Multimodal Large Language Models with Adaptive Preference Optimization for Sequential Recommendation
Pith reviewed 2026-05-17 06:12 UTC · model grok-4.3
The pith
HaNoRec improves multimodal LLM recommendations by weighting harder training samples and adding Gaussian noise to correct modality biases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HaNoRec integrates hardness-aware and noise-regularized preference optimization into multimodal LLMs for sequential recommendation. Optimization weights are adjusted dynamically according to the estimated hardness of each training sample and the policy model's current responsiveness, so harder examples receive more emphasis during training. Gaussian-perturbed distribution optimization is then applied to the output logits to strengthen cross-modal semantic consistency and reduce the modality bias inherited from the reference model.
What carries the argument
HaNoRec, a hardness-aware and noise-regularized preference optimization method that reweights samples by estimated difficulty and applies Gaussian perturbations to output logits.
If this is right
- Prioritizing harder examples during optimization reduces overfitting to easy negatives sampled from user histories.
- Gaussian perturbations on output logits produce more consistent alignments between textual descriptions and visual item features.
- The policy model becomes less constrained by biases in the fixed reference model, especially across longer user sequences.
- Recommendation performance improves when visual signals like product images or movie posters are incorporated into preference learning.
Where Pith is reading between the lines
- The same hardness estimation and noise regularization could be tested on non-recommendation tasks that involve long multimodal sequences.
- If the method scales, it may reduce the need for extensive negative sampling strategies in other preference optimization pipelines.
- Cross-modal consistency gains might translate to better handling of noisy or missing visual data in real-world recommendation settings.
Load-bearing premise
Hardness of training samples can be estimated reliably during training and Gaussian perturbations on logits will reduce cross-modal bias without creating new instabilities or lowering overall recommendation quality.
What would settle it
An ablation study that removes either the hardness-based reweighting or the Gaussian logit perturbations and measures whether recommendation metrics such as NDCG or Hit Rate on standard sequential datasets remain unchanged or degrade.
Figures





read the original abstract
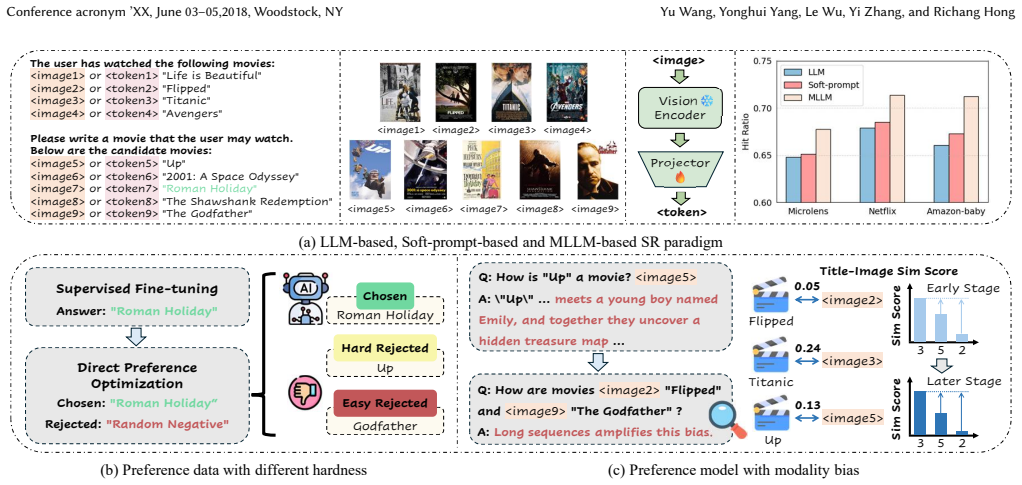
Recent advances in Large Language Models (LLMs) have opened new avenues for sequential recommendation by enabling natural language reasoning over user behavior sequences. A common approach formulates recommendation as a language modeling task, where interaction histories are transformed into prompts and user preferences are learned via supervised fine-tuning. However, these methods operate solely in the textual modality and often miss users' fine-grained interests, especially when shaped by rich visual signals such as product images or movie posters. Multimodal Large Language Models (MLLMs) offer a promising alternative by aligning text and vision in a shared semantic space. A prevalent training paradigm applies Supervised Fine-Tuning (SFT) followed by Direct Preference Optimization (DPO) to model user preferences. Yet, two core challenges remain: 1) Imbalanced sample hardness, where random negative sampling causes overfitting on easy examples and under-training on hard ones; 2) Cross-modal semantic bias, where the fixed reference model in DPO prevents the policy model from correcting modality misalignments--especially over long sequences. To address these issues, we propose a Multimodal LLM framework that integrates Hardness-aware and Noise-regularized preference optimization for Recommendation (HaNoRec). Specifically, HaNoRec dynamically adjusts optimization weights based on both the estimated hardness of each training sample and the policy model's real-time responsiveness, prioritizing harder examples. It further introduces Gaussian-perturbed distribution optimization on output logits to enhance cross-modal semantic consistency and reduce modality bias inherited from the reference model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HaNoRec, a Multimodal Large Language Model framework for sequential recommendation. It integrates hardness-aware preference optimization that dynamically reweights DPO-style updates according to per-sample hardness estimates and the policy model's real-time responsiveness, together with noise-regularized optimization that applies Gaussian perturbations to output logits in order to improve cross-modal semantic consistency and reduce modality bias inherited from the fixed reference model.
Significance. If the adaptive reweighting and logit perturbation mechanisms can be shown to operate as described without introducing instabilities or circular dependencies, the work would address two practically relevant limitations of standard SFT+DPO pipelines for MLLM-based recommendation and could improve performance on visually rich item sequences.
major comments (2)
- [Abstract] Abstract: the hardness-aware component is described as dynamically adjusting weights 'based on both the estimated hardness of each training sample and the policy model's real-time responsiveness,' yet no metric, estimator, or update rule is supplied. Because this reweighting is load-bearing for the claim of prioritizing harder examples, the absence of a concrete definition leaves open the risk that responsiveness correlates with quantities already shaped by the current policy (e.g., loss or logit magnitude), potentially creating a self-reinforcing loop rather than correcting intrinsic hardness.
- [Abstract] Abstract: the noise-regularized component asserts that 'Gaussian-perturbed distribution optimization on output logits' will 'enhance cross-modal semantic consistency and reduce modality bias inherited from the reference model.' No derivation, variance schedule, or propagation analysis through the multimodal alignment layers is given, so it remains unclear whether the isotropic perturbation isolates and corrects modality misalignment or simply adds generic smoothing that may degrade ranking precision.
minor comments (1)
- The abstract would be strengthened by a single high-level equation or pseudocode block that defines the combined loss or the responsiveness measure.
Simulated Author's Rebuttal
Thank you for your valuable comments on our paper. We have reviewed the concerns about the descriptions in the abstract and will update the manuscript accordingly to provide more concrete information.
read point-by-point responses
-
Referee: [Abstract] Abstract: the hardness-aware component is described as dynamically adjusting weights 'based on both the estimated hardness of each training sample and the policy model's real-time responsiveness,' yet no metric, estimator, or update rule is supplied. Because this reweighting is load-bearing for the claim of prioritizing harder examples, the absence of a concrete definition leaves open the risk that responsiveness correlates with quantities already shaped by the current policy (e.g., loss or logit magnitude), potentially creating a self-reinforcing loop rather than correcting intrinsic hardness.
Authors: We acknowledge the need for more specificity in the abstract. The full paper provides the hardness estimator as the per-sample DPO loss and the responsiveness as the policy model's update magnitude on the sample. The reweighting is formulated to use a lagged version of the responsiveness to break any potential self-reinforcing loop. We will revise the abstract to briefly describe these elements and refer readers to Section 3 for the full details and analysis demonstrating the absence of circular dependencies. revision: yes
-
Referee: [Abstract] Abstract: the noise-regularized component asserts that 'Gaussian-perturbed distribution optimization on output logits' will 'enhance cross-modal semantic consistency and reduce modality bias inherited from the reference model.' No derivation, variance schedule, or propagation analysis through the multimodal alignment layers is given, so it remains unclear whether the isotropic perturbation isolates and corrects modality misalignment or simply adds generic smoothing that may degrade ranking precision.
Authors: We agree that additional technical details would strengthen the abstract. In the revised version, we will include a short description of the Gaussian perturbation variance schedule and note that the analysis in Section 3.3 shows the perturbation is propagated through the multimodal layers in a way that specifically encourages correction of modality bias. We will also clarify that empirical results indicate no degradation in ranking precision. The full derivation is available in the appendix. revision: yes
Circularity Check
HaNoRec framework introduces adaptive weighting and logit perturbations without reducing claims to self-referential inputs or fitted predictions.
full rationale
The paper outlines a multimodal LLM approach extending SFT and DPO with hardness-aware reweighting based on sample difficulty and policy responsiveness plus Gaussian perturbations on output logits to address cross-modal bias. No equations or derivations are presented that equate a claimed prediction or optimization outcome directly to its own estimation procedure by construction. Hardness and responsiveness are described as dynamic quantities computed from training data and model behavior, but without shown reductions that make the reweighting tautological or force the noise regularization to be equivalent to the bias it targets. The approach cites standard preference optimization literature without load-bearing self-citations that import uniqueness theorems or smuggle ansatzes. The derivation remains self-contained with independent methodological content.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
HaRS dynamically adjusts optimization weights based on both the estimated hardness of each training sample and the policy model's real-time responsiveness... Gaussian-perturbed distribution optimization on output logits
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a Multimodal LLM framework that integrates Hardness-aware and Noise-regularized preference optimization for Recommendation (HaNoRec)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
ProMax: Exploring the Potential of LLM-derived Profiles with Distribution Shaping for Recommender Systems
ProMax uses dense retrieval and dual distribution reshaping on LLM-derived profiles to guide recommender models toward preferences for unseen items, substantially boosting base model performance on public datasets.
-
DIAURec: Dual-Intent Space Representation Optimization for Recommendation
DIAURec unifies intent and language modeling to reconstruct and optimize representations in prototype and distribution spaces, outperforming baselines on three datasets.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 Technical Report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Alexander A Alemi, Ian Fischer, Joshua V Dillon, and Kevin Murphy. 2017. Deep Variational Information Bottleneck. InICLR
work page 2017
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. 2025. Qwen2.5-VL Technical Rep...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, and Mike Zheng Shou. 2024. Hallucination of Multimodal Large Language Models: A Survey.arXiv preprint arXiv:2404.18930(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Keqin Bao, Jizhi Zhang, Wenjie Wang, Yang Zhang, Zhengyi Yang, Yanchen Luo, Chong Chen, Fuli Feng, and Qi Tian. 2025. A Bi-Step Grounding Paradigm for Large Language Models in Recommendation Systems.ACM Transactions on Recommender Systems (TORS)3, 4 (2025), 1–27
work page 2025
-
[6]
Keqin Bao, Jizhi Zhang, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He. 2023. TallRec: An Effective and Efficient Tuning Framework to Align lLarge Language Model with Recommendation. InRecSys. 1007–1014
work page 2023
-
[7]
Jiawei Chen, Hongyu Lin, Xianpei Han, and Le Sun. 2024. Benchmarking Large Language Models in Retrieval-Augmented Generation. InAAAI, Vol. 38. 17754– 17762
work page 2024
-
[8]
Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Bengio. 2014. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv preprint arXiv:1412.3555(2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[9]
Sunhao Dai, Chen Xu, Shicheng Xu, Liang Pang, Zhenhua Dong, and Jun Xu
-
[10]
Bias and Unfairness in Information Retrieval Systems: New Challenges in the LLM Era. InKDD. 6437–6447
-
[11]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of Deep Bidirectional Transformers for Language Understanding. In NAACL. 4171–4186
work page 2019
-
[12]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The Llama 3 Herd of Models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Chongming Gao, Ruijun Chen, Shuai Yuan, Kexin Huang, Yuanqing Yu, and Xiangnan He. 2025. SPRec: Self-Play to Debias LLM-based Recommendation. In WWW. 5075–5084
work page 2025
- [14]
-
[15]
Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. 2020. Lightgcn: Simplifying and Powering Graph Convolution Network for Recommendation. InSIGIR. 639–648
work page 2020
-
[16]
Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, and Tat-Seng Chua. 2017. Neural Collaborative Filtering. InWWW. 173–182
work page 2017
-
[17]
Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk
-
[18]
Session-based Recommendations with Recurrent Neural Networks. In ICLR
-
[19]
Yupeng Hou, Jiacheng Li, Zhankui He, An Yan, Xiusi Chen, and Julian McAuley
-
[20]
Bridging language and items for retrieval and recommendation.arXiv preprint arXiv:2403.03952(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. 2022. Lora: Low-rank Adaptation of Large Language Models.. InICLR
work page 2022
-
[22]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. GPT-4o System Card.arXiv preprint arXiv:2410.21276(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Jiaming Ji, Mickel Liu, Josef Dai, Xuehai Pan, Chi Zhang, Ce Bian, Boyuan Chen, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. 2023. Beavertails: Towards Improved Safety Alignment of LLM via a Human-Preference Dataset. InNeurIPS, Vol. 36. 24678–24704
work page 2023
-
[24]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive Sequential Recom- mendation. InICDM. 197–206
work page 2018
-
[25]
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling Laws for Neural Language Models.arXiv preprint arXiv:2001.08361(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[26]
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. 2024. LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models.arXiv preprint arXiv:2407.07895(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [27]
- [28]
-
[29]
Jiayi Liao, Sihang Li, Zhengyi Yang, Jiancan Wu, Yancheng Yuan, Xiang Wang, and Xiangnan He. 2024. Llara: Large Language-Recommendation Assistant. In SIGIR. 1785–1795
work page 2024
- [30]
-
[31]
Jinda Lu, Junkang Wu, Jinghan Li, Xiaojun Jia, Shuo Wang, YiFan Zhang, Junfeng Fang, Xiang Wang, and Xiangnan He. 2025. DAMO: Data-and Model-aware Alignment of Multi-modal LLMs. InICML
work page 2025
-
[32]
Yu Meng, Mengzhou Xia, and Danqi Chen. 2024. SimPO: Simple Preference Optimization with a Reference-Free Reward. InNeurIPS, Vol. 37. 124198–124235
work page 2024
- [33]
-
[34]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schul- man, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F Christiano, Jan Leike, and Ryan Lowe. 2022. Training Lan- guage Models to Follow Instructions with Hum...
work page 2022
-
[35]
Yingtao Peng, Chen Gao, Yu Zhang, Tangpeng Dan, Xiaoyi Du, Hengliang Luo, Yong Li, and Xiaofeng Meng. 2025. Denoising alignment with large language model for recommendation.ACM Transactions on Information Systems (TOIS)43, 2 (2025), 1–35
work page 2025
-
[36]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand- hini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
-
[37]
Learning Transferable Visual Models From Natural Language Supervision. InICML. 8748–8763
-
[38]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct Preference Optimization: Your Language Model is Secretly a Reward Model. InNeurIPS, Vol. 36. 53728–53741
work page 2023
- [39]
-
[40]
Xubin Ren, Jiabin Tang, Dawei Yin, Nitesh Chawla, and Chao Huang. 2024. A Survey of Large Language Models for Graphs. InKDD. 6616–6626
work page 2024
-
[41]
Xubin Ren, Wei Wei, Lianghao Xia, Lixin Su, Suqi Cheng, Junfeng Wang, Dawei Yin, and Chao Huang. 2024. Representation Learning with Large Language Models for Recommendation. InWWW. 3464–3475
work page 2024
-
[42]
Francesco Ricci, Lior Rokach, and Bracha Shapira. 2010. Introduction to Rec- ommender Systems Handbook. InRecommender Systems Handbook. Springer, 1–35
work page 2010
-
[43]
Lei Sang, Yu Wang, Yi Zhang, Yiwen Zhang, and Xindong Wu. 2025. Intent- guided Heterogeneous Graph Contrastive Learning for Recommendation.IEEE Transactions on Knowledge and Data Engineering (TKDE)37, 4 (2025), 1915–1929
work page 2025
-
[44]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov
-
[45]
Proximal Policy Optimization Algorithms.arXiv preprint arXiv:1707.06347 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
Leheng Sheng, An Zhang, Yi Zhang, Yuxin Chen, Xiang Wang, and Tat-Seng Chua
-
[47]
Language Representations Can be What Recommenders Need: Findings and Potentials. InICLR
-
[48]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
-
[49]
BERT4Rec: Sequential Recommendation with Bidirectional Encoder Repre- sentations from Transformer. InCIKM. 1441–1450
-
[50]
Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liang-Yan Gui, Yu-Xiong Wang, Yiming Yang, et al. 2024. Aligning Large Multimodal Models with Factually Augmented RLHF. InACL
work page 2024
-
[51]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. InNeurIPS, Vol. 30
work page 2017
-
[52]
Fei Wang, Wenxuan Zhou, James Y Huang, Nan Xu, Sheng Zhang, Hoifung Poon, and Muhao Chen. 2024. mDPO: Conditional Preference Optimization for Multimodal Large Language Models. InEMNLP. 8078–8088
work page 2024
-
[53]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. 2024. Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution.arXiv preprint arXiv:2409.12191(2024). Conference acronym ’XX, June 03–05,2018, Woodstock, NY Yu Wang, Yonghui Yang, Le Wu, Yi Zhang, and Ri...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Shoujin Wang, Liang Hu, Yan Wang, Longbing Cao, Quan Z Sheng, and Mehmet Orgun. 2019. Sequential Recommender Systems: Challenges, Progress and Prospects. InIJCAI. 6332–6338
work page 2019
-
[55]
Yu Wang, Lei Sang, Yi Zhang, and Yiwen Zhang. 2025. Intent Representation Learning with Large Language Model for Recommendation. InSIGIR. 1870–1879
work page 2025
-
[56]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-Thought Prompting Elicits Rea- soning in Large Language Models. InNeurIPS, Vol. 35. 24824–24837
work page 2022
-
[57]
Wei Wei, Xubin Ren, Jiabin Tang, Qinyong Wang, Lixin Su, Suqi Cheng, Junfeng Wang, Dawei Yin, and Chao Huang. 2024. LLMRec: Large Language Models with Graph Augmentation for Recommendation. InWSDM. 806–815
work page 2024
-
[58]
Jiayang Wu, Wensheng Gan, Zefeng Chen, Shicheng Wan, and Philip S Yu. 2023. Multimodal Large Language Models: A Survey. InBigData. IEEE, 2247–2256
work page 2023
-
[59]
Xu Xie, Fei Sun, Zhaoyang Liu, Shiwen Wu, Jinyang Gao, Jiandong Zhang, Bolin Ding, and Bin Cui. 2022. Contrastive Learning for Sequential Recommendation. InICDE. 1259–1273
work page 2022
-
[60]
Zhihe Yang, Xufang Luo, Dongqi Han, Yunjian Xu, and Dongsheng Li. 2025. Mitigating Hallucinations in Large Vision-Language Models via DPO: On-Policy Data Hold the Key. InCVPR. 10610–10620
work page 2025
-
[61]
Yuyang Ye, Zhi Zheng, Yishan Shen, Tianshu Wang, Hengruo Zhang, Peijun Zhu, Runlong Yu, Kai Zhang, and Hui Xiong. 2025. Harnessing Multimodal Large Language Models for Multimodal Sequential Recommendation. InAAAI, Vol. 39. 13069–13077
work page 2025
-
[62]
Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, and Tat-Seng Chua. 2024. RLHF- V: Towards Trustworthy MLLMs via Behavior Alignment from Fine-grained Correctional Human Feedback. InCVPR. 13807–13816
work page 2024
-
[63]
Zheng Yuan, Fajie Yuan, Yu Song, Youhua Li, Junchen Fu, Fei Yang, Yunzhu Pan, and Yongxin Ni. 2023. Where to Go Next for Recommender Systems? ID-vs. Modality-based Recommender Models Revisited. InSIGIR. 2639–2649
work page 2023
-
[64]
Zhenrui Yue, Sara Rabhi, Gabriel de Souza Pereira Moreira, Dong Wang, and Even Oldridge. 2023. LlamaRec: Two-Stage Recommendation using Large Language Models for Ranking. InCIKM Workshop on Personalized Generative AI
work page 2023
-
[65]
Dan Zhang, Yangliao Geng, Wenwen Gong, Zhongang Qi, Zhiyu Chen, Xing Tang, Ying Shan, Yuxiao Dong, and Jie Tang. 2024. RecDCL: Dual Contrastive Learning for Recommendation. InWWW. 3655–3666
work page 2024
-
[66]
Jizhi Zhang, Keqin Bao, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He. 2023. Is ChatGPT Fair for Recommendation? Evaluating Fairness in Large Language Model Recommendation. InRecSys. 993–999
work page 2023
-
[67]
Jinghao Zhang, Yanqiao Zhu, Qiang Liu, Shu Wu, Shuhui Wang, and Liang Wang. 2021. Mining Latent Structures for Multimedia Recommendation. InMM. 3872–3880
work page 2021
-
[68]
Yang Zhang, Fuli Feng, Jizhi Zhang, Keqin Bao, Qifan Wang, and Xiangnan He
-
[69]
CoLLM: Integrating Collaborative Embeddings Into Large Language Models for Recommendation.IEEE Transactions on Knowledge and Data Engineering (TKDE)37, 5 (2025), 2329–2340
work page 2025
-
[70]
Yi Zhang, Yiwen Zhang, Yu Wang, Tong Chen, and Hongzhi Yin. 2025. To- wards Distribution Matching between Collaborative and Language Spaces for Generative Recommendation. InSIGIR. 2006–2016
work page 2025
-
[71]
Zizhuo Zhang and Bang Wang. 2023. Prompt Learning for News Recommendation. InSIGIR. 227–237
work page 2023
-
[72]
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. 2023. A Survey of Large Language Models.arXiv preprint arXiv:2303.18223(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[73]
Zhiyuan Zhao, Bin Wang, Linke Ouyang, Xiaoyi Dong, Jiaqi Wang, and Conghui He. 2023. Beyond Hallucinations: Enhancing LVLMs through Hallucination- Aware Direct Preference Optimization.arXiv preprint arXiv:2311.16839(2023)
work page internal anchor Pith review arXiv 2023
-
[74]
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, Ming Chen, and Ji-Rong Wen. 2024. Adapting Large Language Models by Integrating Collaborative Semantics for Recommendation. InICDE. 1435–1448
work page 2024
-
[75]
Peilin Zhou, Chao Liu, Jing Ren, Xinfeng Zhou, Yueqi Xie, Meng Cao, Zhongtao Rao, You-Liang Huang, Dading Chong, Junling Liu, Jae Boum Kim, Shoujin Wang, Raymond Chi-Wing Wong, and Sunghun Kim. 2025. When Large Vision Language Models Meet Multimodal Sequential Recommendation: An Empirical Study. InWWW. 275–292
work page 2025
-
[76]
Yiyang Zhou, Chenhang Cui, Rafael Rafailov, Chelsea Finn, and Huaxiu Yao. 2024. Aligning Modalities in Vision Large Language Models via Preference Fine-tuning. InICLR Workshop on Reliable and Responsible Foundation Models. Appendix In the Appendix, we first present the pseudo-code for the complete training of the proposed HaNoRec. Subsequently, we provide...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.