Entropy After </Think> for reasoning model early exiting
Pith reviewed 2026-05-18 11:46 UTC · model grok-4.3
The pith
Appending a </think> token and monitoring entropy after it lets reasoning models stop early.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By appending the stop-thinking token </think> during generation and tracking the entropy of the following token, the resulting EAT trajectory decreases and stabilizes precisely when Pass@1 accuracy plateaus across many rollouts. Thresholding the variance of an exponential moving average of the EAT values supplies a practical stopping criterion that reduces token consumption while preserving accuracy.
What carries the argument
Entropy After </Think> (EAT), the entropy of the token predicted immediately after the model is forced to output </think> in the middle of its reasoning chain.
If this is right
- Compute can be allocated adaptively per question according to the EAT trajectory instead of using a fixed token budget for every input.
- The same early-exit rule works in black-box settings by computing EAT with a smaller proxy model.
- Token usage falls 12-22 percent on MATH500 and AIME2025 while accuracy remains unchanged.
- Early stopping remains reliable even when logits from the main reasoning model are unavailable.
Where Pith is reading between the lines
- The same local entropy signal could be tested on non-math reasoning tasks such as code generation or multi-step planning.
- Training models to produce lower entropy immediately after </think> might encourage more efficient reasoning by design.
- Combining EAT with other cheap uncertainty estimates could yield hybrid stopping policies that are harder to fool.
Load-bearing premise
The entropy of the token right after </think> decreases and stabilizes exactly when accuracy across repeated generations stops improving.
What would settle it
Apply the EAT variance threshold to stop generation on a batch of questions and check whether any question that would have produced a correct answer with more tokens instead exits early with an incorrect answer.
Figures









read the original abstract
Reasoning LLMs show improved performance with longer chains of thought. However, recent work has highlighted their tendency to overthink, continuing to revise answers even after reaching the correct solution. We quantitatively confirm this inefficiency from the distribution dynamics perspective by tracking Pass@1 for answers averaged over a large number of rollouts and find the model often begins to always produce the correct answer early in the reasoning, making extra reasoning tokens wasteful. To detect and prevent overthinking, we propose a simple and inexpensive novel signal, Entropy After </Think> (EAT), for monitoring and deciding whether to exit reasoning early. By appending a stop thinking token (</think>) and monitoring the entropy of the following token as the model reasons, we obtain a trajectory that decreases and stabilizes when Pass@1 plateaus; thresholding its variance under an exponential moving average yields a practical stopping rule. Importantly, our approach enables adaptively allocating compute based on the EAT trajectory, allowing us to spend compute in a more efficient way compared with fixing the token budget for all questions. Empirically, on MATH500 and AIME2025, EAT reduces token usage by 12 - 22% without harming accuracy. EAT also remains effective in black box settings where logits from the reasoning model are not accessible, and EAT is computed with proxy models: We verified the feasibility via early stopping Llama 70B with a 1.5B model and Claude 3.7 with a local 4B model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Entropy After </Think> (EAT) as a signal for early exiting during chain-of-thought reasoning in LLMs. By appending the </think> token and tracking the entropy of the immediately following token, the EAT trajectory is claimed to decrease and stabilize precisely when Pass@1 accuracy (averaged over rollouts) plateaus. A practical stopping rule is obtained by thresholding the variance of EAT under an exponential moving average (EMA), enabling adaptive token allocation. On MATH500 and AIME2025 this yields 12-22% token savings with no accuracy loss. The method is also reported to transfer to black-box settings via smaller proxy models (e.g., 1.5B for Llama-70B, 4B for Claude 3.7).
Significance. If the reported correlation between EAT stabilization and the Pass@1 plateau holds under rigorous controls, the work supplies a lightweight, logit-accessible or proxy-accessible mechanism for mitigating overthinking. The adaptive (rather than fixed-budget) compute allocation and the black-box proxy demonstration are practically relevant for efficient inference of reasoning models.
major comments (2)
- Abstract: the central empirical claim of 12-22% token reduction without accuracy loss rests on an EAT-variance threshold under EMA, yet no rollout count, threshold-selection procedure, statistical significance tests, or per-question failure-case analysis is supplied. Without these the link between the observed EAT trajectory and safe early exit cannot be verified.
- Abstract: the stopping rule is defined by an observed correlation between EAT stabilization and Pass@1 plateau rather than a closed-form derivation; the variance threshold and EMA decay are therefore free parameters whose selection on the same MATH500/AIME2025 benchmarks risks circularity and poor generalization to unseen questions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate additional empirical details and clarifications on methodology.
read point-by-point responses
-
Referee: Abstract: the central empirical claim of 12-22% token reduction without accuracy loss rests on an EAT-variance threshold under EMA, yet no rollout count, threshold-selection procedure, statistical significance tests, or per-question failure-case analysis is supplied. Without these the link between the observed EAT trajectory and safe early exit cannot be verified.
Authors: We agree that the abstract would benefit from these supporting details to strengthen verifiability. The full manuscript reports 128 rollouts per question for Pass@1 estimation. Threshold selection was performed via grid search on a held-out validation split of MATH500 (distinct from the reported test results), with statistical tests (paired t-tests showing p > 0.05 for accuracy equivalence) and per-question failure analysis included in the appendix. We will summarize the rollout count, validation procedure, and significance results in the revised abstract while retaining the main findings. revision: yes
-
Referee: Abstract: the stopping rule is defined by an observed correlation between EAT stabilization and Pass@1 plateau rather than a closed-form derivation; the variance threshold and EMA decay are therefore free parameters whose selection on the same MATH500/AIME2025 benchmarks risks circularity and poor generalization to unseen questions.
Authors: We acknowledge that the stopping rule relies on the empirically observed correlation rather than a closed-form derivation, which is a limitation of the current approach. To reduce circularity, hyperparameters were tuned on a 20% validation subset of MATH500 and evaluated on the held-out portion plus the independent AIME2025 benchmark. We will add a dedicated subsection on hyperparameter sensitivity, cross-validation results, and robustness checks in the revised manuscript to better support generalization claims. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical method: appending </think> and tracking entropy of the next token to produce an EAT trajectory that is observed to decrease and stabilize when Pass@1 plateaus, followed by a variance threshold under EMA as a stopping rule. The performance claims (12-22% token reduction on MATH500 and AIME2025) are reported as direct experimental outcomes. No equations, self-citations, fitted parameters renamed as predictions, or uniqueness theorems are invoked that would reduce any central claim to its own inputs by construction. The derivation chain is therefore self-contained as an observation-driven heuristic without load-bearing circular steps.
Axiom & Free-Parameter Ledger
free parameters (2)
- EMA decay factor
- variance threshold
axioms (1)
- domain assumption Entropy after </think> decreases and stabilizes precisely when Pass@1 plateaus.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By appending a stop thinking token (</think>) and monitoring the entropy of the following token as the model reasons, we obtain a trajectory that decreases and stabilizes when Pass@1 plateaus; thresholding its variance under an exponential moving average yields a practical stopping rule.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
LLMs Improving LLMs: Agentic Discovery for Test-Time Scaling
AutoTTS discovers width-depth test-time scaling controllers through agentic search in a pre-collected trajectory environment, yielding better accuracy-cost tradeoffs than hand-designed baselines on math reasoning task...
-
LLMs Improving LLMs: Agentic Discovery for Test-Time Scaling
AutoTTS discovers superior test-time scaling strategies for LLMs via cheap controller synthesis in a pre-collected trajectory environment, outperforming manual baselines on math benchmarks with low discovery cost.
-
Stop When Reasoning Converges: Semantic-Preserving Early Exit for Reasoning Models
PUMA detects reasoning-level semantic redundancy to enable early exit in chains of thought, achieving 26.2% average token reduction across five LRMs and five benchmarks while preserving accuracy and CoT quality.
-
Conformal Thinking: Risk Control for Reasoning on a Compute Budget
Conformal risk control with upper and lower thresholds lets LLMs adaptively stop reasoning while guaranteeing a maximum error rate and minimizing token use.
Reference graph
Works this paper leans on
-
[1]
Nikhil Chandak, Shashwat Goel, Ameya Prabhu, Moritz Hardt, and Jonas Geiping. Answer matching outperforms multiple choice for language model evaluation.arXiv preprint arXiv:2507.02856,
-
[2]
Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, et al. Do not think that much for 2+ 3=? on the overthinking of o1-like llms.arXiv preprint arXiv:2412.21187,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Reasoning with Exploration: An Entropy Perspective
Daixuan Cheng, Shaohan Huang, Xuekai Zhu, Bo Dai, Wayne Xin Zhao, Zhenliang Zhang, and Furu Wei. Reasoning with exploration: An entropy perspective.arXiv preprint arXiv:2506.14758,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
S-grpo: Early exit via reinforcement learning in reasoning models.arXiv preprint arXiv:2505.07686,
Muzhi Dai, Chenxu Yang, and Qingyi Si. S-grpo: Early exit via reinforcement learning in reasoning models.arXiv preprint arXiv:2505.07686,
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
URLhttps://arxiv.org/abs/2501.12948. Maha Elbayad, Jiatao Gu, Edouard Grave, and Michael Auli. Depth-adaptive transformer.arXiv preprint arXiv:1910.10073,
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[6]
Reasoning without self-doubt: More efficient chain-of-thought through certainty probing
Yichao Fu, Junda Chen, Yonghao Zhuang, Zheyu Fu, Ion Stoica, and Hao Zhang. Reasoning without self-doubt: More efficient chain-of-thought through certainty probing. InICLR 2025 Workshop on Foundation Models in the Wild,
work page 2025
-
[7]
Adaptive Computation Time for Recurrent Neural Networks
Alex Graves. Adaptive computation time for recurrent neural networks.arXiv preprint arXiv:1603.08983,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step.arXiv preprint arXiv:2305.20050,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Answer convergence as a signal for early stopping in reasoning.arXiv preprint arXiv:2506.02536,
Xin Liu and Lu Wang. Answer convergence as a signal for early stopping in reasoning.arXiv preprint arXiv:2506.02536,
-
[11]
Uncertainty estimation in autoregressive structured prediction, 2021
Andrey Malinin and Mark Gales. Uncertainty estimation in autoregressive structured prediction. arXiv preprint arXiv:2002.07650,
-
[12]
Early Stopping Chain-of-thoughts in Large Language Models
Minjia Mao, Bowen Yin, Yu Zhu, and Xiao Fang. Early stopping chain-of-thoughts in large language models.arXiv preprint arXiv:2509.14004,
work page internal anchor Pith review arXiv
-
[13]
URLhttps://arxiv.org/abs/2501.19393. Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Jonathan Heek, Kefan Xiao, Shivani Agrawal, and Jeff Dean. Efficiently scaling transformer inference. Proceedings of machine learning and systems, 5:606–624,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Penghui Qi, Zichen Liu, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Optimizing anytime reasoning via budget relative policy optimization.arXiv preprint arXiv:2505.13438,
-
[15]
Vaishnavi Shrivastava, Ahmed Awadallah, Vidhisha Balachandran, Shivam Garg, Harkirat Behl, and Dimitris Papailiopoulos. Sample more to think less: Group filtered policy optimization for concise reasoning.arXiv preprint arXiv:2508.09726,
-
[16]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
Yang Sui, Yu-Neng Chuang, Guanchu Wang, Jiamu Zhang, Tianyi Zhang, Jiayi Yuan, Hongyi Liu, Andrew Wen, Shaochen Zhong, Hanjie Chen, et al. Stop overthinking: A survey on efficient reasoning for large language models.arXiv preprint arXiv:2503.16419,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xionghui Chen, Jianxin Yang, Zhenru Zhang, et al. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning.arXiv preprint arXiv:2506.01939,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Yangzhen Wu, Zhiqing Sun, Shanda Li, Sean Welleck, and Yiming Yang. Inference scaling laws: An empirical analysis of compute-optimal inference for problem-solving with language models.arXiv preprint arXiv:2408.00724,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, et al. Qwen2 technical report.arXiv preprint arXiv:2407.10671,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
arXiv preprint arXiv:2504.15895
Chenxu Yang, Qingyi Si, Yongjie Duan, Zheliang Zhu, Chenyu Zhu, Zheng Lin, Li Cao, and Weiping Wang. Dynamic early exit in reasoning models.arXiv preprint arXiv:2504.15895,
-
[22]
Xixian Yong, Xiao Zhou, Yingying Zhang, Jinlin Li, Yefeng Zheng, and Xian Wu. Think or not? exploring thinking efficiency in large reasoning models via an information-theoretic lens.arXiv preprint arXiv:2505.18237,
-
[23]
Anqi Zhang, Yulin Chen, Jane Pan, Chen Zhao, Aurojit Panda, Jinyang Li, and He He. Reasoning models know when they’re right: Probing hidden states for self-verification.arXiv preprint arXiv:2504.05419,
-
[24]
12 Preprint, under review A LLMUSAGE DISCLOSURE Large language models are only moderately used for editing and improving the coherence of the text; they are not used to provide research or writing ideas in any form. B PREFIX STRING FOR COMPUTINGEAT In the main text, theEATtrajectories we illustrate in Fig. 1, 2 and 3 are computed as EAT=H(f(Q,<think>,r 1,...
work page 2025
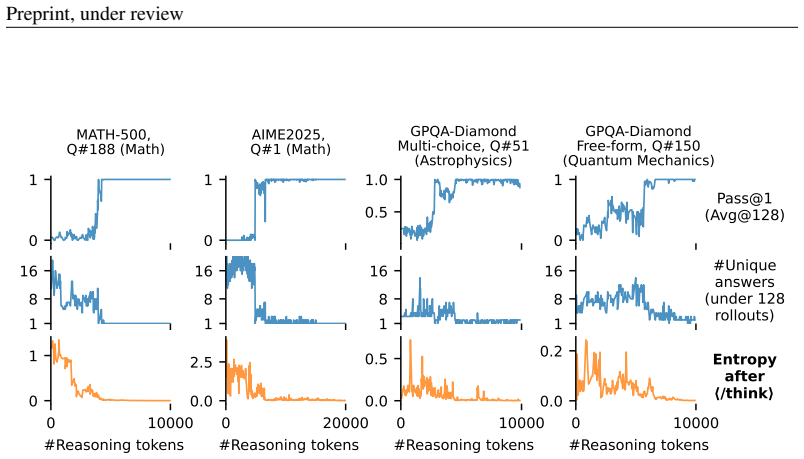
-
[25]
is in the middle of reasoning step or is about to finish and start a new round of revision, but less correlated with whether a confident answer is conditioned on the reasoning, a quantity Pass@1 reflects. 0 1 MATH-500, Q#188 (Math) 0 1 AIME2025, Q#1 (Math) 0.5 1.0 GPQA-Diamond Multi-choice, Q#51 (Astrophysics) 0 1 Pass@1 (Avg@128) GPQA-Diamond Free-form, ...
work page 2000
-
[26]
That’s seven digits. If they want seven after the decimal, it’s 1,4,1,5,9,2,6. But the initial seven digits are 3.141592. The user might be confused by the decimal point. Should I exclude the decimal point and just list the digits? Yes, that’s better. The first seven digits are 3141592. The seven digits after the decimal are 1415926. But the user asked fo...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.