Inference-Time Scaling of Diffusion Language Models via Trajectory Refinement
Pith reviewed 2026-05-19 04:58 UTC · model grok-4.3
The pith
Particle Gibbs sampling refines full denoising trajectories in diffusion language models to introduce a new scaling axis of refinement iterations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
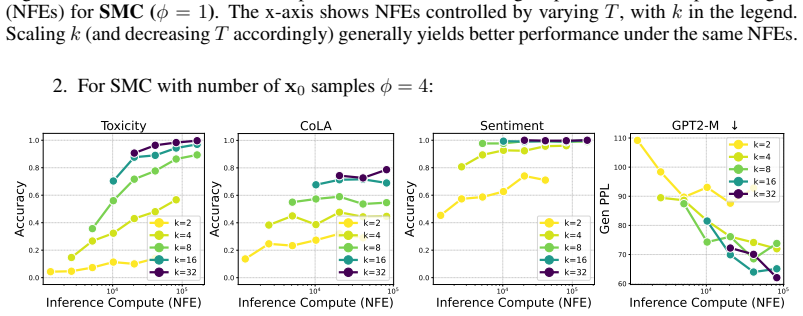
PG-DLM constructs a Markov chain over full denoising trajectories and applies a conditional sequential Monte Carlo kernel to resample them, introducing a new scaling axis (number of refinement iterations) that remains effective even as gains from adding more parallel samples saturate.
What carries the argument
Markov chain over full denoising trajectories with a conditional sequential Monte Carlo kernel for resampling.
If this is right
- Reward-guided generation accuracy rises with additional refinement iterations after parallel sampling saturates.
- Adaptive compute allocation becomes possible by performing extra iterations only on difficult samples.
- Theoretical convergence and variance bounds hold for the constructed Markov chain.
- Empirical outperformance occurs across varying compute budgets on tasks such as GSM8K math problems.
Where Pith is reading between the lines
- The trajectory-level view may extend to other discrete generative processes where step-wise resampling is currently used.
- Future inference scaling laws could treat refinement iterations as an orthogonal axis to model size or sample count.
- Combining trajectory refinement with light fine-tuning might produce larger gains than either alone.
Load-bearing premise
The conditional sequential Monte Carlo kernel can be implemented efficiently and the resulting Markov chain mixes sufficiently fast to deliver measurable gains within a small number of refinement iterations.
What would settle it
If accuracy on GSM8K stops improving when refinement iterations increase from a few to ten while particle count stays fixed, the claim of an effective new scaling axis would be contradicted.
Figures









read the original abstract
Discrete diffusion models have recently emerged as strong alternatives to autoregressive language models, matching their performance through large-scale training. However, inference-time control remains relatively underexplored. In this work, we study how to steer generation toward desired rewards without retraining the models. Prior methods typically resample or filter within a single denoising trajectory, optimizing rewards step-by-step without trajectory-level refinement. We introduce particle Gibbs sampling for diffusion language models (PG-DLM), an inference-time algorithm enabling trajectory-level refinement. PG-DLM constructs a Markov chain over full denoising trajectories and applies a conditional sequential Monte Carlo kernel to resample them. By doing so, PG-DLM introduces a new scaling axis, the number of refinement iterations, which is unavailable to prior methods. Increasing iterations remains effective even as gains from adding more parallel samples saturate. Furthermore, PG-DLM enables adaptive compute allocation by performing additional iterations only when needed, leading to further efficiency gains. We derive theoretical guarantees for convergence and variance bounds, and analyze trade-offs across different scaling axes. Empirically, PG-DLM outperforms prior methods across compute budgets on reward-guided generation tasks. On GSM8K, it achieves 90.07% accuracy with 2.9 particles on average and 94.47% accuracy with 16 particles.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PG-DLM, a particle Gibbs sampling method for diffusion language models. It constructs a Markov chain over full denoising trajectories and applies a conditional sequential Monte Carlo kernel to enable trajectory-level refinement. This adds the number of refinement iterations as a new inference-time scaling axis that remains effective after parallel sampling saturates. Theoretical convergence and variance bounds are derived from SMC/MCMC theory, and experiments show outperformance on reward-guided tasks, including 90.07% accuracy on GSM8K with 2.9 particles on average and 94.47% with 16 particles.
Significance. If the conditional SMC kernel mixes sufficiently fast and can be implemented efficiently, the work provides a new, adaptive compute axis for steering discrete diffusion LMs at inference time without retraining. The theoretical guarantees and concrete GSM8K results strengthen the case for trajectory-level methods over step-wise resampling, with potential efficiency gains from adaptive iteration allocation.
major comments (2)
- [Abstract and theoretical section] Abstract and theoretical section: the convergence and variance bounds rely on standard SMC theory applied to the diffusion process, yet no mixing-time analysis, autocorrelation plots, or effective sample size curves versus refinement iteration count are provided to substantiate that the conditional SMC kernel mixes rapidly enough in the discrete high-dimensional trajectory space for the claimed gains with small iteration counts.
- [Empirical evaluation on GSM8K] Empirical evaluation on GSM8K: the reported accuracies (90.07% with average 2.9 particles, 94.47% with 16 particles) are presented without full specification of the precise SMC kernel form or any post-hoc tuning of particle counts and iteration schedules, leaving open the possibility that performance depends on implementation choices not visible in the manuscript.
minor comments (2)
- [Methods section] Methods section: provide pseudocode or a clear algorithmic description of the conditional SMC kernel and the overall PG-DLM procedure to improve reproducibility.
- [Figures comparing scaling axes] Figures comparing scaling axes: include error bars or multiple random seeds to allow assessment of variability in the trade-off between refinement iterations and parallel samples.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive feedback on our manuscript. We address each major comment below and indicate the revisions we plan to incorporate.
read point-by-point responses
-
Referee: [Abstract and theoretical section] Abstract and theoretical section: the convergence and variance bounds rely on standard SMC theory applied to the diffusion process, yet no mixing-time analysis, autocorrelation plots, or effective sample size curves versus refinement iteration count are provided to substantiate that the conditional SMC kernel mixes rapidly enough in the discrete high-dimensional trajectory space for the claimed gains with small iteration counts.
Authors: We acknowledge that the manuscript presents convergence and variance bounds derived from standard SMC/MCMC theory without accompanying empirical diagnostics such as mixing-time analysis or effective sample size curves. While the theoretical results guarantee asymptotic correctness independent of mixing rate, we agree that empirical evidence would better substantiate the practical gains observed with small iteration counts. In the revised manuscript we will add effective sample size curves and autocorrelation plots versus refinement iteration count for the GSM8K experiments to illustrate the mixing behavior of the conditional SMC kernel. revision: yes
-
Referee: [Empirical evaluation on GSM8K] Empirical evaluation on GSM8K: the reported accuracies (90.07% with average 2.9 particles, 94.47% with 16 particles) are presented without full specification of the precise SMC kernel form or any post-hoc tuning of particle counts and iteration schedules, leaving open the possibility that performance depends on implementation choices not visible in the manuscript.
Authors: We thank the referee for highlighting the need for greater implementation transparency. The manuscript currently describes the PG-DLM procedure at the algorithmic level. To improve reproducibility, the revised version will provide the exact mathematical form of the conditional SMC kernel, pseudocode for the resampling step, and the precise particle counts together with the iteration schedules employed in the GSM8K experiments. We confirm that the reported accuracies correspond to these configurations without additional undisclosed tuning. revision: yes
Circularity Check
No significant circularity; derivation applies standard SMC theory independently
full rationale
The paper introduces PG-DLM by constructing a Markov chain over full denoising trajectories and applying a conditional sequential Monte Carlo kernel, deriving convergence and variance bounds from established SMC/MCMC theory rather than internal fits or self-citations. No equations reduce reported performance or scaling claims to quantities defined or fitted inside the paper itself. The new scaling axis (refinement iterations) is presented as a direct consequence of the trajectory-level resampling, with empirical results on tasks like GSM8K treated as external validation. The derivation remains self-contained against external benchmarks such as standard SMC convergence results.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of particles
- number of refinement iterations
axioms (1)
- domain assumption The discrete diffusion process induces a valid Markov chain on full trajectories that admits a conditional SMC kernel.
Forward citations
Cited by 5 Pith papers
-
Contrastive Distribution Matching for Amortized Sequential Monte Carlo in Discrete Diffusion
CDM amortizes SMC inference for reward-tilted discrete diffusion by training a parameterized twist function on contrastive samples with closed-form kernels.
-
Focus on the Core: Empowering Diffusion Large Language Models by Self-Contrast
FoCore uses self-contrast on early-converging high-density tokens to boost diffusion LLM quality on reasoning benchmarks while cutting decoding steps by over 2x.
-
Iterative Inference-time Scaling with Adaptive Frequency Steering for Image Super-Resolution
IAFS is a training-free iterative inference-time scaling framework that uses adaptive frequency-aware particle fusion to resolve the perception-fidelity conflict in diffusion super-resolution models, outperforming pri...
-
ETS: Energy-Guided Test-Time Scaling for Training-Free RL Alignment
ETS enables direct sampling from the optimal RL policy for language models at inference time by estimating the energy term with online Monte Carlo and acceleration techniques.
-
ETS: Energy-Guided Test-Time Scaling for Training-Free RL Alignment
ETS performs training-free RL alignment for language models by energy-guided test-time scaling with Monte Carlo energy estimation and importance sampling acceleration.
Reference graph
Works this paper leans on
-
[1]
Particle markov chain monte carlo methods
Christophe Andrieu, Arnaud Doucet, and Roman Holenstein. Particle markov chain monte carlo methods. Journal of the Royal Statistical Society Series B: Statistical Methodology, 72 0 (3): 0 269--342, 2010
work page 2010
-
[2]
Structured denoising diffusion models in discrete state-spaces
Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel Tarlow, and Rianne Van Den Berg. Structured denoising diffusion models in discrete state-spaces. In Advances in neural information processing systems, volume 34, pages 17981--17993, 2021
work page 2021
-
[3]
Tweeteval: Unified benchmark and comparative evaluation for tweet classification
Francesco Barbieri, Jose Camacho-Collados, Luis Espinosa Anke, and Leonardo Neves. Tweeteval: Unified benchmark and comparative evaluation for tweet classification. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 1644--1650, 2020
work page 2020
-
[4]
Scaling test-time compute with open models
Edward Beeching, Lewis Tunstall, and Sasha Rush. Scaling test-time compute with open models. URL: https://huggingface.co/spaces/HuggingFaceH4/blogpost-scaling-test-time-compute, 2024
work page 2024
-
[5]
Training diffusion models with reinforcement learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning. In International Conference on Learning Representations, 2024
work page 2024
-
[6]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Directly Fine-Tuning Diffusion Models on Differentiable Rewards
Kevin Clark, Paul Vicol, Kevin Swersky, and David J Fleet. Directly fine-tuning diffusion models on differentiable rewards. arXiv preprint arXiv:2309.17400, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Plug and play language models: A simple approach to controlled text generation
Sumanth Dathathri, Andrea Madotto, Janice Lan, Jane Hung, Eric Frank, Piero Molino, Jason Yosinski, and Rosanne Liu. Plug and play language models: A simple approach to controlled text generation. In International Conference on Learning Representations, 2020
work page 2020
-
[9]
Diffusion posterior sampling for linear inverse problem solving: A filtering perspective
Zehao Dou and Yang Song. Diffusion posterior sampling for linear inverse problem solving: A filtering perspective. In International Conference on Learning Representations, 2024
work page 2024
-
[10]
An introduction to sequential monte carlo methods
Arnaud Doucet, Nando De Freitas, and Neil Gordon. An introduction to sequential monte carlo methods. Sequential Monte Carlo methods in practice, pages 3--14, 2001
work page 2001
-
[11]
Reinforcement learning for fine-tuning text-to-image diffusion models
Ying Fan, Olivia Watkins, Yuqing Du, Hao Liu, Moonkyung Ryu, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, Kangwook Lee, and Kimin Lee. Reinforcement learning for fine-tuning text-to-image diffusion models. In Advances in Neural Information Processing Systems, volume 36, 2024
work page 2024
-
[12]
Itai Gat, Tal Remez, Neta Shaul, Felix Kreuk, Ricky T. Q. Chen, Gabriel Synnaeve, Yossi Adi, and Yaron Lipman. Discrete flow matching. In Advances in Neural Information Processing Systems, volume 37, 2024
work page 2024
-
[13]
Aaron Gokaslan, Vanya Cohen, Ellie Pavlick, and Stefanie Tellex. Openwebtext corpus. http://Skylion007.github.io/OpenWebTextCorpus, 2019
work page 2019
-
[14]
Scaling diffusion language models via adaptation from autoregressive models
Shansan Gong, Shivam Agarwal, Yizhe Zhang, Jiacheng Ye, Lin Zheng, Mukai Li, Chenxin An, Peilin Zhao, Wei Bi, Jiawei Han, et al. Scaling diffusion language models via adaptation from autoregressive models. In International Conference on Learning Representations, 2025
work page 2025
-
[15]
Xiaochuang Han, Sachin Kumar, and Yulia Tsvetkov. Ssd-lm: Semi-autoregressive simplex-based diffusion language model for text generation and modular control. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11575--11596, 2023
work page 2023
-
[16]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in neural information processing systems, volume 33, pages 6840--6851, 2020
work page 2020
-
[17]
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models. In Advances in Neural Information Processing Systems, volume 35, pages 8633--8646, 2022
work page 2022
-
[18]
Sequence tutor: Conservative fine-tuning of sequence generation models with kl-control
Natasha Jaques, Shixiang Gu, Dzmitry Bahdanau, Jos \'e Miguel Hern \'a ndez-Lobato, Richard E Turner, and Douglas Eck. Sequence tutor: Conservative fine-tuning of sequence generation models with kl-control. In International Conference on Machine Learning, pages 1645--1654, 2017
work page 2017
-
[19]
CTRL: A Conditional Transformer Language Model for Controllable Generation
Nitish Shirish Keskar, Bryan McCann, Lav R Varshney, Caiming Xiong, and Richard Socher. Ctrl: A conditional transformer language model for controllable generation. arXiv preprint arXiv:1909.05858, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[20]
Jaihoon Kim, Taehoon Yoon, Jisung Hwang, and Minhyuk Sung. Inference-time scaling for flow models via stochastic generation and rollover budget forcing. arXiv preprint arXiv:2503.19385, 2025
-
[21]
Rl with kl penalties is better viewed as bayesian inference
Tomasz Korbak, Ethan Perez, and Christopher Buckley. Rl with kl penalties is better viewed as bayesian inference. In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 1083--1091, 2022
work page 2022
-
[22]
Sequential monte carlo steering of large language models using probabilistic programs,
Alexander K Lew, Tan Zhi-Xuan, Gabriel Grand, and Vikash K Mansinghka. Sequential monte carlo steering of large language models using probabilistic programs. arXiv preprint arXiv:2306.03081, 2023
-
[23]
Discrete predictor-corrector diffusion models for image synthesis
Jose Lezama, Tim Salimans, Lu Jiang, Huiwen Chang, Jonathan Ho, and Irfan Essa. Discrete predictor-corrector diffusion models for image synthesis. In International Conference on Learning Representations, 2022
work page 2022
-
[24]
arXiv preprint arXiv:2408.08252 , year =
Xiner Li, Yulai Zhao, Chenyu Wang, Gabriele Scalia, Gokcen Eraslan, Surag Nair, Tommaso Biancalani, Shuiwang Ji, Aviv Regev, Sergey Levine, et al. Derivative-free guidance in continuous and discrete diffusion models with soft value-based decoding. arXiv preprint arXiv:2408.08252, 2024
-
[25]
Particle gibbs with ancestor sampling
Fredrik Lindsten, Michael I Jordan, and Thomas B Sch \"o n. Particle gibbs with ancestor sampling. The Journal of Machine Learning Research, 15 0 (1): 0 2145--2184, 2014
work page 2014
-
[26]
Paradetox: Detoxification with parallel data
Varvara Logacheva, Daryna Dementieva, Sergey Ustyantsev, Daniil Moskovskiy, David Dale, Irina Krotova, Nikita Semenov, and Alexander Panchenko. Paradetox: Detoxification with parallel data. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6804--6818, 2022
work page 2022
-
[27]
Discrete diffusion modeling by estimating the ratios of the data distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution. In International Conference on Machine Learning, 2023
work page 2023
-
[28]
Inference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps
Nanye Ma, Shangyuan Tong, Haolin Jia, Hexiang Hu, Yu-Chuan Su, Mingda Zhang, Xuan Yang, Yandong Li, Tommi Jaakkola, Xuhui Jia, et al. Inference-time scaling for diffusion models beyond scaling denoising steps. arXiv preprint arXiv:2501.09732, 2025
work page internal anchor Pith review arXiv 2025
-
[29]
Textattack: A framework for adversarial attacks, data augmentation, and adversarial training in nlp
John Morris, Eli Lifland, Jin Yong Yoo, Jake Grigsby, Di Jin, and Yanjun Qi. Textattack: A framework for adversarial attacks, data augmentation, and adversarial training in nlp. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 119--126, 2020
work page 2020
-
[30]
Elements of sequential monte carlo
Christian A Naesseth, Fredrik Lindsten, Thomas B Sch \"o n, et al. Elements of sequential monte carlo. Foundations and Trends in Machine Learning , 12 0 (3): 0 307--392, 2019
work page 2019
-
[31]
Particle-filtering-based latent diffusion for inverse problems
Amir Nazemi, Mohammad Hadi Sepanj, Nicholas Pellegrino, Chris Czarnecki, and Paul Fieguth. Particle-filtering-based latent diffusion for inverse problems. arXiv preprint arXiv:2408.13868, 2024
-
[32]
Scaling up masked diffusion models on text
Shen Nie, Fengqi Zhu, Chao Du, Tianyu Pang, Qian Liu, Guangtao Zeng, Min Lin, and Chongxuan Li. Scaling up masked diffusion models on text. In International Conference on Learning Representations, 2025 a
work page 2025
-
[33]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models. arXiv preprint arXiv:2502.09992, 2025 b
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. In Advances in neural information processing systems, volume 35, pages 27730--27744, 2022
work page 2022
-
[35]
W\"urstchen: An efficient architecture for large-scale text-to-image diffusion models
Pablo Pernias, Dominic Rampas, Mats Leon Richter, Christopher Pal, and Marc Aubreville. W\"urstchen: An efficient architecture for large-scale text-to-image diffusion models. In International Conference on Learning Representations, 2024
work page 2024
-
[36]
SDXL : Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M \"u ller, Joe Penna, and Robin Rombach. SDXL : Improving latent diffusion models for high-resolution image synthesis. In International Conference on Learning Representations, 2024
work page 2024
-
[37]
Isha Puri, Shivchander Sudalairaj, Guangxuan Xu, Kai Xu, and Akash Srivastava. A probabilistic inference approach to inference-time scaling of llms using particle-based monte carlo methods. arXiv preprint arXiv:2502.01618, 2025
-
[38]
Language models are unsupervised multitask learners
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1 0 (8): 0 9, 2019
work page 2019
-
[39]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In Advances in Neural Information Processing Systems, volume 36, 2024
work page 2024
-
[40]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[41]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj \"o rn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684--10695, 2022
work page 2022
-
[42]
Photorealistic text-to-image diffusion models with deep language understanding
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language understanding. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. O...
work page 2022
-
[43]
Simple and effective masked diffusion language models
Subham Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin Chiu, Alexander Rush, and Volodymyr Kuleshov. Simple and effective masked diffusion language models. In Advances in Neural Information Processing Systems, volume 37, pages 130136--130184, 2024
work page 2024
-
[44]
Simple guidance mechanisms for discrete diffusion models
Yair Schiff, Subham Sekhar Sahoo, Hao Phung, Guanghan Wang, Sam Boshar, Hugo Dalla-torre, Bernardo P de Almeida, Alexander Rush, Thomas Pierrot, and Volodymyr Kuleshov. Simple guidance mechanisms for discrete diffusion models. In International Conference on Learning Representations, 2025
work page 2025
-
[45]
Simplified and generalized masked diffusion for discrete data
Jiaxin Shi, Kehang Han, Zhe Wang, Arnaud Doucet, and Michalis Titsias. Simplified and generalized masked diffusion for discrete data. In Advances in neural information processing systems, volume 37, pages 103131--103167, 2024
work page 2024
-
[46]
Raghav Singhal, Zachary Horvitz, Ryan Teehan, Mengye Ren, Zhou Yu, Kathleen McKeown, and Rajesh Ranganath. A general framework for inference-time scaling and steering of diffusion models. arXiv preprint arXiv:2501.06848, 2025
-
[47]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters. arXiv preprint arXiv:2408.03314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In International conference on machine learning, pages 2256--2265, 2015
work page 2015
-
[49]
Generative modeling by estimating gradients of the data distribution
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. Advances in neural information processing systems, 32, 2019
work page 2019
-
[50]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, 2021
work page 2021
-
[51]
Masatoshi Uehara, Yulai Zhao, Kevin Black, Ehsan Hajiramezanali, Gabriele Scalia, Nathaniel Lee Diamant, Alex M Tseng, Tommaso Biancalani, and Sergey Levine. Fine-tuning of continuous-time diffusion models as entropy-regularized control. arXiv preprint arXiv:2402.15194, 2024 a
-
[52]
Masatoshi Uehara, Yulai Zhao, Ehsan Hajiramezanali, Gabriele Scalia, Gokcen Eraslan, Avantika Lal, Sergey Levine, and Tommaso Biancalani. Bridging model-based optimization and generative modeling via conservative fine-tuning of diffusion models. In Advances in Neural Information Processing Systems, volume 37, pages 127511--127535, 2024 b
work page 2024
-
[53]
Diffusion model alignment using direct preference optimization
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. Diffusion model alignment using direct preference optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8228--8238, 2024
work page 2024
-
[54]
Guanghan Wang, Yair Schiff, Subham Sekhar Sahoo, and Volodymyr Kuleshov. Remasking discrete diffusion models with inference-time scaling. arXiv preprint arXiv:2503.00307, 2025
-
[55]
Neural network acceptability judgments
Alex Warstadt, Amanpreet Singh, and Samuel R Bowman. Neural network acceptability judgments. In Transactions of the Association for Computational Linguistics, volume 7, pages 625--641. MIT Press One Rogers Street, Cambridge, MA 02142-1209, USA journals-info …, 2019
work page 2019
-
[56]
Trippe, Christian A Naesseth, John Patrick Cunningham, and David Blei
Luhuan Wu, Brian L. Trippe, Christian A Naesseth, John Patrick Cunningham, and David Blei. Practical and asymptotically exact conditional sampling in diffusion models. In Advances in Neural Information Processing Systems, 2023
work page 2023
-
[57]
Geodiff: A geometric diffusion model for molecular conformation generation
Minkai Xu, Lantao Yu, Yang Song, Chence Shi, Stefano Ermon, and Jian Tang. Geodiff: A geometric diffusion model for molecular conformation generation. In International Conference on Learning Representations, 2022
work page 2022
-
[58]
Informed correctors for discrete diffusion models, 2025
Yixiu Zhao, Jiaxin Shi, Feng Chen, Shaul Druckmann, Lester Mackey, and Scott Linderman. Informed correctors for discrete diffusion models. arXiv preprint arXiv:2407.21243, 2024
-
[59]
Kaiwen Zheng, Yongxin Chen, Hanzi Mao, Ming-Yu Liu, Jun Zhu, and Qinsheng Zhang. Masked diffusion models are secretly time-agnostic masked models and exploit inaccurate categorical sampling. In International Conference on Learning Representations, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.