Causal-Adapter: Taming Text-to-Image Diffusion for Faithful Counterfactual Generation
Pith reviewed 2026-05-21 21:51 UTC · model grok-4.3
The pith
Causal-Adapter adapts frozen text-to-image diffusion models to generate counterfactual images that respect known causal relationships between attributes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
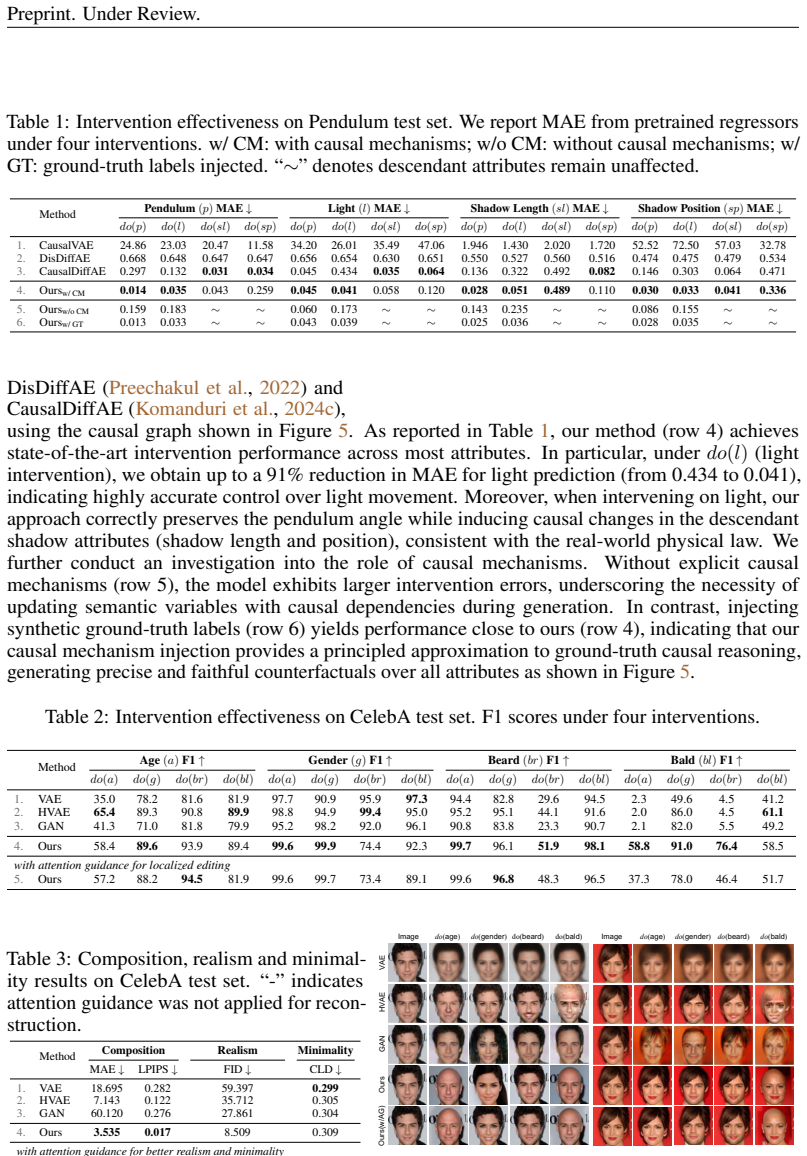
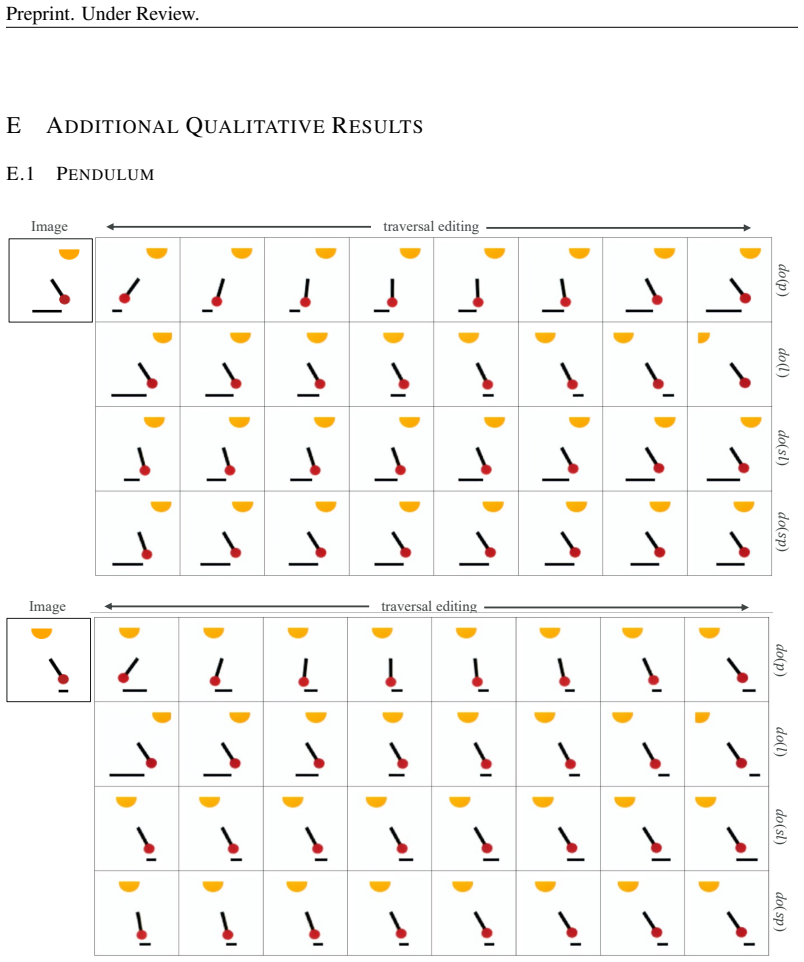
Causal-Adapter adapts frozen text-to-image diffusion backbones for counterfactual image generation. It leverages structural causal modeling together with prompt-aligned injection of causal attributes into textual embeddings and a conditioned token contrastive loss that disentangles factors and reduces spurious correlations. The result supports targeted interventions on chosen attributes while consistently propagating effects to causal dependents and preserving the core identity of the original image.
What carries the argument
Causal-Adapter, which injects a known structural causal model into a frozen diffusion backbone via prompt-aligned injection and a conditioned token contrastive loss to enforce faithful attribute interventions and identity preservation.
If this is right
- Targeted changes to one attribute produce consistent updates to all its causal descendants in the generated image.
- The same frozen diffusion backbone can be reused across different causal graphs by swapping only the adapter components.
- High-fidelity medical images such as MRIs can be edited while keeping patient identity intact.
- Quantitative gains appear on both synthetic benchmarks and real-world datasets without retraining the underlying model.
Where Pith is reading between the lines
- The same adapter pattern could be tested on text-to-video or text-to-3D models if their causal structures are supplied.
- Future work might explore learning the causal graph directly from data instead of requiring it as input.
- If the contrastive loss term is removed, attribute disentanglement would likely degrade on datasets with many interdependent factors.
Load-bearing premise
The method assumes that an accurate structural causal model of the target attributes is already known and can be specified correctly in advance.
What would settle it
Running the method on a dataset where the supplied causal graph is deliberately incorrect and observing that counterfactual accuracy falls to or below the level of ordinary prompt engineering would falsify the central claim.
Figures
























read the original abstract
We present Causal-Adapter, a modular framework that adapts frozen text-to-image diffusion backbones for counterfactual image generation. Our method supports causal interventions on target attributes and consistently propagates their effects to causal dependents while preserving the core identity of the image. Unlike prior approaches that rely on prompt engineering without explicit causal structure, Causal-Adapter leverages structural causal modeling with two attribute-regularization strategies: (i) prompt-aligned injection, which aligns causal attributes with textual embeddings for precise semantic control, and (ii) a conditioned token contrastive loss that disentangles attribute factors and reduces spurious correlations. Causal-Adapter achieves state-of-the-art performance on both synthetic and real-world datasets, including up to a 91% reduction in MAE on Pendulum for accurate attribute control and up to an 87% reduction in FID on ADNI for high-fidelity MRI generation. These results demonstrate robust, generalizable counterfactual editing with faithful attribute modification and strong identity preservation. Code and models will be released at: https://leitong02.github.io/causaladapter/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Causal-Adapter, a modular framework that adapts frozen text-to-image diffusion backbones for counterfactual image generation. It uses structural causal models to support interventions on target attributes, combined with prompt-aligned injection and a conditioned token contrastive loss to propagate effects to causal dependents while preserving image identity. The paper reports state-of-the-art results, including up to 91% MAE reduction on the Pendulum dataset and 87% FID reduction on the ADNI dataset.
Significance. If the empirical claims hold after addressing the noted concerns, the work would advance faithful counterfactual generation in diffusion models by explicitly incorporating causal structure, offering a practical alternative to prompt engineering. The modular adapter design with a frozen backbone is a clear strength for efficient deployment, and the focus on both synthetic and real-world medical imaging datasets highlights potential applicability in causal inference tasks.
major comments (2)
- [Abstract] Abstract: The SOTA performance claims (91% MAE reduction on Pendulum and 87% FID on ADNI) are central to the contribution, yet they rest on the untested assumption that a correctly specified SCM combined with prompt-aligned injection and conditioned token contrastive loss will propagate interventions faithfully through the frozen backbone without new spurious correlations. The manuscript provides no sensitivity analysis or validation of the SCM specification for complex attributes in ADNI.
- [Methods] Methods (regularization strategies): The conditioned token contrastive loss is described as disentangling attribute factors, but it is unclear how this token-level mechanism guarantees image-level causal consistency for downstream dependents. A failure here would mean the reported metrics reflect improved editing rather than true counterfactual faithfulness, directly affecting the central claim.
minor comments (1)
- [Abstract] The abstract would benefit from a short statement on the number of runs or statistical significance for the reported percentage reductions to strengthen the quantitative claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and indicate where revisions will be made to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: The SOTA performance claims (91% MAE reduction on Pendulum and 87% FID on ADNI) are central to the contribution, yet they rest on the untested assumption that a correctly specified SCM combined with prompt-aligned injection and conditioned token contrastive loss will propagate interventions faithfully through the frozen backbone without new spurious correlations. The manuscript provides no sensitivity analysis or validation of the SCM specification for complex attributes in ADNI.
Authors: We acknowledge that the manuscript does not present a dedicated sensitivity analysis for SCM specification on complex ADNI attributes. The SCM is derived from established domain knowledge (e.g., age influencing ventricular volume and cortical thickness). Empirical validation is provided through quantitative metrics (MAE/FID reductions) and qualitative checks showing faithful propagation without obvious spurious artifacts. In revision we will add a dedicated paragraph discussing SCM construction, its assumptions, and limitations for complex attributes. revision: partial
-
Referee: [Methods] Methods (regularization strategies): The conditioned token contrastive loss is described as disentangling attribute factors, but it is unclear how this token-level mechanism guarantees image-level causal consistency for downstream dependents. A failure here would mean the reported metrics reflect improved editing rather than true counterfactual faithfulness, directly affecting the central claim.
Authors: The contrastive loss is applied to prompt tokens that serve as the conditioning signal for the entire diffusion process. By pulling apart embeddings of causally related versus unrelated attribute tokens, it reduces spurious correlations in the latent space that the frozen backbone then uses to synthesize the full image. Because generation is holistic, token-level disentanglement translates to image-level consistency for dependents. We will expand the methods section with a clearer step-by-step explanation of this propagation and reference the ablation results that isolate the loss contribution. revision: partial
Circularity Check
No significant circularity; empirical claims rest on external validation
full rationale
The paper introduces a modular adapter that injects causal interventions into a frozen diffusion backbone via prompt-aligned injection and a conditioned token contrastive loss, assuming a pre-specified SCM. Performance metrics (MAE reduction on Pendulum, FID on ADNI) are reported as experimental outcomes on held-out data rather than quantities algebraically forced by the method's own equations or by self-citation. No derivation step equates a prediction to a fitted input by construction, and the central claims remain falsifiable through independent benchmarks outside the fitted regularization weights.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Image attributes obey a known or specifiable causal graph that can be used to guide interventions.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We assume a known causal graph G encodes the causal relationships among the variables in Y. ... abduction–action–prediction procedure (Pearl, 2013)
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Prompt Aligned Injection (PAI) ... Conditioned Token Contrastive Loss (CTC) ... L = L_DM + λ L_CTC
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Alexander Alemi, Ben Poole, Ian Fischer, Joshua Dillon, Rif A Saurous, and Kevin Murphy. Fixing a broken elbo. In International conference on machine learning, pp.\ 159--168. PMLR, 2018
work page 2018
-
[2]
Instructpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. Instructpix2pix: Learning to follow image editing instructions. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 18392--18402, 2023
work page 2023
-
[3]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In International conference on machine learning, pp.\ 1597--1607. PmLR, 2020
work page 2020
-
[4]
High fidelity image counterfactuals with probabilistic causal models
Fabio De Sousa Ribeiro, Tian Xia, Miguel Monteiro, Nick Pawlowski, and Ben Glocker. High fidelity image counterfactuals with probabilistic causal models. In Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pp.\ 7390--7425, 23--29 Jul 2023. URL https://proceedings.mlr.press/v202/d...
work page 2023
-
[5]
Prompt tuning inversion for text-driven image editing using diffusion models
Wenkai Dong, Song Xue, Xiaoyue Duan, and Shumin Han. Prompt tuning inversion for text-driven image editing using diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp.\ 7430--7440, 2023
work page 2023
-
[6]
An image is worth one word: Personalizing text-to-image generation using textual inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit Haim Bermano, Gal Chechik, and Daniel Cohen-or. An image is worth one word: Personalizing text-to-image generation using textual inversion. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=NAQvF08TcyG
work page 2023
-
[7]
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. Advances in neural information processing systems, 27, 2014
work page 2014
-
[8]
Prompt-to-prompt image editing with cross-attention control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-or. Prompt-to-prompt image editing with cross-attention control. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=_CDixzkzeyb
work page 2023
-
[9]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems, 30, 2017
work page 2017
-
[10]
beta-vae: Learning basic visual concepts with a constrained variational framework
Irina Higgins, Loic Matthey, Arka Pal, Christopher Burgess, Xavier Glorot, Matthew Botvinick, Shakir Mohamed, and Alexander Lerchner. beta-vae: Learning basic visual concepts with a constrained variational framework. In International conference on learning representations, 2017
work page 2017
-
[11]
Classifier-free diffusion guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. In NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021. URL https://openreview.net/forum?id=qw8AKxfYbI
work page 2021
-
[12]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33: 0 6840--6851, 2020
work page 2020
-
[13]
Composer: Creative and controllable image synthesis with composable conditions
Lianghua Huang, Di Chen, Yu Liu, Yujun Shen, Deli Zhao, and Jingren Zhou. Composer: Creative and controllable image synthesis with composable conditions. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett (eds.), Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proce...
work page 2023
-
[14]
Diffusion model-based image editing: A survey
Yi Huang, Jiancheng Huang, Yifan Liu, Mingfu Yan, Jiaxi Lv, Jianzhuang Liu, Wei Xiong, He Zhang, Liangliang Cao, and Shifeng Chen. Diffusion model-based image editing: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[15]
An edit friendly ddpm noise space: Inversion and manipulations
Inbar Huberman-Spiegelglas, Vladimir Kulikov, and Tomer Michaeli. An edit friendly ddpm noise space: Inversion and manipulations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 12469--12478, 2024
work page 2024
-
[16]
Chen Jin, Ryutaro Tanno, Amrutha Saseendran, Tom Diethe, and Philip Alexander Teare. An image is worth multiple words: Discovering object level concepts using multi-concept prompt learning. In Forty-first International Conference on Machine Learning, 2024
work page 2024
-
[17]
Pnp inversion: Boosting diffusion-based editing with 3 lines of code
Xuan Ju, Ailing Zeng, Yuxuan Bian, Shaoteng Liu, and Qiang Xu. Pnp inversion: Boosting diffusion-based editing with 3 lines of code. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=FoMZ4ljhVw
work page 2024
-
[18]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[19]
Dimakis, and Sriram Vishwanath
Murat Kocaoglu, Christopher Snyder, Alexandros G. Dimakis, and Sriram Vishwanath. Causal GAN : Learning causal implicit generative models with adversarial training. In International Conference on Learning Representations, 2018. URL https://openreview.net/forum?id=BJE-4xW0W
work page 2018
-
[20]
Aneesh Komanduri, Xintao Wu, Yongkai Wu, and Feng Chen. From identifiable causal representations to controllable counterfactual generation: A survey on causal generative modeling. Transactions on Machine Learning Research, 2024 a . ISSN 2835-8856. URL https://openreview.net/forum?id=PUpZXvNqmb
work page 2024
-
[21]
Learning causally disentangled representations via the principle of independent causal mechanisms
Aneesh Komanduri, Yongkai Wu, Feng Chen, and Xintao Wu. Learning causally disentangled representations via the principle of independent causal mechanisms. In Kate Larson (ed.), Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI-24 , pp.\ 4308--4316. International Joint Conferences on Artificial Intelligence Or...
-
[22]
Causal diffusion autoencoders: Toward counterfactual generation via diffusion probabilistic models
Aneesh Komanduri, Chen Zhao, Feng Chen, and Xintao Wu. Causal diffusion autoencoders: Toward counterfactual generation via diffusion probabilistic models. European Conference on Artificial Intelligence, 2024 c
work page 2024
-
[23]
Applying guidance in a limited interval improves sample and distribution quality in diffusion models
Tuomas Kynk \"a \"a nniemi, Miika Aittala, Tero Karras, Samuli Laine, Timo Aila, and Jaakko Lehtinen. Applying guidance in a limited interval improves sample and distribution quality in diffusion models. Advances in Neural Information Processing Systems, 37: 0 122458--122483, 2024
work page 2024
-
[24]
Dispose: Disentangling pose guidance for controllable human image animation
Hongxiang Li, Yaowei Li, Yuhang Yang, Junjie Cao, Zhihong Zhu, Xuxin Cheng, and Long Chen. Dispose: Disentangling pose guidance for controllable human image animation. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=AumOa10MKG
work page 2025
-
[25]
Causal representation learning via counterfactual intervention
Xiutian Li, Siqi Sun, and Rui Feng. Causal representation learning via counterfactual intervention. In Proceedings of the AAAI conference on artificial intelligence, volume 38, pp.\ 3234--3242, 2024
work page 2024
-
[26]
Gligen: Open-set grounded text-to-image generation
Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jianwei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee. Gligen: Open-set grounded text-to-image generation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 22511--22521, 2023
work page 2023
-
[27]
Segment anyword: Mask prompt inversion for open-set grounded segmentation
Zhihua Liu, Amrutha Saseendran, Lei Tong, Xilin He, Fariba Yousefi, Nikolay Burlutskiy, Dino Oglic, Tom Diethe, Philip Alexander Teare, Huiyu Zhou, and Chen Jin. Segment anyword: Mask prompt inversion for open-set grounded segmentation. In Forty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=9bzgpYtQZn
work page 2025
-
[28]
Deep learning face attributes in the wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. In Proceedings of International Conference on Computer Vision (ICCV), December 2015
work page 2015
-
[29]
Benchmarking counterfactual image generation
Thomas Melistas, Nikos Spyrou, Nefeli Gkouti, Pedro Sanchez, Athanasios Vlontzos, Yannis Panagakis, Giorgos Papanastasiou, and Sotirios Tsaftaris. Benchmarking counterfactual image generation. Advances in Neural Information Processing Systems, 37: 0 133207--133230, 2024
work page 2024
-
[30]
Negative-prompt inversion: Fast image inversion for editing with text-guided diffusion models
Daiki Miyake, Akihiro Iohara, Yu Saito, and Toshiyuki Tanaka. Negative-prompt inversion: Fast image inversion for editing with text-guided diffusion models. In 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pp.\ 2063--2072. IEEE, 2025
work page 2025
-
[31]
Null-text inversion for editing real images using guided diffusion models
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text inversion for editing real images using guided diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 6038--6047, 2023
work page 2023
-
[32]
Miguel Monteiro, Fabio De Sousa Ribeiro, Nick Pawlowski, Daniel C. Castro, and Ben Glocker. Measuring axiomatic soundness of counterfactual image models. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=lZOUQQvwI3q
work page 2023
-
[33]
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, and Ying Shan. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. In Proceedings of the AAAI conference on artificial intelligence, volume 38, pp.\ 4296--4304, 2024
work page 2024
-
[34]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[35]
Yushu Pan and Elias Bareinboim. Counterfactual image editing. In Forty-first International Conference on Machine Learning, 2024. URL https://openreview.net/forum?id=OXzkw7vFIO
work page 2024
-
[36]
Normalizing flows for probabilistic modeling and inference
George Papamakarios, Eric Nalisnick, Danilo Jimenez Rezende, Shakir Mohamed, and Balaji Lakshminarayanan. Normalizing flows for probabilistic modeling and inference. Journal of Machine Learning Research, 22 0 (57): 0 1--64, 2021
work page 2021
-
[37]
Deep structural causal models for tractable counterfactual inference
Nick Pawlowski, Daniel Coelho de Castro, and Ben Glocker. Deep structural causal models for tractable counterfactual inference. Advances in neural information processing systems, 33: 0 857--869, 2020
work page 2020
- [38]
-
[39]
Judea Pearl. Causal inference. Causality: objectives and assessment, pp.\ 39--58, 2010
work page 2010
-
[40]
Structural counterfactuals: A brief introduction
Judea Pearl. Structural counterfactuals: A brief introduction. Cognitive science, 37 0 (6): 0 977--985, 2013
work page 2013
-
[41]
Alzheimer's disease neuroimaging initiative (adni) clinical characterization
Ronald Carl Petersen, Paul S Aisen, Laurel A Beckett, Michael C Donohue, Anthony Collins Gamst, Danielle J Harvey, CR Jack Jr, William J Jagust, Leslie M Shaw, Arthur W Toga, et al. Alzheimer's disease neuroimaging initiative (adni) clinical characterization. Neurology, 74 0 (3): 0 201--209, 2010
work page 2010
-
[42]
Diffusion autoencoders: Toward a meaningful and decodable representation
Konpat Preechakul, Nattanat Chatthee, Suttisak Wizadwongsa, and Supasorn Suwajanakorn. Diffusion autoencoders: Toward a meaningful and decodable representation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 10619--10629, 2022
work page 2022
-
[43]
Enhancing spatiotemporal disease progression models via latent diffusion and prior knowledge
Lemuel Puglisi, Daniel C Alexander, and Daniele Rav \` . Enhancing spatiotemporal disease progression models via latent diffusion and prior knowledge. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pp.\ 173--183. Springer, 2024
work page 2024
-
[44]
Diffusion counterfactual generation with semantic abduction
Rajat R Rasal, Avinash Kori, Fabio De Sousa Ribeiro, Tian Xia, and Ben Glocker. Diffusion counterfactual generation with semantic abduction. In Forty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=Wqrqcc8O2v
work page 2025
-
[45]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj \"o rn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 10684--10695, 2022
work page 2022
- [46]
-
[47]
Toward causal representation learning
Bernhard Sch \"o lkopf, Francesco Locatello, Stefan Bauer, Nan Rosemary Ke, Nal Kalchbrenner, Anirudh Goyal, and Yoshua Bengio. Toward causal representation learning. Proceedings of the IEEE, 109 0 (5): 0 612--634, 2021
work page 2021
-
[48]
Weakly supervised disentangled generative causal representation learning
Xinwei Shen, Furui Liu, Hanze Dong, Qing Lian, Zhitang Chen, and Tong Zhang. Weakly supervised disentangled generative causal representation learning. Journal of Machine Learning Research, 23 0 (241): 0 1--55, 2022
work page 2022
-
[49]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In International conference on machine learning, pp.\ 2256--2265. pmlr, 2015
work page 2015
-
[50]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. International Conference on Learning Representations, 2021
work page 2021
-
[51]
Causally steered diffusion for automated video counterfactual generation
Nikos Spyrou, Athanasios Vlontzos, Paraskevas Pegios, Thomas Melistas, Nefeli Gkouti, Yannis Panagakis, Giorgos Papanastasiou, and Sotirios A Tsaftaris. Causally steered diffusion for automated video counterfactual generation. arXiv preprint arXiv:2506.14404, 2025
-
[52]
Diff-def: Diffusion-generated deformation fields for conditional atlases
Sophie Starck, Vasiliki Sideri-Lampretsa, Bernhard Kainz, Martin J Menten, Tamara T Mueller, and Daniel Rueckert. Diff-def: Diffusion-generated deformation fields for conditional atlases. IEEE Transactions on Medical Imaging, 2025
work page 2025
-
[53]
Going deeper with convolutions
Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp.\ 1--9, 2015
work page 2015
-
[54]
Nvae: A deep hierarchical variational autoencoder
Arash Vahdat and Jan Kautz. Nvae: A deep hierarchical variational autoencoder. Advances in neural information processing systems, 33: 0 19667--19679, 2020
work page 2020
-
[55]
Concept decomposition for visual exploration and inspiration
Yael Vinker, Andrey Voynov, Daniel Cohen-Or, and Ariel Shamir. Concept decomposition for visual exploration and inspiration. ACM Transactions on Graphics (TOG), 42 0 (6): 0 1--13, 2023
work page 2023
-
[56]
Causality from bottom to top: a survey
Abraham Itzhak Weinberg, Cristiano Premebida, and Diego Resende Faria. Causality from bottom to top: a survey. arXiv preprint arXiv:2403.11219, 2024
-
[57]
Learning likelihoods with conditional normalizing flows, 2020
Christina Winkler, Daniel Worrall, Emiel Hoogeboom, and Max Welling. Learning likelihoods with conditional normalizing flows, 2020. URL https://openreview.net/forum?id=rJg3zxBYwH
work page 2020
-
[58]
Counterfactual generative modeling with variational causal inference
Yulun Wu, Louie McConnell, and Claudia Iriondo. Counterfactual generative modeling with variational causal inference. International Conference on Learning Representations, 2025
work page 2025
-
[59]
Factored Classifier-Free Guidance
Tian Xia, Fabio De Sousa Ribeiro, Rajat R Rasal, Avinash Kori, Raghav Mehta, and Ben Glocker. Decoupled classifier-free guidance for counterfactual diffusion models. arXiv preprint arXiv:2506.14399, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Inversion-free image editing with language-guided diffusion models
Sihan Xu, Yidong Huang, Jiayi Pan, Ziqiao Ma, and Joyce Chai. Inversion-free image editing with language-guided diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 9452--9461, 2024
work page 2024
-
[61]
Causalvae: Disentangled representation learning via neural structural causal models
Mengyue Yang, Furui Liu, Zhitang Chen, Xinwei Shen, Jianye Hao, and Jun Wang. Causalvae: Disentangled representation learning via neural structural causal models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 9593--9602, 2021
work page 2021
-
[62]
Diffusion model with cross attention as an inductive bias for disentanglement
Tao Yang, Cuiling Lan, Yan Lu, and Nanning Zheng. Diffusion model with cross attention as an inductive bias for disentanglement. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[63]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, pp.\ 3836--3847, 2023
work page 2023
-
[64]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp.\ 586--595, 2018
work page 2018
-
[65]
Uni-controlnet: All-in-one control to text-to-image diffusion models
Shihao Zhao, Dongdong Chen, Yen-Chun Chen, Jianmin Bao, Shaozhe Hao, Lu Yuan, and Kwan-Yee K Wong. Uni-controlnet: All-in-one control to text-to-image diffusion models. Advances in Neural Information Processing Systems, 36: 0 11127--11150, 2023
work page 2023
-
[66]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[67]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[68]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[69]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.