DeepSearch: Overcome the Bottleneck of Reinforcement Learning with Verifiable Rewards via Monte Carlo Tree Search
Pith reviewed 2026-05-18 12:09 UTC · model grok-4.3
The pith
Integrating Monte Carlo Tree Search into RLVR training overcomes sparse exploration to raise math reasoning accuracy while cutting GPU hours by a factor of 5.7.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
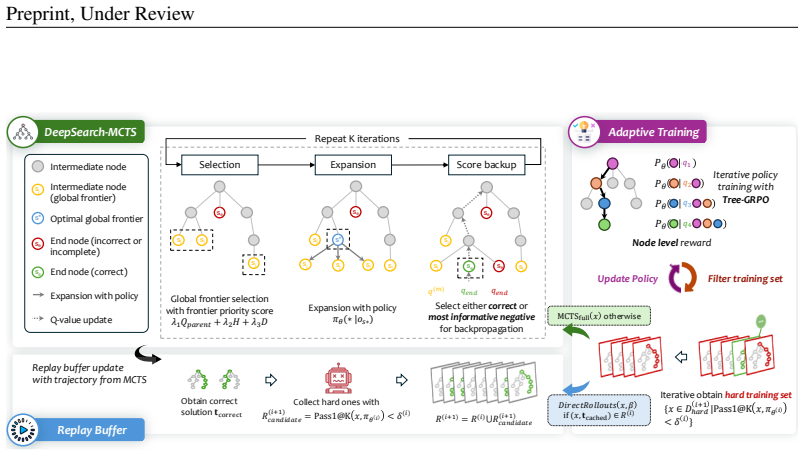
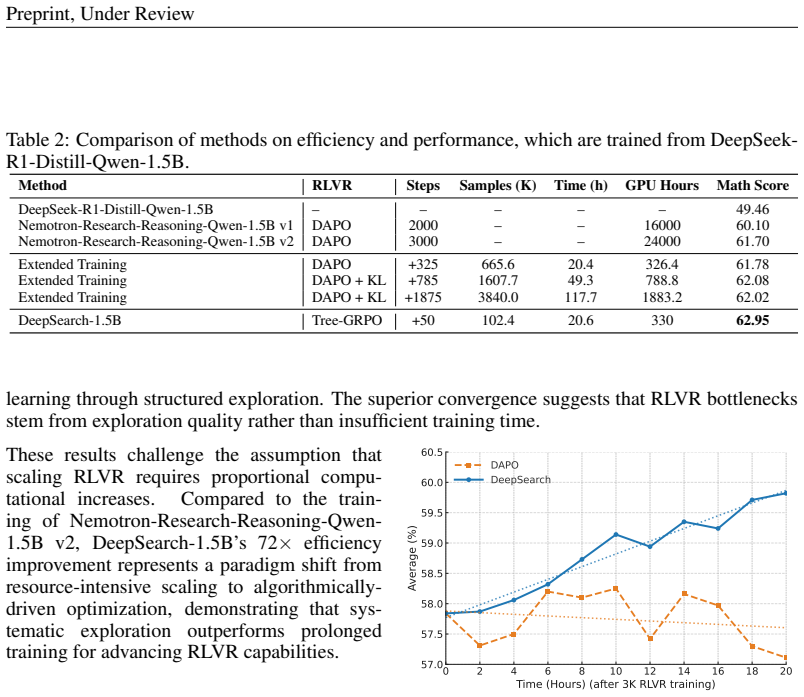
DeepSearch embeds Monte Carlo Tree Search directly into the RLVR training loop. It uses a global frontier selection strategy that prioritizes promising nodes across the entire search tree, entropy-based guidance to identify confident paths for supervision, and adaptive replay buffer training with solution caching. These changes produce systematic exploration and fine-grained credit assignment across reasoning steps, directly addressing the sparse exploration that causes performance plateaus after thousands of optimization steps. The approach yields 62.95 percent average accuracy on mathematical reasoning benchmarks and a new state-of-the-art model while requiring 5.7 times fewer GPU hours.
What carries the argument
Monte Carlo Tree Search placed inside the RLVR training loop and equipped with global frontier selection, entropy-based path guidance, and an adaptive replay buffer that caches solutions.
If this is right
- Training-time tree search supplies broader coverage of critical reasoning paths than the limited rollouts used in ordinary RLVR.
- Fine-grained credit assignment across individual steps improves learning on long or branched solution sequences.
- New state-of-the-art accuracy on math benchmarks is reached without extending the number of optimization steps.
- Scaling reasoning performance becomes possible through targeted search algorithms rather than simply increasing total compute.
Where Pith is reading between the lines
- The same training-time search structure could be tested on non-mathematical domains such as code synthesis or multi-step scientific reasoning.
- Hybrid search-plus-RL loops might reduce reliance on ever-larger model scale for continued capability gains.
- Entropy guidance may also limit overfitting to narrow families of solutions during extended training.
Load-bearing premise
The listed MCTS strategies together reliably fix the sparse exploration problem in RLVR without creating new failure modes or benchmark-specific artifacts.
What would settle it
A controlled replication on the same math reasoning benchmarks that shows no accuracy gain over standard extended RLVR or that the reported GPU-hour savings disappear.
Figures
read the original abstract
Although RLVR has become an essential component for developing advanced reasoning skills in language models, contemporary studies have documented training plateaus after thousands of optimization steps, i.e., notable decreases in performance gains despite increased computational investment. This limitation stems from the sparse exploration patterns inherent in current RLVR practices, where models rely on limited rollouts that often miss critical reasoning paths and fail to provide systematic coverage of the solution space. We present DeepSearch, a framework that integrates Monte Carlo Tree Search (MCTS) directly into RLVR training. In contrast to existing methods that rely on tree search only at inference, DeepSearch embeds structured search into the training loop, enabling systematic exploration and fine-grained credit assignment across reasoning steps. Through training-time exploration, DeepSearch addresses the fundamental bottleneck of insufficient exploration, which leads to diminishing performance gains over prolonged training. Our contributions include: (1) a global frontier selection strategy that prioritizes promising nodes across the search tree, (2) selection with entropy-based guidance that identifies confident paths for supervision, and (3) adaptive replay buffer training with solution caching for efficiency. Experiments on mathematical reasoning benchmarks show that DeepSearch achieves an average accuracy of 62.95\% and establishes a new state-of-the-art reasoning model, while using 5.7x fewer GPU hours than extended training approaches. These results highlight the importance of strategic exploration over brute-force scaling and demonstrate the promise of algorithmic innovation for advancing RLVR methodologies. DeepSearch establishes a new direction for scaling reasoning capabilities through systematic search rather than prolonged computation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DeepSearch, a framework embedding Monte Carlo Tree Search (MCTS) into the RLVR training loop for language models. It introduces three strategies—global frontier selection, entropy-based guidance, and adaptive replay buffer with solution caching—to enable systematic exploration and fine-grained credit assignment, addressing training plateaus from sparse rollouts. Experiments on mathematical reasoning benchmarks report 62.95% average accuracy (new SOTA) and 5.7x fewer GPU hours than extended RLVR training.
Significance. If the results hold under controlled conditions, the work offers a concrete path to improve RLVR efficiency by replacing brute-force scaling with structured search during training. The shift from inference-only tree search to training-time integration is a substantive algorithmic contribution that could reduce compute demands for reasoning model development.
major comments (2)
- The central efficiency and exploration claims require a control experiment that matches total search budget (nodes expanded or rollouts) between DeepSearch and a plain RLVR baseline; without it, gains cannot be isolated from increased exploration effort rather than the listed MCTS strategies.
- §4 (Experiments): the reported 62.95% average accuracy and SOTA status lack per-benchmark breakdowns, run-to-run variance, and statistical tests; these details are load-bearing for the claim that the method systematically overcomes the RLVR bottleneck.
minor comments (2)
- Clarify the precise interaction between the adaptive replay buffer and MCTS node caching to support reproducibility of the training loop.
- Specify the exact mathematical reasoning benchmarks (e.g., GSM8K, MATH, AIME) and their individual accuracies rather than only the aggregate figure.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment point by point below, indicating the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: The central efficiency and exploration claims require a control experiment that matches total search budget (nodes expanded or rollouts) between DeepSearch and a plain RLVR baseline; without it, gains cannot be isolated from increased exploration effort rather than the listed MCTS strategies.
Authors: We agree that isolating the contribution of the proposed MCTS strategies from differences in total exploration effort is important for substantiating the efficiency claims. Our current comparisons focus on GPU-hour savings relative to extended RLVR training, but to directly address this point we will add a new control experiment in the revised manuscript. This experiment will equate the total search budget (measured by nodes expanded or equivalent rollouts) between DeepSearch and a plain RLVR baseline, thereby demonstrating that performance gains derive from global frontier selection, entropy-based guidance, and adaptive replay rather than simply increased search volume. revision: yes
-
Referee: §4 (Experiments): the reported 62.95% average accuracy and SOTA status lack per-benchmark breakdowns, run-to-run variance, and statistical tests; these details are load-bearing for the claim that the method systematically overcomes the RLVR bottleneck.
Authors: We concur that additional experimental details are required to robustly support the average accuracy and SOTA claims. In the revised Section 4 we will include a comprehensive table reporting per-benchmark accuracies across all evaluated mathematical reasoning datasets. We will also report run-to-run variance via standard deviations computed over multiple independent training runs and will add statistical significance tests (such as paired t-tests) against the RLVR baselines to confirm that the observed improvements systematically address the training plateau. revision: yes
Circularity Check
No circularity: empirical algorithmic claims validated on external benchmarks
full rationale
The paper presents DeepSearch as an algorithmic integration of MCTS into RLVR training loops, with listed strategies (global frontier selection, entropy-based guidance, adaptive replay buffer) and reports empirical results on mathematical reasoning benchmarks (62.95% average accuracy, 5.7x fewer GPU hours). No load-bearing derivation, equation, or prediction reduces by construction to fitted inputs, self-definitions, or self-citation chains; performance gains are framed as outcomes of structured exploration tested against external benchmarks rather than tautological renamings or ansatzes smuggled via prior work. The central claim remains independent of the reported metrics and is self-contained against verifiable external evaluation.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
global frontier selection strategy that prioritizes promising nodes across the search tree... entropy-based guidance... adaptive replay buffer training with solution caching
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Tree-GRPO training objective... q-value soft clipping... mean-only Advantages Normalization
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
Maximizing Rollout Informativeness under a Fixed Budget: A Submodular View of Tree Search for Tool-Use Agentic Reinforcement Learning
InfoTree casts intermediate state selection in tree search as monotone submodular maximization under fixed rollout budgets, yielding closed-form UUCB terms and lifting mixed-outcome ratios while outperforming flat GRP...
-
ResRL: Boosting LLM Reasoning via Negative Sample Projection Residual Reinforcement Learning
ResRL decouples shared semantics between positive and negative responses in LLM reinforcement learning via SVD-based projection residuals, outperforming baselines including NSR by up to 9.4% on math reasoning benchmarks.
-
Generate, Filter, Control, Replay: A Comprehensive Survey of Rollout Strategies for LLM Reinforcement Learning
This survey introduces the Generate-Filter-Control-Replay (GFCR) taxonomy to structure rollout pipelines for RL-based post-training of reasoning LLMs.
-
ResRL: Boosting LLM Reasoning via Negative Sample Projection Residual Reinforcement Learning
ResRL boosts LLM reasoning by modulating negative gradients with SVD-based projection residuals from negative samples, outperforming NSR by 9.4% Avg@16 on math benchmarks while preserving diversity across 12 tasks.
Reference graph
Works this paper leans on
-
[1]
Intern-s1: A scientific multimodal foundation model.arXiv preprint arXiv:2508.15763, 2025
Lei Bai, Zhongrui Cai, Maosong Cao, Weihan Cao, Chiyu Chen, Haojiong Chen, Kai Chen, Pengcheng Chen, Ying Chen, Yongkang Chen, et al. Intern-s1: A scientific multimodal foun- dation model.arXiv preprint arXiv:2508.15763,
-
[2]
Michael Bereket and Jure Leskovec. Uncalibrated reasoning: Grpo induces overconfidence for stochastic outcomes.arXiv preprint arXiv:2508.11800,
-
[3]
Zhenni Bi, Kai Han, Chuanjian Liu, Yehui Tang, and Yunhe Wang. Forest-of-thought: Scaling test-time compute for enhancing llm reasoning.arXiv preprint arXiv:2412.09078,
-
[4]
arXiv preprint arXiv:2504.02546 , year=
Xiangxiang Chu, Hailang Huang, Xiao Zhang, Fei Wei, and Yong Wang. Gpg: A simple and strong reinforcement learning baseline for model reasoning.arXiv preprint arXiv:2504.02546,
-
[5]
Reinforcement learning for reasoning in small llms: What works and what doesn’t
Quy-Anh Dang and Chris Ngo. Reinforcement learning for reasoning in small llms: What works and what doesn’t.arXiv preprint arXiv:2503.16219,
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
URLhttps://arxiv.org/abs/2501.12948. Alhussein Fawzi, Matej Balog, Aja Huang, Thomas Hubert, Bernardino Romera-Paredes, Moham- madamin Barekatain, Alexander Novikov, Francisco J R. Ruiz, Julian Schrittwieser, Grzegorz Swirszcz, et al. Discovering faster matrix multiplication algorithms with reinforcement learning. Nature, 610(7930):47–53,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking
Xinyu Guan, Li Lyna Zhang, Yifei Liu, Ning Shang, Youran Sun, Yi Zhu, Fan Yang, and Mao Yang. rstar-math: Small llms can master math reasoning with self-evolved deep thinking.arXiv preprint arXiv:2501.04519,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Anisha Gunjal, Anthony Wang, Elaine Lau, Vaskar Nath, Bing Liu, and Sean Hendryx. Rubrics as rewards: Reinforcement learning beyond verifiable domains.arXiv preprint arXiv:2507.17746,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems.arXiv preprint arXiv:2402.14008,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Skywork Open Reasoner 1 Technical Report
Jujie He, Jiacai Liu, Chris Yuhao Liu, Rui Yan, Chaojie Wang, Peng Cheng, Xiaoyu Zhang, Fuxiang Zhang, Jiacheng Xu, Wei Shen, et al. Skywork open reasoner 1 technical report.arXiv preprint arXiv:2505.22312, 2025a. Shenghua He, Tian Xia, Xuan Zhou, and Hui Wei. Response-level rewards are all you need for online reinforcement learning in llms: A mathematica...
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Andreas Hochlehnert, Hardik Bhatnagar, Vishaal Udandarao, Samuel Albanie, Ameya Prabhu, and Matthias Bethge. A sober look at progress in language model reasoning: Pitfalls and paths to reproducibility.arXiv preprint arXiv:2504.07086,
-
[12]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Marco Kemmerling, Daniel L¨utticke, and Robert H Schmitt. Beyond games: a systematic review of neural monte carlo tree search applications.arXiv preprint arXiv:2303.08060,
-
[14]
ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models
Mingjie Liu, Shizhe Diao, Ximing Lu, Jian Hu, Xin Dong, Yejin Choi, Jan Kautz, and Yi Dong. Prorl: Prolonged reinforcement learning expands reasoning boundaries in large language models. arXiv preprint arXiv:2505.24864, 2025a. 11 Preprint, Under Review Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Underst...
work page internal anchor Pith review arXiv
-
[15]
Zhenting Qi, Mingyuan Ma, Jiahang Xu, Li Lyna Zhang, Fan Yang, and Mao Yang. Mutual reason- ing makes smaller llms stronger problem-solvers.arXiv preprint arXiv:2408.06195,
-
[16]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Yi Su, Dian Yu, Linfeng Song, Juntao Li, Haitao Mi, Zhaopeng Tu, Min Zhang, and Dong Yu. Crossing the reward bridge: Expanding rl with verifiable rewards across diverse domains.arXiv preprint arXiv:2503.23829,
-
[19]
URLhttps://github.com/RUCAIBox/Slow_ Thinking_with_LLMs. Harshil Vagadia, Mudit Chopra, Abhinav Barnawal, Tamajit Banerjee, Shreshth Tuli, Souvik Chakraborty, and Rohan Paul. Phyplan: Compositional and adaptive physical task reasoning with physics-informed skill networks for robot manipulators.arXiv preprint arXiv:2402.15767,
-
[20]
Zhongwei Wan, Zhihao Dou, Che Liu, Yu Zhang, Dongfei Cui, Qinjian Zhao, Hui Shen, Jing Xiong, Yi Xin, Yifan Jiang, et al. Srpo: Enhancing multimodal llm reasoning via reflection-aware rein- forcement learning.arXiv preprint arXiv:2506.01713,
-
[21]
12 Preprint, Under Review Peisong Wang, Ruotian Ma, Bang Zhang, Xingyu Chen, Zhiwei He, Kang Luo, Qingsong Lv, Qingxuan Jiang, Zheng Xie, Shanyi Wang, et al. Rlver: Reinforcement learning with verifiable emotion rewards for empathetic agents.arXiv preprint arXiv:2507.03112, 2025a. Peiyi Wang, Lei Li, Zhihong Shao, RX Xu, Damai Dai, Yifei Li, Deli Chen, Yu...
-
[22]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdh- ery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
Yiping Wang, Qing Yang, Zhiyuan Zeng, Liliang Ren, Liyuan Liu, Baolin Peng, Hao Cheng, Xuehai He, Kuan Wang, Jianfeng Gao, et al. Reinforcement learning for reasoning in large language models with one training example.arXiv preprint arXiv:2504.20571, 2025b. Fang Wu, Weihao Xuan, Ximing Lu, Zaid Harchaoui, and Yejin Choi. The invisible leash: Why rlvr may ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Yangzhen Wu, Zhiqing Sun, Shanda Li, Sean Welleck, and Yiming Yang. Inference scaling laws: An empirical analysis of compute-optimal inference for problem-solving with language models. arXiv preprint arXiv:2408.00724,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, and Zhenru Zhang. Qwen2.5-math technical report: Toward mathematical ex- pert model via self-improvement.arXiv preprint arXiv:2409.12122,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Feiyu Yang. An integrated framework integrating monte carlo tree search and supervised learning for train timetabling problem.arXiv preprint arXiv:2311.00971,
-
[27]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. Does re- inforcement learning really incentivize reasoning capacity in llms beyond the base model?arXiv preprint arXiv:2504.13837,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Large language model-brained gui agents: A survey, 2024a
Dan Zhang, Sining Zhoubian, Ziniu Hu, Yisong Yue, Yuxiao Dong, and Jie Tang. Rest-mcts*: Llm self-training via process reward guided tree search.Advances in Neural Information Processing Systems, 37:64735–64772, 2024a. Di Zhang, Xiaoshui Huang, Dongzhan Zhou, Yuqiang Li, and Wanli Ouyang. Accessing gpt-4 level mathematical olympiad solutions via monte car...
-
[30]
and random sampling ap- proaches (Wang et al., 2022). More recently, search-based reasoning has evolved into sophisticated frameworks that integrate three core components: policy models for generating reasoning steps, reward models for evaluative feedback, and search algorithms for exploring solution spaces. Draw- ing inspiration from game-playing systems...
work page 2022
-
[31]
have improved training stability and efficiency by incorporating critic-free optimiza- tion, dynamic sampling, and adaptive weighting mechanisms. While these approaches demonstrate the significant promise of verifiable rewards, they predominantly rely on direct rollouts, which can constrain systematic exploration of the solution space (Wu et al., 2025; Yu...
work page 2025
-
[32]
Let’s think step by step and output the final answer within\boxed{}
successfully integrated MCTS with deep learning (Kemmerling et al., 2023), achieving superhuman performance in board and video games (Ye et al., 2021). More recently, MCTS has been applied to path finding and train timetabling problems (Pitanov et al., 2023; Yang, 2023), while Vagadia et al. (2024) integrated MCTS into physics-informed planning networks f...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.