Context-Guided Decompilation: A Step Towards Re-executability
Pith reviewed 2026-05-18 01:30 UTC · model grok-4.3
The pith
In-context learning guides LLMs to generate re-executable decompiled code with around 40% higher success rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
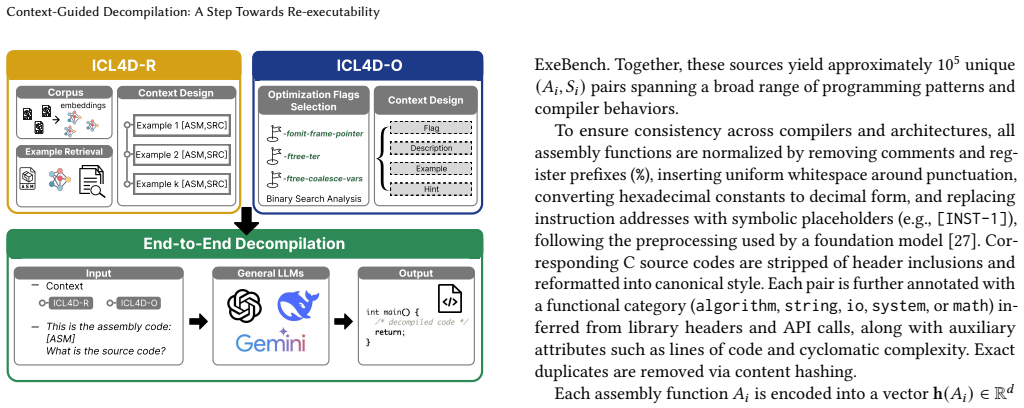
ICL4Decomp is a hybrid decompilation framework that leverages in-context learning to guide LLMs toward generating re-executable source code. It demonstrates around 40% improvement in re-executability over state-of-the-art decompilation methods while maintaining robustness across multiple datasets, optimization levels, and compilers.
What carries the argument
ICL4Decomp, the hybrid framework that supplies in-context learning examples to recover semantic cues lost during compilation and optimization.
Load-bearing premise
That in-context learning examples can reliably supply the semantic cues lost during compilation so the LLM produces code that passes recompilation and execution checks.
What would settle it
A test on binaries from an unseen compiler and optimization level where adding the context examples produces no measurable rise in re-executability rates compared with plain prompting.
Figures



read the original abstract
Binary decompilation plays an important role in software security analysis, reverse engineering, and malware understanding when source code is unavailable. However, existing decompilation techniques often fail to produce source code that can be successfully recompiled and re-executed, particularly for optimized binaries. Recent advances in large language models (LLMs) have enabled neural approaches to decompilation, but the generated code is typically only semantically plausible rather than truly executable, limiting their practical reliability. These shortcomings arise from compiler optimizations and the loss of semantic cues in compiled code, which LLMs struggle to recover without contextual guidance. To address this challenge, we propose ICL4Decomp, a hybrid decompilation framework that leverages in-context learning (ICL) to guide LLMs toward generating re-executable source code. We evaluate our method across multiple datasets, optimization levels, and compilers, demonstrating around 40\% improvement in re-executability over state-of-the-art decompilation methods while maintaining robustness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ICL4Decomp, a hybrid decompilation framework that augments LLM-based decompilation with in-context learning (ICL) examples to recover semantic cues lost during compilation and optimization, thereby producing source code that can be successfully recompiled and re-executed. The central empirical claim is an approximately 40% improvement in re-executability over state-of-the-art decompilation methods, evaluated across multiple datasets, optimization levels, and compilers.
Significance. If the reported gains can be shown to arise specifically from ICL-driven semantic recovery rather than prompt structure or dataset curation, the work would provide a practical advance for reverse engineering and security analysis tools that require executable output.
major comments (2)
- [Abstract and §4 (Evaluation)] The abstract and evaluation sections state a ~40% re-executability improvement, yet supply no concrete metrics (e.g., exact success rates, pass@k definitions), baseline implementations, statistical significance tests, or variance across prompt variations. This absence prevents verification that the lift is load-bearing evidence for the ICL4Decomp framework.
- [§4 (Experimental Setup and Results)] The experimental design does not include ablations that replace ICL examples with (a) zero-shot prompts of identical structure or (b) examples chosen solely for syntactic similarity. Without these controls, the attribution of gains to semantic-cue recovery (variable names, control-flow intent, library semantics) remains unisolated from general prompt-engineering effects.
minor comments (2)
- [Figures 3-5 and Tables 2-4] Figure captions and table headers could more explicitly link re-executability percentages to the precise success criterion (recompilation + execution on held-out test cases).
- [§3 (ICL4Decomp Framework)] The description of how ICL examples are selected and formatted would benefit from a short pseudocode listing or explicit prompt template to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below, agreeing that additional details and controls will strengthen the manuscript, and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract and §4 (Evaluation)] The abstract and evaluation sections state a ~40% re-executability improvement, yet supply no concrete metrics (e.g., exact success rates, pass@k definitions), baseline implementations, statistical significance tests, or variance across prompt variations. This absence prevents verification that the lift is load-bearing evidence for the ICL4Decomp framework.
Authors: We agree that the current presentation of results would benefit from greater specificity to allow independent verification. The manuscript reports an approximate 40% improvement in re-executability but does not enumerate exact per-dataset or per-optimization-level success rates, define the precise success metric (including any pass@k formulation), list baseline implementations in full, or report variance and statistical tests in the abstract or primary evaluation tables. In the revised manuscript we will expand §4 with a detailed results table containing exact re-executability percentages for ICL4Decomp and every baseline, explicitly define the evaluation protocol and success criterion, report standard deviation across prompt variations or random seeds where relevant, and include statistical significance tests (e.g., McNemar’s test on paired success/failure outcomes) to establish that the observed gains are unlikely to be due to chance. These additions will directly address the concern that the reported lift constitutes load-bearing evidence for the framework. revision: yes
-
Referee: [§4 (Experimental Setup and Results)] The experimental design does not include ablations that replace ICL examples with (a) zero-shot prompts of identical structure or (b) examples chosen solely for syntactic similarity. Without these controls, the attribution of gains to semantic-cue recovery (variable names, control-flow intent, library semantics) remains unisolated from general prompt-engineering effects.
Authors: We concur that isolating the contribution of semantically informative ICL examples from generic prompt-engineering effects is important for the central claim. The present evaluation compares ICL4Decomp against published state-of-the-art decompilers but does not contain the requested zero-shot or syntax-only controls. In the revised version we will add two explicit ablations in §4: (a) a zero-shot prompt that preserves the identical overall structure and instructions but supplies no in-context examples, and (b) a syntactic-similarity baseline that retrieves examples using code-embedding cosine similarity without regard to semantic content (variable names, control flow, or library usage). Results from both ablations will be reported alongside the main ICL4Decomp numbers, allowing readers to quantify how much of the observed re-executability gain is attributable to semantic-cue recovery versus prompt structure alone. revision: yes
Circularity Check
No circularity: empirical claims rest on external evaluation
full rationale
The paper presents ICL4Decomp as a hybrid framework that applies in-context learning to guide LLMs for re-executable decompilation and reports an empirical ~40% re-executability gain across datasets, compilers, and optimization levels. No equations, fitted parameters, or derivation steps are described that reduce the central result to inputs defined by the authors themselves. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The evaluation is therefore self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose ICL4Decomp, a hybrid decompilation framework that leverages in-context learning (ICL) to guide LLMs toward generating re-executable source code.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
demonstrating around 40% improvement in re-executability over state-of-the-art decompilation methods
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Constraint-Guided Multi-Agent Decompilation for Executable Binary Recovery
A constraint-guided multi-agent system turns raw decompiler output into re-executable code at 84-97% success rates, outperforming prior LLM decompilation methods on real binaries.
Reference graph
Works this paper leans on
-
[1]
d.].AMP: Assured Micropatching | DARPA
[n. d.].AMP: Assured Micropatching | DARPA. https://www.darpa.mil/research/ programs/assured-micropatching
-
[2]
https://arpa-h.gov/explore-funding/programs/ digiheals
2023.DIGIHEALS | ARPA-H. https://arpa-h.gov/explore-funding/programs/ digiheals
work page 2023
-
[3]
d.].IDA Pro: Powerful Disassembler, Decompiler & Debugger
[n. d.].IDA Pro: Powerful Disassembler, Decompiler & Debugger. https://hex- rays.com/ida-pro
-
[4]
National Security Agency 2025.NationalSecurityAgency/Ghidra. National Secu- rity Agency. https://github.com/NationalSecurityAgency/ghidra
work page 2025
-
[5]
https://arpa-h.gov/explore-funding/programs/ upgrade
2024.UPGRADE | ARPA-H. https://arpa-h.gov/explore-funding/programs/ upgrade
work page 2024
-
[6]
Jordi Armengol-Estapé, Jackson Woodruff, Alexander Brauckmann, José Wesley De Souza Magalhães, and Michael F. P. O’Boyle. 2022. ExeBench: An ML-Scale Dataset of Executable C Functions. InProceedings of the 6th ACM SIGPLAN International Symposium on Machine Programming. ACM, San Diego CA USA, 50–59. doi:10.1145/3520312.3534867
-
[7]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program synthesis with large language models.arXiv preprint arXiv:2108.07732(2021). Context-Guided Decompilation: A Step Towards Re-executability
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al. 2020. Language Models are Few- Shot Learners.Advances in Neural Information Processing Systems (NeurIPS) (2020)
work page 2020
-
[9]
Kevin Cao and Kevin Leach. 2023. Revisiting deep learning for variable type recovery. In2023 IEEE/ACM 31st International Conference on Program Compre- hension (ICPC). IEEE, 275–279
work page 2023
-
[10]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, et al. 2021. Evaluating Large Lan- guage Models Trained on Code.arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Cristina Cifuentes and K John Gough. 1995. Decompilation of binary programs. Software: Practice and Experience25, 7 (1995), 811–829
work page 1995
-
[12]
Cristina Cifuentes, Trent Waddington, and Mike Van Emmerik. 2001. Computer security analysis through decompilation and high-level debugging. InProceedings Eighth Working Conference on Reverse Engineering. IEEE, 375–380
work page 2001
-
[13]
Palacio, Dipin Khati, Henry Burke, and Denys Poshyvanyk
Carlos Eduardo C. Dantas, Adriano M. Rocha, and Marcelo A. Maia. 2023. How do Developers Improve Code Readability? An Empirical Study of Pull Requests. In2023 IEEE International Conference on Software Maintenance and Evolution (ICSME). 110–122. doi:10.1109/ICSME58846.2023.00022
-
[14]
Benedetta Donato, Leonardo Mariani, Daniela Micucci, and Oliviero Riganelli
- [15]
-
[16]
A Survey on In-context Learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Tianyu Liu, Baobao Chang, Xu Sun, Lei Li, and Zhifang Sui. 2024.A Survey on In-Context Learning. arXiv:2301.00234 [cs] doi:10.48550/arXiv.2301.00234
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2301.00234 2024
-
[17]
Luke Dramko, Claire Le Goues, and Edward J. Schwartz. 2025.Idioms: Neural De- compilation With Joint Code and Type Definition Prediction. arXiv:2502.04536 [cs] doi:10.48550/arXiv.2502.04536
-
[18]
2025.ReF Decompile: Relabeling and Function Call Enhanced Decompile
Yunlong Feng, Bohan Li, Xiaoming Shi, Qingfu Zhu, and Wanxiang Che. 2025.ReF Decompile: Relabeling and Function Call Enhanced Decompile. arXiv:2502.12221 [cs] doi:10.48550/arXiv.2502.12221
-
[19]
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, and Ming Zhou. 2020. CodeBERT: A Pre-Trained Model for Programming and Natural Languages.arXiv preprint arXiv:2002.08155(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[20]
Daniel Fried, Kevin Ellis, Maxwell Nye, Edward Chen, and et al. 2023. InCoder: A Generative Model for Code Infilling and Synthesis.Transactions of the Association for Computational Linguistics (TACL)(2023)
work page 2023
-
[21]
Cheng Fu, Huili Chen, Haolan Liu, Xinyun Chen, Yuandong Tian, Farinaz Koushanfar, and Jishen Zhao. 2019. Coda: An End-to-End Neural Program Decompiler. InAdvances in Neural Information Processing Systems(2019), Vol. 32. Curran Associates, Inc. https://proceedings.neurips.cc/paper_files/paper/2019/ hash/093b60fd0557804c8ba0cbf1453da22f-Abstract.html
work page 2019
-
[22]
Zeyu Gao, Yuxin Cui, Hao Wang, Siliang Qin, Yuanda Wang, Bolun Zhang, and Chao Zhang. 2025.DecompileBench: A Comprehensive Benchmark for Evaluating Decompilers in Real-World Scenarios. arXiv:2505.11340 [cs] doi:10.48550/arXiv. 2505.11340
work page internal anchor Pith review doi:10.48550/arxiv 2025
- [23]
-
[24]
Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Nan Duan, and Ming Zhou. 2021. GraphCodeBERT: Pre-training Code Representations with Data Flow.arXiv preprint arXiv:2009.08366(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[25]
Daya Guo, Duyu Tang, Nan Duan, and Ming Zhou. 2022. UniXCoder: Unified Cross-Modal Pre-training for Code Representation.Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL)(2022)
work page 2022
-
[26]
Peiwei Hu, Ruigang Liang, and Kai Chen. 2024. DeGPT: Optimizing Decompiler Output with LLM. InProceedings 2024 Network and Distributed System Security Symposium(San Diego, CA, USA, 2024). Internet Society. doi:10.14722/ndss.2024. 24401
-
[27]
Tao Huang, Zhihong Sun, Zhi Jin, Ge Li, and Chen Lyu. 2024. Knowledge-aware code generation with large language models. InProceedings of the 32nd IEEE/ACM International Conference on Program Comprehension. 52–63
work page 2024
- [28]
- [29]
-
[30]
Katz, Jason Ruchti, and Eric Schulte
Deborah S. Katz, Jason Ruchti, and Eric Schulte. 2018. Using Recurrent Neu- ral Networks for Decompilation. In2018 IEEE 25th International Conference on Software Analysis, Evolution and Reengineering (SANER)(2018-03). 346–356. doi:10.1109/SANER.2018.8330222
-
[31]
Omer Katz, Yuval Olshaker, Yoav Goldberg, and Eran Yahav. 2019.Towards Neural Decompilation. arXiv:1905.08325 [cs] doi:10.48550/arXiv.1905.08325
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1905.08325 2019
-
[32]
Hyungsub Kim, Muslum Ozgur Ozmen, Z Berkay Celik, Antonio Bianchi, and Dongyan Xu. 2022. Pgpatch: Policy-guided logic bug patching for robotic vehicles. In2022 IEEE Symposium on Security and Privacy (SP). IEEE, 1826–1844
work page 2022
-
[33]
Jason Kim, Daniel Genkin, and Kevin Leach. 2023. Revisiting lightweight compiler provenance recovery on ARM binaries. In2023 IEEE/ACM 31st International Conference on Program Comprehension (ICPC). IEEE, 292–303
work page 2023
-
[34]
Jeremy Lacomis, Pengcheng Yin, Edward Schwartz, Miltiadis Allamanis, Claire Le Goues, Graham Neubig, and Bogdan Vasilescu. 2019. DIRE: A Neural Approach to Decompiled Identifier Naming. In2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE)(San Diego, CA, USA, 2019-11). IEEE, 628–639. doi:10.1109/ASE.2019.00064
-
[35]
Hung Le, Yue Wang, Akhilesh Deepak Gotmare Nguyen, Shafiq Joty, and Steven CH Hoi. 2022. CodeRL: Mastering Code Generation through Pre-trained Models and Deep Reinforcement Learning. InProceedings of the 36th Conference on Neural Information Processing Systems (NeurIPS)
work page 2022
-
[36]
Raymond Li, Loubna Ben Allal, Loubna Ben Allal, Niklas Muennighoff, and et al
-
[37]
StarCoder: May the Source Be with You!Transactions on Machine Learning Research (TMLR)(2023)
work page 2023
-
[38]
Yujia Li, David Choi, Junyoung Chung, Chris Cushman, Misha Denil, Tejas D. Han, Nick Jackson, et al. 2022. Competition-Level Code Generation with Alpha- Code.Science378, 6624 (2022), 1092–1097
work page 2022
-
[39]
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. InText summarization branches out. 74–81
work page 2004
- [40]
- [41]
-
[42]
Aman Madaan, Niket Tandon, Amir Yazdanbakhsh, and Peter Clark. 2023. Self- Refine: Iterative Refinement with Self-Feedback.arXiv preprint arXiv:2303.17651 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [43]
-
[44]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics. 311–318
work page 2002
-
[45]
Baptiste Roziere, Loubna Ben Allal, Raymond Li, and et al. 2023. Code Llama: Open Foundation Models for Code.arXiv preprint arXiv:2308.12950(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
Agnia Sergeyuk, Olga Lvova, Sergey Titov, Anastasiia Serova, Farid Bagirov, Evgeniia Kirillova, and Timofey Bryksin. 2024. Reassessing java code readability models with a human-centered approach. InProceedings of the 32nd IEEE/ACM International Conference on Program Comprehension. 225–235
work page 2024
- [47]
-
[48]
Noah Shinn, Fares Labash, Shreya Gopinath, Aman Madaan, and Niket Tandon
-
[49]
Reflexion: Language Agents with Verbal Reinforcement Learning.arXiv preprint arXiv:2303.11366(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [50]
-
[51]
Ilya Sutskever, Oriol Vinyals, and Quoc V Le. 2014. Sequence to sequence learning with neural networks.Advances in neural information processing systems27 (2014)
work page 2014
-
[52]
Llm4decompile: Decompiling binary code with large language models
Hanzhuo Tan, Qi Luo, Jing Li, and Yuqun Zhang. 2024.LLM4Decompile: De- compiling Binary Code with Large Language Models. arXiv:2403.05286 [cs] doi:10.48550/arXiv.2403.05286
-
[53]
2025.URL:https://arxiv.org/abs/2505.12668
Hanzhuo Tan, Xiaolong Tian, Hanrui Qi, Jiaming Liu, Zuchen Gao, Siyi Wang, Qi Luo, Jing Li, and Yuqun Zhang. 2025.Decompile-Bench: Million-Scale Binary- Source Function Pairs for Real-World Binary Decompilation. arXiv:2505.12668 [cs] doi:10.48550/arXiv.2505.12668
-
[54]
Jacob Trentini, Victor Liu, Yiming Peng, and Ziliang Zong. 2025. Advancing Large Language Models in Code Generation: Usaco Benchmark and Bug Mit- igation Insights. In2025 IEEE/ACM 33rd International Conference on Program Comprehension (ICPC). IEEE, 01–12
work page 2025
- [55]
-
[56]
Yue Wang, Weishi Wang, Shafiq Joty, and Steven CH Hoi. 2021. CodeT5: Identifier- aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation.Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP)(2021)
work page 2021
-
[57]
Noam Wies, Yoav Levine, and Amnon Shashua. 2023. The learnability of in- context learning.Advances in Neural Information Processing Systems36 (2023), 36637–36651. Wang et al
work page 2023
-
[58]
2013.Compiler design: syntactic and semantic analysis
Reinhard Wilhelm, Helmut Seidl, and Sebastian Hack. 2013.Compiler design: syntactic and semantic analysis. Springer Science & Business Media
work page 2013
-
[59]
Danning Xie, Zhuo Zhang, Nan Jiang, Xiangzhe Xu, Lin Tan, and Xiangyu Zhang
-
[60]
InProceedings of the 2024 ACM SIGSAC Conference on Computer and Communications Security (CCS ’24)
ReSym: Harnessing LLMs to Recover Variable and Data Structure Symbols from Stripped Binaries. InProceedings of the 2024 ACM SIGSAC Conference on Computer and Communications Security (CCS ’24). –. doi:10.1145/3658644.3670340
-
[61]
Khaled Yakdan, Sergej Dechand, Elmar Gerhards-Padilla, and Matthew Smith
-
[62]
In2016 IEEE Symposium on Security and Privacy (SP)
Helping johnny to analyze malware: A usability-optimized decompiler and malware analysis user study. In2016 IEEE Symposium on Security and Privacy (SP). IEEE, 158–177
-
[63]
Yuwei Yang, Skyler Grandel, Jeremy Lacomis, Edward Schwartz, Bogdan Vasilescu, Claire Le Goues, and Kevin Leach. 2025. A Human Study of Au- tomatically Generated Decompiler Annotations. In2025 55th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN). IEEE, 129– 142
work page 2025
- [64]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.