RadAgents: Multimodal Agentic Reasoning for Chest X-ray Interpretation with Radiologist-like Workflows
Pith reviewed 2026-05-18 13:38 UTC · model grok-4.3
The pith
A multi-agent framework encodes radiologist workflows to make chest X-ray interpretation more reliable and interpretable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
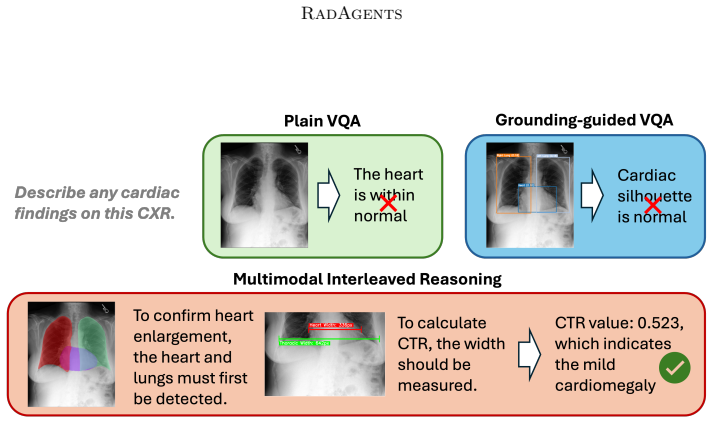
RadAgents is a multi-agent framework that couples clinical priors with task-aware multimodal reasoning and encodes a radiologist-style workflow into a modular, auditable pipeline. By integrating grounding and multimodal retrieval-augmentation to verify and resolve context conflicts, it produces outputs that are more reliable, transparent, and consistent with clinical practice.
What carries the argument
The multi-agent pipeline that follows a radiologist-style workflow, using task-aware multimodal reasoning combined with clinical priors, grounding, and retrieval-augmentation for verification.
If this is right
- Reasoning becomes clinically interpretable and aligned with guidelines instead of just aggregating tool outputs.
- Multimodal evidence is fused, resulting in visually grounded rationales rather than text-only explanations.
- The system detects and resolves cross-tool inconsistencies through principled verification.
- Overall outputs gain reliability, transparency, and consistency with clinical practice.
Where Pith is reading between the lines
- Similar agentic setups could extend to other diagnostic imaging tasks like MRI or ultrasound analysis.
- By making the reasoning auditable, it might facilitate regulatory approval for clinical AI tools.
- Doctors could use the modular steps for teaching or collaborative diagnosis sessions.
- Integration with patient history data might further enhance the framework's accuracy in real-world settings.
Load-bearing premise
That incorporating clinical priors and a radiologist-style workflow into an agent-based system will generate reasoning that is both clinically meaningful and capable of handling multimodal conflicts.
What would settle it
Observing whether the generated reports match radiologist standards in blind tests or if they fail to correctly identify inconsistencies in conflicting tool outputs would test the claim.
Figures





read the original abstract
Agentic systems offer a potential path to solve complex clinical tasks through collaboration among specialized agents, augmented by tool use and external knowledge bases. Nevertheless, for chest X-ray (CXR) interpretation, prevailing methods remain limited: (i) reasoning is frequently neither clinically interpretable nor aligned with guidelines, reflecting mere aggregation of tool outputs; (ii) multimodal evidence is insufficiently fused, yielding text-only rationales that are not visually grounded; and (iii) systems rarely detect or resolve cross-tool inconsistencies and provide no principled verification mechanisms. To bridge the above gaps, we present RadAgents, a multi-agent framework that couples clinical priors with task-aware multimodal reasoning and encodes a radiologist-style workflow into a modular, auditable pipeline. In addition, we integrate grounding and multimodal retrieval-augmentation to verify and resolve context conflicts, resulting in outputs that are more reliable, transparent, and consistent with clinical practice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RadAgents, a multi-agent framework for chest X-ray interpretation. It couples clinical priors with task-aware multimodal reasoning, encodes a radiologist-style workflow into a modular auditable pipeline, and integrates grounding plus multimodal retrieval-augmentation to address limitations in interpretability, visual grounding, and cross-tool inconsistency resolution, with the stated outcome of producing more reliable, transparent, and clinically consistent outputs.
Significance. If the framework's design choices demonstrably deliver the claimed gains in reliability and clinical alignment, the work could advance agentic AI for medical imaging by supplying modular, auditable pipelines that better match radiologist workflows and reduce reliance on ungrounded tool aggregation.
major comments (2)
- [Abstract] Abstract: the assertion that the described integrations 'resulting in outputs that are more reliable, transparent, and consistent with clinical practice' is presented as a direct outcome, yet the manuscript supplies no experiments, datasets, metrics, ablations, error analysis, or baseline comparisons to support this performance claim.
- [Method (framework description)] The central design (multi-agent workflow encoding, grounding, and conflict-resolution mechanisms) is described at the architectural level but lacks concrete implementation details or pseudocode showing how cross-tool inconsistencies are detected and resolved, which is load-bearing for the reliability claim.
minor comments (1)
- [Abstract] The abstract and introduction would benefit from explicit forward references to any planned evaluation sections or supplementary material containing quantitative results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for improving the presentation of claims and technical details. We address each major comment below and commit to revisions that strengthen the work without overstating current results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the described integrations 'resulting in outputs that are more reliable, transparent, and consistent with clinical practice' is presented as a direct outcome, yet the manuscript supplies no experiments, datasets, metrics, ablations, error analysis, or baseline comparisons to support this performance claim.
Authors: We agree that the abstract phrasing presents the benefits of reliability, transparency, and clinical consistency as a direct result of the integrations. The current manuscript is primarily a framework description and does not include empirical evaluations, datasets, or quantitative comparisons to substantiate these outcomes. To correct this, we will revise the abstract to describe these as design goals and expected properties of the RadAgents pipeline rather than demonstrated results, with a note that empirical validation is planned for subsequent work. revision: yes
-
Referee: [Method (framework description)] The central design (multi-agent workflow encoding, grounding, and conflict-resolution mechanisms) is described at the architectural level but lacks concrete implementation details or pseudocode showing how cross-tool inconsistencies are detected and resolved, which is load-bearing for the reliability claim.
Authors: The referee accurately notes that the conflict-resolution and grounding mechanisms are presented at the architectural level. While the high-level design is intended to encode radiologist-like verification steps, additional specificity would better support the reliability claims. We will add pseudocode and step-by-step algorithmic descriptions for inconsistency detection (e.g., cross-tool output comparison rules) and the multimodal retrieval-augmentation resolution process in the Methods section of the revised manuscript. revision: yes
Circularity Check
No circularity: framework is an engineering design without derivations or self-referential predictions
full rationale
The paper describes RadAgents as a modular multi-agent architecture that encodes clinical priors and radiologist workflows, augmented by grounding and retrieval. No equations, fitted parameters, predictions of derived quantities, or uniqueness theorems appear in the abstract or described claims. The assertion that the pipeline 'results in outputs that are more reliable, transparent, and consistent with clinical practice' is presented as a design motivation rather than a mathematical reduction to prior inputs. No self-citation chains, ansatz smuggling, or renaming of known results are load-bearing. The work is self-contained as a proposed system architecture.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Clinical priors and radiologist-style workflows can be modularly encoded into agentic systems to produce interpretable outputs.
invented entities (1)
-
Specialized multimodal agents with grounding and conflict-resolution capabilities
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RadAgents, a multi-agent framework that couples clinical priors with task-aware multimodal reasoning and encodes a radiologist-style workflow into a modular, auditable pipeline
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Multi-Modal Multi-Agent Reinforcement Learning for Radiology Report Generation
MARL-Rad trains region-specific and global agents with reinforcement learning on clinical rewards to produce more accurate radiology reports than prior methods on MIMIC-CXR and IU X-ray datasets.
-
Echo-{\alpha}: Large Agentic Multimodal Reasoning Model for Ultrasound Interpretation
Echo-α integrates organ-specific detectors with global visual context via an invoke-and-reason agentic loop, trained on a nine-task curriculum plus sequential RL, to achieve superior grounding (56.73%/43.78% F1@0.5) a...
Reference graph
Works this paper leans on
-
[1]
Maira-2: Grounded radiology report gener- ation.arXiv preprint arXiv:2406.04449, 2024
Shruthi Bannur, Kenza Bouzid, Daniel C Castro, Anton Schwaighofer, Anja Thieme, Sam Bond- Taylor, Maximilian Ilse, Fernando P´ erez-Garc´ ıa, Valentina Salvatelli, Harshita Sharma, et al. Maira- 2: Grounded radiology report generation.arXiv preprint arXiv:2406.04449,
-
[2]
Pierre Chambon, Jean-Benoit Delbrouck, Thomas Sounack, Shih-Cheng Huang, Zhihong Chen, Maya Varma, Steven QH Truong, Chu The Chuong, and Curtis P Langlotz. Chexpert plus: Augmenting a large chest x-ray dataset with text radiology re- ports, patient demographics and additional image formats.arXiv preprint arXiv:2405.19538,
-
[3]
Mllm-as-a-judge: Assessing multimodal llm-as-a-judge with vision- language benchmark
Dongping Chen, Ruoxi Chen, Shilin Zhang, Yaochen Wang, Yinuo Liu, Huichi Zhou, Qihui Zhang, Yao Wan, Pan Zhou, and Lichao Sun. Mllm-as-a-judge: Assessing multimodal llm-as-a-judge with vision- language benchmark. InForty-first International Conference on Machine Learning, 2024a. Wenting Chen, Yi Dong, Zhaojun Ding, Yucheng Shi, Yifan Zhou, Fang Zeng, Yiju...
-
[4]
Zhihong Chen, Maya Varma, Jean-Benoit Del- brouck, Magdalini Paschali, Louis Blankemeier, Dave Van Veen, Jeya Maria Jose Valanarasu, Alaa Youssef, Joseph Paul Cohen, Eduardo Pontes Reis, et al. Chexagent: Towards a foundation model for chest x-ray interpretation.arXiv preprint arXiv:2401.12208, 2024b. Yun-Wei Chu, Kai Zhang, Christopher Malon, and Martin ...
-
[5]
Juerg Hodler, Rahel A Kubik-Huch, and Gustav K von Schulthess.Diseases of the chest, breast, heart and vessels 2019-2022: diagnostic and interven- tional imaging. Springer Nature,
work page 2019
-
[6]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Os- trow, Akila Welihinda, Alan Hayes, Alec Rad- ford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
MIMIC-CXR-JPG, a large publicly available database of labeled chest radiographs
Alistair EW Johnson, Tom J Pollard, Nathaniel R Greenbaum, Matthew P Lungren, Chih-ying Deng, Yifan Peng, Zhiyong Lu, Roger G Mark, Seth J Berkowitz, and Steven Horng. Mimic-cxr-jpg, a large publicly available database of labeled chest radiographs.arXiv preprint arXiv:1901.07042,
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[8]
Mmedagent: Learn- ing to use medical tools with multi-modal agent
Binxu Li, Tiankai Yan, Yuanting Pan, Jie Luo, Ruiyang Ji, Jiayuan Ding, Zhe Xu, Shilong Liu, Haoyu Dong, Zihao Lin, et al. Mmedagent: Learn- ing to use medical tools with multi-modal agent. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 8745–8760,
work page 2024
-
[9]
Advances in Neural Information Processing Systems , year =
Chengzhi Liu, Zhongxing Xu, Qingyue Wei, Juncheng Wu, James Zou, Xin Eric Wang, Yuyin Zhou, and Sheng Liu. More thinking, less seeing? assessing amplified hallucination in multimodal reasoning models.arXiv preprint arXiv:2505.21523,
-
[10]
OctoTools: An Agentic Framework with Extensible Tools for Complex Reasoning
Pan Lu, Bowen Chen, Sheng Liu, Rahul Thapa, Joseph Boen, and James Zou. Octotools: An agen- tic framework with extensible tools for complex reasoning.arXiv preprint arXiv:2502.11271,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Green: Generative radiology report evaluation and error notation
Sophie Ostmeier, Justin Xu, Zhihong Chen, Maya Varma, Louis Blankemeier, Christian Bluethgen, Arne Md, Michael Moseley, Curtis Langlotz, Ak- shay Chaudhari, et al. Green: Generative radiology report evaluation and error notation. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 374–390,
work page 2024
-
[12]
Cheng Peng, Kai Zhang, Mengxian Lyu, Hong- fang Liu, Lichao Sun, and Yonghui Wu. Scal- ing up biomedical vision-language models: Fine- tuning, instruction tuning, and multi-modal learn- ing.arXiv preprint arXiv:2505.17436,
-
[13]
AgentClinic: a multimodal agent benchmark to evaluate AI in simulated clinical environments
Samuel Schmidgall, Rojin Ziaei, Carl Harris, Ed- uardo Reis, Jeffrey Jopling, and Michael Moor. Agentclinic: a multimodal agent benchmark to evaluate ai in simulated clinical environments. arXiv preprint arXiv:2405.07960,
work page internal anchor Pith review arXiv
-
[14]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, C´ ıan Hughes, Charles Lau, et al. Medgemma technical report. arXiv preprint arXiv:2507.05201,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Akshay Smit, Saahil Jain, Pranav Rajpurkar, Anuj Pareek, Andrew Y Ng, and Matthew Lungren. Combining automatic labelers and expert annota- tions for accurate radiology report labeling using bert. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1500–1519,
work page 2020
-
[16]
Lei WANG, Wanyu XU, Yihuai LAN, Zhiqiang HU, Yunshi LAN, and Roy Ka-Wei LEE. Lim, ee- peng. plan-and-solve prompting: Improving zero- shot chain-of-thought reasoning by large language models.(2023). In61st Annual Meeting of the Asso- ciation for Computational Linguistics, ACL, pages 9–14,
work page 2023
-
[17]
Multimodal Chain-of-Thought Reasoning: A Comprehensive Survey
Yaoting Wang, Shengqiong Wu, Yuecheng Zhang, Shuicheng Yan, Ziwei Liu, Jiebo Luo, and Hao Fei. Multimodal chain-of-thought reason- ing: A comprehensive survey.arXiv preprint arXiv:2503.12605,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Ratescore: A met- ric for radiology report generation
Weike Zhao, Chaoyi Wu, Xiaoman Zhang, Ya Zhang, Yanfeng Wang, and Weidi Xie. Ratescore: A met- ric for radiology report generation. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 15004–15019,
work page 2024
-
[19]
and BLEU (Papineni et al., 2002). While these metrics are widely used for text evaluation, they treat differences in wording the same as clini- cally significant errors, failing to reflect medical accu- racy. To address this limitation, clinically informed evaluation metrics, such as CheXbert (Smit et al., 2020), RadGraph (Jain et al., 2021), GREEN (Ost- ...
work page 2002
-
[20]
Dataset # Cases # Images per case Has prior? MIMIC-CXR (subset) 181 2 Yes MS-CXR (test set) 181 1 No MS-CXR-T 785 2 Yes Table 2: Details of datasets used in RadAgents. Appendix D. Prompting The input toRadAgentsincludes not only the im- age and query but also optional clinical context, such as patient demographics, indication, acquisition tech- nique, com...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.