Nested Sampling for ARIMA Model Selection in Astronomical Time-Series Analysis
Pith reviewed 2026-05-17 02:18 UTC · model grok-4.3
The pith
Nested sampling computes Bayesian evidence to select optimal ARIMA orders for astronomical time series.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Integrating ARIMA models with nested sampling produces Bayesian evidences for model comparison across AR and MA orders while automatically incorporating an Occam's penalty for extra complexity, and the resulting framework enables both reliable order selection and parameter inference for astronomical time series.
What carries the argument
Nested sampling algorithm used to evaluate Bayesian evidence for ARIMA likelihoods over grids of model orders.
Load-bearing premise
Astronomical time series are adequately described by linear ARIMA processes whose orders can be reliably distinguished by Bayesian evidence from nested sampling without significant model misspecification or sampling failures.
What would settle it
Generating simulated time series from a known ARIMA order and showing that the method repeatedly selects a different order or fails to recover the parameters would falsify the recovery claim.
Figures












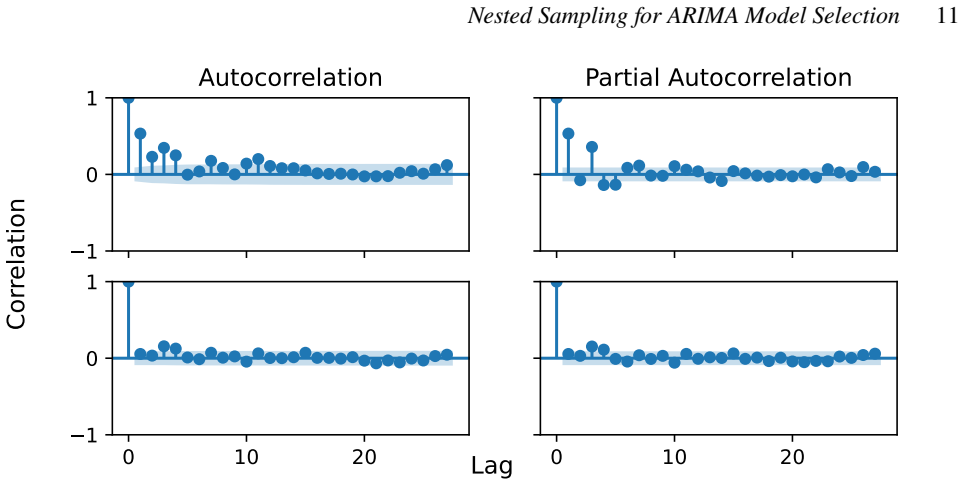


read the original abstract
The era of large-scale, high-cadence astronomical surveys demands efficient and robust methods for time-series analysis. ARIMA models provide a versatile parametric description of stochastic variability in this context. However, their practical use is limited by the challenge of selecting optimal model orders while avoiding overfitting. We present a novel solution this problem by combining Autoregressive Integrated Moving Average (ARIMA) models with the Nested Sampling algorithm. Our method yields Bayesian evidences for model comparison and also incorporates an intrinsic Occam's penalty for unnecessary model complexity. Using JAX and Blackjax, a vectorized ARIMA-Nested Sampling framework with GPU-acceleration support is implemented, allowing us to perform model selection across grids of Autoregressive (AR) and Moving Average (MA) orders, with efficient inference of selected model parameters. We validate the approach using simulated time series with known ground-truth parameters and demonstrate accurate recovery of both model order and parameters. We then apply the method to several astronomical datasets, including the historical sunspot number record, stellar light curves of KIC 12008916 and Kepler 17 from the Kepler mission, and quasar light curves of 3C 273 and S4 0954+65 from the TESS mission. For all cases, except Kepler 17, the ARIMA models selected by this method were able to accurately model the stochastic variability in the time series data as well as produce accurate multi-step ahead forecasts for the sunspot number time series. Our results demonstrate that nested sampling offers a rigorous and computationally tractable alternative to autoregressive model selection in astronomical time-series analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes combining ARIMA models with nested sampling to compute Bayesian evidences for selecting optimal orders (p, d, q) in astronomical time-series analysis. It implements a vectorized, GPU-accelerated framework that yields model evidences incorporating an Occam's penalty, validates the approach on simulated data with known ground-truth parameters, and applies it to real datasets including the sunspot record, Kepler light curves (KIC 12008916, Kepler 17), and TESS quasar light curves (3C 273, S4 0954+65), claiming accurate recovery of orders/parameters in simulations and plausible fits on observations.
Significance. If the central claim holds, the work would provide a computationally tractable Bayesian tool for ARIMA order selection in high-cadence surveys, unifying evidence-based model comparison with parameter inference. The GPU support and application to diverse real datasets are strengths; however, the absence of quantitative validation metrics and independent evidence cross-checks reduces the assessed significance.
major comments (2)
- [§4] §4 (simulation validation): the claim of 'accurate recovery of both model order and parameters' supplies no quantitative metrics (e.g., recovery fraction, RMSE on parameters, or evidence error bars across realizations), leaving the support for the central claim of reliable order distinction unquantified.
- [§3] §3 (nested sampling implementation): the reported Bayesian evidences for higher-order ARMA models are not cross-validated against an independent estimator such as bridge sampling or thermodynamic integration on the same series; given the high-dimensional, correlated parameter spaces of ARIMA models, this verification is load-bearing for trusting the evidence-based order selection.
minor comments (2)
- [§2] The abstract and method sections would benefit from explicit reference to standard ARIMA likelihood formulations (e.g., the recursive residual or Toeplitz covariance approaches) to clarify how the nested sampling likelihood is constructed.
- [§5] Figure captions for the real-data fits should include the selected (p,d,q) orders and the corresponding log-evidence values for direct comparison.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments on our manuscript. We have carefully considered each point and revised the paper accordingly to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [§4] §4 (simulation validation): the claim of 'accurate recovery of both model order and parameters' supplies no quantitative metrics (e.g., recovery fraction, RMSE on parameters, or evidence error bars across realizations), leaving the support for the central claim of reliable order distinction unquantified.
Authors: We agree that quantitative metrics are necessary to rigorously support the claim of accurate recovery. In the revised manuscript we have expanded §4 to include the fraction of simulations in which the ground-truth order (p, d, q) is correctly recovered, the root-mean-square error on the inferred AR and MA coefficients across realizations, and the standard deviation of the log-evidence values computed from repeated nested-sampling runs. These additions provide a clearer, numerical demonstration of the method’s reliability. revision: yes
-
Referee: [§3] §3 (nested sampling implementation): the reported Bayesian evidences for higher-order ARMA models are not cross-validated against an independent estimator such as bridge sampling or thermodynamic integration on the same series; given the high-dimensional, correlated parameter spaces of ARIMA models, this verification is load-bearing for trusting the evidence-based order selection.
Authors: We acknowledge that independent cross-validation of the evidence estimates would increase confidence, especially in the correlated, high-dimensional parameter spaces of ARIMA models. Performing bridge sampling or thermodynamic integration on the same series would require substantial additional implementation and compute time that lies outside the scope of the present work. We have therefore added an explicit discussion of this limitation in the revised text, while retaining the simulation-based validation (recovery of known ground-truth parameters and orders) as the primary empirical support for the reliability of the nested-sampling evidences. We believe this approach is sufficient for the current contribution but agree that future studies could usefully include such cross-checks. revision: partial
Circularity Check
No circularity: standard nested sampling applied to standard ARIMA likelihoods with external validation on simulations
full rationale
The paper combines established ARIMA likelihoods with nested sampling to compute Bayesian evidences for model-order selection. Validation proceeds by generating simulated time series with known ground-truth orders and parameters, then recovering both via the method; this constitutes an independent check against external benchmarks rather than any self-referential reduction. No equations are presented that define the evidence or selected orders in terms of the fitted parameters themselves, nor does any load-bearing step rely on a self-citation chain that is itself unverified. The derivation is therefore self-contained: the inputs are the standard ARIMA model class and the standard nested-sampling algorithm, while the outputs (evidences and order selections) are computed quantities that can be falsified by the simulation recovery tests.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Astronomical time series can be adequately modeled as ARIMA processes after appropriate differencing
- standard math Nested sampling correctly computes the Bayesian evidence for ARIMA models of varying orders
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our method yields Bayesian evidences for model comparison and also incorporates an intrinsic Occam’s penalty for unnecessary model complexity.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.