RL Fine-Tuning Heals OOD Forgetting in SFT
Pith reviewed 2026-05-18 17:31 UTC · model grok-4.3
The pith
Reinforcement learning restores out-of-distribution reasoning lost during extended supervised fine-tuning of language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
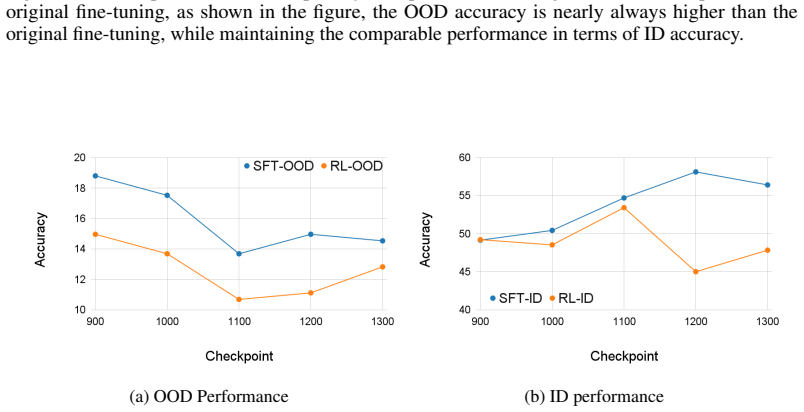
Through checkpoint-wise analyses of in-distribution and out-of-distribution reasoning, OOD performance peaks early during SFT and then declines despite continued improvement in ID reasoning. RL typically does not surpass this early SFT peak; rather, it restores OOD capability lost during later SFT, and only from a bounded range of SFT checkpoints. Further spectral analysis shows that this forgetting-and-recovery pattern correlates with rotations of singular vectors, while singular values remain largely stable.
What carries the argument
Checkpoint-wise performance tracking combined with spectral analysis of singular vector rotations during SFT and RL stages.
If this is right
- SFT improves ID reasoning but can degrade OOD performance after an early peak.
- RL fine-tuning recovers lost OOD capability only when applied to a bounded range of SFT checkpoints.
- The recovery does not exceed the highest OOD level reached in early SFT.
- Singular vector rotations track the forgetting and recovery cycle while singular values stay stable.
Where Pith is reading between the lines
- Monitoring changes in singular vector directions during training could flag when OOD degradation begins.
- Training methods that limit singular vector rotation might reduce reliance on a separate RL recovery stage.
- The same checkpoint and spectral analysis could be applied to other post-training methods such as preference optimization to test for similar patterns.
Load-bearing premise
The observed OOD forgetting during continued SFT and the subsequent recovery by RL reflect a general property of post-training dynamics rather than an artifact of the specific models, datasets, or evaluation splits chosen.
What would settle it
Re-running the checkpoint-wise ID and OOD evaluations plus spectral analysis on a new model family and reasoning dataset, then finding no early OOD peak during SFT or no restoration by RL from any checkpoint range.
Figures













read the original abstract
Supervised Fine-Tuning (SFT) followed by Reinforcement Learning (RL) is a standard post-training recipe for improving Large Language Models (LLM) reasoning, but why it works remains unclear. We revisit the common claim that ``SFT memorizes, RL generalizes'' through checkpoint-wise analyses of in-distribution (ID) and out-of-distribution (OOD) reasoning. We find that OOD performance often peaks early during SFT and then declines despite continued improvement in ID reasoning. RL typically does not surpass this early SFT peak; rather, it restores OOD capability lost during later SFT, and only from a bounded range of SFT checkpoints. Further spectral analysis shows that this forgetting-and-recovery pattern correlates with rotations of singular vectors, while singular values remain largely stable. These findings suggest a more precise view of post-training dynamics: SFT can forget, RL can recover, and controlling singular-vector rotation may improve OOD robustness. Code is available at \href{https://github.com/jinhangzhan/RL\_Heals\_SFT.git}{https://github.com/jinhangzhan/RL\_Heals\_SFT}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that OOD reasoning performance in LLMs often peaks early during SFT and then declines even as ID performance keeps improving. RL fine-tuning typically restores the lost OOD capability from a bounded range of SFT checkpoints without surpassing the early SFT peak. Spectral (SVD) analysis shows this forgetting-and-recovery pattern correlates with rotations of singular vectors while singular values remain largely stable. The authors conclude that SFT can induce forgetting, RL can recover it, and controlling singular-vector rotation may improve OOD robustness. Code is released.
Significance. If these dynamics hold beyond the studied settings, the work refines the 'SFT memorizes, RL generalizes' view by identifying a recoverable forgetting phase and linking it to a concrete spectral signature. This could inform checkpoint selection and regularization strategies for OOD robustness in reasoning models. The released code is a clear strength, allowing direct reproduction of the checkpoint-wise curves and SVD decompositions.
major comments (2)
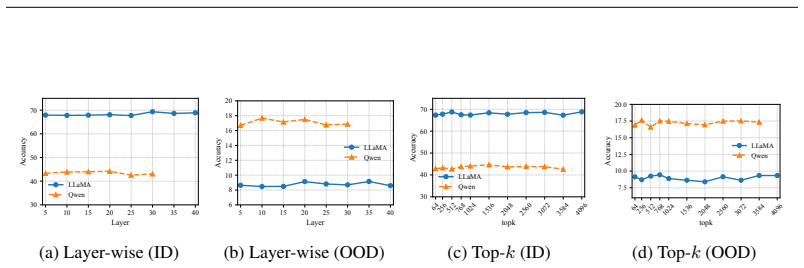
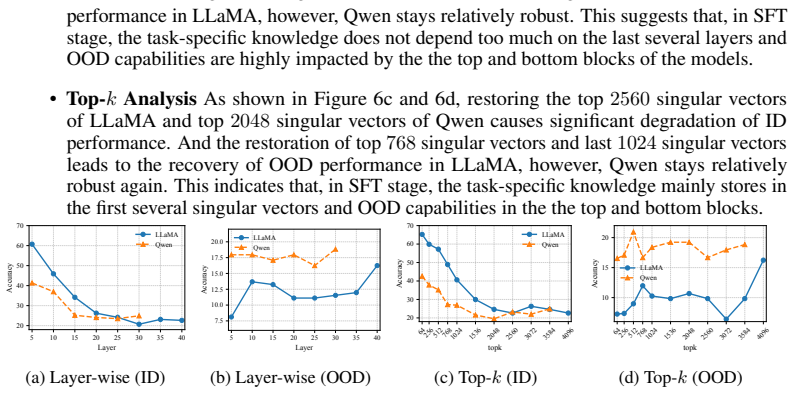
- [§3] §3 (checkpoint-wise ID/OOD curves): the central claim that OOD performance peaks early and then declines rests on these trajectories. Without reported error bars, number of random seeds, or statistical tests for the peak location and decline, it is difficult to judge whether the forgetting pattern is robust or sensitive to run-to-run variation.
- [§4] §4 (SVD analysis): the reported correlation between singular-vector rotations and the OOD recovery pattern is presented as empirical. To support the mechanistic interpretation that rotation drives the forgetting, a quantitative metric (e.g., principal-angle change versus OOD drop) and its consistency across the evaluated models would be needed; the current qualitative description leaves open whether the link is load-bearing or coincidental.
minor comments (1)
- [Figures 2-4] Figure captions and axis labels for the checkpoint curves could explicitly state the number of evaluation examples per point and whether results are averaged over multiple prompts or seeds.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of empirical robustness and mechanistic interpretation that we will address in the revision.
read point-by-point responses
-
Referee: [§3] §3 (checkpoint-wise ID/OOD curves): the central claim that OOD performance peaks early and then declines rests on these trajectories. Without reported error bars, number of random seeds, or statistical tests for the peak location and decline, it is difficult to judge whether the forgetting pattern is robust or sensitive to run-to-run variation.
Authors: We acknowledge the validity of this concern. The presented curves were generated from single runs per configuration, which limits assessment of variability. In the revised manuscript we will rerun the key SFT trajectories with at least three random seeds, add error bars to the ID/OOD plots in §3, and report that the early peak and subsequent decline remain consistent across seeds. A brief note on the stability of the peak location will be included. revision: yes
-
Referee: [§4] §4 (SVD analysis): the reported correlation between singular-vector rotations and the OOD recovery pattern is presented as empirical. To support the mechanistic interpretation that rotation drives the forgetting, a quantitative metric (e.g., principal-angle change versus OOD drop) and its consistency across the evaluated models would be needed; the current qualitative description leaves open whether the link is load-bearing or coincidental.
Authors: We agree that a quantitative link would strengthen the mechanistic claim. In the revision we will introduce a principal-angle metric between the leading singular vectors of early-SFT and later checkpoints, compute its correlation with the observed OOD drop, and report these values (including Pearson coefficients) for every model examined in §4. This will replace the purely qualitative description and demonstrate consistency across models. revision: yes
Circularity Check
No circularity: empirical observations from checkpoint analyses and spectral correlations
full rationale
The paper presents direct experimental results from SFT checkpoint evaluations on ID/OOD reasoning tasks and subsequent spectral analysis of singular vectors/values. No derivation chain, fitted parameters renamed as predictions, or self-citation load-bearing steps are present. Claims such as OOD performance peaking early then declining, RL restoring lost capability from bounded checkpoints, and correlation with singular-vector rotations are reported as observed patterns rather than quantities derived by construction from inputs or prior self-citations. The work is self-contained against external benchmarks via code release and does not invoke uniqueness theorems or ansatzes that reduce to the target results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Singular value decomposition of weight matrices reveals directions whose rotation correlates with changes in out-of-distribution reasoning performance.
Forward citations
Cited by 4 Pith papers
-
ControBench: An Interaction-Aware Benchmark for Controversial Discourse Analysis on Social Networks
ControBench is a new interaction-aware benchmark combining heterogeneous graphs and rich text for controversial discourse analysis on social networks.
-
Rotation-Preserving Supervised Fine-Tuning
RPSFT improves the in-domain versus out-of-domain performance trade-off during LLM supervised fine-tuning by penalizing rotations in pretrained singular subspaces as a proxy for loss-sensitive directions.
-
Emergent Slow Thinking in LLMs as Inverse Tree Freezing
RLVR drives a concept network in LLMs through nucleation and freezing into inverse trees that support slow thinking, and intervening with brief SFT at peak frustration outperforms standard RLVR while post-freeze SFT c...
-
Reinforcement Learning for Compositional Generalization with Outcome-Level Optimization
Outcome-level RL with binary or composite rewards improves compositional generalization over supervised fine-tuning by avoiding overfitting to frequent training patterns.
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
URLhttps://arxiv.org/abs/2501.12948. Jonathan B Freeman and Rick Dale. Assessing bimodality to detect the presence of a dual cognitive process.Behavior research methods, 45(1):83–97, 2013. Yuqian Fu, Tinghong Chen, Jiajun Chai, Xihuai Wang, Songjun Tu, Guojun Yin, Wei Lin, Qichao Zhang, Yuanheng Zhu, and Dongbin Zhao. Srft: A single-stage method with supe...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1103/physreve.106.054124 2013
-
[2]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
URLhttps://arxiv.org/abs/2504.13837. David Yunis, Kumar Kshitij Patel, Samuel Wheeler, Pedro Savarese, Gal Vardi, Karen Livescu, Michael Maire, and Matthew R Walter. Approaching deep learning through the spectral dynamics of weights.arXiv preprint arXiv:2408.11804, 2024. Simon Zhai, Hao Bai, Zipeng Lin, Jiayi Pan, Peter Tong, Yifei Zhou, Alane Suhr, Saini...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
First, turn right to face north
-
[5]
Turn left to face west
-
[9]
Turn right to face east
-
[10]
Move forward until you reach next intersection where Levi & Korsinsky, LLP is on your right behind
-
[11]
Turn left to face north
-
[13]
Turn slightly right to face northeast
-
[14]
Move forward until you reach next intersection
-
[16]
Move forward until you reach next intersection where Mr Goods Buy & Sell is on your left front
-
[17]
Turn left to face northeast
-
[18]
Move forward until you reach next intersection where Skullfade Barbers is on your left front
-
[19]
Turn right to face northwest
-
[20]
Move forward until you reach destination where The destination Ann Cleaners is on your left. [Action space] forward(): indicates moving forward one step turn direction(x): indicates adjust the ego agent direction towards x direction. x could be any following 8 directions [’north’, ’northeast’, ’east’, ’southeast’, ’south’, ’southwest’, ’west’, ’northwest’...
work page 2025
-
[21]
Number check: if numbers in formula are invalid (not from set, wrong count, etc.) → INCOR- RECT_NUMBER
- [22]
-
[23]
Aggregation: if≥2of the above are true for a step→also count AGGREGATED_ERR. How we compute metrics- Loss: mean token-level CE on train data (OOD). - CORRECT_SOLUTION(CS): a problem is correct if any of its 6 attempts ends with a correct final answer; accuracy is the fraction over 24. - Step-level rates (NO_SOLUTION(NS), ILLEGAL_FORMAT(IF), INCORRECT_NUMB...
work page 2059
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.