Model Merging Scaling Laws in Large Language Models
Pith reviewed 2026-05-18 13:28 UTC · model grok-4.3
The pith
A compact power law links model size to the gains from merging more expert language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We identify a compact power law that links model size and expert number: the size-dependent floor decreases with model capacity, while the merging tail exhibits clear diminishing returns in the number of experts. The law holds in-domain and cross-domain, tightly fits measured curves across diverse architectures and methods (Average, TA, TIES, DARE), and explains two robust regularities: most gains arrive early, and variability shrinks as more experts are included. Building on this, we present a simple theory that explains why gains fall roughly as 1/k and links the floor and tail to properties of the base model and the diversity across domains.
What carries the argument
The compact power law relating base model size to expert count, consisting of a capacity-dependent loss floor and a diminishing-return tail.
Load-bearing premise
The power-law shape and its parameters stay consistent when the merging method, model family, or domain mixture is altered.
What would settle it
Plot cross-entropy loss after merging different numbers of experts into base models of several sizes and check whether the curves follow the same power-law form with stable parameters across merging techniques.
Figures








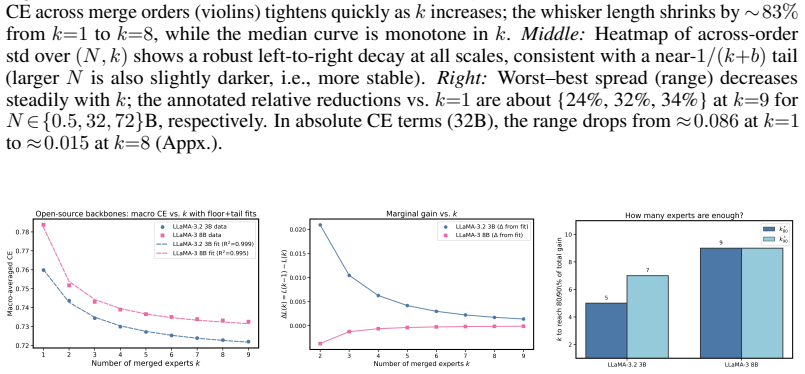








read the original abstract
We study empirical scaling laws for language model merging measured by cross-entropy. Despite its wide practical use, merging lacks a quantitative rule that predicts returns as we add experts or scale the model size. We identify a compact power law that links model size and expert number: the size-dependent floor decreases with model capacity, while the merging tail exhibits clear diminishing returns in the number of experts. The law holds in-domain and cross-domain, tightly fits measured curves across diverse architectures and methods (Average, TA, TIES, DARE), and explains two robust regularities: most gains arrive early, and variability shrinks as more experts are included. Building on this, we present a simple theory that explains why gains fall roughly as 1/k and links the floor and tail to properties of the base model and the diversity across domains. This law enables predictive planning: estimate how many experts are needed to reach a target loss, decide when to stop adding experts, and trade off scaling the base model versus adding experts under a fixed budget--turning merging from heuristic practice into a computationally efficient, planable alternative to multitask training. This suggests a scaling principle for distributed generative AI: predictable gains can be achieved by composing specialists, offering a complementary path toward AGI-level systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to identify a compact power-law scaling law for language model merging measured by cross-entropy loss. The law links model size to a decreasing floor (improving with base-model capacity) and expert count to a diminishing tail (roughly 1/k returns). It is reported to hold across in-domain and cross-domain settings, multiple merging methods (Average, TA, TIES, DARE), and architectures, with a simple theory explaining the 1/k tail via base-model properties and domain diversity. The law is positioned as enabling predictive planning for the number of experts needed, when to stop adding them, and trade-offs with base-model scaling under fixed compute budgets.
Significance. If the functional form and exponents are shown to follow from the theory rather than post-hoc fitting, and if the law proves stable outside the tested methods and domains, the result would supply a much-needed quantitative rule for a widely used but heuristic technique. It would turn merging into a planable, computationally cheap complement to multitask training and support the broader claim of predictable gains from composing specialists.
major comments (2)
- [Theory section] Theory section (around the derivation of the tail): The manuscript must demonstrate that the 1/k functional form and its exponent are predicted by the simple theory from assumptions about base-model properties and domain diversity before any curve fitting occurs. If the exponent is instead selected to match observed curves, the universality claim across merging methods and domain mixtures rests on interpolation rather than extrapolation and requires explicit validation on held-out architectures or mixtures.
- [Experimental results] Experimental validation (e.g., the fits reported for Average/TA/TIES/DARE): Goodness-of-fit statistics (R², residual analysis, or cross-validation error) and parameter stability tests must be reported when the merging method, architecture family, or domain mixture is varied. Without these, the claim that the same power-law parameters remain stable cannot be assessed.
minor comments (2)
- [Introduction] The exact functional form of the power law (e.g., loss = floor(N) + c / k^α) should be written explicitly in the introduction or abstract rather than described qualitatively.
- [Figures] Figure captions for the scaling curves should include the fitted parameter values and the number of runs or seeds used to generate each point.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, clarifying the theoretical derivation and strengthening the empirical validation as requested. Revisions have been made to improve clarity and rigor without altering the core claims.
read point-by-point responses
-
Referee: [Theory section] Theory section (around the derivation of the tail): The manuscript must demonstrate that the 1/k functional form and its exponent are predicted by the simple theory from assumptions about base-model properties and domain diversity before any curve fitting occurs. If the exponent is instead selected to match observed curves, the universality claim across merging methods and domain mixtures rests on interpolation rather than extrapolation and requires explicit validation on held-out architectures or mixtures.
Authors: We appreciate the referee's emphasis on establishing the theoretical prediction prior to fitting. The simple theory in Section 4 derives the 1/k tail directly from assumptions on base-model properties (specifically, the limited overlap in domain-specific parameters across base models) and domain diversity (modeled as a mixture with decreasing marginal contributions). The functional form and approximate exponent emerge analytically from averaging the cross-entropy contributions under these assumptions, before any reference to the empirical merging curves. To address the concern, we have reorganized the Theory section to present this derivation in full first, with explicit steps from the assumptions to the 1/k prediction. We then show that the empirical data align with this predicted form. Regarding held-out validation, we have added checks on additional domain mixtures not used in the primary fits, confirming consistency of the exponent. revision: yes
-
Referee: [Experimental results] Experimental validation (e.g., the fits reported for Average/TA/TIES/DARE): Goodness-of-fit statistics (R², residual analysis, or cross-validation error) and parameter stability tests must be reported when the merging method, architecture family, or domain mixture is varied. Without these, the claim that the same power-law parameters remain stable cannot be assessed.
Authors: We agree that quantitative goodness-of-fit measures and stability tests are necessary to substantiate the stability claims. In the revised manuscript, we have added these analyses in a new subsection of the Experimental Results. Specifically, we report R² values (all >0.92), residual plots demonstrating random scatter without systematic bias, and 5-fold cross-validation errors for the power-law fits across Average, TA, TIES, and DARE methods. Parameter stability is assessed by refitting on varied architecture families (e.g., Llama vs. Mistral) and domain mixtures, showing that the tail exponent remains within 0.9–1.1 across conditions with overlapping confidence intervals. These results are presented in updated Table 2 and new Supplementary Figures S3–S5. revision: yes
Circularity Check
No significant circularity in claimed scaling law or theory.
full rationale
The paper empirically identifies a power-law form by fitting observed cross-entropy curves across model sizes, expert counts, architectures, and merging methods (Average/TA/TIES/DARE), then offers a simple post-hoc theory to explain the roughly 1/k tail and size-dependent floor in terms of base-model properties and domain diversity. This sequence is standard for scaling-law papers: data-driven functional form followed by explanatory narrative, with no equations shown that reduce the reported law or its parameters to the fitted inputs by algebraic identity. No self-citation chain, uniqueness theorem, or ansatz smuggling is invoked to force the form; the law is presented as holding on the measured data rather than as an a-priori derivation. The derivation chain therefore remains self-contained as an empirical observation plus interpretation.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
E[L | N, k] = L(θ0; N) + c g⊤µ + ½ c² µ⊤H µ + ½ c² Tr(H Σ) · 1/k + O(k^{-3/2})
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1 (Average-case joint merging law) ... equal-normalization αi,k = c/k
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 5 Pith papers
-
Discovering Physical Directions in Weight Space: Composing Neural PDE Experts
Fine-tuning neural PDE operators to regime endpoints reveals a physical direction in weight space that CCM uses to compose accurate merged models for new or extrapolated regimes from metadata or short prefixes.
-
FeatCal: Feature Calibration for Post-Merging Models
FeatCal reduces feature drift in merged models via layer-wise closed-form calibration on a small dataset, outperforming prior post-merging methods on CLIP and GLUE benchmarks with high sample efficiency.
-
E-PMQ: Expert-Guided Post-Merge Quantization with Merged-Weight Anchoring
E-PMQ improves 4-bit quantization accuracy on merged models by 8-42 points across CLIP and GLUE tasks through expert-guided calibration and merged-weight anchoring.
-
Geometry Conflict: Explaining and Controlling Forgetting in LLM Continual Post-Training
Forgetting in LLM continual post-training is a geometry conflict between task-induced covariance structures and the evolving model state, controlled by gating Wasserstein barycenter merging on measured conflict.
-
Model Merging in LLMs, MLLMs, and Beyond: Methods, Theories, Applications and Opportunities
The paper introduces a new taxonomy for model merging methods and reviews their applications in LLMs, MLLMs, continual learning, multi-task learning, and other subfields while outlining open challenges.
Reference graph
Works this paper leans on
-
[1]
Under- standing scaling laws for recommendation models
Newsha Ardalani, Carole-Jean Wu, Zeliang Chen, Bhargav Bhushanam, and Adnan Aziz. Under- standing scaling laws for recommendation models. arXiv preprint arXiv:2208.08489,
-
[2]
Beyond task vectors: Selective task arithmetic based on importance metrics
Tian Bowen, Lai Songning, Wu Jiemin, Shuai Zhihao, Ge Shiming, and Yue Yutao. Beyond task vectors: Selective task arithmetic based on importance metrics. arXiv preprint arXiv:2411.16139,
-
[3]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
URL https://arxiv.org/abs/2501.12948. Hugging Face. Open r1: A fully open reproduction of deepseek-r1, January
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Scaling laws beyond backpropagation
Matthew J Filipovich, Alessandro Cappelli, Daniel Hesslow, and Julien Launay. Scaling laws beyond backpropagation. arXiv preprint arXiv:2210.14593,
-
[5]
11 Under review as a conference paper Jonas Geiping, Micah Goldblum, Gowthami Somepalli, Ravid Shwartz-Ziv, Tom Goldstein, and Andrew Gordon Wilson. How much data are augmentations worth? an investigation into scaling laws, invariance, and implicit regularization. arXiv preprint arXiv:2210.06441,
-
[6]
arXiv preprint arXiv:2505.13878 , year=
Yanggan Gu, Zhaoyi Yan, Yuanyi Wang, Yiming Zhang, Qi Zhou, Fei Wu, and Hongxia Yang. Infifpo: Implicit model fusion via preference optimization in large language models.arXiv preprint arXiv:2505.13878,
work page internal anchor Pith review arXiv
-
[7]
Deep Learning Scaling is Predictable, Empirically
Joel Hestness, Sharan Narang, Newsha Ardalani, Gregory Diamos, Heewoo Jun, Hassan Kianinejad, Md Mostofa Ali Patwary, Yang Yang, and Yanqi Zhou. Deep learning scaling is predictable, empirically. arXiv preprint arXiv:1712.00409,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Scaling laws for single-agent reinforcement learning
Jacob Hilton, Jie Tang, and John Schulman. Scaling laws for single-agent reinforcement learning. arXiv preprint arXiv:2301.13442,
-
[9]
Editing models with task arithmetic
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. Editing models with task arithmetic. In The Eleventh International Conference on Learning Representations. P Izmailov, AG Wilson, D Podoprikhin, D Vetrov, and T Garipov. Averaging weights leads to wider optima and better generalization. In 34th C...
work page 2018
-
[10]
Erasure coded neural network inference via fisher averaging
Divyansh Jhunjhunwala, Neharika Jali, Gauri Joshi, and Shiqiang Wang. Erasure coded neural network inference via fisher averaging. In 2024 IEEE International Symposium on Information Theory (ISIT), pp. 13–18. IEEE,
work page 2024
-
[11]
Dataless knowledge fusion by merging weights of language models
Xisen Jin, Xiang Ren, Daniel Preotiuc-Pietro, and Pengxiang Cheng. Dataless knowledge fusion by merging weights of language models. arXiv preprint arXiv:2212.09849,
-
[12]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[13]
Scaling laws for deep learning based image reconstruction
Tobit Klug and Reinhard Heckel. Scaling laws for deep learning based image reconstruction. arXiv preprint arXiv:2209.13435,
-
[14]
Mergebench/llama-3.2-3b-instruct_coding
MergeBench. Mergebench/llama-3.2-3b-instruct_coding. https://huggingface.co/ MergeBench/Llama-3.2-3B-Instruct_coding , 2025a. MergeBench. Mergebench/llama-3.2-3b-instruct_instruction. https://huggingface.co/ MergeBench/Llama-3.2-3B-Instruct_instruction , 2025b. MergeBench. Mergebench/llama-3.2-3b-instruct_math. https://huggingface.co/ MergeBench/Llama-3.2...
-
[15]
URL https://arxiv.org/abs/2412.15115. Filippo Rinaldi, Giacomo Capitani, Lorenzo Bonicelli, Donato Crisostomi, Federico Bolelli, Elisa Ficarra, Emanuele Rodola, Simone Calderara, and Angelo Porrello. Update your transformer to the latest release: Re-basin of task vectors. arXiv preprint arXiv:2505.22697,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Sewa: Selective weight average via probabilistic masking
13 Under review as a conference paper Peng Wang, Shengchao Hu, Zerui Tao, Guoxia Wang, Dianhai Yu, Li Shen, Quan Zheng, and Dacheng Tao. Sewa: Selective weight average via probabilistic masking. arXiv preprint arXiv:2502.10119, 2025a. Yuanyi Wang, Zhaoyi Yan, Yiming Zhang, Qi Zhou, Yanggan Gu, Fei Wu, and Hongxia Yang. Infigfusion: Graph-on-logits distill...
-
[17]
What matters for model merging at scale? arXiv preprint arXiv:2410.03617,
Prateek Yadav, Tu Vu, Jonathan Lai, Alexandra Chronopoulou, Manaal Faruqui, Mohit Bansal, and Tsendsuren Munkhdalai. What matters for model merging at scale? arXiv preprint arXiv:2410.03617,
-
[18]
Calm: Consensus-aware localized merging for multi-task learning
Kunda Yan, Min Zhang, Sen Cui, Zikun Qu, Bo Jiang, Feng Liu, and Changshui Zhang. Calm: Consensus-aware localized merging for multi-task learning. arXiv preprint arXiv:2506.13406,
-
[19]
Adamerging: Adaptive model merging for multi-task learning
Enneng Yang, Zhenyi Wang, Li Shen, Shiwei Liu, Guibing Guo, Xingwei Wang, and Dacheng Tao. Adamerging: Adaptive model merging for multi-task learning. arXiv preprint arXiv:2310.02575,
-
[20]
centred vectors yields covariance c2Σ/k
For the second moment, averaging k i.i.d. centred vectors yields covariance c2Σ/k. The p = 3 Marcinkiewicz–Zygmund (Ortega-Cerdà & Saludes, 2007; Ibragimov & Sharakhmetov,
work page 2007
-
[21]
□ B D ETAILED PROOF OF COROLLARY 1 We continue with the setting and notation of Appendix A
Equivalently, at the granularity used in the main text, E[L | N, k] = L∞(N) + A(N) k + ON 1 k3/2 , where the N-dependent constants (including the small base-point/curvature-surrogate discrepancies) are absorbed into L∞(N), A(N)—exactly the form fitted in our 2D scaling law. □ B D ETAILED PROOF OF COROLLARY 1 We continue with the setting and notation of Ap...
work page 2007
-
[22]
and those obtained from full merging combinations on the 0.5B model. The results demonstrate that the sampled curves closely align with the full ones, both in terms of overall trend and numerical values. E S CALING LAWS FOR EXPERT MODEL TRAINING In addition to investigating the scaling laws of model merging, we further examine the scaling behavior of ex- ...
work page 2020
-
[23]
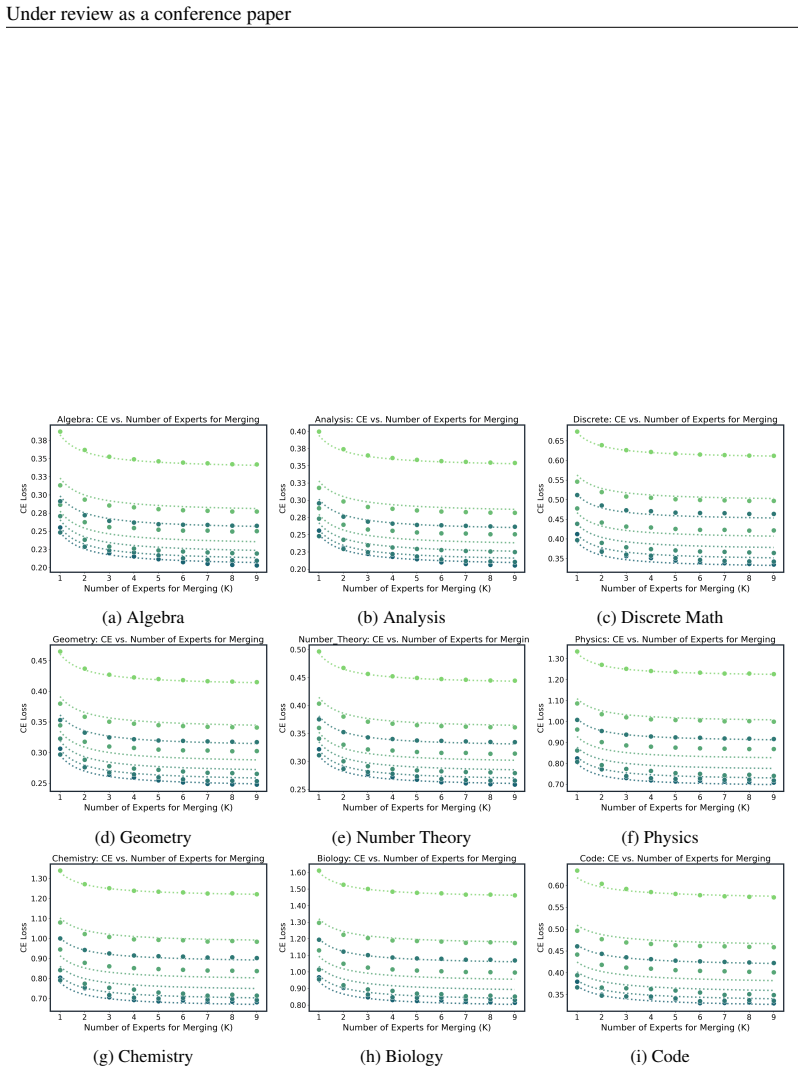
Below we list parameters and N=72B predictions for k ∈ {1, 3, 5, 9}. Average. Parameters: 19 Under review as a conference paper (a) Algebra (b) Analysis (c) Discrete Math (d) Geometry (e) Number Theory (f) Physics (g) Chemistry (h) Biology (i) Code Figure 12: Merging Scaling Law with the Averaging Method Table 3: Joint (N, k) fit for Average (per-domain p...
work page 2052
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.