Depth-Breadth Synergy in RLVR: Unlocking LLM Reasoning Gains with Adaptive Exploration
Pith reviewed 2026-05-18 22:29 UTC · model grok-4.3
The pith
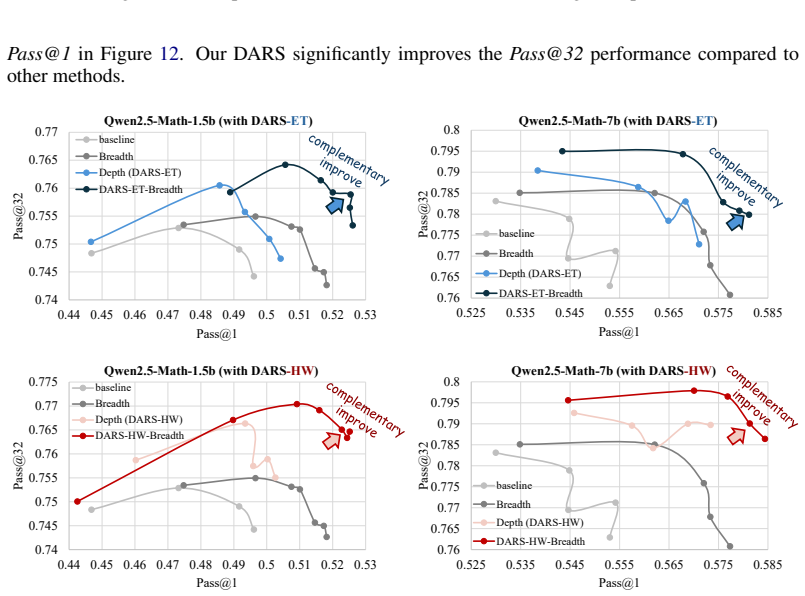
DARS rebalances RLVR rollouts toward difficult problems to raise Pass@K while batch scaling lifts Pass@1 via entropy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DARS applies targeted multi-stage rollouts to re-weight difficult low-accuracy problems according to re-balancing schedules, increasing their rollout outcomes and delivering consistent gains in Pass@K. Scaling batch size for greater breadth improves Pass@1 through higher token-level entropy that ensures robust exploration and lower gradient noise. The combined DARS-Breadth approach achieves simultaneous gains in both metrics, establishing that depth via adaptive exploration and breadth via scaled iteration instances are orthogonal and complementary dimensions.
What carries the argument
Difficulty Adaptive Rollout Sampling (DARS), which uses multi-stage re-balancing schedules to adapt the number of rollout outcomes based on problem difficulty and accuracy.
If this is right
- DARS produces consistent Pass@K gains by increasing rollout outcomes for harder problems.
- Scaling batch size improves Pass@1 by raising token-level entropy and reducing gradient noise.
- DARS-Breadth achieves simultaneous gains in both Pass@K and Pass@1.
- Depth through adaptive exploration and breadth through scaled instances function as orthogonal and complementary levers.
Where Pith is reading between the lines
- The re-balancing idea could transfer to other RL algorithms that share similar accuracy-based weighting biases.
- Practitioners might combine DARS with larger batches to improve reasoning performance without extra hyperparameter search.
- The synergy may extend to non-verifiable reward settings if the underlying bias in problem weighting persists.
- Testing the method on progressively harder reasoning benchmarks would clarify how far the depth-breadth gains scale.
Load-bearing premise
GRPO has a bias that systematically down-weights difficult low-accuracy problems, and DARS corrects this bias effectively without introducing new selection effects or requiring problem-specific tuning.
What would settle it
An experiment in which DARS produces no increase in effective rollout weight or Pass@K on hard problems, or in which larger batches fail to raise token-level entropy or Pass@1.
Figures













read the original abstract
Reinforcement Learning with Verifiable Reward (RLVR) is a powerful method for enhancing the reasoning abilities of Large Language Models, but its full potential is limited by a lack of exploration in two key areas: Depth (the difficulty of problems) and Breadth (the number of training instances). Our analysis of the popular GRPO algorithm reveals a bias that down-weights difficult, low-accuracy problems, which are crucial for improving reasoning skills. To address this, we introduce Difficulty Adaptive Rollout Sampling (DARS), a method that re-weights difficult problems by using targeted, multi-stage rollouts. DARS increases the number of rollout outcomes for these harder problems according to our proposed re-balancing schedules and leads to consistent gains in Pass@K. We discovered that increasing rollout size alone does not improve performance and may actually impair it. In contrast, scaling the batch size to increase breadth via full-batch updates significantly boosted Pass@1 metrics. This improvement stems from higher token-level entropy, ensuring robust exploration and minimized gradient noise. We further present DARS-Breadth, a combined approach that uses DARS with a large breadth of training data. This method demonstrates simultaneous gains in both Pass@K and Pass@1, confirming that depth (adaptive exploration) and breadth (scaling iteration instances) are orthogonal and complementary dimensions for unlocking the full power of RLVR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes a bias in the GRPO algorithm for Reinforcement Learning with Verifiable Reward (RLVR) that down-weights difficult, low-accuracy problems. It introduces Difficulty Adaptive Rollout Sampling (DARS) using multi-stage re-balancing schedules to increase rollouts on harder problems, reporting consistent gains in Pass@K. The work further shows that scaling batch size (breadth) improves Pass@1 via higher token-level entropy, while simply increasing rollout size does not, and presents DARS-Breadth as a combined method yielding simultaneous gains in both metrics, concluding that depth and breadth are orthogonal and complementary for RLVR.
Significance. If the empirical results are robust and reproducible, the paper offers a practical approach to improving exploration in RLVR by separately targeting problem difficulty (depth) and training instance volume (breadth). The finding that batch-size scaling boosts entropy and performance more effectively than rollout scaling, along with the orthogonality claim for DARS-Breadth, could inform more efficient training of reasoning LLMs. The explicit re-balancing schedules and focus on verifiable rewards represent a concrete algorithmic contribution in an active area.
major comments (2)
- [Abstract] Abstract: The central claim that DARS corrects GRPO's bias against difficult low-accuracy problems and yields consistent Pass@K gains is stated qualitatively, but the abstract supplies no quantitative results, specific baselines, effect sizes, or statistical details. This makes it impossible to evaluate whether the re-balancing schedules actually mitigate the bias without introducing new selection effects or requiring problem-specific tuning, as required by the weakest assumption.
- [Abstract] The claim that depth (DARS) and breadth (batch scaling) are orthogonal and complementary, confirmed by simultaneous gains in DARS-Breadth, rests on the assumption that total compute and rollout budget are controlled. Without explicit ablation on matched compute budgets or rollout counts across conditions, it remains unclear whether the observed gains are confounded by increased total sampling rather than true orthogonality.
minor comments (1)
- [Abstract] The abstract refers to 'our proposed re-balancing schedules' and 'full-batch updates' without defining the exact functional form or hyperparameters of the schedules, which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. Below we respond point-by-point to the major comments and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that DARS corrects GRPO's bias against difficult low-accuracy problems and yields consistent Pass@K gains is stated qualitatively, but the abstract supplies no quantitative results, specific baselines, effect sizes, or statistical details. This makes it impossible to evaluate whether the re-balancing schedules actually mitigate the bias without introducing new selection effects or requiring problem-specific tuning, as required by the weakest assumption.
Authors: We agree that the abstract would be strengthened by quantitative details. In the revision we will add concise quantitative statements (e.g., relative Pass@K gains and the GRPO baseline) while preserving brevity. The re-balancing schedules are defined from aggregate accuracy statistics rather than per-problem tuning; we will add a short clarification in Section 3 to make this explicit and rule out unintended selection effects. revision: yes
-
Referee: [Abstract] The claim that depth (DARS) and breadth (batch scaling) are orthogonal and complementary, confirmed by simultaneous gains in DARS-Breadth, rests on the assumption that total compute and rollout budget are controlled. Without explicit ablation on matched compute budgets or rollout counts across conditions, it remains unclear whether the observed gains are confounded by increased total sampling rather than true orthogonality.
Authors: We controlled total rollout count by adjusting the number of optimization steps when batch size or rollout depth was increased, but we acknowledge that an explicit matched-budget ablation was not presented. We will add a new table and accompanying text in the experiments section that reports all three conditions (DARS, breadth scaling, DARS-Breadth) under identical total sampling budgets, confirming that the joint gains remain after budget equalization. revision: yes
Circularity Check
No significant circularity; empirical algorithmic proposal with independent experimental validation
full rationale
The paper's core contribution is an empirical analysis of GRPO training dynamics revealing a bias against difficult problems, followed by the introduction of DARS re-balancing schedules and DARS-Breadth variants. These are validated through Pass@K and Pass@1 metrics on rollout experiments, with claims about orthogonality of depth and breadth dimensions supported by observed entropy and gradient effects. No equations or first-principles derivations are presented that reduce results to fitted parameters, self-definitions, or self-citation chains; the method is an algorithmic adjustment grounded in observed data rather than a closed mathematical loop. The derivation chain remains self-contained as standard empirical RL research.
Axiom & Free-Parameter Ledger
free parameters (1)
- re-balancing schedules
axioms (1)
- domain assumption The GRPO algorithm exhibits a bias that down-weights difficult, low-accuracy problems
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We dissect the popular GRPO algorithm and reveal a systematic bias: the cumulative-advantage disproportionately weights samples with medium accuracy, while down-weighting the low-accuracy instances... DARS performs a lightweight first-stage rollout... rebalancing schedules ET/HW
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
large-breadth training sustains high token-level entropy... depth and breadth are orthogonal and complementary dimensions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 8 Pith papers
-
CuSearch: Curriculum Rollout Sampling via Search Depth for Agentic RAG
CuSearch reallocates rollout budget in RLVR toward deeper-search trajectories as a proxy for retrieval supervision density, yielding up to 11.8 exact-match gains over uniform GRPO sampling on ZeroSearch.
-
Rethinking Importance Sampling in LLM Policy Optimization: A Cumulative Token Perspective
The cumulative token IS ratio gives unbiased prefix correction and lower variance than full-sequence ratios for token-level gradients in LLM policy optimization, enabling CTPO to outperform GRPO and GSPO baselines on ...
-
ResRL: Boosting LLM Reasoning via Negative Sample Projection Residual Reinforcement Learning
ResRL decouples shared semantics between positive and negative responses in LLM reinforcement learning via SVD-based projection residuals, outperforming baselines including NSR by up to 9.4% on math reasoning benchmarks.
-
Low-rank Optimization Trajectories Modeling for LLM RLVR Acceleration
NExt accelerates RLVR training for LLMs by nonlinearly extrapolating low-rank parameter trajectories extracted from LoRA runs.
-
ResRL: Boosting LLM Reasoning via Negative Sample Projection Residual Reinforcement Learning
ResRL boosts LLM reasoning by modulating negative gradients with SVD-based projection residuals from negative samples, outperforming NSR by 9.4% Avg@16 on math benchmarks while preserving diversity across 12 tasks.
-
WebGen-R1: Incentivizing Large Language Models to Generate Functional and Aesthetic Websites with Reinforcement Learning
WebGen-R1 uses end-to-end RL with scaffold-driven generation and cascaded rewards for structure, function, and aesthetics to transform a 7B model into a generator of deployable multi-page websites that rivals much lar...
-
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
Survey that defines agentic RL for LLMs via POMDPs, introduces a taxonomy of planning/tool-use/memory/reasoning capabilities and domains, and compiles open environments from over 500 papers.
-
CuSearch: Curriculum Rollout Sampling via Search Depth for Agentic RAG
CuSearch reallocates fixed training budget toward deeper-search rollouts in RLVR for agentic RAG, treating search depth as an annotation-free proxy for supervision density and reporting up to 11.8 exact-match gains ov...
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Ale- man, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Anna Goldie, Azalia Mirhoseini, Hao Zhou, Irene Cai, and Christopher D
URLhttps://deepmind.google/ technologies/gemini/flash-thinking/. Yuqian Fu, Tinghong Chen, Jiajun Chai, Xihuai Wang, Songjun Tu, Guojun Yin, Wei Lin, Qichao Zhang, Yuanheng Zhu, and Dongbin Zhao. Srft: A single-stage method with supervised and reinforcement fine-tuning for reasoning.arXiv preprint arXiv:2506.19767,
-
[3]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Association for Computational Linguis- tics. doi: 10.18653/v1/2024.acl-long.211. URLhttps://aclanthology.org/2024. acl-long.211/. Hugging Face. Open r1: A fully open reproduction of deepseek-r1, January
-
[6]
URLhttps: //github.com/huggingface/open-r1. Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
From System 1 to System 2: A Survey of Reasoning Large Language Models
URLhttps://proceedings.neurips.cc/paper_files/paper/ 2022/file/18abbeef8cfe9203fdf9053c9c4fe191-Paper-Conference.pdf. Zhong-Zhi Li, Duzhen Zhang, Ming-Liang Zhang, Jiaxin Zhang, Zengyan Liu, Yuxuan Yao, Haotian Xu, Junhao Zheng, Pei-Jie Wang, Xiuyi Chen, et al. From system 1 to system 2: A survey of reasoning large language models.arXiv preprint arXiv:2502.17419,
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Xiao Liang, Zhongzhi Li, Yeyun Gong, Yelong Shen, Ying Nian Wu, Zhijiang Guo, and Weizhu Chen. Beyond pass@ 1: Self-play with variational problem synthesis sustains rlvr.arXiv preprint arXiv:2508.14029,
-
[9]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step.arXiv preprint arXiv:2305.20050,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Tianyu Pang, Chao Du, and Min Lin. There may not be aha moment in r1-zero-like training—a pilot study, 2025a. 12 Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025b. Michael Lu...
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Training language models to follow instructions with human feedback
Notion Blog. Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kel- ton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Rethinking reflection in pre- training.arXiv preprint arXiv:2504.04022,
Darsh J Shah, Peter Rushton, Somanshu Singla, Mohit Parmar, Kurt Smith, Yash Vanjani, Ashish Vaswani, Adarsh Chaluvaraju, Andrew Hojel, Andrew Ma, et al. Rethinking reflection in pre- training.arXiv preprint arXiv:2504.04022,
-
[14]
URLhttps://arxiv.org/abs/2402. 03300. Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
URLhttps://arxiv.org/abs/ 2504.14945. An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, and Zhenru Zhang. Qwen2.5-math technical report: Toward mathematical ex- pert model via self-improvement,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
URLhttps://arxiv.org/abs/2409.12122. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guang- ming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, X...
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
URL https://arxiv.org/abs/2503.14476. 13 Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. Does re- inforcement learning really incentivize reasoning capacity in llms beyond the base model?arXiv preprint arXiv:2504.13837, 2025a. Yu Yue, Yufeng Yuan, Qiying Yu, Xiaochen Zuo, Ruofei Zhu, Wenyuan Xu, Jiaze Chen, Chengyi Wang...
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Kakade, Cengiz Pehlevan, Samy Jelassi, and Eran Malach
Rosie Zhao, Alexandru Meterez, Sham Kakade, Cengiz Pehlevan, Samy Jelassi, and Eran Malach. Echo chamber: Rl post-training amplifies behaviors learned in pretraining.arXiv preprint arXiv:2504.07912,
-
[20]
14 APPENDIX A DERIVATION OFADDITIONALROLLOUTS∆n j The cumulative advantage for a group with accuracyˆaj and total rollout sizeN j =N pre + ∆nj is given by: Agroup(ˆaj, Nj) =N j · S(ˆaj), whereS(ˆaj) = 2ˆaj(1−ˆaj). After the first-stage rollout of sizeN pre, the initial cumulative advantage is: AN pre group (ˆaj) =N pre · S(ˆaj). Our goal is to determine t...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.