Data Compressibility Quantifies LLM Memorization
Pith reviewed 2026-05-19 05:57 UTC · model grok-4.3
The pith
Set-level data entropy linearly correlates with memorization scores in large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a set-level data entropy estimator exhibits a linear correlation with memorization scores; the authors call this relationship the Entropy-Memorization (EM) Linearity. The shift from instance-level to set-level metrics is what makes the correlation visible and robust where earlier approaches did not succeed.
What carries the argument
The set-level data entropy estimator, which assesses compressibility across groups of training examples rather than single instances and thereby serves as a proxy linking data properties to memorization levels.
If this is right
- Memorization levels become estimable from data properties without needing to train or query the full model.
- Training data can be curated or filtered using entropy calculations to influence the amount of memorization that occurs.
- The linear relation supplies a quantitative yardstick for studying how different data characteristics affect model retention.
- Data-driven interventions become feasible for reducing unintended verbatim reproduction in deployed models.
Where Pith is reading between the lines
- The linearity may generalize to other model behaviors such as factual recall or style copying if the same set-level approach is used.
- Privacy audits of training corpora could incorporate entropy checks to flag high-memorization subsets ahead of time.
- Repeating the analysis on models of varying scale or training regimes would test how stable the EM Linearity remains.
- Alternative compression algorithms could be substituted to check whether the linear pattern is method-independent.
Load-bearing premise
The particular set-level entropy estimator chosen truly reflects the data properties that drive memorization instead of depending on the specific compression or sampling choices.
What would settle it
Finding no linear correlation when the same set-level estimator is applied to a fresh collection of training data or when an alternative compression procedure is substituted would disprove the claimed linearity.
Figures




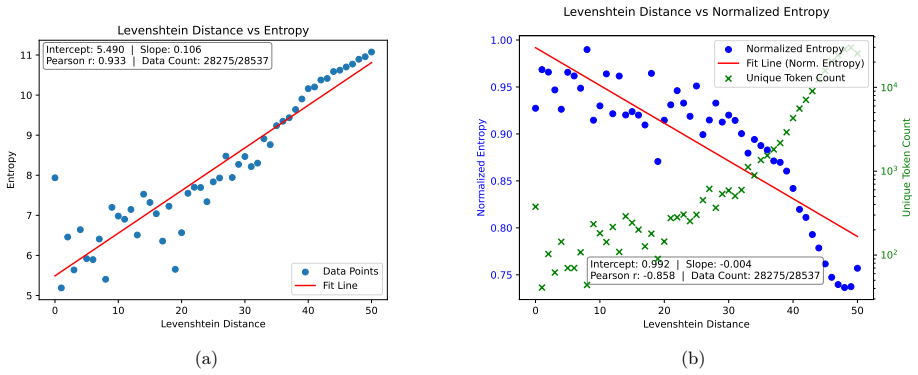



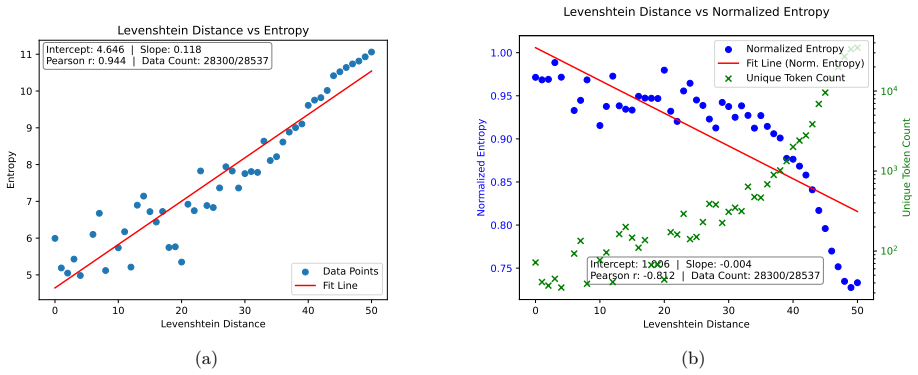





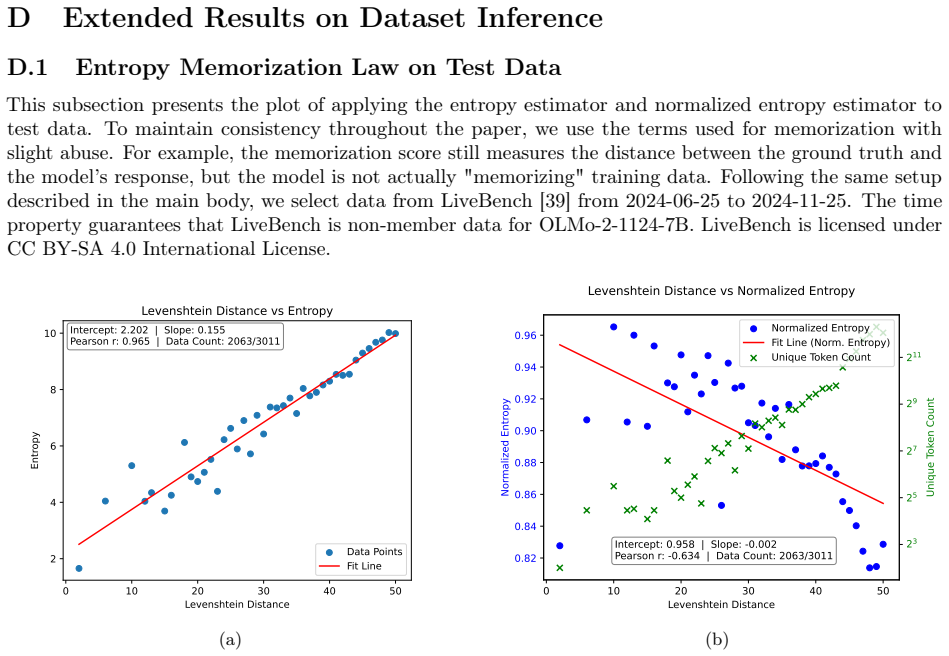
read the original abstract
Large Language Models (LLMs) are known to memorize portions of their training data, sometimes even reproduce content verbatim when prompted appropriately. Despite substantial interest, existing LLM memorization research has offered limited insight into how training data influences memorization and largely lacks quantitative characterization. In this work, we build upon the line of research that seeks to quantify memorization through data compressibility. We analyze why prior attempts fail to yield a reliable quantitative measure and show that a surprisingly simple shift from instance-level to set-level metrics uncovers a robust phenomenon, which we term the \textit{Entropy--Memorization (EM) Linearity}. This law states that a set-level data entropy estimator exhibits a linear correlation with memorization scores.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that prior instance-level attempts to quantify LLM memorization via data compressibility fail to yield reliable measures, but a shift to set-level metrics reveals a robust linear correlation (termed the Entropy-Memorization or EM Linearity) between a compression-based set-level data entropy estimator and memorization scores.
Significance. If the EM Linearity holds under reasonable variations in estimator and data construction, it would provide a concrete quantitative bridge between training-data properties and memorization behavior, moving the field beyond qualitative observations. The set-level framing itself is a clear methodological contribution that directly addresses documented shortcomings of instance-level compressibility metrics.
major comments (2)
- [§4 and §3.2] §4 (Experiments) and §3.2 (Set-level estimator definition): the central claim that the observed linearity is intrinsic rather than an artifact of the chosen compressor and set-construction procedure is load-bearing, yet the manuscript provides no systematic ablation across alternative compressors (e.g., gzip vs. zstandard vs. neural compressors) or controlled variations in set size and sampling method. Without these controls the linearity could be tied to the specific entropy estimator rather than to the underlying data properties that drive memorization.
- [§3.3 and §5] §3.3 (Memorization scoring) and §5 (Discussion): the paper must demonstrate that the entropy estimator was computed independently of the memorization scores and that the linearity survives reasonable changes in the entropy estimator (e.g., different block sizes or sampling densities). The current presentation leaves open the possibility that the reported correlation is partly circular or sensitive to hyper-parameters chosen on the same data.
minor comments (2)
- [Figures 2-3] Figure 2 and Figure 3: axis labels and error-bar definitions are not fully specified in the captions; readers cannot immediately reproduce the plotted quantities from the text alone.
- [§3.2] Notation: the symbol H_set is introduced without an explicit equation linking it to the underlying compression length; a short derivation or pseudocode block would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback. We address the major comments point by point below, providing clarifications and committing to revisions that strengthen the robustness claims for the Entropy-Memorization Linearity without overstating the original manuscript's scope.
read point-by-point responses
-
Referee: [§4 and §3.2] §4 (Experiments) and §3.2 (Set-level estimator definition): the central claim that the observed linearity is intrinsic rather than an artifact of the chosen compressor and set-construction procedure is load-bearing, yet the manuscript provides no systematic ablation across alternative compressors (e.g., gzip vs. zstandard vs. neural compressors) or controlled variations in set size and sampling method. Without these controls the linearity could be tied to the specific entropy estimator rather than to the underlying data properties that drive memorization.
Authors: We agree that additional controls are needed to establish that the EM Linearity reflects intrinsic data properties. The original manuscript used gzip as the compressor because it is a standard, reproducible choice in prior compressibility literature and balances computational cost with effectiveness for text data. To address the concern directly, the revised version includes new ablations: comparisons with zstandard and a lightweight neural compressor, plus controlled variations in set size (50–1000 instances) and sampling strategies (random vs. stratified by length). The linear relationship persists with comparable correlation coefficients across these settings. These results are added to §4 with a new supplementary figure. revision: yes
-
Referee: [§3.3 and §5] §3.3 (Memorization scoring) and §5 (Discussion): the paper must demonstrate that the entropy estimator was computed independently of the memorization scores and that the linearity survives reasonable changes in the entropy estimator (e.g., different block sizes or sampling densities). The current presentation leaves open the possibility that the reported correlation is partly circular or sensitive to hyper-parameters chosen on the same data.
Authors: The set-level entropy estimator is applied solely to the raw training data partitions using compression algorithms; it has no access to model weights, outputs, or memorization labels. Memorization scores are obtained independently by prompting the trained LLM on held-out sequences. To further rule out sensitivity, we have added analyses varying compressor block size (1 KB to 16 KB) and set-sampling density. The linearity remains stable under these perturbations. The revised §5 now explicitly states the separation of computations and includes the sensitivity results in the appendix. revision: yes
Circularity Check
No significant circularity; EM Linearity is an observed empirical correlation, not a derived equality.
full rationale
The paper presents the Entropy-Memorization (EM) Linearity as a robust linear correlation uncovered by shifting from instance-level to set-level metrics on data compressibility and memorization scores. This is explicitly described as an observed phenomenon after analyzing prior failures, with no mathematical derivation chain, no equations reducing predictions to inputs by construction, no load-bearing self-citations for uniqueness theorems, and no fitted parameters or ansatzes renamed as results. The central claim rests on empirical findings from the chosen estimator rather than tautological definitions or self-referential reductions, rendering the analysis self-contained.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
level-set-based entropy estimator ... M(se) ≜ −∑x∈Te p̂e(x) log p̂e(x) ... linear correlation with memorization scores
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Entropy–Memorization Law ... higher entropy correlates with higher memorization scores
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
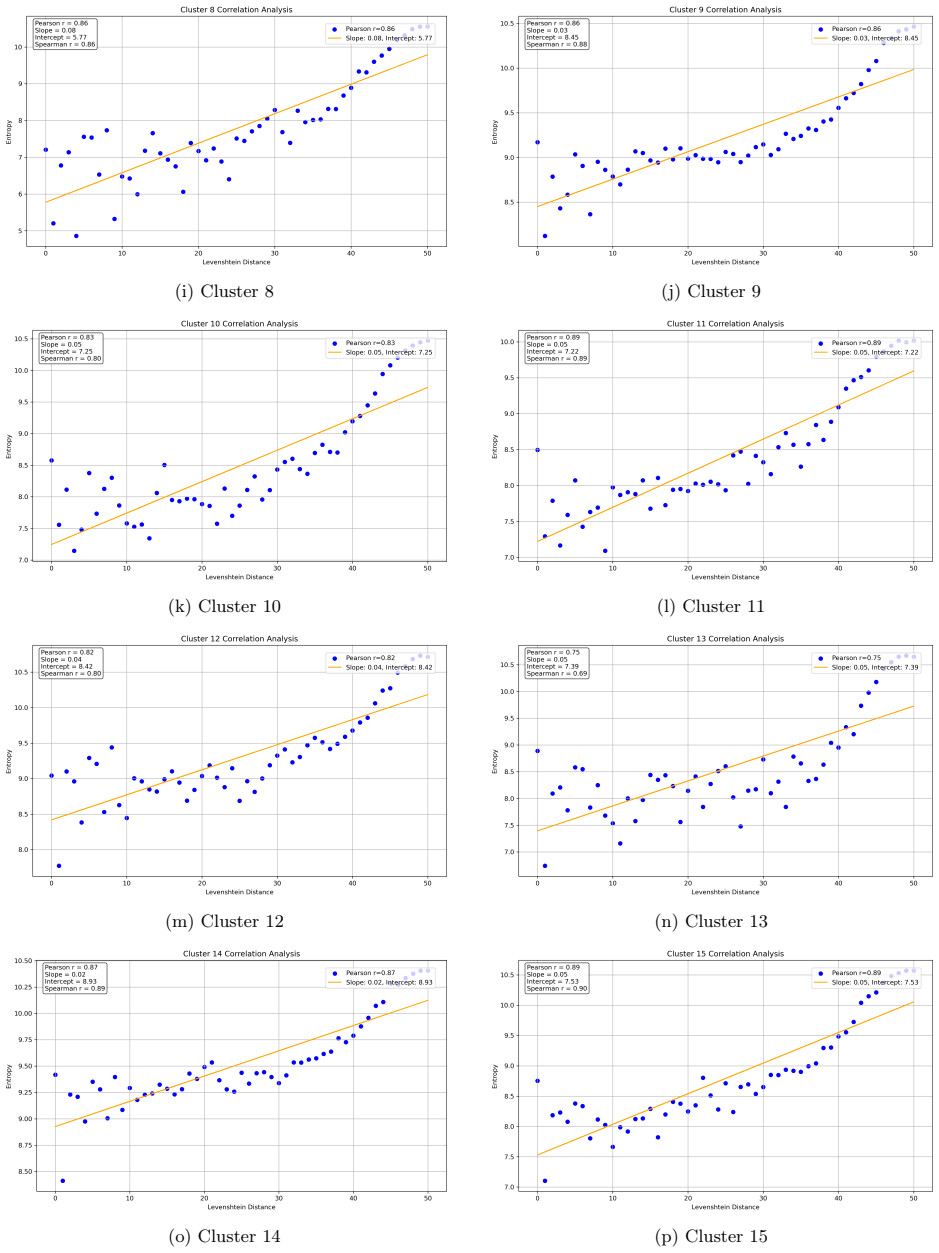
Reference graph
Works this paper leans on
-
[1]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
-
[2]
Language models are unsupervised multitask learners
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. 2019. 8
work page 2019
-
[3]
Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov. RoBERTa: A robustly optimized BERT pretraining approach.arXiv e-prints, 2019
work page 2019
-
[4]
N. Carlini, C. Liu, Ú. Erlingsson, J. Kos, and D. Song. The secret sharer: Evaluating and testing unintended memorization in neural networks. InUSENIX Security, 2019
work page 2019
-
[5]
N. Carlini, F. Tramèr, E. Wallace, M. Jagielski, A. Herbert-Voss, K. Lee, A. Roberts, T. B. Brown, D. Song, Ú. Erlingsson, A. Oprea, and C. Raffel. Extracting training data from large language models. In USENIX Security Symposium, pages 2633–2650, 2020
work page 2020
-
[6]
More than 15,000 authors sign authors guild letter calling on ai industry leaders to protect writers
USAuthorsGuild. More than 15,000 authors sign authors guild letter calling on ai industry leaders to protect writers. authors-guild-open-letter, 2023
work page 2023
-
[7]
LLMLitigation. Kadrey, silverman, golden v meta platforms, inc.https://llmlitigation.com/pdf/ 03417/kadrey-meta-complaint.pdf, 2023
work page 2023
-
[8]
The times sues OpenAI and microsoft over A.I
Michael. The times sues OpenAI and microsoft over A.I. use of copyrighted work.The New York Times, December 2023
work page 2023
-
[9]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[10]
Xinyi Wang, Antonis Antoniades, Yanai Elazar, Alfonso Amayuelas, Alon Albalak, Kexun Zhang, and William Yang Wang. Generalization v.s. memorization: Tracing language models’ capabilities back to pretraining data. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[11]
Preventing generation of verbatim memorization in language models gives a false sense of privacy
Daphne Ippolito, Florian Tramer, Milad Nasr, Chiyuan Zhang, Matthew Jagielski, Katherine Lee, Christopher Choquette Choo, and Nicholas Carlini. Preventing generation of verbatim memorization in language models gives a false sense of privacy. In C. Maria Keet, Hung-Yi Lee, and Sina Zarrieß, editors, Proceedings of the 16th International Natural Language Ge...
work page 2023
-
[12]
Vitaly Feldman and Chiyuan Zhang. What neural networks memorize and why: Discovering the long tail via influence estimation.Advances in Neural Information Processing Systems, 33:2881–2891, 2020
work page 2020
-
[13]
Rethinking LLM memorization through the lens of adversarial compression
Avi Schwarzschild, Zhili Feng, Pratyush Maini, Zachary Chase Lipton, and J Zico Kolter. Rethinking LLM memorization through the lens of adversarial compression. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[14]
SFT memorizes, RL generalizes: A comparative study of foundation model post-training
Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Sergey Levine, and Yi Ma. SFT memorizes, RL generalizes: A comparative study of foundation model post-training. InThe Second Conference on Parsimony and Learning (Recent Spotlight Track), 2025
work page 2025
-
[15]
Deduplicating training data mitigates privacy risks in language models
Nikhil Kandpal, Eric Wallace, and Colin Raffel. Deduplicating training data mitigates privacy risks in language models. InInternational Conference on Machine Learning, pages 10697–10707. PMLR, 2022
work page 2022
-
[16]
Pythia: a suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, Aviya Skowron, Lintang Sutawika, and Oskar Van Der Wal. Pythia: a suite for analyzing large language models across training and scaling. InProceedings of the 40th International Conferen...
work page 2023
-
[17]
OLMo: Accelerating the Science of Language Models
Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, et al. Olmo: Accelerating the science of language models. arXiv preprint arXiv:2402.00838, 2024. 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
J. Li, A. Fang, G. Smyrnis, M. Ivgi, M. Jordan, S. Y. Gadre, and et al. Datacomp-lm: In search of the next generation of training sets for language models. InAdvances in Neural Information Processing Systems, volume 37, pages 14200–14282, 2024
work page 2024
-
[19]
Yanai Elazar, Akshita Bhagia, Ian Helgi Magnusson, Abhilasha Ravichander, Dustin Schwenk, Alane Suhr, Evan Pete Walsh, Dirk Groeneveld, Luca Soldaini, Sameer Singh, Hannaneh Hajishirzi, Noah A. Smith, and Jesse Dodge. What’s in my big data? InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[20]
arXiv preprint arXiv:2402.00159 , year=
L. Soldaini, R. Kinney, A. Bhagia, D. Schwenk, D. Atkinson, R. Authur, and et al. Dolma: An open corpus of three trillion tokens for language model pretraining research.arXiv preprint arXiv:2402.00159, 2024
-
[21]
T. OLMo, P. Walsh, L. Soldaini, D. Groeneveld, K. Lo, S. Arora, and H. Hajishirzi. 2 olmo 2 furious. arXiv preprint arXiv:2501.00656, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Feder Cooper, Daphne Ippolito, Christopher A.Choquette-Choo, Florian Tramèr, and KatherineLee
Milad Nasr, Javier Rando, Nicholas Carlini, Jonathan Hayase, Matthew Jagielski, A. Feder Cooper, Daphne Ippolito, Christopher A.Choquette-Choo, Florian Tramèr, and KatherineLee. Scalable extraction of training data from aligned, production language models. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[23]
Quantifying memorization across neural language models
Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramer, and Chiyuan Zhang. Quantifying memorization across neural language models. In The Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[24]
Ali Al-Kaswan, Maliheh Izadi, and Arie Van Deursen. Targeted attack on gpt-neo for the satml language model data extraction challenge.arXiv preprint arXiv:2302.07735, 2023
-
[25]
Yihong Dong, Xue Jiang, Huanyu Liu, Zhi Jin, Bin Gu, Mengfei Yang, and Ge Li. Generalization or memorization: Data contamination and trustworthy evaluation for large language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Findings of the Association for Computational Linguistics: ACL 2024. Association for Computational Linguistics, August 2024
work page 2024
-
[26]
Binary codes capable of correcting deletions, insertions, and reversals
Vladimir I Levenshtein et al. Binary codes capable of correcting deletions, insertions, and reversals. In Soviet physics doklady, volume 10, pages 707–710. Soviet Union, 1966
work page 1966
-
[27]
Kushal Tirumala, Aram Markosyan, Luke Zettlemoyer, and Armen Aghajanyan. Memorization without overfitting: Analyzing the training dynamics of large language models.Advances in Neural Information Processing Systems, 35:38274–38290, 2022
work page 2022
-
[28]
Sentence-bert: Sentence embeddings using siamese bert-networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982–3992, 2019
work page 2019
-
[29]
Tong Chen, Akari Asai, Niloofar Mireshghallah, Sewon Min, James Grimmelmann, Yejin Choi, Hannaneh Hajishirzi, Luke Zettlemoyer, and Pang Wei Koh. Copybench: Measuring literal and non-literal reproduction of copyright-protected text in language model generation. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages...
work page 2024
-
[30]
On the bias of information estimates.Psychological Bulletin, 71(2):108, 1969
AG Carlton. On the bias of information estimates.Psychological Bulletin, 71(2):108, 1969
work page 1969
-
[31]
Francis Galton. Regression towards mediocrity in hereditary stature.The Journal of the Anthropological Institute of Great Britain and Ireland, 15:246–263, 1886
-
[32]
A new algorithm for data compression.C Users J., 12(2):23–38, February 1994
Philip Gage. A new algorithm for data compression.C Users J., 12(2):23–38, February 1994. 10
work page 1994
-
[33]
Yandex cloud documentation: Yandex identity and access management: Oauth token, July 2023
Yandex. Yandex cloud documentation: Yandex identity and access management: Oauth token, July 2023
work page 2023
-
[34]
Behind github’s new authentication token formats, Apr 2021
Heather Harvey. Behind github’s new authentication token formats, Apr 2021
work page 2021
-
[35]
CodexLeaks: Privacy leaks from code generation language models in GitHub copilot
Liang Niu, Shujaat Mirza, Zayd Maradni, and Christina Pöpper. CodexLeaks: Privacy leaks from code generation language models in GitHub copilot. In32nd USENIX Security Symposium (USENIX Security 23), pages 2133–2150, Anaheim, CA, August 2023. USENIX Association
work page 2023
-
[36]
Yizhan Huang, Yichen Li, Weibin Wu, Jianping Zhang, and Michael R Lyu. Your code secret belongs to me: neural code completion tools can memorize hard-coded credentials.Proceedings of the ACM on Software Engineering, 1(FSE):2515–2537, 2024
work page 2024
-
[37]
Pratyush Maini, Hengrui Jia, Nicolas Papernot, and Adam Dziedzic. LLM dataset inference: Did you train on my dataset? InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[38]
Dataset inference: Ownership resolution in machine learning
Pratyush Maini, Mohammad Yaghini, and Nicolas Papernot. Dataset inference: Ownership resolution in machine learning. InInternational Conference on Learning Representations, 2021
work page 2021
-
[39]
Livebench: A challenging, contamination-limited LLM benchmark
Colin White, Samuel Dooley, Manley Roberts, Arka Pal, Benjamin Feuer, Siddhartha Jain, Ravid Shwartz-Ziv, Neel Jain, Khalid Saifullah, Sreemanti Dey, Shubh-Agrawal, Sandeep Singh Sandha, Siddartha Venkat Naidu, Chinmay Hegde, Yann LeCun, Tom Goldstein, Willie Neiswanger, and Micah Goldblum. Livebench: A challenging, contamination-limited LLM benchmark. In...
work page 2025
-
[40]
M. Duan, A. Suri, N. Mireshghallah, S. Min, W. Shi, L. Zettlemoyer, and H. Hajishirzi. Do membership inference attacks work on large language models?, 2024. arXiv preprint
work page 2024
-
[41]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[42]
Understanding deep learning requires rethinking generalization
Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. Understanding deep learning requires rethinking generalization. InInternational Conference on Learning Representations, 2017
work page 2017
-
[43]
Does learning require memorization? a short tale about a long tail
Vitaly Feldman. Does learning require memorization? a short tale about a long tail. InProceedings of the 52nd Annual ACM SIGACT Symposium on Theory of Computing, STOC 2020, page 954–959, New York, NY, USA, 2020. Association for Computing Machinery
work page 2020
-
[44]
Stella Biderman, Usvsn Prashanth, Lintang Sutawika, Hailey Schoelkopf, Quentin Anthony, Shivanshu Purohit, and Edward Raff. Emergent and predictable memorization in large language models.Advances in Neural Information Processing Systems, 36:28072–28090, 2023
work page 2023
-
[45]
Siwon Kim, Sangdoo Yun, Hwaran Lee, Martin Gubri, Sungroh Yoon, and Seong Joon Oh. Propile: Probing privacy leakage in large language models.Advances in Neural Information Processing Systems, 36:20750–20762, 2023
work page 2023
- [46]
-
[47]
Measuring non-adversarial reproduction of training data in large language models
Michael Aerni, Javier Rando, Edoardo Debenedetti, Nicholas Carlini, Daphne Ippolito, and Florian Tramèr. Measuring non-adversarial reproduction of training data in large language models. InThe Thirteenth International Conference on Learning Representations, 2025. 11
work page 2025
-
[48]
Counterfactual memorization in neural language models
Chiyuan Zhang, Daphne Ippolito, Katherine Lee, Matthew Jagielski, Florian Tramer, and Nicholas Carlini. Counterfactual memorization in neural language models. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 39321–39362. Curran Associates, Inc., 2023
work page 2023
-
[49]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Membership inference attacks against language models via neighbourhood comparison
Justus Mattern, Fatemehsadat Mireshghallah, Zhijing Jin, Bernhard Schoelkopf, Mrinmaya Sachan, and Taylor Berg-Kirkpatrick. Membership inference attacks against language models via neighbourhood comparison. Findings of the Association for Computational Linguistics: ACL 2023, pages 11330–11343, 2023
work page 2023
-
[51]
S. Shachor, N. Razinkov, and A. Goldsteen. Improved membership inference attacks against language classification models, October 2023. arXiv preprint arXiv:2310.07219
-
[52]
Membership inference attacks against NLP classification models, 2021
Virat Shejwalkar, Huseyin A Inan, Amir Houmansadr, and Robert Sim. Membership inference attacks against NLP classification models, 2021
work page 2021
-
[53]
A. Jagannatha, B. P. S. Rawat, and H. Yu. Membership inference attack susceptibility of clinical language models, April 2021. arXiv preprint arXiv:2104.08305
-
[54]
C. Song and V. Shmatikov. Auditing data provenance in text-generation models. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 196–206, July 2019
work page 2019
- [55]
-
[56]
Noisy neighbors: Efficient membership inference attacks against llms
F. Galli, L. Melis, and T. Cucinotta. Noisy neighbors: Efficient membership inference attacks against llms. arXiv preprint arXiv:2406.16565, 2024
-
[57]
Membership inference attacks against fine-tuned large language models via self-prompt calibration
Wenjie Fu, Huandong Wang, Chen Gao, Guanghua Liu, Yong Li, and Tao Jiang. Membership inference attacks against fine-tuned large language models via self-prompt calibration. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 134981–135010. Curran ...
work page 2024
-
[58]
Membership inference attacks from first principles
NicholasCarlini, Steve Chien, Milad Nasr, ShuangSong, AndreasTerzis, andFlorianTramer. Membership inference attacks from first principles. In2022 IEEE symposium on security and privacy (SP), pages 1897–1914. IEEE, 2022
work page 1914
-
[59]
Detecting pretraining data from large language models, 2024
Weijia Shi, Anirudh Ajith, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, and Luke Zettlemoyer. Detecting pretraining data from large language models, 2024
work page 2024
-
[60]
Pretraining data detection for large language models: A divergence-based calibration method
Weichao Zhang, Ruqing Zhang, Jiafeng Guo, Maarten de Rijke, Yixing Fan, and Xueqi Cheng. Pretraining data detection for large language models: A divergence-based calibration method. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 5263–5274, Miami, Florida, USA, November 2024. Association for Computational Li...
work page 2024
-
[61]
Chatterji, Faisal Ladhak, and Tatsunori Hashimoto
Yonatan Oren, Nicole Meister, Niladri S. Chatterji, Faisal Ladhak, and Tatsunori Hashimoto. Proving test set contamination in black-box language models. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[62]
H. Mozaffari and V. J. Marathe. Semantic membership inference attack against large language models. arXiv preprint arXiv:2406.10218, 2024. 12
-
[63]
Scaling up membership inference: When and how attacks succeed on large language models, April 2025
Haritz Puerto, Martin Gubri, Sangdoo Yun, and Seong Joon Oh. Scaling up membership inference: When and how attacks succeed on large language models, April 2025
work page 2025
-
[64]
Multicalibration for confidence scoring in llms
Gianluca Detommaso, Martin Andres Bertran, Riccardo Fogliato, and Aaron Roth. Multicalibration for confidence scoring in llms. InInternational Conference on Machine Learning, pages 10624–10641. PMLR, 2024
work page 2024
-
[65]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
work page 2023
-
[66]
Least squares quantization in pcm.IEEE transactions on information theory, 28(2):129–137, 1982
Stuart Lloyd. Least squares quantization in pcm.IEEE transactions on information theory, 28(2):129–137, 1982
work page 1982
- [67]
-
[68]
Jingwei Zhang, Mohammad Jalali, Cheuk Ting Li, and Farzan Farnia. Identification of novel modes in generative models via fourier-based differential clustering.arXiv preprint arXiv:2405.02700, 2024
-
[69]
Ricardo Campos, Vítor Mangaravite, Arian Pasquali, Alípio Jorge, Célia Nunes, and Adam Jatowt. Yake! keyword extraction from single documents using multiple local features.Information Sciences, 509:257–289, 2020. A Compute All experiments were conducted on a GPU cluster equipped with 4 NVIDIA RTX 3090 GPUs (24GB CUDA memory per card), running Ubuntu 22.04...
work page 2020
-
[70]
Extracting semantic embedding. We first encode each answer sequence into embeddings employed using Sentence Transformers in Huggingfaces. 18 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Levenshtein Distance 0.70 0.75 0.80 0.85 0.90 0.95 1.00Normalized Entropy Normalized Levenshtein Distance vs Normalized Entropy levenshtein_distance_gen10 levenshtein_distance_gen10...
-
[71]
With semantic embeddings, we apply K-Means [66] to partition the data intok = 16 semantic clusters
Clustering. With semantic embeddings, we apply K-Means [66] to partition the data intok = 16 semantic clusters
-
[72]
We develop a pipeline that largely automates identifying the semantics of each cluster
Identifying semantics of the cluster. We develop a pipeline that largely automates identifying the semantics of each cluster. The details will be shown in Appendix C.3.3
-
[73]
For each cluster, a linear regression is applied
Run Algorithm 2 on 16 partitions of the dataset. For each cluster, a linear regression is applied. We report the Pearson correlation coefficient, slope, and intercept and visualize the fitted lines. For step 1, we select a popular pre-trained modelall-mpnet-base-v2 [67] as the Sentence Transformer encoder to project a sentence to a high-dimension embeddin...
-
[74]
Detect distinctive samples within each cluster. Zhang et al. [68] formulates this task as adifferential clustering problem and proposes a FINC method. To quantitatively measure semantic distinctions 19 Figure 13: Clustering Visualization (OLMo-1B Pretraining Datasets) among the 16 clusters obtained via K-means, we conducted 16 FINC comparisons. For each c...
-
[75]
Keywords summarization. In this stage, we use tri-grams as effective descriptors for naming and interpreting cluster identities. Specifically, we use i)spaCy [69] to perform named entity recognition and dependency parsing to ensure that extracted units are linguistically complete phrases (e.g.,“protective spell harry”, “lend broom fly”), and ii)YAKE [70] ...
-
[76]
Human annotation. Based on summarized keywords, human annotators further summarize the semantics of the cluster. Semantics of each cluster Table 5 presents top-5 keywords and human-annotated semantic labels for each cluster. 20 (a) Cluster 0 (b) Cluster 1 (c) Cluster 2 (d) Cluster 3 (e) Cluster 4 (f) Cluster 5 (g) Cluster 6 (h) Cluster 7 Figure 14: Cluste...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.