Ordinal Adaptive Correction: A Data-Centric Approach to Ordinal Image Classification with Noisy Labels
Pith reviewed 2026-05-21 23:14 UTC · model grok-4.3
The pith
Dynamically adjusting per-sample label distributions corrects noise in ordinal image classification
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that adaptive correction of label distributions, achieved by updating their mean and standard deviation for individual samples throughout training, identifies and fixes noisy ordinal labels, allowing models to achieve higher accuracy and robustness without discarding any training data.
What carries the argument
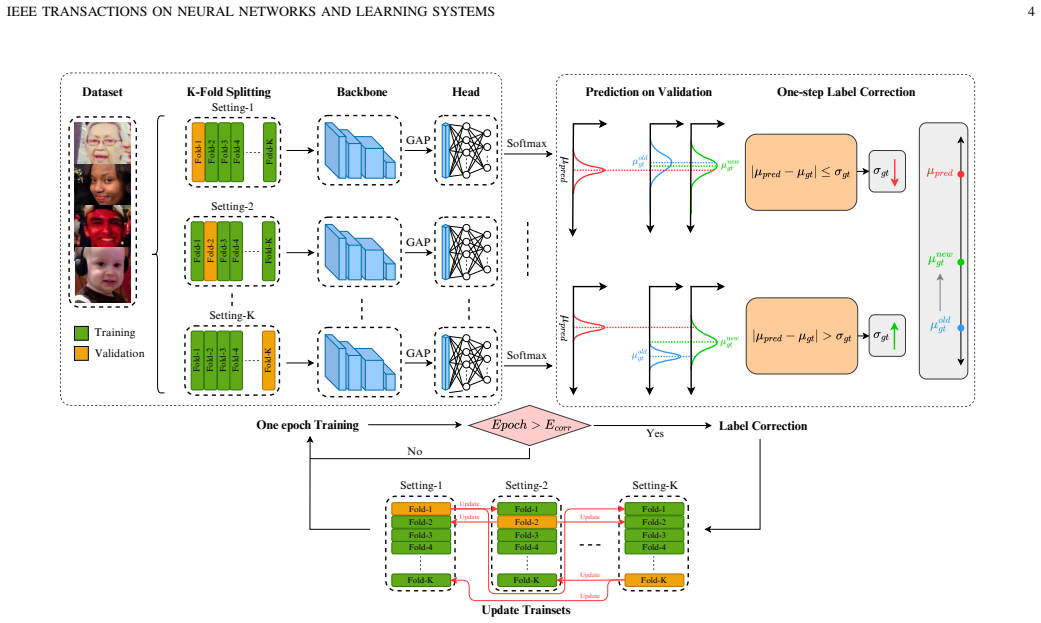
ORDAC, the ordinal adaptive correction procedure that models labels as distributions and tunes their per-sample mean and standard deviation to separate and repair noise.
If this is right
- The full training set can be used effectively even when a large fraction of ordinal labels contain errors.
- Mean absolute error drops substantially on noisy versions of age estimation benchmarks.
- Recall rises on disease severity grading tasks after label corrections are applied.
- The same adjustments also mitigate intrinsic noise already present in real-world datasets.
Where Pith is reading between the lines
- The adjustment mechanism may transfer to other ordered classification settings such as medical staging or quality assessment.
- Pairing the dynamic updates with different base architectures could reveal whether the gains depend on the underlying model.
- Testing the approach on noise patterns other than asymmetric Gaussian would clarify its scope.
Load-bearing premise
Dynamically adjusting the mean and standard deviation of per-sample label distributions can reliably identify and correct noise without the adjustments being driven by or reinforcing the underlying errors.
What would settle it
Apply the method to a dataset where clean ground-truth labels are known, introduce controlled noise, run training, and measure whether the final corrected distributions or predictions match the true labels more closely than a baseline model trained without the adjustments.
Figures



read the original abstract
Labeled data is a fundamental component in training supervised deep learning models for computer vision tasks. However, the labeling process, especially for ordinal image classification where class boundaries are often ambiguous, is prone to error and noise. Such label noise can significantly degrade the performance and reliability of machine learning models. This paper addresses the problem of detecting and correcting label noise in ordinal image classification tasks. To this end, a novel data-centric method called ORDinal Adaptive Correction (ORDAC) is proposed for adaptive correction of noisy labels. The proposed approach leverages the capabilities of Label Distribution Learning (LDL) to model the inherent ambiguity and uncertainty present in ordinal labels. During training, ORDAC dynamically adjusts the mean and standard deviation of the label distribution for each sample. Rather than discarding potentially noisy samples, this approach aims to correct them and make optimal use of the entire training dataset. The effectiveness of the proposed method is evaluated on benchmark datasets for age estimation (Adience) and disease severity detection (Diabetic Retinopathy) under various asymmetric Gaussian noise scenarios. Results show that ORDAC and its extended versions (ORDAC_C and ORDAC_R) lead to significant improvements in model performance. For instance, on the Adience dataset with 40% noise, ORDAC_R reduced the mean absolute error from 0.86 to 0.62 and increased the recall metric from 0.37 to 0.49. The method also demonstrated its effectiveness in correcting intrinsic noise present in the original datasets. This research indicates that adaptive label correction using label distributions is an effective strategy to enhance the robustness and accuracy of ordinal classification models in the presence of noisy data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Ordinal Adaptive Correction (ORDAC), a data-centric approach for noisy label correction in ordinal image classification. It employs Label Distribution Learning (LDL) to model label ambiguity and dynamically adjusts the mean and standard deviation of per-sample label distributions during training to correct rather than discard noisy samples. The method and its extensions (ORDAC_C, ORDAC_R) are evaluated on Adience (age estimation) and Diabetic Retinopathy (disease severity) datasets under asymmetric Gaussian noise, with reported gains such as MAE dropping from 0.86 to 0.62 and recall rising from 0.37 to 0.49 on Adience at 40% noise. The central claim is that adaptive label correction via label distributions enhances robustness and accuracy for ordinal tasks with noisy data.
Significance. If validated, the work could provide a practical data-centric strategy for improving ordinal classification robustness without data discarding, relevant to applications with inherent label ambiguity like medical imaging and age estimation. It builds on LDL to handle ordinal noise adaptively. However, significance is currently limited by insufficient experimental detail and unresolved questions about whether the online adjustments truly separate noise or risk feedback from early errors on the noisy labels.
major comments (3)
- [Section 3 (Proposed Method)] Section 3 (Proposed Method): The dynamic adjustment of per-sample mean and standard deviation for label distributions is presented at a conceptual level without explicit equations, update rules, or pseudocode. This leaves open whether the adjustments are driven by the model's predictions on the original noisy labels, potentially creating a self-reinforcing loop that amplifies rather than corrects boundary errors, directly challenging the claim of reliable noise separation.
- [Section 4 (Experiments)] Section 4 (Experiments): Concrete metric improvements are reported (e.g., Adience 40% noise case), yet the manuscript provides no details on baseline implementations, statistical testing, ablation studies isolating the mean/std adjustment, or the full experimental protocol including noise injection procedure and hyperparameter settings. This absence prevents verification of the results and assessment of whether gains are robust or protocol-dependent.
- [Abstract and Section 4] Abstract and Section 4: Extended variants ORDAC_C and ORDAC_R are introduced and evaluated without clear motivation relative to the core ORDAC or dedicated ablations, making it unclear how they contribute to or extend the primary claim and complicating interpretation of the main method's effectiveness.
minor comments (2)
- [Section 2 and 3] Notation for label distributions and their parameters should be defined explicitly with equations at first use to improve clarity for readers unfamiliar with LDL variants.
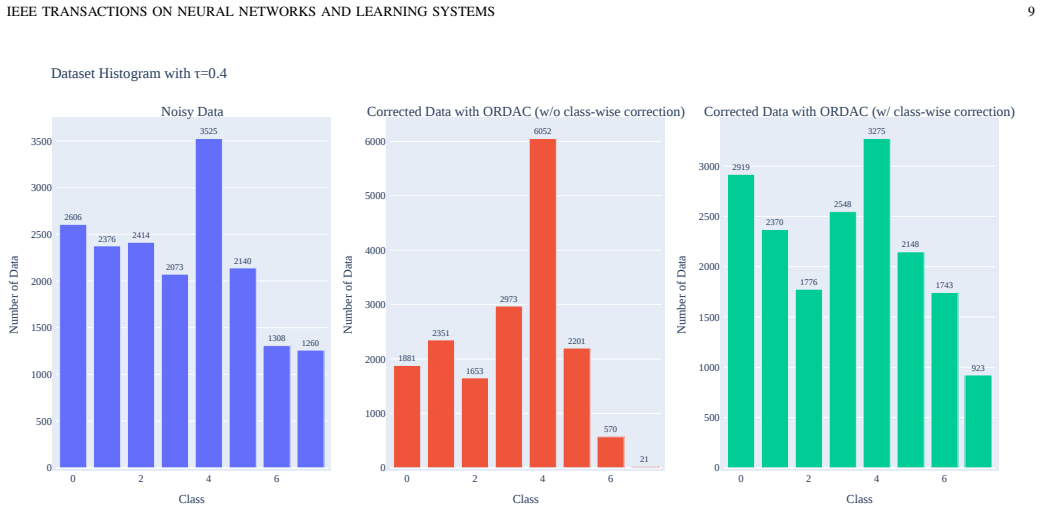
- [Figures and Tables in Section 4] Figure captions and table legends could more explicitly state the noise levels and metrics to facilitate quick comparison across experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have carefully addressed each major comment below and will incorporate revisions to improve clarity, reproducibility, and motivation in the next version of the paper.
read point-by-point responses
-
Referee: [Section 3 (Proposed Method)] Section 3 (Proposed Method): The dynamic adjustment of per-sample mean and standard deviation for label distributions is presented at a conceptual level without explicit equations, update rules, or pseudocode. This leaves open whether the adjustments are driven by the model's predictions on the original noisy labels, potentially creating a self-reinforcing loop that amplifies rather than corrects boundary errors, directly challenging the claim of reliable noise separation.
Authors: We agree that Section 3 would benefit from greater mathematical precision. In the revised manuscript we will add the explicit update equations for the per-sample mean and standard deviation, the full algorithmic pseudocode, and a step-by-step description of how the adjustments are computed. The updates are indeed informed by the current model predictions, but they are performed inside the Label Distribution Learning objective and are regularized by an ordinal-aware consistency term that penalizes large deviations from the original label distribution; this mechanism is intended to prevent runaway feedback. We will also include a short stability analysis (training curves of the adjustment magnitude) to demonstrate that early errors do not propagate uncontrollably. These additions directly respond to the concern about reliable noise separation. revision: yes
-
Referee: [Section 4 (Experiments)] Section 4 (Experiments): Concrete metric improvements are reported (e.g., Adience 40% noise case), yet the manuscript provides no details on baseline implementations, statistical testing, ablation studies isolating the mean/std adjustment, or the full experimental protocol including noise injection procedure and hyperparameter settings. This absence prevents verification of the results and assessment of whether gains are robust or protocol-dependent.
Authors: We acknowledge that the current experimental section lacks the necessary detail for independent verification. In the revision we will expand Section 4 with: (i) precise descriptions and code references for all baselines, (ii) statistical significance tests (paired t-tests across multiple runs), (iii) dedicated ablation tables that isolate the contribution of the dynamic mean/std adjustment, (iv) the exact asymmetric Gaussian noise injection procedure (including the per-class variance schedule), and (v) the complete hyperparameter table and training protocol. These additions will allow readers to reproduce the reported improvements (e.g., MAE reduction from 0.86 to 0.62 on Adience at 40 % noise) and assess their robustness. revision: yes
-
Referee: [Abstract and Section 4] Abstract and Section 4: Extended variants ORDAC_C and ORDAC_R are introduced and evaluated without clear motivation relative to the core ORDAC or dedicated ablations, making it unclear how they contribute to or extend the primary claim and complicating interpretation of the main method's effectiveness.
Authors: We accept that the motivation and incremental value of ORDAC_C and ORDAC_R were not sufficiently articulated. In the revised manuscript we will (a) add a concise paragraph in the abstract and at the beginning of Section 4 explaining the design rationale for each variant (conservative correction for ORDAC_C and robust regularization for ORDAC_R), and (b) include a dedicated ablation subsection that compares all three methods head-to-head on the same noise settings. These changes will clarify how the variants extend the core ORDAC claim while preserving focus on the primary adaptive-correction approach. revision: yes
Circularity Check
No significant circularity: empirical training procedure with held-out evaluation
full rationale
The paper presents ORDAC as a practical, data-centric training algorithm that uses LDL to dynamically adjust per-sample label distribution mean and standard deviation on noisy ordinal data, with performance measured on held-out test sets after controlled noise injection on Adience and Diabetic Retinopathy. No mathematical derivation chain, closed-form predictions, or first-principles results are claimed that reduce by construction to fitted inputs or self-citations. The central claims rest on experimental outcomes rather than equations that equate outputs to the method's own adjustments, satisfying the self-contained criterion for an empirical method.
Axiom & Free-Parameter Ledger
free parameters (1)
- per-sample mean and standard deviation adjustment rules
axioms (1)
- domain assumption Label distributions effectively model the inherent ambiguity and uncertainty in ordinal labels
Reference graph
Works this paper leans on
-
[1]
“everyone wants to do the model work, not the data work
N. Sambasivan, S. Kapania, H. Highfill, D. Akrong, P. Paritosh, and L. M. Aroyo, ““everyone wants to do the model work, not the data work”: Data cascades in high-stakes ai,” in proceedings of the 2021 CHI Conference on Human Factors in Computing Systems , pp. 1–15, 2021
work page 2021
-
[2]
Imagenet large scale visual recognition challenge,
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al., “Imagenet large scale visual recognition challenge,” International journal of computer vision, vol. 115, pp. 211–252, 2015
work page 2015
-
[3]
F. R. Cordeiro and G. Carneiro, “A survey on deep learning with noisy labels: How to train your model when you cannot trust on the annotations?,” in 2020 33rd SIBGRAPI conference on graphics, patterns and images (SIBGRAPI) , pp. 9–16, IEEE, 2020
work page 2020
-
[4]
Learning multiple layers of features from tiny images,
A. Krizhevsky, G. Hinton, et al., “Learning multiple layers of features from tiny images,” 2009
work page 2009
-
[5]
The mnist database of handwritten digit images for machine learning research [best of the web],
L. Deng, “The mnist database of handwritten digit images for machine learning research [best of the web],” IEEE signal processing magazine , vol. 29, no. 6, pp. 141–142, 2012
work page 2012
-
[6]
Learning from noisy labels with deep neural networks: A survey,
H. Song, M. Kim, D. Park, Y . Shin, and J.-G. Lee, “Learning from noisy labels with deep neural networks: A survey,” IEEE transactions on neural networks and learning systems , vol. 34, no. 11, pp. 8135– 8153, 2022
work page 2022
-
[7]
Cassor: Class-aware sample selection for ordinal regression with noisy labels,
Y . Yuan, S. Wan, C. Zhang, and C. Gong, “Cassor: Class-aware sample selection for ordinal regression with noisy labels,” in Pacific Rim International Conference on Artificial Intelligence , pp. 117–123, Springer, 2023
work page 2023
-
[8]
Noise cleaning for nonuniform ordinal labels based on inter-class distance,
G. Jiang, F. Wang, and W. Wang, “Noise cleaning for nonuniform ordinal labels based on inter-class distance,” Applied Intelligence , vol. 54, no. 11, pp. 6997–7011, 2024
work page 2024
-
[9]
X. Geng, “Label distribution learning,” IEEE Transactions on Knowl- edge and Data Engineering , vol. 28, no. 7, pp. 1734–1748, 2016
work page 2016
-
[10]
Data-centric ai: Perspectives and challenges,
D. Zha, Z. P. Bhat, K.-H. Lai, F. Yang, and X. Hu, “Data-centric ai: Perspectives and challenges,” in Proceedings of the 2023 SIAM international conference on data mining (SDM) , pp. 945–948, SIAM, 2023
work page 2023
-
[11]
Generalized cross entropy loss for training deep neural networks with noisy labels,
Z. Zhang and M. Sabuncu, “Generalized cross entropy loss for training deep neural networks with noisy labels,” Advances in neural information processing systems, vol. 31, 2018
work page 2018
-
[12]
mixup: Beyond Empirical Risk Minimization
H. Zhang, M. Cisse, Y . N. Dauphin, and D. Lopez-Paz, “mixup: Beyond empirical risk minimization,” arXiv preprint arXiv:1710.09412 , 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[13]
Co-teaching: Robust training of deep neural networks with extremely noisy labels,
B. Han, Q. Yao, X. Yu, G. Niu, M. Xu, W. Hu, I. Tsang, and M. Sugiyama, “Co-teaching: Robust training of deep neural networks with extremely noisy labels,” Advances in neural information processing systems, vol. 31, 2018
work page 2018
-
[14]
Mentornet: Learning data-driven curriculum for very deep neural networks on corrupted labels,
L. Jiang, Z. Zhou, T. Leung, L.-J. Li, and L. Fei-Fei, “Mentornet: Learning data-driven curriculum for very deep neural networks on corrupted labels,” in International conference on machine learning , pp. 2304–2313, PMLR, 2018
work page 2018
-
[15]
Confident learning: Estimating uncertainty in dataset labels,
C. Northcutt, L. Jiang, and I. Chuang, “Confident learning: Estimating uncertainty in dataset labels,” Journal of Artificial Intelligence Research, vol. 70, pp. 1373–1411, 2021
work page 2021
-
[16]
Model-agnostic label quality scoring to detect real-world label errors,
J. Kuan and J. Mueller, “Model-agnostic label quality scoring to detect real-world label errors,” in ICML DataPerf Workshop, 2022
work page 2022
-
[17]
Dataset cartography: Mapping and diagnosing datasets with training dynamics
S. Swayamdipta, R. Schwartz, N. Lourie, Y . Wang, H. Hajishirzi, N. A. Smith, and Y . Choi, “Dataset cartography: Mapping and diagnosing datasets with training dynamics,” arXiv preprint arXiv:2009.10795 , 2020
-
[18]
Objectlab: Automated diagnosis of mislabeled images in object detection data,
U. Tkachenko, A. Thyagarajan, and J. Mueller, “Objectlab: Automated diagnosis of mislabeled images in object detection data,” arXiv preprint arXiv:2309.00832, 2023. IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS 10
-
[19]
Estimating label quality and errors in semantic segmentation data via any model,
V . Lad and J. Mueller, “Estimating label quality and errors in semantic segmentation data via any model,” arXiv preprint arXiv:2307.05080 , 2023
-
[20]
Meta label correction for noisy label learning,
G. Zheng, A. H. Awadallah, and S. Dumais, “Meta label correction for noisy label learning,” in Proceedings of the AAAI conference on artificial intelligence, vol. 35, pp. 11053–11061, 2021
work page 2021
-
[21]
Dualgraph: A graph-based method for reasoning about label noise,
H. Zhang, X. Xing, and L. Liu, “Dualgraph: A graph-based method for reasoning about label noise,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pp. 9654–9663, 2021
work page 2021
-
[22]
Ordinal regression methods: survey and experimental study,
P. A. Guti ´errez, M. Perez-Ortiz, J. Sanchez-Monedero, F. Fernandez- Navarro, and C. Hervas-Martinez, “Ordinal regression methods: survey and experimental study,” IEEE Transactions on Knowledge and Data Engineering, vol. 28, no. 1, pp. 127–146, 2015
work page 2015
-
[23]
Ordinal regression with multiple output cnn for age estimation,
Z. Niu, M. Zhou, L. Wang, X. Gao, and G. Hua, “Ordinal regression with multiple output cnn for age estimation,” in Proceedings of the IEEE conference on computer vision and pattern recognition , pp. 4920–4928, 2016
work page 2016
-
[24]
Rank consistent ordinal regres- sion for neural networks with application to age estimation,
W. Cao, V . Mirjalili, and S. Raschka, “Rank consistent ordinal regres- sion for neural networks with application to age estimation,” Pattern Recognition Letters, vol. 140, pp. 325–331, 2020
work page 2020
-
[25]
Deep neural networks for rank- consistent ordinal regression based on conditional probabilities,
X. Shi, W. Cao, and S. Raschka, “Deep neural networks for rank- consistent ordinal regression based on conditional probabilities,” Pattern Analysis and Applications , vol. 26, no. 3, pp. 941–955, 2023
work page 2023
-
[26]
Cumulative link models for deep ordinal classification,
V . M. Vargas, P. A. Guti ´errez, and C. Hervas-Martinez, “Cumulative link models for deep ordinal classification,” Neurocomputing, vol. 401, pp. 48–58, 2020
work page 2020
-
[27]
Support vector learning for ordinal regression,
R. Herbrich, T. Graepel, and K. Obermayer, “Support vector learning for ordinal regression,” in 1999 Ninth International Conference on Artificial Neural Networks ICANN 99.(Conf. Publ. No. 470) , vol. 1, pp. 97–102, IET, 1999
work page 1999
-
[28]
Weighted kappa loss function for multi-class classification of ordinal data in deep learning,
J. de La Torre, D. Puig, and A. Valls, “Weighted kappa loss function for multi-class classification of ordinal data in deep learning,” Pattern Recognition Letters, vol. 105, pp. 144–154, 2018
work page 2018
-
[29]
Unimodal-concentrated loss: Fully adaptive label distribution learning for ordinal regression,
Q. Li, J. Wang, Z. Yao, Y . Li, P. Yang, J. Yan, C. Wang, and S. Pu, “Unimodal-concentrated loss: Fully adaptive label distribution learning for ordinal regression,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. 20513–20522, 2022
work page 2022
-
[30]
Age estimation using expectation of label distribution learning.,
B.-B. Gao, H.-Y . Zhou, J. Wu, and X. Geng, “Age estimation using expectation of label distribution learning.,” in IJCAI, vol. 1, p. 3, 2018
work page 2018
-
[31]
Ordinal label distribution learning,
C. Wen, X. Zhang, X. Yao, and J. Yang, “Ordinal label distribution learning,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 23481–23491, 2023
work page 2023
-
[32]
J. Paplh ´am, V . Franc,et al., “A call to reflect on evaluation practices for age estimation: comparative analysis of the state-of-the-art and a unified benchmark,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. 1196–1205, 2024
work page 2024
-
[33]
Age and gender estimation of unfiltered faces,
E. Eidinger, R. Enbar, and T. Hassner, “Age and gender estimation of unfiltered faces,” IEEE Transactions on information forensics and security, vol. 9, no. 12, pp. 2170–2179, 2014
work page 2014
-
[34]
Diabetic retinopathy de- tection
E. Dugas, Jared, Jorge, and W. Cukierski, “Diabetic retinopathy de- tection.” https://kaggle.com/competitions/diabetic-retinopathy-detection,
-
[35]
Distributed robust support vector ordi- nal regression under label noise,
H. Liu, J. Tu, A. Gao, and C. Li, “Distributed robust support vector ordi- nal regression under label noise,” Neurocomputing, vol. 598, p. 128057, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.