RLCracker: Evaluating the Worst-Case Vulnerability of LLM Watermarks with Adaptive RL Attacks
Pith reviewed 2026-05-18 14:20 UTC · model grok-4.3
The pith
Reinforcement learning lets a 3B model remove LLM watermarks at 98.5 percent success after training on 100 samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce the adaptive robustness radius, a formal metric that quantifies the worst-case resilience of watermarks against adaptive adversaries. By lifting the paraphrase space into a KL-divergence ball, we approximate this radius and theoretically demonstrate that optimizing the attack context and model parameters can significantly reduce the approximate radius, making watermarks highly vulnerable to paraphrase attacks. Leveraging this insight, we propose RLCracker, a reinforcement learning based adaptive attack that erases watermark signals with limited watermarked examples and limited access to the detector.
What carries the argument
Adaptive robustness radius approximated by lifting the paraphrase space into a KL-divergence ball
If this is right
- Watermark removal becomes practical with small training sets and modest model sizes.
- Robustness claims based on non-adaptive attacks fail against optimized RL methods.
- The vulnerability appears across multiple watermarking schemes and model scales.
- Effective attacks remain possible even with limited detector access.
Where Pith is reading between the lines
- Watermark designers may need to build resistance to optimization-based attacks into their theoretical models.
- The same RL approach could serve as a general test for other AI-generated content detectors.
- Long-term reliance on watermarking for provenance may require additional complementary defenses.
Load-bearing premise
The KL-divergence ball approximation faithfully captures the capabilities of a worst-case adaptive adversary using real paraphrases.
What would settle it
Run RLCracker on a previously untested watermarking scheme and check whether removal success stays above 90 percent while semantic similarity remains above 0.95.
Figures



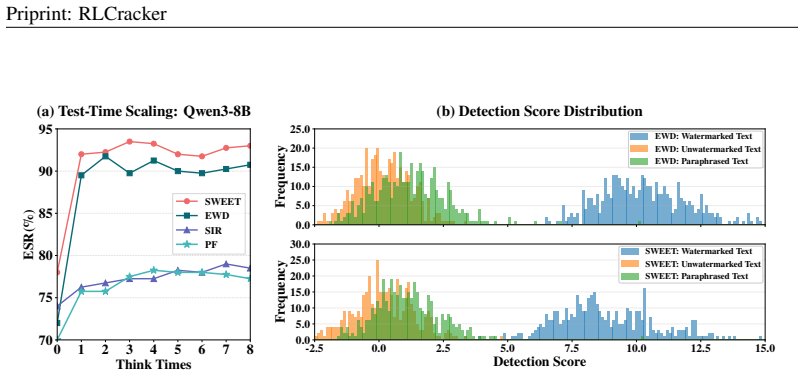


read the original abstract
Large language model (LLM) watermarking has shown promise in detecting AI-generated content and mitigating misuse, with prior work claiming robustness against paraphrasing and text editing. In this paper, we argue that existing evaluations are not sufficiently adversarial, obscuring critical vulnerabilities and overstating the security. To address this, we introduce the adaptive robustness radius, a formal metric that quantifies the worst-case resilience of watermarks against adaptive adversaries. By lifting the paraphrase space into a KL-divergence ball, we approximate this radius and theoretically demonstrate that optimizing the attack context and model parameters can significantly reduce the approximate radius, making watermarks highly vulnerable to paraphrase attacks. Leveraging this insight, we propose RLCracker, a reinforcement learning (RL)-based adaptive attack that erases watermark signals with limited watermarked examples and limited access to the detector. Despite weak supervision, it empowers a 3B model to achieve 98.5% removal success with minimal semantic shift on 1,500-token Unigram-marked texts after training on only 100 short samples. This performance dramatically exceeds 6.75% by GPT-4o and generalizes across five model sizes over ten watermarking schemes. Our code is available at https://github.com/OTT0-OTO/RLCracker.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that prior evaluations of LLM watermarks are insufficiently adversarial. It introduces the adaptive robustness radius as a formal metric for worst-case resilience, approximates it by lifting the paraphrase space into a KL-divergence ball, and claims that optimizing attack context and model parameters provably reduces this approximate radius. The authors present RLCracker, an RL-based adaptive attack that, after training on only 100 short samples, allows a 3B model to achieve 98.5% watermark removal success on 1,500-token Unigram-marked texts with minimal semantic shift, far exceeding GPT-4o's 6.75% and generalizing across five model sizes and ten watermarking schemes. Code is released at https://github.com/OTT0-OTO/RLCracker.
Significance. If the results hold, the work is significant for LLM security research. It supplies both a formal metric and a practical, low-resource RL attack demonstrating concrete vulnerabilities, supported by clear empirical success rates and cross-scheme generalization. The open-source code is a strength that aids reproducibility and allows independent verification of the reported attack performance.
major comments (1)
- [Theoretical analysis of adaptive robustness radius and KL-ball approximation] The lifting of the paraphrase space into a KL-divergence ball to approximate the adaptive robustness radius and the claim that optimization inside this ball reduces the radius (as stated in the abstract and theoretical analysis) is load-bearing for the central argument. The manuscript asserts rather than derives bounds on approximation tightness and provides no verification that the learned RL policy outputs remain inside the ball or that the ball contains the relevant worst-case semantic-preserving paraphrases. Without this, the 98.5% empirical removal success does not directly confirm the theoretical reduction.
minor comments (2)
- [Abstract] The abstract refers to 'minimal semantic shift' without naming the concrete metric (e.g., cosine similarity on embeddings or BLEU score); adding this detail would improve clarity and reproducibility.
- [Experimental setup] The description of the 100 training samples (their length distribution and selection process) relative to the 1,500-token evaluation texts could be expanded to better support the generalization claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for emphasizing the need for rigorous theoretical grounding. We address the single major comment below and agree that additional clarification and verification would strengthen the connection between the adaptive robustness radius and the empirical results. We plan to revise the manuscript accordingly.
read point-by-point responses
-
Referee: The lifting of the paraphrase space into a KL-divergence ball to approximate the adaptive robustness radius and the claim that optimization inside this ball reduces the radius (as stated in the abstract and theoretical analysis) is load-bearing for the central argument. The manuscript asserts rather than derives bounds on approximation tightness and provides no verification that the learned RL policy outputs remain inside the ball or that the ball contains the relevant worst-case semantic-preserving paraphrases. Without this, the 98.5% empirical removal success does not directly confirm the theoretical reduction.
Authors: We appreciate this observation. The manuscript defines the adaptive robustness radius as the minimal perturbation radius needed to erase the watermark under an adaptive adversary and approximates the space of semantic-preserving paraphrases via a KL-divergence ball centered on the original text distribution. Within this ball, we show that jointly optimizing attack context and model parameters yields a policy whose effective radius is smaller than that of non-adaptive baselines, because the learned policy identifies watermark-removing transformations that remain distributionally close. However, we acknowledge that the paper does not derive quantitative bounds on the tightness of the KL-ball approximation to the true paraphrase space, nor does it include post-training verification that RL-generated outputs lie inside the ball. The reported low semantic drift (high BERTScore, low perplexity change) provides indirect support that the attacks are semantically plausible, but this is not equivalent to a KL-membership check. In revision we will (1) explicitly state the heuristic nature of the approximation, (2) add a dedicated limitations subsection discussing the absence of tightness bounds, and (3) include new experiments that compute the empirical KL divergence of the attacked texts relative to the original distribution to confirm they remain within the modeled ball. These changes will make the theoretical-empirical linkage more transparent without altering the core empirical claims. revision: yes
Circularity Check
Derivation self-contained; KL-ball approximation external to empirical attack results
full rationale
The paper defines the adaptive robustness radius as a formal worst-case metric, approximates it by lifting paraphrases into a KL-divergence ball, and separately demonstrates a theoretical reduction under optimization inside that ball. RLCracker is then presented as an RL policy realizing attacks in practice, with results reported on held-out test texts (1,500-token samples) after training on 100 short examples. No equation or claim reduces the reported 98.5% removal success or the radius reduction to a fitted parameter or self-citation by construction. The KL-ball construction is introduced as an external modeling choice rather than derived from the attack success metric itself, and the empirical evaluation uses standard held-out generalization checks. This yields only minor self-citation risk at most and keeps the central claims independent of the inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- training sample count
axioms (1)
- domain assumption The paraphrase space can be lifted into a KL-divergence ball that approximates worst-case adaptive attacks
invented entities (1)
-
adaptive robustness radius
no independent evidence
Forward citations
Cited by 1 Pith paper
-
RLSpoofer: A Lightweight Evaluator for LLM Watermark Spoofing Resilience
RLSpoofer trains a 4B model on 100 watermarked paraphrase pairs to spoof PF watermarks at 62% success rate, far exceeding baselines trained on up to 10,000 samples.
Reference graph
Works this paper leans on
-
[1]
Revealing weaknesses in text watermarking through self-information rewrite attacks
Yixin Cheng, Hongcheng Guo, Yangming Li, and Leonid Sigal. Revealing weaknesses in text watermarking through self-information rewrite attacks. arXiv preprint arXiv:2505.05190, 2025
-
[2]
Undetectable watermarks for language models
Miranda Christ, Sam Gunn, and Or Zamir. Undetectable watermarks for language models. In The Thirty Seventh Annual Conference on Learning Theory, pp.\ 1125--1139. PMLR, 2024
work page 2024
-
[3]
Certified adversarial robustness via randomized smoothing
Jeremy M Cohen, Elan Rosenfeld, and J Zico Kolter. Certified adversarial robustness via randomized smoothing. In ICML, 2019
work page 2019
-
[4]
Scalable watermarking for identifying large language model outputs
Sumanth Dathathri, Abigail See, Sumedh Ghaisas, Po-Sen Huang, Rob McAdam, Johannes Welbl, Vandana Bachani, Alex Kaskasoli, Robert Stanforth, Tatiana Matejovicova, et al. Scalable watermarking for identifying large language model outputs. Nature, 634 0 (8035): 0 818--823, 2024
work page 2024
-
[5]
Distributionally robust losses for latent covariate mixtures
John Duchi and Hongseok Namkoong. Distributionally robust losses for latent covariate mixtures. arXiv preprint arXiv:1906.08764, 2019
-
[6]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
arXiv preprint arXiv:2402.14007 (2024)
Zhiwei He, Binglin Zhou, Hongkun Hao, Aiwei Liu, Xing Wang, Zhaopeng Tu, Zhuosheng Zhang, and Rui Wang. Can watermarks survive translation? on the cross-lingual consistency of text watermark for large language models. arXiv preprint arXiv:2402.14007, 2024
-
[8]
Unbiased watermark for large language models
Zhengmian Hu, Lichang Chen, Xidong Wu, Yihan Wu, Hongyang Zhang, and Heng Huang. Unbiased watermark for large language models. arXiv preprint arXiv:2310.10669, 2023
-
[9]
b^ 4 : A black-box scrubbing attack on llm watermarks
Baizhou Huang, Xiao Pu, and Xiaojun Wan. b^ 4 : A black-box scrubbing attack on llm watermarks. arXiv preprint arXiv:2411.01222, 2024
-
[10]
Open r1: A fully open reproduction of deepseek-r1, January 2025
Hugging Face . Open r1: A fully open reproduction of deepseek-r1, January 2025. URL https://github.com/huggingface/open-r1
work page 2025
-
[11]
Watermark stealing in large language models
Nikola Jovanovi \'c , Robin Staab, and Martin Vechev. Watermark stealing in large language models. arXiv preprint arXiv:2402.19361, 2024
-
[12]
A watermark for large language models
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. A watermark for large language models. In International Conference on Machine Learning, pp.\ 17061--17084. PMLR, 2023 a
work page 2023
-
[13]
On the reliability of watermarks for large language models.arXiv preprint arXiv:2306.04634, 2023
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Manli Shu, Khalid Saifullah, Kezhi Kong, Kasun Fernando, Aniruddha Saha, Micah Goldblum, and Tom Goldstein. On the reliability of watermarks for large language models. arXiv preprint arXiv:2306.04634, 2023 b
-
[14]
Paraphrasing evades detectors of ai-generated text, but retrieval is an effective defense
Kalpesh Krishna, Yixiao Song, Marzena Karpinska, John Wieting, and Mohit Iyyer. Paraphrasing evades detectors of ai-generated text, but retrieval is an effective defense. Advances in Neural Information Processing Systems, 36: 0 27469--27500, 2023 a
work page 2023
-
[15]
Paraphrasing evades detectors of ai-generated text, but retrieval is an effective defense
Kalpesh Krishna, Yixiao Song, Marzena Karpinska, John Wieting, and Mohit Iyyer. Paraphrasing evades detectors of ai-generated text, but retrieval is an effective defense. Advances in Neural Information Processing Systems, 36: 0 27469--27500, 2023 b
work page 2023
-
[16]
Robust distortion- free watermarks for language models.arXiv preprint arXiv:2307.15593, 2023
Rohith Kuditipudi, John Thickstun, Tatsunori Hashimoto, and Percy Liang. Robust distortion-free watermarks for language models. arXiv preprint arXiv:2307.15593, 2023
-
[17]
On information and sufficiency
Solomon Kullback and Richard A Leibler. On information and sufficiency. The annals of mathematical statistics, 22 0 (1): 0 79--86, 1951
work page 1951
-
[18]
Who wrote this code? watermarking for code generation.arXiv preprint arXiv:2305.15060,
Taehyun Lee, Seokhee Hong, Jaewoo Ahn, Ilgee Hong, Hwaran Lee, Sangdoo Yun, Jamin Shin, and Gunhee Kim. Who wrote this code? watermarking for code generation. arXiv preprint arXiv:2305.15060, 2023
-
[19]
An unforgeable publicly verifiable watermark for large language models
Aiwei Liu, Leyi Pan, Xuming Hu, Shu'ang Li, Lijie Wen, Irwin King, and Philip S Yu. An unforgeable publicly verifiable watermark for large language models. arXiv preprint arXiv:2307.16230, 2023 a
-
[20]
A semantic invariant robust watermark for large language models.arXiv preprint arXiv:2310.06356,
Aiwei Liu, Leyi Pan, Xuming Hu, Shiao Meng, and Lijie Wen. A semantic invariant robust watermark for large language models. arXiv preprint arXiv:2310.06356, 2023 b
-
[21]
Aiwei Liu, Sheng Guan, Yiming Liu, Leyi Pan, Yifei Zhang, Liancheng Fang, Lijie Wen, Philip S Yu, and Xuming Hu. Can watermarked llms be identified by users via crafted prompts? arXiv preprint arXiv:2410.03168, 2024 a
-
[22]
Preventing and detecting misinformation generated by large language models
Aiwei Liu, Qiang Sheng, and Xuming Hu. Preventing and detecting misinformation generated by large language models. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp.\ 3001--3004, 2024 b
work page 2024
-
[23]
An entropy-based text watermarking detection method
Yijian Lu, Aiwei Liu, Dianzhi Yu, Jingjing Li, and Irwin King. An entropy-based text watermarking detection method. arXiv preprint arXiv:2403.13485, 2024
-
[24]
Towards deep learning models resistant to adversarial attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. In ICLR, 2018
work page 2018
-
[25]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Cand \`e s, and Tatsunori Hashimoto. s1: Simple test-time scaling. arXiv preprint arXiv:2501.19393, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Markllm: An open-source toolkit for llm watermarking.arXiv preprint arXiv:2405.10051,
Leyi Pan, Aiwei Liu, Zhiwei He, Zitian Gao, Xuandong Zhao, Yijian Lu, Binglin Zhou, Shuliang Liu, Xuming Hu, Lijie Wen, et al. Markllm: An open-source toolkit for llm watermarking. arXiv preprint arXiv:2405.10051, 2024
-
[27]
Markmywords: Analyzing and evaluating language model watermarks
Julien Piet, Chawin Sitawarin, Vivian Fang, Norman Mu, and David Wagner. Markmywords: Analyzing and evaluating language model watermarks. In 2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), pp.\ 68--91. IEEE, 2025
work page 2025
-
[28]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Watermarking makes language models radioactive
Tom Sander, Pierre Fernandez, Alain Durmus, Matthijs Douze, and Teddy Furon. Watermarking makes language models radioactive. Advances in Neural Information Processing Systems, 37: 0 21079--21113, 2024
work page 2024
-
[30]
John Schulman. Approximating kl divergence. http://joschu.net/blog/kl-approx.html, 2020
work page 2020
-
[31]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Certifying some distributional robustness with principled adversarial training
Aman Sinha, Hongseok Namkoong, and John C Duchi. Certifying some distributional robustness with principled adversarial training. In ICLR, 2018
work page 2018
-
[33]
Necessary and sufficient watermark for large language models
Yuki Takezawa, Ryoma Sato, Han Bao, Kenta Niwa, and Makoto Yamada. Necessary and sufficient watermark for large language models. arXiv preprint arXiv:2310.00833, 2023
-
[34]
Ghostbuster: Detecting text ghostwritten by large language models
Vivek Verma, Eve Fleisig, Nicholas Tomlin, and Dan Klein. Ghostbuster: Detecting text ghostwritten by large language models. arXiv preprint arXiv:2305.15047, 2023
-
[35]
Trl: Transformer reinforcement learning
Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallouédec. Trl: Transformer reinforcement learning. https://github.com/huggingface/trl, 2020
work page 2020
-
[36]
Unveiling the misuse potential of base large language models via in-context learning
Xiao Wang, Tianze Chen, Xianjun Yang, Qi Zhang, Xun Zhao, and Dahua Lin. Unveiling the misuse potential of base large language models via in-context learning. arXiv preprint arXiv:2404.10552, 2024
-
[37]
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. Jailbroken: How does llm safety training fail? Advances in Neural Information Processing Systems, 36: 0 80079--80110, 2023
work page 2023
-
[38]
Paraphrastic representations at scale
John Wieting, Kevin Gimpel, Graham Neubig, and Taylor Berg-Kirkpatrick. Paraphrastic representations at scale. arXiv preprint arXiv:2104.15114, 2021
-
[39]
A survey on llm-generated text detection: Necessity, methods, and future directions
Junchao Wu, Shu Yang, Runzhe Zhan, Yulin Yuan, Lidia Sam Chao, and Derek Fai Wong. A survey on llm-generated text detection: Necessity, methods, and future directions. Computational Linguistics, 51 0 (1): 0 275--338, 2025
work page 2025
-
[40]
Dipmark: A stealthy, efficient and resilient watermark for large language models
Yihan Wu, Zhengmian Hu, Hongyang Zhang, and Heng Huang. Dipmark: A stealthy, efficient and resilient watermark for large language models. 2023
work page 2023
-
[41]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? arXiv preprint arXiv:2504.13837, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Xuandong Zhao, Prabhanjan Ananth, Lei Li, and Yu-Xiang Wang. Provable robust watermarking for ai-generated text. arXiv preprint arXiv:2306.17439, 2023
-
[44]
Xuandong Zhao, Lei Li, and Yu-Xiang Wang. Permute-and-flip: An optimally stable and watermarkable decoder for llms. arXiv preprint arXiv:2402.05864, 2024
-
[45]
Certified robustness to adversarial word substitutions
Yizheng Zhu, Hongxin Zhang, and Pin-Yu Chen. Certified robustness to adversarial word substitutions. In EMNLP, 2021
work page 2021
-
[46]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[47]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[48]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[49]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.