Scaling Vision Transformers for Functional MRI with Flat Maps
Pith reviewed 2026-05-18 06:58 UTC · model grok-4.3
The pith
Converting fMRI volumes to 2D cortical flat maps lets Vision Transformers scale and outperform prior models on cognitive state decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
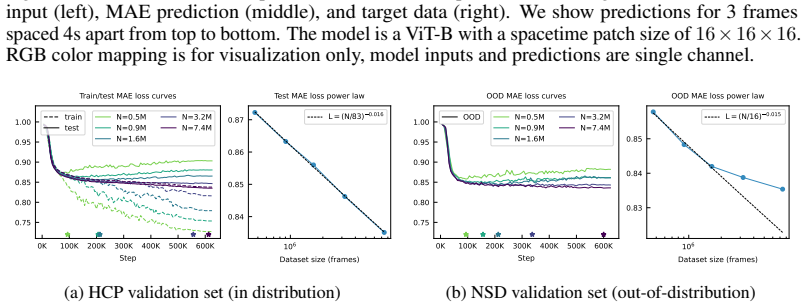
The central claim is that cortical flat map projections turn each 3D fMRI volume into a 2D image that a standard Vision Transformer can process directly inside a masked autoencoder framework. Trained on 2.1K hours of open data, the resulting CortexMAE models exhibit strict power-law scaling with data size and deliver substantially higher accuracy on cognitive state decoding benchmarks than earlier fMRI models. In contrast, the same models show no clear advantage on subject-level trait prediction, where even a simple functional connectivity baseline remains competitive.
What carries the argument
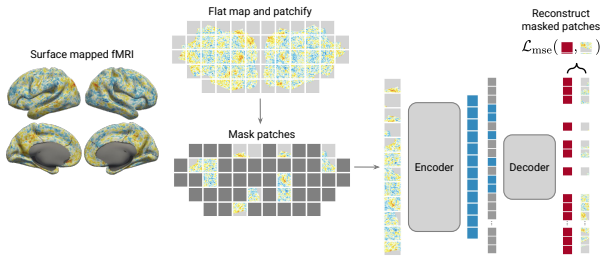
Cortical flat map projection that converts each 3D fMRI volume into a 2D map for direct input to a Vision Transformer trained under the masked autoencoder objective.
If this is right
- Flat maps generally outperform both parcellation and direct volume representations across the tested tasks.
- Model performance follows a strict power law with increasing training data, subject to observable limits.
- CortexMAE models achieve large gains over prior methods specifically on cognitive state decoding.
- No single architecture dominates subject-level trait prediction, and all models remain close to a functional connectivity baseline.
Where Pith is reading between the lines
- The performance gap between trait and state tasks suggests self-supervised pretraining on fMRI may be better suited to capturing transient activity patterns than stable individual traits.
- Observed scaling limits imply that further gains will require changes in architecture or data quality rather than data volume alone.
- If flat maps transfer well to other 3D brain imaging modalities, the same projection step could simplify transformer use across neuroimaging.
Load-bearing premise
Cortical flat-map projections preserve the spatial and temporal information needed for trait prediction and cognitive state decoding without introducing systematic distortions that would invalidate comparisons to volume-based or parcellation baselines.
What would settle it
A controlled experiment in which a volume-based or parcellation-based transformer matches or exceeds CortexMAE accuracy on the same cognitive state decoding tasks would falsify the claimed advantage of flat maps.
Figures






read the original abstract
We study the problem of training self-supervised foundation models for functional MRI. Our main contributions are: (1) we introduce a new model family (CortexMAE) trained using the masked autoencoder framework on 2.1K hours of open fMRI data, and (2) we release the first open evaluation suite (Brainmarks) for fMRI foundation models. Our core innovation is simple: we adapt the Vision Transformer to fMRI by first converting each 3D fMRI volume to a 2D map using a cortical flat map projection. We directly compare flat maps to both parcellation and volume-based representations. While each has its advantages, flat maps generally perform best. We perform the first systematic scaling analysis for fMRI and observe strict power law scaling, albeit with limits. Finally, we use Brainmarks to do controlled benchmark comparisons. On subject-level trait prediction, we report a challenging null result: no single model achieves clear state-of-the-art performance. Moreover, all models struggle to outperform a simple functional connectivity baseline. On cognitive state decoding, we observe more robust performance, and in this setting our CortexMAE family outperforms prior models by a large margin. Code, models, and datasets are available at https://github.com/MedARC-AI/CortexMAE and https://github.com/MedARC-AI/Brainmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CortexMAE, a family of masked autoencoder models based on Vision Transformers adapted to fMRI via cortical flat-map projections of 3D volumes. Trained self-supervised on 2.1K hours of open data, the work releases the Brainmarks evaluation suite and performs direct comparisons of flat-map, parcellation, and volume representations. It reports strict power-law scaling (with limits), a null result on subject-level trait prediction (no model clearly outperforms a functional connectivity baseline), and substantially stronger performance on cognitive state decoding where CortexMAE outperforms prior models by a large margin. Code, models, and datasets are released.
Significance. If the central empirical claims hold, this provides a useful open foundation-model baseline and scaling analysis for fMRI, together with a new benchmark suite. The explicit release of code, models, and data, plus the honest reporting of the null result on trait prediction, are clear strengths that facilitate independent verification. The flat-map approach could influence representation choices in neuroimaging if shown to preserve functional structure without systematic bias relative to volume or parcellation inputs.
major comments (2)
- [§4 and Table 2] §4 (Experimental Comparisons) and Table 2: the headline ranking that flat maps generally perform best, and the large-margin win on cognitive state decoding, rests on the untested assumption that the 3D-to-2D cortical projection retains the spatial structure exploited by the ViT without introducing distortions that favor one input format. No voxel-wise reconstruction error, subcortical signal retention statistics, or representational similarity analysis between flat-map, volume, and parcellation inputs is reported; this is load-bearing for the claim that the observed ordering reflects architectural or representational advantage rather than unequal information fidelity.
- [Methods and Results] Methods and Results sections: performance numbers for both trait prediction and cognitive decoding lack error bars, standard deviations across random seeds or cross-validation folds, and explicit statements of the exact train/validation/test splits used. Without these, the robustness of the 'large margin' outperformance and the null result cannot be assessed at the level required for a foundation-model benchmark paper.
minor comments (2)
- [Figure 3] Figure 3 (scaling curves): axis labels and legend entries are too small for readability; consider increasing font size and adding a panel showing the fitted power-law exponents with confidence intervals.
- [§5] The abstract states 'strict power law scaling, albeit with limits' but the main text does not define the quantitative criterion used to identify the 'limits'; a short clarification would help readers interpret the scaling regime.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We appreciate the focus on validating the representational fidelity of our flat-map approach and on improving the statistical reporting of our results. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4 and Table 2] §4 (Experimental Comparisons) and Table 2: the headline ranking that flat maps generally perform best, and the large-margin win on cognitive state decoding, rests on the untested assumption that the 3D-to-2D cortical projection retains the spatial structure exploited by the ViT without introducing distortions that favor one input format. No voxel-wise reconstruction error, subcortical signal retention statistics, or representational similarity analysis between flat-map, volume, and parcellation inputs is reported; this is load-bearing for the claim that the observed ordering reflects architectural or representational advantage rather than unequal information fidelity.
Authors: We agree that the absence of direct fidelity checks on the 3D-to-2D projection is a limitation that weakens the interpretation of why flat maps outperform the alternatives. Although cortical flat mapping is a standard preprocessing step in the field (as implemented in FreeSurfer and used in the HCP), we did not report quantitative comparisons of information preservation across formats. In the revised version we will add voxel-wise reconstruction error between original volumes and projected maps, subcortical signal retention statistics, and representational similarity analysis (RSA) comparing flat-map, volume, and parcellation inputs. These additions will allow readers to evaluate whether the performance ordering reflects genuine representational advantages rather than differential information loss. revision: yes
-
Referee: [Methods and Results] Methods and Results sections: performance numbers for both trait prediction and cognitive decoding lack error bars, standard deviations across random seeds or cross-validation folds, and explicit statements of the exact train/validation/test splits used. Without these, the robustness of the 'large margin' outperformance and the null result cannot be assessed at the level required for a foundation-model benchmark paper.
Authors: We acknowledge that the original submission reported only point estimates without measures of variability or precise split details, which is insufficient for a benchmark paper. We will revise the Methods section to document the exact train/validation/test splits (including subject-wise partitioning to avoid leakage) and will update all performance tables and figures in Results to include error bars corresponding to standard deviation across random seeds and cross-validation folds. These changes will make both the large-margin gains on cognitive decoding and the null result on trait prediction more rigorously interpretable. revision: yes
Circularity Check
No circularity: purely empirical training, scaling observations, and held-out benchmarks
full rationale
The paper reports an empirical study: CortexMAE models are trained via masked autoencoding on 2.1K hours of fMRI data after converting volumes to 2D cortical flat maps, then evaluated on the released Brainmarks suite for trait prediction and cognitive state decoding. All performance claims, scaling observations (strict power laws with limits), and comparisons to parcellation/volume baselines arise directly from training runs and held-out test metrics. No mathematical derivations, first-principles results, fitted parameters renamed as predictions, or load-bearing self-citations appear in the described contributions. The work is self-contained against external benchmarks because code, models, and datasets are released for independent reproduction, and results are falsifiable via direct replication on the same splits rather than reducing to any internal definition or prior author result by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Masked autoencoder pretraining on flat-map fMRI yields representations that generalize to downstream decoding tasks.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we transform the 4D volumetric fMRI data into videos of 2D fMRI activity flat maps... tokenized into patches... standard ViT on temporal sequences of patchified flat maps using a spatiotemporal MAE
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
masked fMRI modeling performance improves with dataset size according to a strict power scaling law
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Meta-learning In-Context Enables Training-Free Cross Subject Brain Decoding
A meta-optimized in-context learning approach enables training-free cross-subject semantic visual decoding from fMRI by inferring individual neural encoding patterns via hierarchical inference on a few examples.
Reference graph
Works this paper leans on
-
[1]
John DE Gabrieli, Satrajit S Ghosh, and Susan Whitfield-Gabrieli. Prediction as a humanitarian and pragmatic contribution from human cognitive neuroscience.Neuron, 85(1):11–26, 2015
work page 2015
-
[2]
Choong-Wan Woo, Luke J Chang, Martin A Lindquist, and Tor D Wager. Building better biomarkers: brain models in translational neuroimaging.Nature neuroscience, 20(3):365–377, 2017
work page 2017
-
[3]
On the Opportunities and Risks of Foundation Models
Rishi Bommasani et al. On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Yukun Zhou, Mark A Chia, Siegfried K Wagner, Murat S Ayhan, Dominic J Williamson, Robbert R Struyven, Timing Liu, Moucheng Xu, Mateo G Lozano, Peter Woodward-Court, et al. A foundation model for generalizable disease detection from retinal images.Nature, 622(7981):156–163, 2023
work page 2023
-
[5]
Hanwen Xu, Naoto Usuyama, Jaspreet Bagga, Sheng Zhang, Rajesh Rao, Tristan Naumann, Cliff Wong, Zelalem Gero, Javier González, Yu Gu, et al. A whole-slide foundation model for digital pathology from real-world data.Nature, 630(8015):181–188, 2024
work page 2024
-
[6]
A foundation model for the earth system.Nature, pages 1–8, 2025
Cristian Bodnar, Wessel P Bruinsma, Ana Lucic, Megan Stanley, Anna Allen, Johannes Brandstetter, Patrick Garvan, Maik Riechert, Jonathan A Weyn, Haiyu Dong, et al. A foundation model for the earth system.Nature, pages 1–8, 2025
work page 2025
-
[7]
Eric Y Wang, Paul G Fahey, Zhuokun Ding, Stelios Papadopoulos, Kayla Ponder, Marissa A Weis, Andersen Chang, Taliah Muhammad, Saumil Patel, Zhiwei Ding, et al. Foundation model of neural activity predicts response to new stimulus types.Nature, 640(8058):470–477, 2025
work page 2025
-
[8]
Bert: Pre-training of deep bidi- rectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidi- rectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019
work page 2019
-
[9]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020
work page 1901
-
[10]
Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. wav2vec 2.0: A framework for self-supervised learning of speech representations.Advances in neural information processing systems, 33: 12449–12460, 2020
work page 2020
-
[11]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022
work page 2022
-
[12]
Xuan Kan, Wei Dai, Hejie Cui, Zilong Zhang, Ying Guo, and Carl Yang. Brain network transformer. Advances in Neural Information Processing Systems, 35:25586–25599, 2022
work page 2022
-
[13]
Armin Thomas, Christopher Ré, and Russell Poldrack. Self-supervised learning of brain dynamics from broad neuroimaging data.Advances in neural information processing systems, 35:21255–21269, 2022
work page 2022
-
[14]
Self-supervised transformers for fmri representation
Itzik Malkiel, Gony Rosenman, Lior Wolf, and Talma Hendler. Self-supervised transformers for fmri representation. InInternational Conference on Medical Imaging with Deep Learning, pages 895–913. PMLR, 2022. 6
work page 2022
-
[15]
Seeing beyond the brain: Conditional diffusion model with sparse masked modeling for vision decoding
Zijiao Chen, Jiaxin Qing, Tiange Xiang, Wan Lin Yue, and Juan Helen Zhou. Seeing beyond the brain: Conditional diffusion model with sparse masked modeling for vision decoding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22710–22720, 2023
work page 2023
-
[16]
Peter Kim, Junbeom Kwon, Sunghwan Joo, Sangyoon Bae, Donggyu Lee, Yoonho Jung, Shinjae Yoo, Jiook Cha, and Taesup Moon. Swift: Swin 4d fmri transformer.Advances in Neural Information Processing Systems, 36:42015–42037, 2023
work page 2023
-
[17]
BrainLM: A foundation model for brain activity recordings
Josue Ortega Caro, Antonio Henrique de Oliveira Fonseca, Syed A Rizvi, Matteo Rosati, Christopher Averill, James L Cross, Prateek Mittal, Emanuele Zappala, Rahul Madhav Dhodapkar, Chadi Abdallah, and David van Dijk. BrainLM: A foundation model for brain activity recordings. InThe Twelfth International Conference on Learning Representations, 2024. URL http...
work page 2024
-
[18]
Zijian Dong, Ruilin Li, Yilei Wu, Thuan Tinh Nguyen, Joanna Chong, Fang Ji, Nathanael Tong, Christopher Chen, and Juan Helen Zhou. Brain-jepa: Brain dynamics foundation model with gradient positioning and spatiotemporal masking.Advances in Neural Information Processing Systems, 37:86048–86073, 2024
work page 2024
-
[19]
General-purpose brain foundation models for time-series neuroimaging data
Mohammad Javad Darvishi Bayazi, Hena Ghonia, Roland Riachi, Bruno Aristimunha, Arian Khorasani, Md Rifat Arefin, Amin Darabi, Guillaume Dumas, and Irina Rish. General-purpose brain foundation models for time-series neuroimaging data. InNeurIPS Workshop on Time Series in the Age of Large Models, 2024. URLhttps://openreview.net/forum?id=HwDQH0r37I
work page 2024
-
[20]
arXiv preprint arXiv:2506.11167 , year=
Cheng Wang, Yu Jiang, Zhihao Peng, Chenxin Li, Changbae Bang, Lin Zhao, Jinglei Lv, Jorge Sepulcre, Carl Yang, Lifang He, et al. Towards a general-purpose foundation model for fmri analysis.arXiv preprint arXiv:2506.11167, 2025
-
[21]
Mehdi Azabou, Vinam Arora, Venkataramana Ganesh, Ximeng Mao, Santosh Nachimuthu, Michael Mendelson, Blake Richards, Matthew Perich, Guillaume Lajoie, and Eva Dyer. A unified, scalable framework for neural population decoding.Advances in Neural Information Processing Systems, 36: 44937–44956, 2023
work page 2023
-
[22]
Alexander Schaefer, Ru Kong, Evan M Gordon, Timothy O Laumann, Xi-Nian Zuo, Avram J Holmes, Simon B Eickhoff, and BT Thomas Yeo. Local-global parcellation of the human cerebral cortex from intrinsic functional connectivity mri.Cerebral cortex, 28(9):3095–3114, 2018
work page 2018
-
[23]
Fine-grain atlases of functional modes for fmri analysis.NeuroImage, 221:117126, 2020
Kamalaker Dadi, Gaël Varoquaux, Antonia Machlouzarides-Shalit, Krzysztof J Gorgolewski, Demian Wassermann, Bertrand Thirion, and Arthur Mensch. Fine-grain atlases of functional modes for fmri analysis.NeuroImage, 221:117126, 2020
work page 2020
-
[24]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. InProceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021
work page 2021
-
[25]
Olaf Sporns, Giulio Tononi, and Rolf Kötter. The human connectome: a structural description of the human brain.PLoS computational biology, 1(4):e42, 2005
work page 2005
-
[26]
BT Thomas Yeo, Fenna M Krienen, Jorge Sepulcre, Mert R Sabuncu, Danial Lashkari, Marisa Hollinshead, Joshua L Roffman, Jordan W Smoller, Lilla Zöllei, Jonathan R Polimeni, et al. The organization of the human cerebral cortex estimated by intrinsic functional connectivity.Journal of neurophysiology, 2011
work page 2011
-
[27]
Geometric constraints on human brain function.Nature, 618(7965): 566–574, 2023
James C Pang, Kevin M Aquino, Marianne Oldehinkel, Peter A Robinson, Ben D Fulcher, Michael Breakspear, and Alex Fornito. Geometric constraints on human brain function.Nature, 618(7965): 566–574, 2023
work page 2023
-
[28]
The bitter lesson.Incomplete Ideas (blog), 13(1):38, 2019
Richard Sutton. The bitter lesson.Incomplete Ideas (blog), 13(1):38, 2019
work page 2019
-
[29]
Hyung Won Chung. Stanford cs25: V4. https://youtu.be/3gb-ZkVRemQ?si=7FXnklTS9X3FCuv1,
-
[30]
YouTube video, Stanford University
-
[31]
Pycortex: an interactive surface visualizer for fmri.Frontiers in neuroinformatics, 9:23, 2015
James S Gao, Alexander G Huth, Mark D Lescroart, and Jack L Gallant. Pycortex: an interactive surface visualizer for fmri.Frontiers in neuroinformatics, 9:23, 2015
work page 2015
-
[32]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations, 2021. URL https...
work page 2021
-
[33]
Masked autoencoders as spatiotemporal learners
Christoph Feichtenhofer, Yanghao Li, Kaiming He, et al. Masked autoencoders as spatiotemporal learners. Advances in neural information processing systems, 35:35946–35958, 2022
work page 2022
-
[34]
The wu-minn human connectome project: an overview.Neuroimage, 80: 62–79, 2013
David C Van Essen, Stephen M Smith, Deanna M Barch, Timothy EJ Behrens, Essa Yacoub, Kamil Ugurbil, Wu-Minn HCP Consortium, et al. The wu-minn human connectome project: an overview.Neuroimage, 80: 62–79, 2013
work page 2013
-
[35]
Cortical surface-based analysis: I
Anders M Dale, Bruce Fischl, and Martin I Sereno. Cortical surface-based analysis: I. segmentation and surface reconstruction.Neuroimage, 9(2):179–194, 1999
work page 1999
-
[36]
Freesurfer.Neuroimage, 62(2):774–781, 2012
Bruce Fischl. Freesurfer.Neuroimage, 62(2):774–781, 2012
work page 2012
-
[37]
The minimal preprocessing pipelines for the human connectome project.Neuroimage, 80:105–124, 2013
Matthew F Glasser, Stamatios N Sotiropoulos, J Anthony Wilson, Timothy S Coalson, Bruce Fischl, Jesper L Andersson, Junqian Xu, Saad Jbabdi, Matthew Webster, Jonathan R Polimeni, et al. The minimal preprocessing pipelines for the human connectome project.Neuroimage, 80:105–124, 2013
work page 2013
-
[38]
fmriprep: a robust preprocessing pipeline for functional mri.Nature methods, 16(1):111–116, 2019
Oscar Esteban, Christopher J Markiewicz, Ross W Blair, Craig A Moodie, A Ilkay Isik, Asier Erra- muzpe, James D Kent, Mathias Goncalves, Elizabeth DuPre, Madeleine Snyder, et al. fmriprep: a robust preprocessing pipeline for functional mri.Nature methods, 16(1):111–116, 2019
work page 2019
-
[39]
Emily J Allen, Ghislain St-Yves, Yihan Wu, Jesse L Breedlove, Jacob S Prince, Logan T Dowdle, Matthias Nau, Brad Caron, Franco Pestilli, Ian Charest, et al. A massive 7t fmri dataset to bridge cognitive neuroscience and artificial intelligence.Nature neuroscience, 25(1):116–126, 2022
work page 2022
-
[40]
Fidel Alfaro-Almagro, Mark Jenkinson, Neal K Bangerter, Jesper LR Andersson, Ludovica Griffanti, Gwenaëlle Douaud, Stamatios N Sotiropoulos, Saad Jbabdi, Moises Hernandez-Fernandez, Emmanuel Vallee, et al. Image processing and quality control for the first 10,000 brain imaging datasets from uk biobank.Neuroimage, 166:400–424, 2018
work page 2018
-
[41]
Sources and implications of whole-brain fmri signals in humans.Neuroimage, 146:609–625, 2017
Jonathan D Power, Mark Plitt, Timothy O Laumann, and Alex Martin. Sources and implications of whole-brain fmri signals in humans.Neuroimage, 146:609–625, 2017
work page 2017
-
[42]
Videomae v2: Scaling video masked autoencoders with dual masking
Limin Wang, Bingkun Huang, Zhiyu Zhao, Zhan Tong, Yinan He, Yi Wang, Yali Wang, and Yu Qiao. Videomae v2: Scaling video masked autoencoders with dual masking. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14549–14560, 2023
work page 2023
-
[43]
Yu Zhang, Loïc Tetrel, Bertrand Thirion, and Pierre Bellec. Functional annotation of human cognitive states using deep graph convolution.NeuroImage, 231:117847, 2021
work page 2021
-
[44]
Yu Zhang, Nicolas Farrugia, and Pierre Bellec. Deep learning models of cognitive processes constrained by human brain connectomes.Medical image analysis, 80:102507, 2022
work page 2022
-
[45]
Shima Rastegarnia, Marie St-Laurent, Elizabeth DuPre, Basile Pinsard, and Pierre Bellec. Brain decoding of the human connectome project tasks in a dense individual fmri dataset.NeuroImage, 283:120395, 2023
work page 2023
-
[46]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
work page 2014
-
[47]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[48]
Self-supervised learning from images with a joint-embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint-embedding predictive architecture. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15619–15629, 2023
work page 2023
-
[49]
Timothée Darcet, Federico Baldassarre, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Cluster and predict latents patches for improved masked image modeling.Transactions on Machine Learning Research, 2025. ISSN 2835-8856. URLhttps://openreview.net/forum?id=Ycmz7qJxUQ
work page 2025
-
[50]
Michelle Hampson, Naomi R Driesen, Pawel Skudlarski, John C Gore, and R Todd Constable. Brain connectivity related to working memory performance.Journal of Neuroscience, 26(51):13338–13343, 2006
work page 2006
-
[51]
Emily S Finn, Xilin Shen, Dustin Scheinost, Monica D Rosenberg, Jessica Huang, Marvin M Chun, Xenophon Papademetris, and R Todd Constable. Functional connectome fingerprinting: identifying individuals using patterns of brain connectivity.Nature neuroscience, 18(11):1664–1671, 2015. 8
work page 2015
-
[52]
Tong He, Lijun An, Pansheng Chen, Jianzhong Chen, Jiashi Feng, Danilo Bzdok, Avram J Holmes, Simon B Eickhoff, and BT Thomas Yeo. Meta-matching as a simple framework to translate phenotypic predictive models from big to small data.Nature neuroscience, 25(6):795–804, 2022
work page 2022
-
[53]
Masked autoencoders for low-dose ct denoising
Dayang Wang, Yongshun Xu, Shuo Han, and Hengyong Yu. Masked autoencoders for low-dose ct denoising. In2023 IEEE 20th International Symposium on Biomedical Imaging (ISBI), pages 1–4. IEEE, 2023
work page 2023
-
[54]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[55]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[56]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, et al. DINOv2: Learning robust visual features without supervision.Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URLhttps://openreview.net/forum?id=a68SUt6zFt. F...
work page 2024
-
[57]
Flexivit: One model for all patch sizes
Lucas Beyer, Pavel Izmailov, Alexander Kolesnikov, Mathilde Caron, Simon Kornblith, Xiaohua Zhai, Matthias Minderer, Michael Tschannen, Ibrahim Alabdulmohsin, and Filip Pavetic. Flexivit: One model for all patch sizes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14496–14506, 2023
work page 2023
-
[58]
Mindeye2: Shared-subject models enable fmri-to-image with 1 hour of data
Paul Steven Scotti, Mihir Tripathy, Cesar Torrico, Reese Kneeland, Tong Chen, Ashutosh Narang, Charan Santhirasegaran, Jonathan Xu, Thomas Naselaris, Kenneth A Norman, et al. Mindeye2: Shared-subject models enable fmri-to-image with 1 hour of data. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[59]
Mindbridge: A cross-subject brain decoding framework
Shizun Wang, Songhua Liu, Zhenxiong Tan, and Xinchao Wang. Mindbridge: A cross-subject brain decoding framework. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11333–11342, 2024
work page 2024
-
[60]
Yuqin Dai, Zhouheng Yao, Chunfeng Song, Qihao Zheng, Weijian Mai, Kunyu Peng, Shuai Lu, Wanli Ouyang, Jian Yang, and Jiamin Wu. Mindaligner: Explicit brain functional alignment for cross-subject visual decoding from limited fMRI data. InForty-second International Conference on Machine Learning,
-
[61]
URLhttps://openreview.net/forum?id=1W2WlYRq0K
-
[62]
Daniel S Marcus, Michael P Harms, Abraham Z Snyder, Mark Jenkinson, J Anthony Wilson, Matthew F Glasser, Deanna M Barch, Kevin A Archie, Gregory C Burgess, Mohana Ramaratnam, et al. Human connectome project informatics: quality control, database services, and data visualization.Neuroimage, 80:202–219, 2013
work page 2013
-
[63]
Pauli Virtanen, Ralf Gommers, Travis E Oliphant, Matt Haberland, Tyler Reddy, David Cournapeau, Evgeni Burovski, Pearu Peterson, Warren Weckesser, Jonathan Bright, et al. Scipy 1.0: fundamental algorithms for scientific computing in python.Nature methods, 17(3):261–272, 2020
work page 2020
-
[64]
Stephen M Smith, Mark Jenkinson, Mark W Woolrich, Christian F Beckmann, Timothy EJ Behrens, Heidi Johansen-Berg, Peter R Bannister, Marilena De Luca, Ivana Drobnjak, David E Flitney, et al. Advances in functional and structural mr image analysis and implementation as fsl.Neuroimage, 23:S208–S219, 2004
work page 2004
-
[65]
Cortical analysis of heterogeneous clinical brain mri scans for large-scale neuroimaging studies
Karthik Gopinath, Douglas N Greve, Sudeshna Das, Steve Arnold, Colin Magdamo, and Juan Eugenio Iglesias. Cortical analysis of heterogeneous clinical brain mri scans for large-scale neuroimaging studies. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 35–45. Springer, 2023
work page 2023
-
[66]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[67]
SGDR: Stochastic Gradient Descent with Warm Restarts
Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts.arXiv preprint arXiv:1608.03983, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[68]
Augment your batch: Improving generalization through instance repetition
Elad Hoffer, Tal Ben-Nun, Itay Hubara, Niv Giladi, Torsten Hoefler, and Daniel Soudry. Augment your batch: Improving generalization through instance repetition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8129–8138, 2020. 9
work page 2020
-
[69]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
Leland McInnes, John Healy, and James Melville. Umap: Uniform manifold approximation and projection for dimension reduction.arXiv preprint arXiv:1802.03426, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[70]
Spurious reconstruction from brain activity.Neural Networks, page 107515, 2025
Ken Shirakawa, Yoshihiro Nagano, Misato Tanaka, Shuntaro C Aoki, Yusuke Muraki, Kei Majima, and Yukiyasu Kamitani. Spurious reconstruction from brain activity.Neural Networks, page 107515, 2025. 10 A Author contributions Connor Laneconceived and implemented the flat map strategy, developed the project framing, wrote the majority of the code, trained all t...
work page 2025
-
[71]
to yield a valid flat map mask of containing 58212 vertices across both cortical hemispheres. We fit a regular grid of size height × width = 224×560 to the array of (x, y) points contained in the mask. The grid has a pixel resolution of 1.2mm in flat map coordinates, which equals the mean nearest neighbor distance. To project surface-mapped fMRI data onto...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.