Beyond Binary Rewards: Training LMs to Reason About Their Uncertainty
Pith reviewed 2026-05-21 23:58 UTC · model grok-4.3
The pith
Augmenting binary rewards with Brier scores in RL training produces accurate and well-calibrated language model reasoners.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By training with a composite reward of binary correctness plus Brier score on verbalized confidence, language models learn to generate reasoning chains that support both correct answers and accurate probability estimates, with theoretical guarantees from proper scoring rules and empirical gains in calibration metrics across in- and out-of-domain settings.
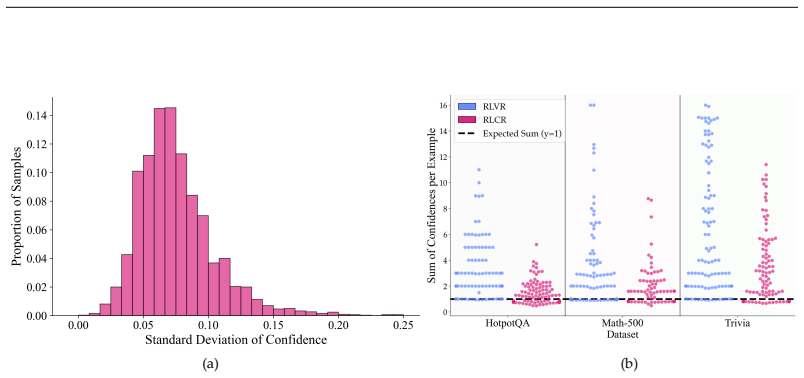
What carries the argument
The calibration-augmented reward function in RLCR, which scores both the correctness of the final answer and the accuracy of the accompanying confidence estimate using the Brier score.
If this is right
- RLCR improves calibration metrics while maintaining accuracy on diverse QA datasets.
- Verbalized confidence from RLCR models enables better accuracy and calibration through confidence-weighted scaling at test time.
- The approach outperforms both standard RL and post-hoc trained confidence classifiers.
- Ordinary RL training degrades calibration, whereas RLCR enhances it.
Where Pith is reading between the lines
- This joint optimization could support safer use of reasoning models in settings where knowing when outputs are uncertain reduces risk.
- The method might combine with other uncertainty techniques to handle different types of model uncertainty.
- Scaling tests on longer or multi-step reasoning problems could check whether the calibration gains hold without extra stabilization.
Load-bearing premise
Language models can be trained via RL to produce meaningful numerical confidence estimates alongside reasoning chains, with the Brier score term optimized jointly without destabilizing policy gradients.
What would settle it
If RLCR models show no reduction in expected calibration error compared to standard RL models on out-of-domain tasks, the claim of improved calibration would be falsified.
Figures





read the original abstract
When language models (LMs) are trained via reinforcement learning (RL) to generate natural language "reasoning chains", their performance improves on a variety of difficult question answering tasks. Today, almost all successful applications of RL for reasoning use binary reward functions that evaluate the correctness of LM outputs. Because such reward functions do not penalize guessing or low-confidence outputs, they often have the unintended side-effect of degrading calibration and increasing the rate at which LMs generate incorrect responses (or "hallucinate") in other problem domains. This paper describes RLCR (Reinforcement Learning with Calibration Rewards), an approach to training reasoning models that jointly improves accuracy and calibrated confidence estimation. During RLCR, LMs generate both predictions and numerical confidence estimates after reasoning. They are trained to optimize a reward function that augments a binary correctness score with a Brier score -- a scoring rule for confidence estimates that incentivizes calibrated prediction. We first prove that this reward function (or any reward function that uses a bounded, proper scoring rule) yields models whose predictions are both accurate and well-calibrated. We next show that across diverse datasets, RLCR substantially improves calibration with no loss in accuracy, on both in-domain and out-of-domain evaluations -- outperforming both ordinary RL training and classifiers trained to assign post-hoc confidence scores. While ordinary RL hurts calibration, RLCR improves it. Finally, we demonstrate that verbalized confidence can be leveraged at test time to improve accuracy and calibration via confidence-weighted scaling methods. Our results show that explicitly optimizing for calibration can produce more generally reliable reasoning models. Code, models, and further info is available at https://rl-calibration.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RLCR, an RL approach for training language models on reasoning tasks that augments standard binary correctness rewards with a Brier score term to jointly optimize accuracy and calibrated confidence estimates. It proves that any reward using a bounded proper scoring rule produces models whose predictions are both accurate and well-calibrated, demonstrates empirically that RLCR improves calibration with no accuracy loss on in- and out-of-domain tasks (outperforming ordinary RL and post-hoc classifiers), and shows that verbalized confidence can be used at test time for further gains via scaling methods.
Significance. If the central claims hold, the work is significant because it directly tackles the calibration degradation induced by binary rewards in RL for reasoning, a common issue leading to increased hallucinations. The theoretical result leverages standard properties of proper scoring rules to guarantee calibration under reward maximization, and the empirical results across diverse datasets provide evidence that explicit calibration optimization can yield more reliable reasoning models without sacrificing performance. Releasing code and models further strengthens the contribution for reproducibility.
major comments (2)
- [§4 (Theoretical Analysis)] §4 (Theoretical Analysis): The proof that bounded proper scoring rules (including the binary + Brier composite) yield accurate and well-calibrated models assumes exact expected-reward maximization. It does not address whether standard policy-gradient methods (e.g., REINFORCE) can reach this joint optimum given the differing scales and variances of the binary term and the (c - y)^2 Brier term, which is load-bearing for transferring the guarantee to practical LM training.
- [Experimental section (results on calibration and accuracy)] Experimental section (results on calibration and accuracy): The reported improvements in calibration with no accuracy loss rest on the assumption that the Brier term can be optimized jointly without destabilizing updates. No ablations on reward scaling, normalization, or separate critics are described to mitigate gradient issues, weakening the claim that RLCR reliably outperforms ordinary RL in practice.
minor comments (2)
- [Abstract] The abstract states that RLCR 'substantially improves calibration with no loss in accuracy' but should explicitly name the primary metrics (e.g., ECE, Brier score) and the number of datasets used in the one-paragraph summary.
- [Method] Notation for the composite reward function should be introduced earlier and used consistently when describing how the Brier score is added to the binary correctness signal.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and describe the revisions we plan to make.
read point-by-point responses
-
Referee: [§4 (Theoretical Analysis)] §4 (Theoretical Analysis): The proof that bounded proper scoring rules (including the binary + Brier composite) yield accurate and well-calibrated models assumes exact expected-reward maximization. It does not address whether standard policy-gradient methods (e.g., REINFORCE) can reach this joint optimum given the differing scales and variances of the binary term and the (c - y)^2 Brier term, which is load-bearing for transferring the guarantee to practical LM training.
Authors: We agree that the theoretical guarantee in §4 holds under exact expected-reward maximization, which is the natural setting for analyzing proper scoring rules. The proof establishes that any policy maximizing the composite reward (binary correctness plus bounded proper scoring rule) must be both accurate and calibrated. We do not claim that REINFORCE or other policy-gradient methods necessarily converge to this exact joint optimum, given the potential differences in scale and variance between the two reward components. Our empirical results across in-domain and out-of-domain tasks nevertheless show that RLCR consistently improves calibration without accuracy loss relative to standard RL, indicating that the practical optimization procedure is effective. In the revision we will add a brief discussion of this distinction between the exact optimum and the approximate optimization achieved by policy gradients, along with a note on the empirical evidence supporting transfer of the qualitative guarantee. revision: partial
-
Referee: [Experimental section (results on calibration and accuracy)] Experimental section (results on calibration and accuracy): The reported improvements in calibration with no accuracy loss rest on the assumption that the Brier term can be optimized jointly without destabilizing updates. No ablations on reward scaling, normalization, or separate critics are described to mitigate gradient issues, weakening the claim that RLCR reliably outperforms ordinary RL in practice.
Authors: We acknowledge that the current experiments do not include explicit ablations on reward scaling, normalization, or separate critics, which would strengthen the robustness claims. In the experiments we combined the terms into a single scalar reward and observed stable training with the reported gains. To address this concern we will add ablations in the revised manuscript that vary the relative scaling of the Brier term, apply normalization to each component, and compare against a variant using separate value heads where feasible. These results will be included to demonstrate that the calibration improvements are not artifacts of a particular reward formulation. revision: yes
Circularity Check
No significant circularity; calibration proof relies on external proper scoring rule properties
full rationale
The paper's load-bearing theoretical step is the claim that a composite reward using a bounded proper scoring rule (binary correctness plus Brier score) produces accurate and calibrated models. This follows directly from the known mathematical property that proper scoring rules elicit truthful reporting of beliefs, which is a standard result in decision theory and is invoked as external background rather than derived or fitted inside the paper. No equations reduce a prediction to a fitted parameter by construction, no uniqueness theorem is imported from the authors' prior work, and no ansatz is smuggled via self-citation. Empirical RL results and test-time scaling are presented as separate contributions without circular dependence on the proof. A minor self-citation for related RL reasoning methods may be present but is not load-bearing for the central claim.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Bounded proper scoring rules such as the Brier score incentivize calibrated probability estimates.
Forward citations
Cited by 9 Pith papers
-
Distributional Process Reward Models: Calibrated Prediction of Future Rewards via Conditional Optimal Transport
Conditional optimal transport calibrates PRMs by learning monotonic conditional quantile functions over success probabilities conditioned on hidden states, yielding improved calibration and downstream Best-of-N perfor...
-
Distributional Process Reward Models: Calibrated Prediction of Future Rewards via Conditional Optimal Transport
Conditional optimal transport is used to turn raw PRM outputs into monotonic quantile functions that improve calibration and downstream Best-of-N performance on MATH-500 and AIME.
-
Process Supervision of Confidence Margin for Calibrated LLM Reasoning
RLCM trains LLMs with a margin-enhanced process reward that widens the gap between correct and incorrect reasoning steps, improving calibration on math, code, logic, and science tasks without hurting accuracy.
-
Do Not Imitate, Reinforce: Iterative Classification via Belief Refinement
RIC replaces single-pass label imitation with RL-driven iterative belief refinement, recovering cross-entropy optima while enabling adaptive halting via a value function.
-
Unsupervised Confidence Calibration for Reasoning LLMs from a Single Generation
Unsupervised single-generation confidence calibration for reasoning LLMs via offline self-consistency proxy distillation outperforms baselines on math and QA tasks and improves selective prediction.
-
Calibration-Aware Policy Optimization for Reasoning LLMs
CAPO improves LLM calibration by up to 15% while matching or exceeding GRPO accuracy through logistic AUC loss and noise masking, enabling better abstention and scaling performance.
-
Decoupling Reasoning and Confidence: Resurrecting Calibration in Reinforcement Learning from Verifiable Rewards
DCPO decouples reasoning optimization from calibration in RLVR to fix overconfidence in LLMs without losing accuracy.
-
Illusions of Confidence? Diagnosing LLM Truthfulness via Neighborhood Consistency
Neighbor-Consistency Belief (NCB) measures LLM belief robustness across conceptual neighborhoods, revealing that high-NCB facts resist contextual interference better, and Structure-Aware Training reduces brittleness b...
-
AI Observability for Large Language Model Systems: A Multi-Layer Analysis of Monitoring Approaches from Confidence Calibration to Infrastructure Tracing
This analysis synthesizes recent LLM observability research into a five-layer framework and identifies the integration of model signals with infrastructure anomalies as the central open problem.
Reference graph
Works this paper leans on
-
[1]
On Verbalized Confidence Scores for LLMs
URL https://arxiv.org/abs/2412.14737. 14 Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answer- ing. In Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii (eds.), Proceedings of the 2018 Conference on Empir...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/d18-1259 2018
-
[2]
If S(p, 1) − S(p, 0) is bounded, then there exists a finiteλ > 0 such that the reward function R(c, q) = λc − S(q, c) satisfies the correctness condition: S(p, 1) − S(p, 0) ≤ λ for all p ∈ [0, 1] and thus jointly incentivizes calibration and correctness
-
[3]
If S(p, 1) − S(p, 0) is unbounded, then for any finite λ > 0, there may exist some y ≥ y′ such that W (py) < W (py′), and RRLCR prefers (y′, py′) to (y, py). Examples. The Brier score is bounded: S(p, 1) = (1 − p)2, S(p, 0) = p2, so: S(p, 1) − S(p, 0) = 1 − 2p ≤ 1 for all p ∈ [0, 1] Thus, the condition holds for λ = 1. In contrast, the logarithmic score i...
work page 2018
-
[4]
We slightly modify the dataset and remove 2 non-relevant paragraphs from each question
HotPotQA (Distractor): We use 1000 validation examples from the original HotpotQA distractor dataset. We slightly modify the dataset and remove 2 non-relevant paragraphs from each question. Thus, each question has 8 paragraphs with both supporting paragraphs present. We measure correctness using exact-match (Yang et al., 2018)
work page 2018
-
[5]
We measure correctness using exact-match
HotPotQA-Modified: We evaluate on 500 held-out validation examples. We measure correctness using exact-match. 18
-
[6]
We use the no-context split to purely test factual accuracy.We evaluate using LLM-as-a-judge
TriviaQA: We use 2000 examples from the validation set of the TriviaQA dataset (Joshi et al., 2017). We use the no-context split to purely test factual accuracy.We evaluate using LLM-as-a-judge
work page 2000
-
[7]
We evaluate using LLM-as-a-judge
SimpleQA: We use the full SimpleQA dataset consisting of 4326 factual questions (Wei et al., 2024). We evaluate using LLM-as-a-judge
work page 2024
-
[8]
We evaluate usingmath-verify, a mathematical expression evaluation system released by huggingface
Math-500 We use the popular MATH-500 dataset, which contains a subset of problems from the original MATH dataset (Hendrycks et al., 2021). We evaluate usingmath-verify, a mathematical expression evaluation system released by huggingface
work page 2021
-
[9]
GSM8K: We use the test set ( 1319 problems) of the popular Grade School Math 8K dataset (Cobbe et al., 2021). We evaluate using math-verify
work page 2021
-
[10]
Big-Math-Digits: We evaluate on1000 held-out validation examples. We evaluate using math-verify
-
[11]
We evaluate using LLM-as-a-judge
CommonSenseQA: We use the validation set (1220 problems) of the CommonsenseQA dataset (Talmor et al., 2019), a multiple-choice question answering dataset that requires different types of commonsense knowledge to predict the correct answers. We evaluate using LLM-as-a-judge
work page 2019
-
[12]
We evaluate using LLM- as-a-judge
GPQA: We use the GPQA main dataset containing 448 multiple-choice questions written by experts in biology, physics, and chemistry (Rein et al., 2024). We evaluate using LLM- as-a-judge. B.4 E VALUATION DETAILS All models are evaluated with temperature 0. For all datasets except Math and GSM8K, we use a maximum token budget of 4096. The system prompt for e...
work page 2024
-
[13]
They are evaluated with the same system prompts they are trained on
RLCR (ours): RLCR models use <think>, <answer>, <analysis> and <confidence> tags. They are evaluated with the same system prompts they are trained on. We extract their answer from <answer> tag and their confidence from <confidence> tag
-
[14]
It is evaluated with the same system prompt and we extract their answer from the <answer> tag
RLVR: RLVR models use the <think> and <answer>. It is evaluated with the same system prompt and we extract their answer from the <answer> tag. To obtain their verbalized confidence, we append ”Thinking time ended. My verbalized confidence in my answer as a number between 0 and 100 is equal to” to their generated output
-
[15]
Classifier/Probe: Both methods are conditioned on the question and the RLVR model’s generation (solution and answer). These methods thus use RLVR model as a generator and their reported accuracies in the result tables are equal
-
[16]
In case no valid confidence can be extracted, we append ”Thinking time ended
Base: The base model is not good at instruction following and is prompted with a simpler system prompt (Simple Confidence Prompt) that guides it to use <think>, <answer> and <confidence> tags. In case no valid confidence can be extracted, we append ”Thinking time ended. My verbalized confidence in my answer as a number between 0 and 100 is equal to” to th...
-
[17]
You should not suggest ways of fixing the response, your job is only to reason about uncertainties
-
[18]
For some questions, the response might be correct. In these cases, It is also okay to have only a small number of uncertainties and then explicitly say that I am unable to spot more uncertainties
-
[19]
Uncertainties might be different from errors. For example, uncertainties may arise from ambiguities in the question, or from the application of a particular lemma/proof
-
[20]
If there are alternate potential approaches that may lead to different answers, you should mention them
-
[21]
List out plausible uncertainties, do not make generic statements, be as specific about uncertainties as possible
-
[22]
Enclose this uncertainty analysis within <analysis> </analysis> tags. The final format that must be followed is : <think> reasoning process here </think> <answer> final answer here</analysis> <analysis> analysis about confidence and uncertainty here </analysis> <confidence> confidence level here (number between 0 and 1) </confidence> ) Simple RLCR Prompt ...
-
[23]
The user asks a question, and the Assistant solves it
</confidence> 20 Simple Confidence Prompt A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and analyzes its confidence about the solution and then provides the user with the final answer as well as its confidence level. The confidence level ...
-
[24]
Your analysis should also be in ’I’ form as if you wrote the solution and are now verifying it
-
[25]
Your goal is not to solve the problem but instead to verify if the steps in the presented solution are correct
-
[26]
If there are ambiguities in the solution steps or if a step introduces uncertainty, you should mention it in the analysis
-
[27]
Go through the solution sequentially in a step-by-step manner
-
[28]
The analysis should be 300 characters minimum
-
[29]
21 D R ESULTS D.1 M ODELS TRAINED ON HOTPOT QA Method SimpleQA Trivia Acc
Enclose this uncertainty analysis within <analysis> </analysis> tags. 21 D R ESULTS D.1 M ODELS TRAINED ON HOTPOT QA Method SimpleQA Trivia Acc. AUROC Brier ECE Acc. AUROC Brier ECE Base 13.5% 0.502 0.773 0.809 57.8% 0.510 0.381 0.371 RLVR 12.4% 0.501 0.875 0.875 62.2% 0.502 0.377 0.377 RLVR +Classifier 12.4% 0.477 0.531 0.638 62.2% 0.567 0.256 0.151 RLVR...
work page 2018
-
[30]
**Total movies watched by each individual:** - Dalton: 15 movies - Hunter: 19 movies - Alex: 25 movies - Bella: 21 movies - Chris: 11 movies
-
[31]
**Movies watched together:** They all watched 5 movies together
-
[32]
- Bella and Chris watched 2 more movies only with each other
**Movies watched exclusively among themselves:** - Dalton, Hunter, and Alex watched an additional 3 movies only among themselves. - Bella and Chris watched 2 more movies only with each other
-
[33]
**Calculating the total number of movies watched:** - First, sum the total movies watched by each individual: 15 + 19 + 25 + 21 + 11 = 91 - Subtract the movies watched together (since they are counted multiple times in the individual totals): 91 − 5 = 86 - Add back the movies watched together (they should only be counted once): 86 + 5 = 91 - Subtract the ...
-
[34]
**Final calculation:** The total number of different movies they saw is the sum of all individual movies watched, minus the movies watched together (to avoid double-counting), plus the movies watched together again (to include them once), and no further adjustments are needed for the exclusive movies: 91 − 5 + 5 = 91 Thus, the total number of different mo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.