Rethinking Parameter Sharing for LLM Fine-Tuning with Multiple LoRAs
Pith reviewed 2026-05-18 11:55 UTC · model grok-4.3
The pith
Similarity among LoRA A matrices comes mainly from identical initialization, so sharing the B matrix instead produces more balanced multi-task performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
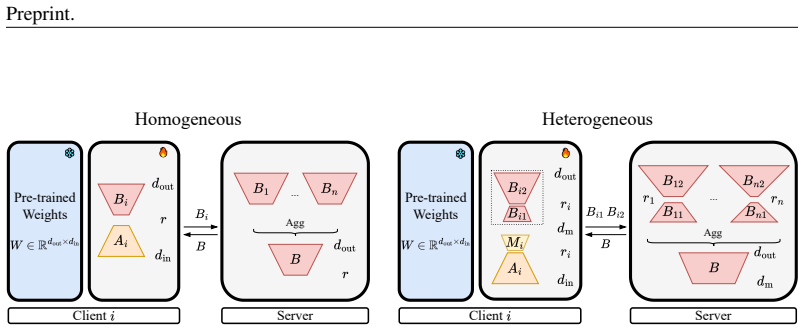
The high similarity observed among the A matrices of multiple LoRAs is largely attributable to their identical initialization rather than to the acquisition of shared knowledge. The B matrix plays a more critical role in knowledge encoding and transfer. This insight motivates the proposal of ALoRA, an asymmetric multi-LoRA design featuring multiple A matrices and a single shared B for multi-task fine-tuning, and Fed-ALoRA, which shares B across clients in federated fine-tuning using a novel matrix decomposition strategy to handle heterogeneous ranks.
What carries the argument
ALoRA asymmetric multi-LoRA design that keeps multiple distinct A matrices while sharing a single B matrix (extended to Fed-ALoRA with decomposition for heterogeneous ranks)
Load-bearing premise
The high similarity among A matrices during training is caused primarily by identical initialization and does not reflect meaningful shared knowledge acquisition.
What would settle it
Running multi-task training where each A matrix receives a distinctly different initialization yet still converges to high similarity would contradict the claim that initialization is the dominant cause.
Figures








read the original abstract
Large language models are often adapted using parameter-efficient techniques such as Low-Rank Adaptation (LoRA), formulated as $y = W_0x + BAx$, where $W_0$ is the pre-trained parameters and $x$ is the input to the adapted layer. While multi-adapter extensions often employ multiple LoRAs, prior studies suggest that the inner $A$ matrices are highly similar during training and thus suitable for sharing. We revisit this phenomenon and find that this similarity is largely attributable to the identical initialization rather than shared knowledge, with $B$ playing a more critical role in knowledge encoding and transfer. Motivated by these insights, we propose \textbf{ALoRA}, an asymmetric multi-LoRA design with multiple $A$ matrices and a single shared $B$ in multi-task fine-tuning, and \textbf{Fed-ALoRA}, which shares $B$ across clients in federated fine-tuning under both homogeneous and heterogeneous settings, through a novel matrix decomposition strategy to accommodate heterogeneous ranks across clients. Experiments on commonsense reasoning, math reasoning, multi-task NLP dataset, and federated NLP dataset demonstrate that our methods achieve more balanced performance across tasks with comparable or superior average accuracy relative to existing multi-LoRA approaches. The code is available at https://github.com/OptMN-Lab/ALoRA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper revisits the high similarity observed among A matrices in multi-LoRA fine-tuning of LLMs and attributes it primarily to identical initialization rather than shared knowledge acquisition, concluding that B plays a more critical role in knowledge encoding and transfer. Motivated by this, it introduces ALoRA (multiple independent A matrices with a single shared B) for multi-task fine-tuning and Fed-ALoRA (with a novel matrix decomposition for heterogeneous ranks) for federated settings. Experiments across commonsense reasoning, math reasoning, multi-task NLP, and federated NLP benchmarks report more balanced per-task performance with comparable or superior average accuracy relative to prior multi-LoRA methods.
Significance. If the empirical findings hold under stronger controls, the asymmetric sharing insight could meaningfully influence efficient multi-adapter and federated LLM adaptation practices by improving task balance without sacrificing average performance. The public code release supports reproducibility, which strengthens the contribution.
major comments (2)
- [Motivation section and experimental analysis of matrix similarity] The central motivation—that A-matrix similarity during training is largely attributable to identical initialization rather than task-induced shared knowledge—requires a control experiment initializing the A matrices from independent random seeds while training on the same data. Without this contrast (reported only under the default identical-init regime), the attribution remains correlational and does not rule out gradient-driven alignment, directly weakening the rationale for preferring to share B over A. This is load-bearing for the design of ALoRA and Fed-ALoRA.
- [Experiments section] Table reporting per-task and average accuracies (and any associated ablation tables) should include statistical significance tests, standard deviations across runs, and precise descriptions of baseline implementations and hyperparameter matching to substantiate the claims of 'more balanced performance' and 'comparable or superior average accuracy'.
minor comments (2)
- [Fed-ALoRA description] Clarify the exact matrix decomposition strategy used in Fed-ALoRA to accommodate heterogeneous ranks; a small illustrative example or equation would improve readability.
- [Figures] Ensure all figures showing matrix similarity or performance comparisons include axis labels, legends, and error bars where appropriate.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the motivation and experimental rigor of our work. We address each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Motivation section and experimental analysis of matrix similarity] The central motivation—that A-matrix similarity during training is largely attributable to identical initialization rather than task-induced shared knowledge—requires a control experiment initializing the A matrices from independent random seeds while training on the same data. Without this contrast (reported only under the default identical-init regime), the attribution remains correlational and does not rule out gradient-driven alignment, directly weakening the rationale for preferring to share B over A. This is load-bearing for the design of ALoRA and Fed-ALoRA.
Authors: We agree that a control experiment with independently initialized A matrices (different random seeds) while training on identical data would provide stronger causal evidence distinguishing initialization effects from gradient-driven alignment. In the revised manuscript, we will add this experiment, report the resulting cosine similarities, and update the motivation section to reference these results directly supporting the preference for sharing B. revision: yes
-
Referee: [Experiments section] Table reporting per-task and average accuracies (and any associated ablation tables) should include statistical significance tests, standard deviations across runs, and precise descriptions of baseline implementations and hyperparameter matching to substantiate the claims of 'more balanced performance' and 'comparable or superior average accuracy'.
Authors: We acknowledge that adding statistical details will improve the robustness of our claims. In the revised manuscript, we will update all relevant tables (including per-task accuracies, averages, and ablations) to report standard deviations over multiple runs, include statistical significance tests (e.g., paired t-tests with p-values), and expand the experimental setup section with precise baseline implementation details and hyperparameter matching procedures. revision: yes
Circularity Check
No significant circularity; empirical claims are self-contained
full rationale
The paper's central argument rests on experimental observations of LoRA matrix similarity under identical initialization, followed by the proposal of ALoRA and Fed-ALoRA designs validated through comparative accuracy metrics on multiple reasoning and NLP tasks. No derivation chain, fitted parameter, or prediction reduces to its own inputs by construction. The attribution of similarity to initialization is presented as an empirical finding rather than a self-definitional or self-citation load-bearing step, and the method choices follow directly from those reported results without tautological renaming or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The low-rank update form of LoRA is sufficient to capture task adaptation.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Ale- man, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Hao Ban, Gokul Ram Subramani, and Kaiyi Ji. Samo: A lightweight sharpness-aware approach for multi-task optimization with joint global-local perturbation.arXiv preprint arXiv:2507.07883,
-
[3]
Jieming Bian, Lei Wang, Letian Zhang, and Jie Xu. Fedalt: Federated fine-tuning through adaptive local training with rest-of-world lora.arXiv preprint arXiv:2503.11880,
-
[4]
Weiyu Chen, Baijiong Lin, Xiaoyuan Zhang, Xi Lin, Han Zhao, Qingfu Zhang, and James T Kwok. Gradient-based multi-objective deep learning: Algorithms, theories, applications, and beyond. arXiv preprint arXiv:2501.10945,
-
[5]
Heterogeneous lora for fed- erated fine-tuning of on-device foundation models
Yae Jee Cho, Luyang Liu, Zheng Xu, Aldi Fahrezi, and Gauri Joshi. Heterogeneous lora for fed- erated fine-tuning of on-device foundation models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 12903–12913,
work page 2024
-
[6]
Boolq: Exploring the surprising difficulty of natural yes/no questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational 10 Preprint. Linguistics: Human Language Technologies, Volume 1 (Long and Sh...
work page 2019
-
[7]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capa- bilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
URLhttps://www.databricks.com/blog/2023/04/ 12/dolly-first-open-commercially-viable-instruction-tuned-llm. Dongshang Deng, Xuangou Wu, Tao Zhang, Xiangyun Tang, Hongyang Du, Jiawen Kang, Jiqiang Liu, and Dusit Niyato. Fedasa: A personalized federated learning with adaptive model aggrega- tion for heterogeneous mobile edge computing.IEEE Transactions on Mo...
work page 2023
-
[11]
Loramoe: Alleviating world knowledge forgetting in large language models via moe-style plugin
Shihan Dou, Enyu Zhou, Yan Liu, Songyang Gao, Wei Shen, Limao Xiong, Yuhao Zhou, Xiao Wang, Zhiheng Xi, Xiaoran Fan, et al. Loramoe: Alleviating world knowledge forgetting in large language models via moe-style plugin. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 1932–1945,
work page 1932
-
[12]
Llm-adapters: An adapter family for parameter-efficient fine-tuning of large language models
Zhiqiang Hu, Lei Wang, Yihuai Lan, Wanyu Xu, Ee-Peng Lim, Lidong Bing, Xing Xu, Soujanya Poria, and Roy Lee. Llm-adapters: An adapter family for parameter-efficient fine-tuning of large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Lan- guage Processing, pp. 5254–5276,
work page 2023
-
[13]
Mawps: A math word problem repository
Rik Koncel-Kedziorski, Subhro Roy, Aida Amini, Nate Kushman, and Hannaneh Hajishirzi. Mawps: A math word problem repository. InProceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technolo- gies, pp. 1152–1157,
work page 2016
-
[14]
The power of scale for parameter-efficient prompt tuning
Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Pro- cessing, pp. 3045–3059,
work page 2021
-
[15]
arXiv preprint arXiv:2008.03371 , year=
Ang Li, Jingwei Sun, Binghui Wang, Lin Duan, Sicheng Li, Yiran Chen, and Hai Li. Lotteryfl: Personalized and communication-efficient federated learning with lottery ticket hypothesis on non-iid datasets.arXiv preprint arXiv:2008.03371, 2020a. Dengchun Li, Yingzi Ma, Naizheng Wang, Zhengmao Ye, Zhiyuan Cheng, Yinghao Tang, Yan Zhang, Lei Duan, Jie Zuo, Cal...
-
[16]
Dynmole: Boosting mixture of lora experts fine-tuning with a hybrid routing mechanism
Dengchun Li, Naizheng Wang, Zihao Zhang, Haoyang Yin, Lei Duan, Meng Xiao, and Mingjie Tang. Dynmole: Boosting mixture of lora experts fine-tuning with a hybrid routing mechanism. arXiv preprint arXiv:2504.00661, 2025a. 12 Preprint. Tian Li, Maziar Sanjabi, Ahmad Beirami, and Virginia Smith. Fair resource allocation in federated learning. InInternational ...
-
[17]
Youqi Li, Fan Li, Song Yang, and Yu Wang. Bgefl: Enabling communication-efficient federated learning via bandit gradient estimation in resource-constrained networks.IEEE Transactions on Networking, 2025b. Jian Liang, Wenke Huang, Xianda Guo, Guancheng Wan, Bo Du, and Mang Ye. Thanora: Task heterogeneity-aware multi-task low-rank adaptation.arXiv preprint ...
-
[18]
Tongxu Luo, Jiahe Lei, Fangyu Lei, Weihao Liu, Shizhu He, Jun Zhao, and Kang Liu. Moelora: Contrastive learning guided mixture of experts on parameter-efficient fine-tuning for large lan- guage models.arXiv preprint arXiv:2402.12851,
-
[19]
Can a suit of armor conduct elec- tricity? a new dataset for open book question answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct elec- tricity? a new dataset for open book question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp. 2381–2391,
work page 2018
-
[20]
Arkil Patel, Satwik Bhattamishra, and Navin Goyal. Are nlp models really able to solve simple math word problems? InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 2080–2094,
work page 2021
-
[21]
Improving multi-task learning via seeking task-based flat regions.arXiv preprint arXiv:2211.13723,
Hoang Phan, Lam Tran, Ngoc N Tran, Nhat Ho, Dinh Phung, and Trung Le. Improving multi-task learning via seeking task-based flat regions.arXiv preprint arXiv:2211.13723,
-
[22]
Ravan: Multi-head low-rank adaptation for federated fine-tuning.arXiv preprint arXiv:2506.05568,
Arian Raje, Baris Askin, Divyansh Jhunjhunwala, and Gauri Joshi. Ravan: Multi-head low-rank adaptation for federated fine-tuning.arXiv preprint arXiv:2506.05568,
-
[23]
Social iqa: Common- sense reasoning about social interactions
Maarten Sap, Hannah Rashkin, Derek Chen, Ronan Le Bras, and Yejin Choi. Social iqa: Common- sense reasoning about social interactions. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473,
work page 2019
-
[24]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Niko- lay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open founda- tion and fine-tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Aprompt: Attention prompt tuning for efficient adaptation of pre-trained language models
Qifan Wang, Yuning Mao, Jingang Wang, Hanchao Yu, Shaoliang Nie, Sinong Wang, Fuli Feng, Lifu Huang, Xiaojun Quan, Zenglin Xu, et al. Aprompt: Attention prompt tuning for efficient adaptation of pre-trained language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 9147–9160,
work page 2023
-
[26]
Mixture-of-subspaces in low-rank adapta- tion
Taiqiang Wu, Jiahao Wang, Zhe Zhao, and Ngai Wong. Mixture-of-subspaces in low-rank adapta- tion. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Pro- cessing, pp. 7880–7899, 2024a. Xun Wu, Shaohan Huang, and Furu Wei. Mixture of lora experts. InThe Twelfth International Conference on Learning Representations, 2024b. Peiyao X...
work page 2024
-
[27]
Low-rank adaptation for foundation models: A comprehensive review.arXiv preprint arXiv:2501.00365,
Menglin Yang, Jialin Chen, Yifei Zhang, Jiahong Liu, Jiasheng Zhang, Qiyao Ma, Harshit Verma, Qianru Zhang, Min Zhou, Irwin King, et al. Low-rank adaptation for foundation models: A comprehensive review.arXiv preprint arXiv:2501.00365,
-
[28]
Dacao Zhang, Kun Zhang, Shimao Chu, Le Wu, Xin Li, and Si Wei. More: A mixture of low-rank experts for adaptive multi-task learning.arXiv preprint arXiv:2505.22694, 2025a. 15 Preprint. Jianyi Zhang, Saeed Vahidian, Martin Kuo, Chunyuan Li, Ruiyi Zhang, Tong Yu, Guoyin Wang, and Yiran Chen. Towards building the federatedgpt: Federated instruction tuning. I...
-
[29]
To- wards adaptive prefix tuning for parameter-efficient language model fine-tuning
Zhen-Ru Zhang, Chuanqi Tan, Haiyang Xu, Chengyu Wang, Jun Huang, and Songfang Huang. To- wards adaptive prefix tuning for parameter-efficient language model fine-tuning. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pp. 1239–1248, 2023b. Zikai Zhang, Ping Liu, Jiahao Xu, and Rui Hu. Fed...
-
[30]
Delta-lora: Fine- tuning high-rank parameters with the delta of low-rank matrices
Bojia Zi, Xianbiao Qi, Lingzhi Wang, Jianan Wang, Kam-Fai Wong, and Lei Zhang. Delta- lora: Fine-tuning high-rank parameters with the delta of low-rank matrices.arXiv preprint arXiv:2309.02411,
-
[31]
SUPPLEMENTARYMATERIALS A ADDITIONALRELATEDWORK Parameter-efficient fine-tuning
16 Preprint. SUPPLEMENTARYMATERIALS A ADDITIONALRELATEDWORK Parameter-efficient fine-tuning. PEFT adapts large language models (LLM) by training only a small subset of parameters, significantly reducing the computation cost while maintaining the per- formance compared to full fine-tuning. Existing PEFT methods are typically categorized into the following ...
work page 2019
-
[32]
and gradient weighting approaches, such as MGDA (D ´esid´eri, 2012; Sener & Koltun,
work page 2012
-
[33]
and its variants (Liu et al., 2021; Xiao et al., 2023; Fernando et al., 2023; Chen et al., 2023; Zhang et al., 2025b; Wang et al., 2025a), which apply multi-objective optimization to explore Pareto-optimal solutions for balancing gradient conflicts. Other methods examine MTL from the perspective of label noise (He et al., 2024), fairness (Navon et al., 20...
work page 2021
-
[34]
or analyze the sharpness of the loss landscape (Phan et al., 2022; Ban et al., 2025). Federated learning. FL allows multiple clients to train collaboratively in a decentralized setting while preserving data privacy by keeping raw data local. In each communication round, clients compute local updates on their private data and send only these updates (e.g.,...
work page 2022
-
[35]
10.0% CloQA 40.1% GenQA50.0% IE 24.8% OpnQA 25.3% Figure 7: Data distribution of clients
Sum.50.0% Clf. 10.0% CloQA 40.1% GenQA50.0% IE 24.8% OpnQA 25.3% Figure 7: Data distribution of clients. Left: Client 1 contains Closed QA, Summarization, and Classification tasks. Right: Client 2 contains Open QA, General QA, and Information Extraction tasks. We fine-tune the LLaMA2-7B model on the two clients and analyze how the similarity of LoRA modul...
work page 2025
-
[36]
The methods are applied toq proj andv proj modules
In the heterogeneous setting, the ranks are set to{64,64,32,32,16,16,8,8}. The methods are applied toq proj andv proj modules. All experiments are conducted on RTX A6000 GPU. C ADDITIONALEXPERIMENTALDETAILS ANDRESULTS C.1 BENCHMARKS The intra-domain multi-task commonsense reasoning 170K benchmark contains questions from the following datasets: (1) ARC-Cha...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.