MetaGraph: A Large-Scale Meta-Analysis of GenAI in Financial NLP (2022-2025)
Pith reviewed 2026-05-18 17:38 UTC · model grok-4.3
pith:HSQP5ETK Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{HSQP5ETK}
Prints a linked pith:HSQP5ETK badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
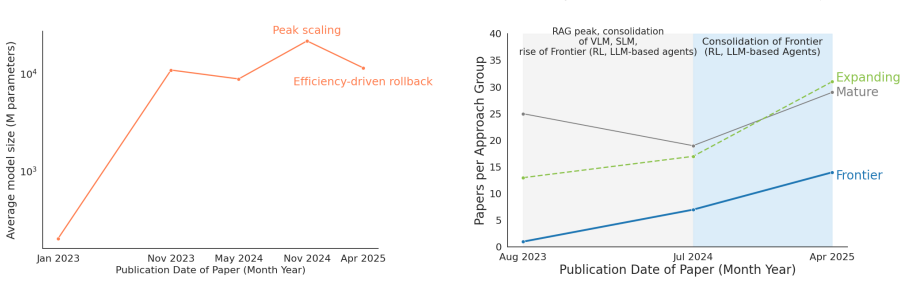
MetaGraph uses ontology-guided LLM extraction to turn 681 papers into a knowledge graph that maps three phases of GenAI development in financial NLP from 2022 to 2025.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MetaGraph is a methodology for extracting typed knowledge graphs from scientific corpora using ontology-guided LLM extraction to enable structured, large-scale trend analysis. Applied to 681 papers on GenAI in Finance (2022-2025), MetaGraph reveals three phases: early LLM-driven expansion of tasks and datasets, growing emphasis on limitations and risk, and a shift toward modular, system-oriented methods (e.g., retrieval-augmented designs).
What carries the argument
Ontology-guided LLM extraction that builds typed knowledge graphs from paper text to support structured meta-analysis of trends and relations.
If this is right
- The field can now be monitored with reproducible, graph-based snapshots instead of ad-hoc narrative surveys.
- Researchers gain access to a released resource of extracted entities and relations for further study.
- Future papers can be added incrementally to track whether the shift toward modular designs continues.
- The three-phase pattern supplies a baseline for comparing GenAI progress in finance against other application domains.
Where Pith is reading between the lines
- The same extraction approach could be applied to other fast-moving technical literatures such as medical AI or robotics to detect comparable phase shifts.
- If the phases prove stable, they might guide funding or regulatory priorities by highlighting when risk discussions overtake capability expansion.
- Periodic re-runs of the pipeline on new papers could create an early-warning system for emerging methodological trends.
Load-bearing premise
The ontology-guided LLM extraction process accurately and consistently identifies the relevant entities, relations, and trends across the 681 papers without substantial errors, omissions, or biases introduced by the model or ontology choices.
What would settle it
Running the same extraction pipeline on the identical 681 papers with a different large language model or a modified ontology that produces markedly different phases or trend patterns would show the method is not reliable.
Figures












read the original abstract
Financial NLP has evolved rapidly since late 2022, outpacing narrative surveys. We introduce MetaGraph, a methodology for extracting typed knowledge graphs from scientific corpora using ontology-guided LLM extraction to enable structured, large-scale trend analysis. Applied to 681 papers on GenAI in Finance (2022-2025), MetaGraph reveals three phases: early LLM-driven expansion of tasks and datasets, growing emphasis on limitations and risk, and a shift toward modular, system-oriented methods (e.g., retrieval-augmented designs). We release the resulting resource and artifacts to support reproducible meta-analysis and future monitoring of the field.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MetaGraph, a methodology for extracting typed knowledge graphs from scientific corpora using ontology-guided LLM extraction to enable structured, large-scale trend analysis. Applied to 681 papers on GenAI in Finance (2022-2025), it reveals three phases: early LLM-driven expansion of tasks and datasets, growing emphasis on limitations and risk, and a shift toward modular, system-oriented methods (e.g., retrieval-augmented designs). The resulting resource and artifacts are released to support reproducible meta-analysis.
Significance. If the extraction process is shown to be reliable, MetaGraph provides a scalable framework for meta-analysis in rapidly evolving fields, moving beyond narrative surveys. The public release of the knowledge graph and artifacts is a clear strength that enables reproducibility and ongoing field monitoring.
major comments (2)
- [Methodology] The central claims about the three observed phases rest on the accuracy of the ontology-guided LLM extraction from the 681 papers. The manuscript provides no quantitative validation of this step, such as precision/recall on a held-out sample, inter-annotator agreement with experts, or error analysis stratified by year (see Methodology section on the extraction pipeline). Without these, it is impossible to rule out systematic biases from the LLM or ontology choices influencing the reported trends.
- [Results] The derivation of the three phases from the extracted graph lacks detail on the quantitative process used (e.g., how changes in entity/relation frequencies or modular method mentions were aggregated over time to identify phase boundaries). This makes the narrative in the Results section difficult to assess for robustness.
minor comments (2)
- [Abstract] The abstract would benefit from briefly noting the corpus size (681 papers) and the public release of the resource to better convey the work's scope.
- [Figures] Figure captions for the knowledge graph visualizations should include more detail on node/edge types and temporal encoding to improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our work. We address the major comments point-by-point below, indicating the revisions we plan to make to improve the manuscript's methodological transparency and robustness.
read point-by-point responses
-
Referee: [Methodology] The central claims about the three observed phases rest on the accuracy of the ontology-guided LLM extraction from the 681 papers. The manuscript provides no quantitative validation of this step, such as precision/recall on a held-out sample, inter-annotator agreement with experts, or error analysis stratified by year (see Methodology section on the extraction pipeline). Without these, it is impossible to rule out systematic biases from the LLM or ontology choices influencing the reported trends.
Authors: We agree that demonstrating the reliability of the extraction process is essential to support the validity of the identified phases. While the original submission emphasized the use of a carefully designed ontology to guide the LLM and reduce hallucinations, we did not include quantitative metrics. In the revised manuscript, we will add a dedicated validation subsection. This will report results from a held-out sample of 100 papers where we compute precision and recall by comparing LLM extractions to expert annotations, along with inter-annotator agreement scores. We will also provide a year-stratified error analysis to assess potential temporal biases. These additions will directly address concerns about systematic biases. revision: yes
-
Referee: [Results] The derivation of the three phases from the extracted graph lacks detail on the quantitative process used (e.g., how changes in entity/relation frequencies or modular method mentions were aggregated over time to identify phase boundaries). This makes the narrative in the Results section difficult to assess for robustness.
Authors: We acknowledge that greater detail on the phase identification process would enhance the transparency and allow for better evaluation of the results. The phases were derived by analyzing temporal trends in the frequencies of key entities and relations in the knowledge graph, such as increases in 'limitation' and 'risk' mentions, and the emergence of modular architectures. In the revision, we will expand the Results section to describe the quantitative aggregation method, including the use of time-binned frequency plots, normalization procedures, and the specific criteria (e.g., inflection points in multiple indicators) used to delineate the phase boundaries. Supporting figures and a step-by-step description will be added to facilitate reproducibility. revision: yes
Circularity Check
No significant circularity; trends are outputs from external corpus processing
full rationale
The derivation applies the MetaGraph extraction methodology to an independent corpus of 681 papers and reports the resulting three-phase narrative as an empirical finding. No equations, parameters, or premises reduce by construction to the target trends; the ontology-guided LLM step is a processing tool whose outputs are not presupposed in its definition, and no self-citation or fitted-input patterns are present in the provided description.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An ontology can be defined that comprehensively captures the key concepts, tasks, methods, and risks relevant to GenAI in financial NLP.
Reference graph
Works this paper leans on
-
[1]
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Hamed Babaei Giglou, Jennifer D'Souza, and S \"o ren Auer. 2023. Llms4ol: Large language models for ontology learning. In The Semantic Web -- ISWC 2023, pages 408--427, Cham. Springer Nature Switzerland
work page 2023
-
[4]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, and 29 others. 2023. https://arxiv.org/abs/2309.16609 Qwen technical report . Preprint, arXiv:2309.16609
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Gagan Bhatia, El Moatez Billah Nagoudi, Hasan Cavusoglu, and Muhammad Abdul-Mageed. 2024. https://doi.org/10.18653/v1/2024.findings-acl.774 F in T ral: A family of GPT -4 level multimodal financial large language models . In Findings of the Association for Computational Linguistics: ACL 2024, pages 13064--13087, Bangkok, Thailand. Association for Computat...
- [6]
- [7]
-
[8]
Wei Chen, Qiushi Wang, Zefei Long, Xianyin Zhang, Zhongtian Lu, Bingxuan Li, Siyuan Wang, Jiarong Xu, Xiang Bai, Xuanjing Huang, and Zhongyu Wei. 2023. https://arxiv.org/abs/2310.15205 Disc-finllm: A chinese financial large language model based on multiple experts fine-tuning . Preprint, arXiv:2310.15205
-
[9]
Yuemin Chen, Feifan Wu, Jingwei Wang, Hao Qian, Ziqi Liu, Zhiqiang Zhang, Jun Zhou, and Meng Wang. 2024 b . https://doi.org/10.18653/v1/2024.emnlp-industry.90 Knowledge-augmented financial market analysis and report generation . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 1207--1217, Mia...
-
[10]
Zhiyu Chen, Wenhu Chen, Charese Smiley, Sameena Shah, Iana Borova, Dylan Langdon, Reema Moussa, Matt Beane, Ting-Hao Huang, Bryan Routledge, and William Yang Wang. 2021. https://doi.org/10.18653/v1/2021.emnlp-main.300 F in QA : A dataset of numerical reasoning over financial data . In Proceedings of the 2021 Conference on Empirical Methods in Natural Lang...
-
[11]
Zhiyu Chen, Shiyang Li, Charese Smiley, Zhiqiang Ma, Sameena Shah, and William Yang Wang. 2022. https://doi.org/10.18653/v1/2022.emnlp-main.421 C onv F in QA : Exploring the chain of numerical reasoning in conversational finance question answering . In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 6279--6292...
-
[12]
Nicole Cho, Nishan Srishankar, Lucas Cecchi, and William Watson. 2024. https://doi.org/10.1145/3677052.3698597 Fishnet: Financial intelligence from sub-querying, harmonizing, neural-conditioning, expert swarms, and task planning . In Proceedings of the 5th ACM International Conference on AI in Finance, ICAIF '24, page 591–599, New York, NY, USA. Associati...
-
[13]
Raul Salles de Padua, Imran Qureshi, and Mustafa U. Karakaplan. 2023. https://arxiv.org/abs/2307.13617 Gpt-3 models are few-shot financial reasoners . Preprint, arXiv:2307.13617
-
[14]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, and 181 others. 2025. https://arxiv.org/abs/2501.12948 Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement lea...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [15]
-
[16]
Kelvin Du, Yazhi Zhao, Rui Mao, Frank Xing, and Erik Cambria. 2025. https://doi.org/10.1016/j.inffus.2024.102755 Natural language processing in finance: A survey . Information Fusion, 115:102755
-
[17]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. 2025. https://arxiv.org/abs/2404.16130 From local to global: A graph rag approach to query-focused summarization . Preprint, arXiv:2404.16130
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Sorouralsadat Fatemi and Yuheng Hu. 2024. https://doi.org/10.1145/3677052.3698686 Enhancing financial question answering with a multi-agent reflection framework . In Proceedings of the 5th ACM International Conference on AI in Finance, ICAIF ’24, page 530–537. ACM
-
[19]
George Fatouros, Kostas Metaxas, John Soldatos, and Dimosthenis Kyriazis. 2024. https://doi.org/10.1007/s00521-024-10613-4 Can large language models beat wall street? evaluating gpt-4’s impact on financial decision-making with marketsenseai . Neural Computing and Applications
-
[20]
Maurice Funk, Simon Hosemann, Jean Christoph Jung, and Carsten Lutz. 2023. https://ceur-ws.org/Vol-3577/paper16.pdf Towards ontology construction with language models . In Joint proceedings of the 1st workshop on Knowledge Base Construction from Pre-Trained Language Models (KBC-LM) and the 2nd challenge on Language Models for Knowledge Base Construction (...
work page 2023
-
[21]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Qianyu Guo, Meng Wang, and Haofen Wang. 2023. https://api.semanticscholar.org/CorpusID:266359151 Retrieval-augmented generation for large language models: A survey . ArXiv, abs/2312.10997
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [22]
-
[23]
Yue Guo and Yi Yang. 2024. https://doi.org/10.18653/v1/2024.findings-acl.58 E con NLI : Evaluating large language models on economics reasoning . In Findings of the Association for Computational Linguistics: ACL 2024, pages 982--994, Bangkok, Thailand. Association for Computational Linguistics
- [24]
-
[25]
Pranab Islam, Anand Kannappan, Douwe Kiela, Rebecca Qian, Nino Scherrer, and Bertie Vidgen. 2023. https://arxiv.org/abs/2311.11944 Financebench: A new benchmark for financial question answering . Preprint, arXiv:2311.11944
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Simerjot Kaur, Charese Smiley, Akshat Gupta, Joy Sain, Dongsheng Wang, Suchetha Siddagangappa, Toyin Aguda, and Sameena Shah. 2023. https://doi.org/10.1145/3539618.3591911 Refind: Relation extraction financial dataset . In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR '23, page 3054–...
- [27]
-
[28]
Michael Krumdick, Rik Koncel-Kedziorski, Viet Dac Lai, Varshini Reddy, Charles Lovering, and Chris Tanner. 2024. https://doi.org/10.18653/v1/2024.acl-long.452 B iz B ench: A quantitative reasoning benchmark for business and finance . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8...
- [29]
- [30]
-
[31]
Xiang Li, Zhenyu Li, Chen Shi, Yong Xu, Qing Du, Mingkui Tan, and Jun Huang. 2024 a . https://aclanthology.org/2024.lrec-main.69/ A lpha F in: Benchmarking financial analysis with retrieval-augmented stock-chain framework . In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLIN...
work page 2024
-
[32]
Yinheng Li, Shaofei Wang, Han Ding, and Hang Chen. 2023 b . https://doi.org/10.48550/arXiv.2311.10723 Large language models in finance: A survey . arXiv preprint arXiv:2311.10723. Accepted at the 4th ACM International Conference on AI in Finance (ICAIF-23)
-
[33]
Yuan Li, Bingqiao Luo, Qian Wang, Nuo Chen, Xu Liu, and Bingsheng He. 2024 b . https://doi.org/10.18653/v1/2024.emnlp-main.63 C rypto T rade: A reflective LLM -based agent to guide zero-shot cryptocurrency trading . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1094--1106, Miami, Florida, USA. Association...
- [34]
- [36]
-
[37]
Zhaowei Liu, Xin Guo, Fangqi Lou, Lingfeng Zeng, Jinyi Niu, Zixuan Wang, Jiajie Xu, Weige Cai, Ziwei Yang, Xueqian Zhao, Chao Li, Sheng Xu, Dezhi Chen, Yun Chen, Zuo Bai, and Liwen Zhang. 2025 b . https://arxiv.org/abs/2503.16252 Fin-r1: A large language model for financial reasoning through reinforcement learning . Preprint, arXiv:2503.16252
-
[38]
Zhiwei Liu, Xin Zhang, Kailai Yang, Qianqian Xie, Jimin Huang, and Sophia Ananiadou. 2025 c . https://doi.org/10.1145/3701716.3715599 Fmdllama: Financial misinformation detection based on large language models . In Companion Proceedings of the ACM on Web Conference 2025, WWW '25, page 1153–1157, New York, NY, USA. Association for Computing Machinery
-
[39]
Dakuan Lu, Hengkui Wu, Jiaqing Liang, Yipei Xu, Qianyu He, Yipeng Geng, Mengkun Han, Yingsi Xin, and Yanghua Xiao. 2023. https://arxiv.org/abs/2302.09432 Bbt-fin: Comprehensive construction of chinese financial domain pre-trained language model, corpus and benchmark . Preprint, arXiv:2302.09432
-
[40]
Macedo Maia, Siegfried Handschuh, Andr\' e Freitas, Brian Davis, Ross McDermott, Manel Zarrouk, and Alexandra Balahur. 2018. https://doi.org/10.1145/3184558.3192301 Www'18 open challenge: Financial opinion mining and question answering . In Companion Proceedings of the The Web Conference 2018, WWW '18, page 1941–1942, Republic and Canton of Geneva, CHE. I...
-
[41]
Pekka Malo, Ankur Sinha, Pekka Korhonen, Jyrki Wallenius, and Pyry Takala. 2014. https://doi.org/10.1002/asi.23062 Good debt or bad debt: Detecting semantic orientations in economic texts . Journal of the Association for Information Science and Technology, 65(4):782--796
-
[42]
Yuqi Nie, Yaxuan Kong, Xiaowen Dong, John M. Mulvey, H. Vincent Poor, Qingsong Wen, and Stefan Zohren. 2024. https://arxiv.org/abs/2406.11903 A survey of large language models for financial applications: Progress, prospects and challenges . Preprint, arXiv:2406.11903
-
[43]
Sohini Roychowdhury. 2024. https://doi.org/10.1145/3616855.3635737 Journey of hallucination-minimized generative ai solutions for financial decision makers . In Proceedings of the 17th ACM International Conference on Web Search and Data Mining, WSDM '24, page 1180–1181, New York, NY, USA. Association for Computing Machinery
- [44]
-
[45]
Sander Schulhoff, Michael Ilie, Nishant Balepur, Konstantine Kahadze, Amanda Liu, Chenglei Si, Yinheng Li, Aayush Gupta, HyoJung Han, Sevien Schulhoff, Pranav Sandeep Dulepet, Saurav Vidyadhara, Dayeon Ki, Sweta Agrawal, Chau Pham, Gerson Kroiz, Feileen Li, Hudson Tao, Ashay Srivastava, and 12 others. 2025. https://arxiv.org/abs/2406.06608 The prompt repo...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Raj Shah, Kunal Chawla, Dheeraj Eidnani, Agam Shah, Wendi Du, Sudheer Chava, Natraj Raman, Charese Smiley, Jiaao Chen, and Diyi Yang. 2022. https://doi.org/10.18653/v1/2022.emnlp-main.148 When FLUE meets FLANG : Benchmarks and large pretrained language model for financial domain . In Proceedings of the 2022 Conference on Empirical Methods in Natural Langu...
-
[47]
Jiashuo Sun, Hang Zhang, Chen Lin, Xiangdong Su, Yeyun Gong, and Jian Guo. 2024. https://aclanthology.org/2024.lrec-main.122/ APOLLO : An optimized training approach for long-form numerical reasoning . In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 1370--1...
work page 2024
-
[48]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. https://arxiv.org/abs/2302.13971 Llama: Open and efficient foundation language models . Preprint, arXiv:2302.13971
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
Shijie Wu, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David Rosenberg, and Gideon Mann. 2023. https://arxiv.org/abs/2303.17564 Bloomberggpt: A large language model for finance . Preprint, arXiv:2303.17564
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Kwon, Makoto Onizuka, Shaojie Tang, and Chuan Xiao
Zengqing Wu, Run Peng, Shuyuan Zheng, Qianying Liu, Xu Han, Brian I. Kwon, Makoto Onizuka, Shaojie Tang, and Chuan Xiao. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.297 Shall we team up: Exploring spontaneous cooperation of competing LLM agents . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 5163--5186, Miami, F...
-
[51]
Qianqian Xie, Weiguang Han, Zhengyu Chen, Ruoyu Xiang, Xiao Zhang, Yueru He, Mengxi Xiao, Dong Li, Yongfu Dai, Duanyu Feng, Yijing Xu, Haoqiang Kang, Ziyan Kuang, Chenhan Yuan, Kailai Yang, Zheheng Luo, Tianlin Zhang, Zhiwei Liu, Guojun Xiong, and 15 others. 2024. https://proceedings.neurips.cc/paper_files/paper/2024/file/adb1d9fa8be4576d28703b396b82ba1b-...
work page 2024
- [52]
-
[53]
Qianqian Xie, Weiguang Han, Xiao Zhang, Yanzhao Lai, Min Peng, Alejandro Lopez-Lira, and Jimin Huang. 2023 b . Pixiu: a large language model, instruction data and evaluation benchmark for finance. In Proceedings of the 37th International Conference on Neural Information Processing Systems, NIPS '23, Red Hook, NY, USA. Curran Associates Inc
work page 2023
-
[54]
Frank Z. Xing, Erik Cambria, and Roy E. Welsch. 2018. https://doi.org/10.1007/s10462-017-9588-9 Natural language based financial forecasting: a survey . Artificial Intelligence Review, 50(1):49--73
-
[55]
Siqiao Xue, Fan Zhou, Yi Xu, Ming Jin, Qingsong Wen, Hongyan Hao, Qingyang Dai, Caigao Jiang, Hongyu Zhao, Shuo Xie, Jianshan He, James Zhang, and Hongyuan Mei. 2024. https://arxiv.org/abs/2308.05361 Weaverbird: Empowering financial decision-making with large language model, knowledge base, and search engine . Preprint, arXiv:2308.05361
- [56]
-
[57]
Hongyang Yang, Boyu Zhang, Neng Wang, Cheng Guo, Xiaoli Zhang, Likun Lin, Junlin Wang, Tianyu Zhou, Mao Guan, Runjia Zhang, and Christina Dan Wang. 2024. https://arxiv.org/abs/2405.14767 Finrobot: An open-source ai agent platform for financial applications using large language models . Preprint, arXiv:2405.14767
- [58]
- [59]
-
[60]
Xinli Yu, Zheng Chen, and Yanbin Lu. 2023. https://doi.org/10.18653/v1/2023.emnlp-industry.69 Harnessing LLM s for temporal data - a study on explainable financial time series forecasting . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 739--753, Singapore. Association for Computational Linguistics
-
[61]
Yangyang Yu, Zhiyuan Yao, Haohang Li, Zhiyang Deng, Yuechen Jiang, Yupeng Cao, Zhi Chen, Jordan W. Suchow, Zhenyu Cui, Rong Liu, Zhaozhuo Xu, Denghui Zhang, Koduvayur Subbalakshmi, Guojun Xiong, Yueru He, Jimin Huang, Dong Li, and Qianqian Xie. 2024. https://proceedings.neurips.cc/paper_files/paper/2024/file/f7ae4fe91d96f50abc2211f09b6a7e49-Paper-Conferen...
work page 2024
-
[62]
Alexandros Zeakis, George Papadakis, Dimitrios Skoutas, and Manolis Koubarakis. 2023. https://doi.org/10.14778/3598581.3598594 Pre-trained embeddings for entity resolution: An experimental analysis . Proc. VLDB Endow., 16(9):2225–2238
-
[63]
Boyu Zhang, Hongyang Yang, Tianyu Zhou, Muhammad Ali Babar, and Xiao-Yang Liu. 2023. https://doi.org/10.1145/3604237.3626866 Enhancing financial sentiment analysis via retrieval augmented large language models . In Proceedings of the Fourth ACM International Conference on AI in Finance, ICAIF '23, page 349–356, New York, NY, USA. Association for Computing...
-
[64]
Yiyun Zhao, Prateek Singh, Hanoz Bhathena, Bernardo Ramos, Aviral Joshi, Swaroop Gadiyaram, and Saket Sharma. 2024. https://doi.org/10.18653/v1/2024.naacl-industry.23 Optimizing LLM based retrieval augmented generation pipelines in the financial domain . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computation...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.