annotations of causal events and relations. Without IAA metrics, it is impossible to determine whether the ground-truth labels contain substantial ambiguity or noise, which would undermine the interpretation of the 0.535 F1 as evidence of LLM limitations rather than annotation difficulty.
Authors: We agree that reporting inter-annotator agreement is important for validating annotation quality. The manuscript describes the annotation protocol and guidelines in Section 3 but does not include quantitative IAA statistics. In the revision we will add Cohen's kappa and percentage agreement figures computed on the annotations, which demonstrate substantial agreement. This will strengthen the claim that the 0.535 F1 reflects LLM limitations rather than label noise. revision: yes
-
Referee: [Section 4 (Experiments and Analysis)] Section 4 (Experiments and Analysis): No human expert performance baseline is provided on the same extraction task. The central claim that LLMs 'face significant challenges' therefore lacks calibration; an F1 of 0.535 could reflect inherent task difficulty in long academic texts with implicit relations rather than model-specific shortcomings. Adding a human baseline would directly test this.
Authors: We acknowledge that a human baseline would help calibrate task difficulty. Our experiments focus on LLM performance, but we agree a direct comparison is valuable. In the revised version we will report human expert performance on the causal extraction task for a representative subset of the benchmark, enabling readers to interpret the 0.535 F1 score relative to human-level results on the same real-world texts. revision: yes
Circularity Check
No circularity: empirical benchmark evaluation is self-contained
full rationale
The paper constructs a new dataset from real-world academic texts and reports empirical LLM performance metrics (F1 scores) on causal inference extraction. No derivation chain, equations, or predictions are present that reduce to fitted inputs, self-definitions, or author self-citations by construction. The central claim rests on observed results from the benchmark rather than any load-bearing self-referential step or renamed known result. The benchmark is presented as novel without invoking prior author theorems to force uniqueness or outcomes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human annotations of causal relations in academic text constitute a reliable ground truth.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArrowOfTime.leanarrow_from_z unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We develop a benchmark drawn from real-world academic literature... best-performing model achieving an average F1 score of only 0.535.
-
IndisputableMonolith/Foundation/Atomicity.leanatomic_tick unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the task is to construct a causal graph where nodes represent causal events and directed edges represent their causal relationships
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
METER: Evaluating Multi-Level Contextual Causal Reasoning in Large Language Models
METER benchmark reveals LLMs decline sharply in causal reasoning proficiency from association to intervention to counterfactual levels due to distraction by irrelevant facts and loss of faithfulness to provided context.
-
Large Language Models for Causal Relations Extraction in Social Media: A Validation Framework for Disaster Intelligence
The authors introduce a validation framework showing LLMs can pull causal links from disaster social media but require checks against post-event evidence to avoid relying on model priors.
Reference graph
Works this paper leans on
-
[1]
Hallucination of multimodal large language models: A survey.Preprint, arXiv:2404.18930. T. Bratanic. 2024. Building knowledge graphs with llm graph transformer: A deep dive into langchain’s implementation of graph construction with llms. To- wards Data Science. Sirui Chen, Bo Peng, Meiqi Chen, Ruiqi Wang, Mengy- ing Xu, Xingyu Zeng, Rui Zhao, Shengjie Zha...
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [2]
-
[3]
Constructing inferences during narrative text comprehension.Psychological Review, 101(3):371– 395. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schel- ten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mi- tra, Archie Sravank...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
The node (or the concept behind it) is explicitly mentioned in the text - This can be verbatim, or though use of a synonym - It is sufficient to be mentioned in the text; it is irrelevant if it is mentioned to be in the causal graph or not
-
[5]
The node is mentioned indirectly or implicitly in the text
-
[6]
The node is unmentioned in the text, even if related concepts are discussed Be conservative when determining the degree of explicitness for each node. Output only the JSON code block with your answer, without commentary, reasoning, explanation, or any other text. You must include the name of each node in the graph verbatim, even when the graph is very lar...
work page 2025
-
[7]
The exact wording of the original paper must be preserved verbatim
Modify the text only when absolutely necessary. The exact wording of the original paper must be preserved verbatim. - Do not correct spelling or grammar, even if it is incorrect - The response will be rejected if even a single word is edited or removed un- necessarily; most of the response should effectively be copy-pasted from the original text - Your re...
-
[8]
- Convert sections and sub-sections into headings and subheadings
Correct any broken text from the PDF processing and convert it into a well-structured md file. - Convert sections and sub-sections into headings and subheadings
-
[9]
Remove the following information in entirety: - Images, figures, and any other visual elements - References and Citations, including when in-line. E.g., "[20, 22]" would be removed. - Acknowledgments - Authorship information - Appendices - Page numbers Remember; your only output is the processed text in full, with no thinking, reasoning, or other commenta...
-
[10]
start_string: The beginning of the text to replace
-
[11]
end_string: The end of the text to replace
-
[12]
replacement: The text to insert instead You can call normalize multiple times to make several targeted replacements in the document. All three parameters are required for each call. - By default, normalize will locate the *first* occurrence of the start_string. As a workaround for when the same text ap- pears verbatim multiple times, use a slightly longer...
-
[13]
Follow each direction carefully, com- pletely, and in-order a. It is very important to be thorough and not take shortcuts, even when it seems tedious, redundant, or unnecessary. Do this for each node or edge you are evaluating; there is no time limit. Be sure to fully to fully think through each node or edge you are tasked with evaluating fully before mov...
-
[14]
Ground-Truth Graph Evaluation - Explicitly identify and quote ALL potentially corresponding nodes from ground-truth graph - Apply these labels where applicable: Presence Labels (select one): - PRESENCE_STRONG_MATCH: Core concept matches a ground-truth node with only minor, inconsequential differences - PRESENCE_WEAK_MATCH: Core concept shares meaning with...
-
[15]
Ground-Truth Text Evaluation - Explicitly quote ALL relevant supporting text from source - Apply these labels where applicable: Evidence Labels (select one): - PRESENCE_STRONG_MATCH: Core concept appears in text with only minor, inconsequential differences - PRESENCE_WEAK_MATCH: Core concept shares significant meaning with text but has notable differences...
-
[16]
Ground-Truth Graph Evaluation - Explicitly identify and quote ALL potentially corresponding edges from ground-truth graph - Apply these labels where applicable: Presence Labels (select one): - PRESENCE_STRONG_MATCH: Edge connects highly similar concepts as in ground-truth - PRESENCE_WEAK_MATCH: Edge connects somewhat similar concepts as in ground-truth - ...
-
[17]
Ground-Truth Text Evaluation - Explicitly quote ALL relevant supporting text that describes causal relationships - Apply these labels where applicable: Evidence Labels (select one): - PRESENCE_GRAPH_ONLY: Causal relationship present in ground-truth graph (always select this if present) - PRESENCE_EXPLICIT: Causal relation- ship directly stated in text (on...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.