Hypothesis-Driven Feature Manifold Analysis in LLMs via Supervised Multi-Dimensional Scaling
Pith reviewed 2026-05-18 10:36 UTC · model grok-4.3
The pith
Language models encode temporal concepts as distinct geometric structures like circles, lines, and clusters in their latent space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
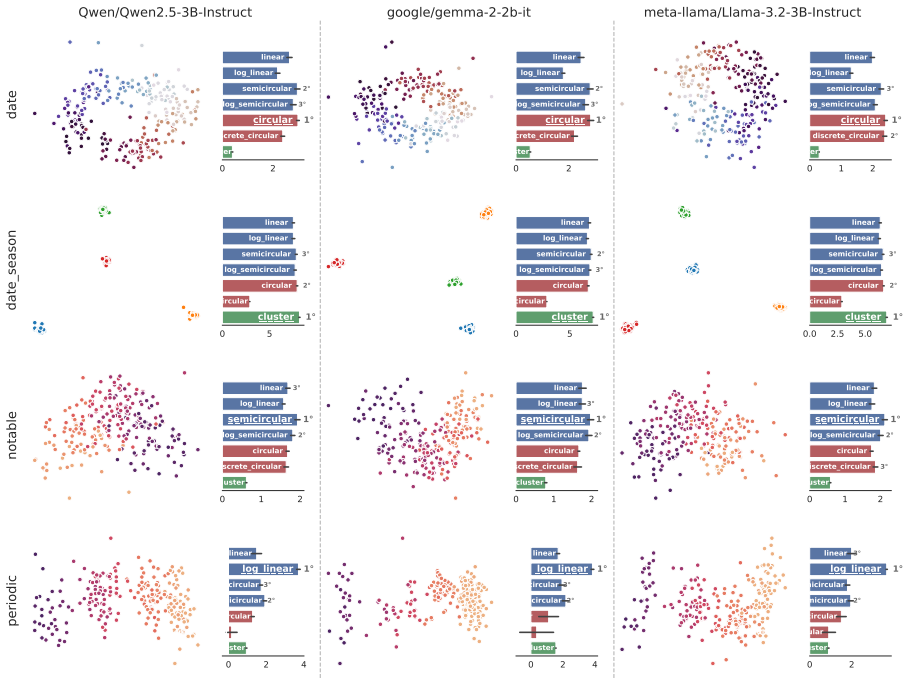
Supervised Multi-Dimensional Scaling reveals that different features in language models instantiate distinct geometric structures, including circles, lines, and clusters. These structures reflect the semantic properties of the concepts they represent, remain stable across model families and sizes, actively support reasoning, and dynamically reshape in response to contextual changes, thereby supporting a model of entity-based reasoning in which LMs encode and transform structured representations.
What carries the argument
Supervised Multi-Dimensional Scaling (SMDS), a model-agnostic method that evaluates competing hypotheses about the geometry of feature manifolds by projecting representations while respecting supervised information.
If this is right
- Feature manifolds reflect the semantic properties of the concepts they represent.
- These structures remain stable across model families and sizes.
- They actively support reasoning in the model.
- They dynamically reshape in response to contextual changes.
Where Pith is reading between the lines
- Similar manifold structures might appear in other reasoning tasks, allowing SMDS to map how models handle spatial or causal concepts.
- The finding of dynamic reshaping suggests that prompting strategies could be designed to control or stabilize these internal geometries for more reliable outputs.
- Entity-based reasoning may imply that models treat concepts as objects with properties that can be transformed, opening ways to debug specific failures in multi-step inference.
Load-bearing premise
The assumption that Supervised Multi-Dimensional Scaling reliably recovers the true underlying geometric structures of feature manifolds without artifacts introduced by the supervision signals, distance metrics, or the specific choice of temporal reasoning as the case study domain.
What would settle it
A calculation showing that disrupting the identified geometric structures through targeted interventions does not affect the model's accuracy on temporal reasoning tasks would falsify the claim that these structures actively support reasoning.
Figures














read the original abstract
The linear representation hypothesis states that language models (LMs) encode concepts as directions in their latent space, forming organized, multidimensional manifolds. Prior work has largely focused on identifying specific geometries for individual features, limiting its ability to generalize. We introduce Supervised Multi-Dimensional Scaling (SMDS), a model-agnostic method for evaluating and comparing competing feature manifold hypotheses. We apply SMDS to temporal reasoning as a case study and find that different features instantiate distinct geometric structures, including circles, lines, and clusters. SMDS reveals several consistent characteristics of these structures: they reflect the semantic properties of the concepts they represent, remain stable across model families and sizes, actively support reasoning, and dynamically reshape in response to contextual changes. Together, our findings shed light on the functional role of feature manifolds, supporting a model of entity-based reasoning in which LMs encode and transform structured representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Supervised Multi-Dimensional Scaling (SMDS) as a model-agnostic method to evaluate competing hypotheses about feature manifolds in LLMs. Applied to temporal reasoning as a case study, it claims that distinct features instantiate different geometric structures (circles, lines, clusters) that reflect semantic properties of the concepts, remain stable across model families and sizes, actively support reasoning, and dynamically reshape under contextual changes, thereby supporting an entity-based model of reasoning in which LLMs encode and transform structured representations.
Significance. If SMDS can be shown to recover intrinsic manifold geometries rather than artifacts of its supervision, the work would provide a useful general-purpose tool for hypothesis-driven analysis of internal representations. The reported cross-model stability and context-dependent reshaping, if quantitatively substantiated with controls, would strengthen evidence for structured representations that functionally contribute to reasoning.
major comments (2)
- [Method (SMDS formulation and loss)] The central assumption that SMDS recovers intrinsic geometries is load-bearing for all claims about semantic reflection, stability, and reasoning support. Because SMDS is supervised on temporal-reasoning labels and employs a chosen distance metric, the recovered circles, lines, and clusters could be imposed by the objective. No ablations are presented that vary supervision strength, remove labels entirely, or compare against unsupervised MDS/PCA on identical activations to rule out method-induced artifacts.
- [Experiments and Results] The results section reports qualitative observations of distinct geometries and their properties but supplies no quantitative metrics, error bars, statistical tests, or baseline comparisons. This absence makes it impossible to evaluate the strength of the stability-across-models claim or the dynamic-reshaping claim.
minor comments (2)
- [Abstract] The abstract would be strengthened by a single sentence summarizing the key quantitative controls or metrics that support the qualitative findings.
- [Preliminaries] Notation for the supervised scaling objective and the distance function could be introduced with a short table of symbols for readers outside the immediate subfield.
Simulated Author's Rebuttal
Thank you for the detailed review and constructive feedback on our manuscript. We have carefully considered the major comments and will revise the paper to address the concerns regarding potential method-induced artifacts and the lack of quantitative evaluations. Below we provide point-by-point responses.
read point-by-point responses
-
Referee: [Method (SMDS formulation and loss)] The central assumption that SMDS recovers intrinsic geometries is load-bearing for all claims about semantic reflection, stability, and reasoning support. Because SMDS is supervised on temporal-reasoning labels and employs a chosen distance metric, the recovered circles, lines, and clusters could be imposed by the objective. No ablations are presented that vary supervision strength, remove labels entirely, or compare against unsupervised MDS/PCA on identical activations to rule out method-induced artifacts.
Authors: We thank the referee for highlighting this important methodological concern. While SMDS is intentionally supervised to evaluate specific hypotheses about feature manifolds, we agree that it is essential to demonstrate that the recovered structures are not solely artifacts of the supervision or chosen metric. In the revised manuscript, we will add a series of ablations, including: (1) comparisons of SMDS results with those from unsupervised MDS and PCA applied to the same activation data, (2) experiments varying the strength of supervision (e.g., using partial or noisy labels), and (3) a fully unsupervised baseline. These additions will provide evidence that the observed geometric structures reflect intrinsic properties of the representations rather than being imposed by the method. revision: yes
-
Referee: [Experiments and Results] The results section reports qualitative observations of distinct geometries and their properties but supplies no quantitative metrics, error bars, statistical tests, or baseline comparisons. This absence makes it impossible to evaluate the strength of the stability-across-models claim or the dynamic-reshaping claim.
Authors: We acknowledge that the current presentation relies primarily on qualitative visualizations, which limits the ability to rigorously assess the claims. In the revision, we will introduce quantitative metrics to evaluate manifold properties, such as measures of geometric fidelity (e.g., stress or reconstruction error for the scaling), cross-model stability quantified via Procrustes analysis or correlation of distances with error bars from multiple seeds, and statistical tests (e.g., permutation tests) for the significance of observed differences in reshaping under context changes. We will also include baseline comparisons to quantify the improvements or differences from SMDS. revision: yes
Circularity Check
No circularity: SMDS applied as independent analysis tool to observed activations
full rationale
The paper introduces Supervised Multi-Dimensional Scaling (SMDS) as a model-agnostic method to evaluate competing feature manifold hypotheses on LLM activations for temporal reasoning. The central findings (distinct geometries like circles/lines/clusters that reflect semantics, remain stable, support reasoning, and reshape with context) are presented as outcomes of applying this method to empirical data rather than being defined into existence or recovered by construction from fitted parameters. No self-definitional loops, fitted-input predictions, or load-bearing self-citations that reduce the derivation to its own inputs are evident in the abstract or described approach. The method is positioned as an evaluation tool against external model behavior, making the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Language models encode concepts as directions in latent space that form organized multidimensional manifolds (linear representation hypothesis).
Lean theorems connected to this paper
-
Foundation/AlexanderDuality.lean; Cost/FunctionalEquation.leanalexander_duality_circle_linking; washburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
different features instantiate distinct geometric structures, including circles, lines, and clusters... remain stable across model families and sizes, actively support reasoning, and dynamically reshape in response to contextual changes
-
Foundation/ArithmeticFromLogic.lean; Cost/FunctionalEquation.leanembed_strictMono_of_one_lt; Jcost_pos_of_ne_one refines?
refinesRelation between the paper passage and the cited Recognition theorem.
2 sin(π min(|δij|,1−|δij|)) ... circular; |δij| ... linear; 0 if yi=yj, 1 otherwise ... cluster
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Latent Trajectory Dynamics in Large Language Models: A Manifold Evolution Framework with Empirical Validation
DMET models LLM generation as controlled dynamical trajectories on a semantic manifold, with three proxy metrics that predict output quality and support adaptive decoding to lower perplexity.
-
H-Probes: Extracting Hierarchical Structures From Latent Representations of Language Models
H-probes locate low-dimensional subspaces encoding hierarchy in LLM activations for synthetic tree tasks, show causal importance and generalization, and detect weaker signals in mathematical reasoning traces.
Reference graph
Works this paper leans on
-
[1]
In2014 IEEE Pacific Visualization Symposium, pages 209–216
Multidimensional Projection with Radial Basis Function and Control Points Selection. In2014 IEEE Pacific Visualization Symposium, pages 209–216. Mikel Artetxe, Sebastian Ruder, and Dani Yogatama
-
[2]
Unicode replacement / encoding-error characters
On the Cross-lingual Transferability of Mono- lingual Representations. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online. Association for Computational Linguistics. Yonatan Belinkov. 2022. Probing Classifiers: Promises, Shortcomings, and Advances.Computational Lin- guistics, 48(1):207–219. Trenton Bricken, A...
-
[3]
The Geometry of Numerical Reasoning: Lan- guage Models Compare Numeric Properties in Linear Subspaces. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Asso- ciation for Computational Linguistics: Human Lan- guage Technologies (Volume 2: Short Papers), pages 550–561, Albuquerque, New Mexico. Association for Computational ...
work page 2025
-
[4]
InThe Thirteenth In- ternational Conference on Learning Representations
Test of Time: A Benchmark for Evaluating LLMs on Temporal Reasoning. InThe Thirteenth In- ternational Conference on Learning Representations. Jiahai Feng and Jacob Steinhardt. 2023. How do Lan- guage Models Bind Entities in Context? InThe Twelfth International Conference on Learning Repre- sentations. Lisa Ferro, Laurie Gerber, Inderjeet Mani, Beth M. Sun...
work page 2023
-
[5]
Bias and Fairness in Large Language Models: A Survey.Computational Linguistics, 50(3):1097– 1179. Gemma, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean-bastien Grill, Sabela Ramos, Edouard Yvinec, Mich...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
In The Eleventh International Conference on Learning Representations
Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task. In The Eleventh International Conference on Learning Representations. Bill Yuchen Lin, Abhilasha Ravichander, Ximing Lu, Nouha Dziri, Melanie Sclar, Khyathi Chandu, Chan- dra Bhagavatula, and Yejin Choi. 2023. The Unlock- ing Spell on Base LLMs: Rethinking Alignment vi...
-
[7]
Open Problems in Mechanistic Interpretability
TimeML Annotation Guidelines Version 1.2.1. Andrea Setzer. 2001.Temporal Information in Newswire Articles: An Annotation Scheme and Cor- pus Study. PhD dissertation, University of Sheffield. Lee Sharkey, Bilal Chughtai, Joshua Batson, Jack Lind- sey, Jeff Wu, Lucius Bushnaq, Nicholas Goldowsky- Dill, Stefan Heimersheim, Alejandro Ortega, Joseph Bloom, Ste...
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[8]
Chemometrics and Intelligent Laboratory Systems, 58(2):109–130
PLS-regression: A basic tool of chemometrics. Chemometrics and Intelligent Laboratory Systems, 58(2):109–130. Xuansheng Wu, Wenlin Yao, Jianshu Chen, Xiaoman Pan, Xiaoyang Wang, Ninghao Liu, and Dong Yu
-
[9]
From Language Modeling to Instruction Fol- lowing: Understanding the Behavior Shift in LLMs after Instruction Tuning. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 2341–2369, Mexico City, Mexico. Association for Computational L...
work page 2024
-
[10]
Ben Zhou, Daniel Khashabi, Qiang Ning, and Dan Roth
Zero-shot Temporal Relation Extraction with ChatGPT.Preprint, arXiv:2304.05454. Ben Zhou, Daniel Khashabi, Qiang Ning, and Dan Roth
-
[11]
“Going on a vacation” takes longer than “Go- ing for a walk”: A Study of Temporal Commonsense Understanding. InProceedings of the 2019 Confer- ence on Empirical Methods in Natural Language Pro- cessing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China. Association for Computational Linguistics. Chun...
work page 2019
-
[12]
and TimeML (Saurí et al., 2006), as well as several variants. We take inspiration from TIMEX1-3 to construct several synthetic datasets. Each one covers a specific family of temporal ex- pressions (Table 2): •date : Refers to a specific calendar date. To explore periodic reasoning, we omit the year; •time_of_day : Specifies a precise moment in the day; •d...
work page 2006
-
[13]
may improve performance. D.2 Additional Observations on Manifold Discovery We observe two instances where manifold dis- covery exhibits unexpected behaviours. On the date_temperature task (Figure 10), the clusters are correctly identified but the scoring yields unre- liable values. This is expected when considering how distances are computed in the binary...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.