Quality Assurance of LLM-generated Code: Addressing Non-Functional Quality Characteristics
Pith reviewed 2026-05-17 22:48 UTC · model grok-4.3
The pith
LLM-generated code shows misalignment on non-functional qualities like maintainability and security despite functional correctness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Guided by the ISO/IEC 25010 quality model, the multi-methods study shows existing research primarily emphasizes security, performance efficiency, and maintainability; practitioners instead prioritize maintainability and readability; and empirical patching of real-world issues with three LLMs reveals instability when attempting to optimize these attributes through prompts.
What carries the argument
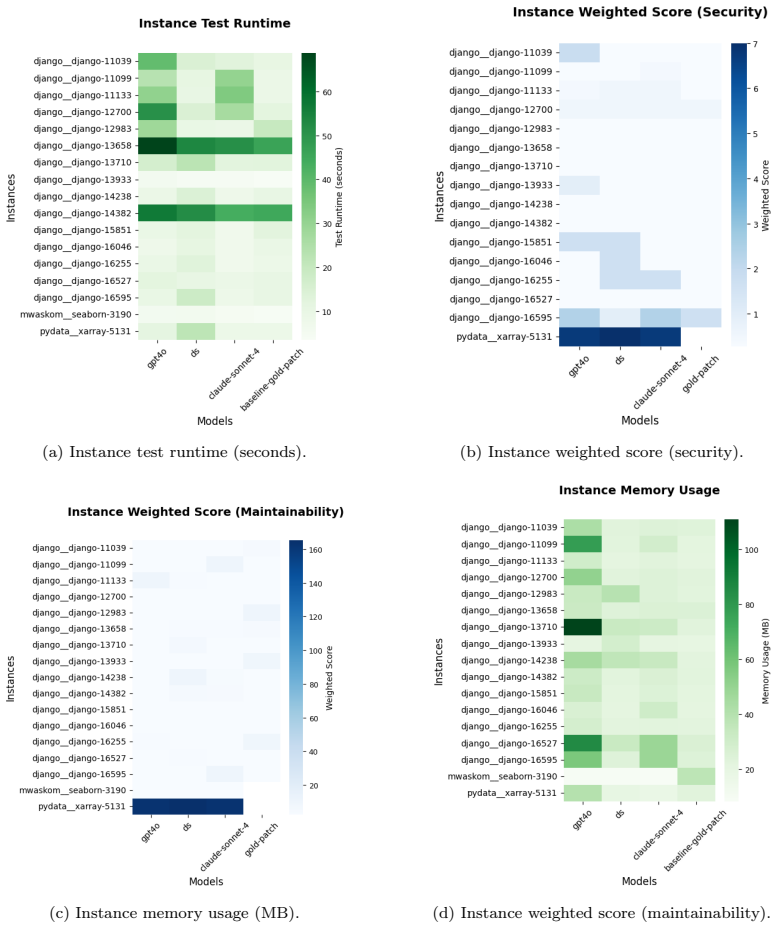
Multi-methods evaluation that combines a review of 109 papers, practitioner workshops, and empirical tests of LLM-generated patches on real software issues, centered on the attributes of security, maintainability, and performance efficiency.
If this is right
- Quality assurance mechanisms need integration into LLM code generation pipelines so outputs pass with quality rather than only functional tests.
- Prompt engineering alone proves unstable for reliably improving non-functional qualities in practical software engineering tasks.
- Generated code risks accelerating technical debt accumulation if maintainability and readability remain unaddressed.
- Research attention should broaden to understudied quality attributes beyond the current emphasis on security, performance, and maintainability.
Where Pith is reading between the lines
- Teams adopting LLMs for code may require new post-generation review tools focused on maintainability metrics.
- Future model training could benefit from datasets weighted toward readable and maintainable examples to reduce the observed gaps.
- Widespread use of current LLMs for development might increase long-term maintenance costs unless quality controls are added.
Load-bearing premise
The three chosen LLMs, the selected real-world issues, and the specific metrics for security, maintainability, and performance efficiency are representative enough to support general claims about LLM-generated code quality.
What would settle it
A larger study with additional LLMs, more varied real-world issues, and broader quality metrics that finds stable high scores across non-functional attributes would indicate the observed misalignment does not hold generally.
Figures














read the original abstract
In recent years, large language models have been widely integrated into software engineering workflows, supporting tasks like code generation. While prior evaluations focus on functional correctness, there is still a limited understanding of the non-functional quality characteristics of generated code. Guided by the ISO/IEC 25010 quality model, this study adopts a multi-methods approach comprising three complementary elements: a literature review of 109 papers, two industry workshops with practitioners from multiple organizations, and an empirical analysis of patching real-world software issues using three LLMs. Motivated by insights from both the literature and practitioners, the empirical study examined the quality of generated patches regarding security, maintainability, and performance efficiency, which were identified as critical code-level quality attributes. Our results indicate that existing research primarily emphasizes security, performance efficiency, and maintainability, while other quality attributes are understudied. In contrast, practitioners prioritize maintainability and readability, warning that generated code may accelerate the accumulation of technical debt. The empirical evaluation demonstrates the instability of optimizing NFQCs through prompts in practical software engineering settings. Overall, our findings expose a misalignment between academic focus, industry priorities, and observed model behavior, highlighting the need to integrate quality assurance mechanisms into LLM code generation pipelines to ensure that future generated code not only passes tests but truly passes with quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM-generated code exhibits a misalignment between academic research priorities (emphasizing security, performance efficiency, and maintainability per a review of 109 papers), industry/practitioner priorities (maintainability and readability to avoid technical debt, from two workshops), and observed LLM behavior (instability when optimizing these NFQCs via prompts in an empirical patching study using three LLMs on real-world issues, guided by ISO/IEC 25010). It concludes that quality assurance mechanisms must be integrated into LLM code generation pipelines.
Significance. If the empirical instability results and misalignment hold under broader testing, the work would be significant for SE practice by motivating QA integration beyond functional correctness testing. The multi-methods design (literature synthesis + practitioner input + direct experiments) is a strength that provides contextual grounding and falsifiable observations about prompt-based NFQC optimization.
major comments (2)
- [Empirical evaluation] Empirical evaluation section: the abstract and empirical component provide no detail on concrete metrics, tools, or procedures used to assess security, maintainability, and performance efficiency of the generated patches, nor on inter-rater reliability or statistical tests. This directly affects the load-bearing claim of 'instability of optimizing NFQCs through prompts' and the resulting misalignment conclusion.
- [Empirical study] Empirical study (patching real-world issues): the representativeness of the three chosen LLMs and the selected real-world issues is not justified or tested via sensitivity analysis. Because the central misalignment claim and call for QA mechanisms rest on generalizing from these specific observations, limited sampling risks making the instability finding artifactual rather than general.
minor comments (2)
- [Abstract] Abstract: the summary of results could preview one or two concrete observations from the empirical patching (e.g., specific instability patterns) to better orient readers before the full methods are described.
- [Literature review] Ensure the literature review section explicitly states the search strategy, inclusion/exclusion criteria, and any coding scheme used to categorize the 109 papers' focus on NFQCs, to support the academic-vs-industry comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for strengthening the transparency and generalizability of our empirical component. We address each major comment below, indicating planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Empirical evaluation] Empirical evaluation section: the abstract and empirical component provide no detail on concrete metrics, tools, or procedures used to assess security, maintainability, and performance efficiency of the generated patches, nor on inter-rater reliability or statistical tests. This directly affects the load-bearing claim of 'instability of optimizing NFQCs through prompts' and the resulting misalignment conclusion.
Authors: We agree that additional methodological detail is needed to support the instability claim. In the revised manuscript we will expand the empirical evaluation section with: (1) explicit metrics for each NFQC (e.g., maintainability via cyclomatic complexity, code duplication, and cognitive complexity measured with SonarQube; security via static analysis with CodeQL and Bandit for common vulnerabilities; performance efficiency via execution time and memory profiling on standardized benchmarks); (2) the exact prompting templates and patch-generation procedure; (3) inter-rater reliability statistics (Cohen’s kappa) for any manual quality assessments performed by the authors; and (4) the statistical tests applied (Wilcoxon signed-rank tests with effect sizes and p-values) to compare prompt-optimization outcomes. These additions will make the evidence for prompt instability more transparent and reproducible. revision: yes
-
Referee: [Empirical study] Empirical study (patching real-world issues): the representativeness of the three chosen LLMs and the selected real-world issues is not justified or tested via sensitivity analysis. Because the central misalignment claim and call for QA mechanisms rest on generalizing from these specific observations, limited sampling risks making the instability finding artifactual rather than general.
Authors: We acknowledge the sampling limitation. The three LLMs were chosen to represent distinct model families (closed-source frontier, hybrid, and open-source) that were publicly accessible during the study period; the issues were selected from actively maintained GitHub repositories with real developer-reported bugs. A full sensitivity analysis across additional models and issue corpora was not feasible within the original resource constraints. In the revision we will (a) add an explicit justification subsection for the model and issue selection criteria, (b) include a dedicated “Threats to Validity and Limitations” paragraph that discusses the risks of limited sampling and the exploratory nature of the study, and (c) moderate the generalization language while retaining the core observation that prompt-based NFQC optimization proved unstable in the tested settings. We view this as a partial revision because a comprehensive sensitivity study would require a follow-up experiment beyond the scope of the current work. revision: partial
Circularity Check
No significant circularity; claims rest on independent empirical sources
full rationale
The paper's central claim of misalignment between academic focus, industry priorities, and LLM behavior is derived from three independent elements: a review of 109 external papers, two practitioner workshops, and direct experiments patching real-world issues with three LLMs while measuring security, maintainability, and performance efficiency per ISO 25010. No equations, fitted parameters, self-definitional loops, or load-bearing self-citations reduce any result to the paper's own inputs by construction. The instability observation and call for QA mechanisms follow directly from the reported empirical outcomes rather than from renaming or smuggling prior author work.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our results indicate that existing research primarily emphasizes security, performance efficiency, and maintainability... improvements in one quality dimension often come at the cost of others.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
risk_score = Σ W_severity × W_precision × trigger_count
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
Contract Based Verification of Non-functional Requirements for Embedded Automotive C Code
The authors define general non-functional rules for C modules, propose an interface contract language, implement a Frama-C checker plugin, and demonstrate verification on two Scania truck codebases alongside ACSL func...
-
"Refactoring Runaway": Understanding and Mitigating Tangled Refactorings in Coding Agents for Issue Resolution
Empirical study finds coding agents produce fewer and less intense tangled refactorings than humans on Multi-SWE-bench; a refactoring-aware refinement improves compilability from 19.34% to 38.33% and resolves 2.79% mo...
-
Sustainable Code Generation Using Large Language Models: A Systematic Literature Review
A systematic review finds research on the sustainability of LLM-generated code to be limited, fragmented, and without accepted frameworks for measurement or benchmarking.
Reference graph
Works this paper leans on
-
[1]
Starcoder: may the source be with you! Trans. Mach. Learn. Res
-
[2]
URL:https://openreview.net/forum?id=KoFOg41haE. Li, Y., Choi, D.H., Chung, J., Kushman, N., Schrittwieser, J., Leblond, R., et al., 2022. Competition-level code generation with alpha- code. Science 378, 1092–1097. URL:https://www.science.org/ doi/abs/10.1126/science.abq1158, doi:10.1126/science.abq1158, arXiv:https://www.science.org/doi/pdf/10.1126/scienc...
-
[3]
URL:https://doi.org/10.1145/3583131.3590481, doi:10.1145/ 3583131.3590481. Lovable, 2024. Build apps with an AI engineer. URL:https://lovable.dev. accessed: May 13, 2025. Luo, Z., Xu, C., Zhao, P., Sun, Q., Geng, X., Hu, W., Tao, C., Ma, J., Lin, Q., Jiang, D., 2024. Wizardcoder: Empowering code large language models with evol-instruct, in: The Twelfth In...
-
[4]
URL:https://doi.org/10.1109/MSEC.2024.3355713, doi:10.1109/ MSEC.2024.3355713. Nguyen, N., Nadi, S., 2022. An empirical evaluation of github copilot’s code suggestions, in: 19thIEEE/ACMInternationalConferenceonMiningSoft- ware Repositories, MSR 2022, Pittsburgh, PA, USA, May 23-24, 2022, ACM. pp. 1–5. URL:https://doi.org/10.1145/3524842.3528470, doi:10.11...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.