Same Content, Different Answers: Cross-Modal Inconsistency in MLLMs
Pith reviewed 2026-05-16 23:49 UTC · model grok-4.3
The pith
Multimodal LLMs produce different answers for the same content presented as text or as an image.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
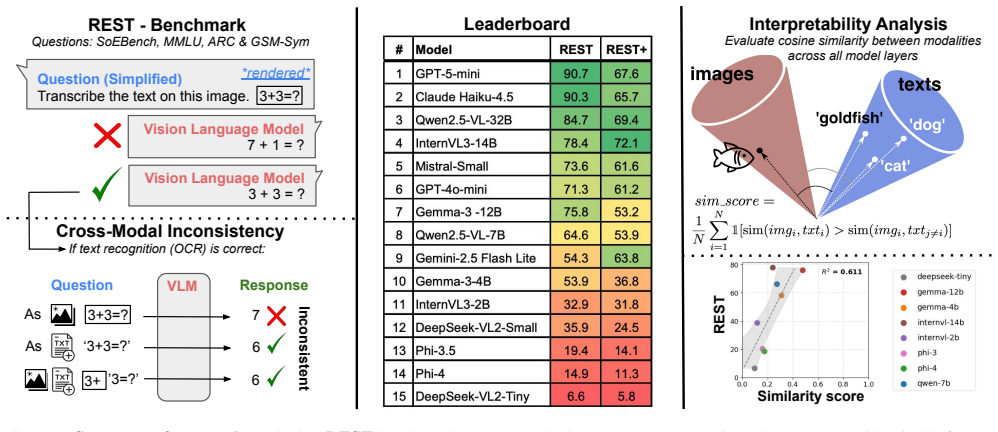
MLLMs are trained to represent vision and language in the same embedding space, yet they cannot perform the same tasks in both modalities. The benchmarks contain samples with the same semantic information in three modalities, and evaluations of 15 MLLMs reveal substantial variation in inconsistency. Even with correct OCR, visual characteristics and vision token count affect results, and consistency correlates with the modality gap.
What carries the argument
REST and REST+ benchmarks that render equivalent semantic content in image, text, and mixed modalities to stress-test cross-modal reasoning consistency.
Load-bearing premise
The constructed samples truly contain identical semantic information across modalities without introducing differences in complexity or presentation.
What would settle it
A model that produces identical correct answers for every REST sample across all three modalities would demonstrate that the inconsistency is not inherent to current MLLMs.
Figures













read the original abstract
We introduce two new benchmarks REST and REST+ (Render-Equivalence Stress Tests) to enable systematic evaluation of cross-modal inconsistency in multimodal large language models (MLLMs). MLLMs are trained to represent vision and language in the same embedding space, yet they cannot perform the same tasks in both modalities. Our benchmarks contain samples with the same semantic information in three modalities (image, text, mixed) and we show that state-of-the-art MLLMs cannot consistently reason over these different modalities. We evaluate 15 MLLMs and find that the degree of modality inconsistency varies substantially, even when accounting for problems with text recognition (OCR). Neither rendering text as image nor rendering an image as text solves the inconsistency. Even if OCR is correct, we find that visual characteristics (text colour and resolution, but not font) and the number of vision tokens have an impact on model performance. Finally, we find that our consistency score correlates with the modality gap between text and images, highlighting a mechanistic interpretation of cross-modal inconsistent MLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces REST and REST+ (Render-Equivalence Stress Tests) benchmarks containing identical semantic content presented in image, text, and mixed modalities. It evaluates 15 MLLMs and reports substantial cross-modal inconsistency in reasoning performance, even after controlling for OCR accuracy. The study finds that visual factors (color, resolution, vision token count) influence results, that neither text-to-image nor image-to-text conversion resolves the gaps, and that a proposed consistency score correlates with the text-image modality gap.
Significance. If the sample equivalence holds, the work is significant for highlighting a practical limitation in state-of-the-art MLLMs' ability to maintain consistent reasoning across equivalent inputs in different modalities. The benchmarks provide a concrete evaluation framework that could inform training objectives and architectural choices aimed at closing modality gaps. The correlation between consistency and modality gap offers a potential mechanistic lens, though the empirical nature of the study means impact depends on the robustness of the controls.
major comments (2)
- [Benchmark construction] Benchmark construction section: the central claim that REST/REST+ instances encode precisely the same semantic content and reasoning demands across modalities is load-bearing but insufficiently validated. The abstract itself states that visual characteristics (color, resolution) and vision token count affect performance even when OCR is correct, which directly suggests rendering-induced non-semantic differences that could explain observed gaps rather than a pure cross-modal reasoning failure.
- [Evaluation and results] Evaluation and results sections: details on sample construction (how semantic equivalence was ensured and verified), statistical significance of performance differences, and explicit ablations isolating visual factors from modality are missing. Without these, the claim that inconsistency is inherent to MLLMs rather than an artifact of the rendering pipeline cannot be fully assessed.
minor comments (3)
- [Methods] Provide the exact formula and computation procedure for the consistency score, including how it is aggregated across samples and modalities.
- [Experiments] Clarify the selection criteria and size of the 15 evaluated models, and report per-model breakdowns rather than aggregate trends only.
- [Results] Add error bars or confidence intervals to performance tables and figures to support claims of substantial variation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that additional validation and methodological details will strengthen the paper and will incorporate revisions to address the concerns. We respond to each major comment below.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction section: the central claim that REST/REST+ instances encode precisely the same semantic content and reasoning demands across modalities is load-bearing but insufficiently validated. The abstract itself states that visual characteristics (color, resolution) and vision token count affect performance even when OCR is correct, which directly suggests rendering-induced non-semantic differences that could explain observed gaps rather than a pure cross-modal reasoning failure.
Authors: We agree that the semantic equivalence claim requires stronger validation. REST and REST+ are constructed by starting with text-based reasoning problems and rendering the identical text content into images under controlled conditions, so that the semantic information and required reasoning steps are identical by design. We will revise the benchmark construction section to add: (1) a step-by-step description of the generation pipeline, (2) concrete examples of matched image-text pairs, and (3) results from a human verification study on a random subset of 100 samples confirming that annotators judge the semantic content and reasoning demands to be equivalent. On the visual factors point, the manuscript already reports that inconsistencies persist even when OCR is perfect; we will add explicit discussion clarifying that while rendering parameters influence absolute performance, the cross-modal gaps remain after these controls, supporting a modality-gap interpretation beyond pure rendering artifacts. revision: yes
-
Referee: [Evaluation and results] Evaluation and results sections: details on sample construction (how semantic equivalence was ensured and verified), statistical significance of performance differences, and explicit ablations isolating visual factors from modality are missing. Without these, the claim that inconsistency is inherent to MLLMs rather than an artifact of the rendering pipeline cannot be fully assessed.
Authors: We accept that these details are currently insufficient and will expand the evaluation and results sections. Revisions will include: (1) expanded description of how semantic equivalence is ensured and verified (cross-referencing the new benchmark construction details), (2) statistical significance testing (e.g., McNemar’s test for paired modality comparisons) on the reported performance differences, and (3) new ablations that hold modality fixed while systematically varying visual factors such as resolution and color to isolate their contribution from cross-modal effects. These changes will allow readers to better assess whether the inconsistencies are inherent to MLLM modality handling rather than rendering artifacts. revision: yes
Circularity Check
No circularity: purely empirical benchmark evaluation
full rationale
The paper introduces REST and REST+ benchmarks and reports empirical performance gaps across modalities in 15 MLLMs. No derivations, equations, fitted parameters presented as predictions, or self-citation chains appear in the abstract or described content. The consistency score is computed directly from observed accuracy differences, and claims about modality inconsistency rest on experimental results rather than reducing to inputs by construction. The noted concern about rendering artifacts affects benchmark validity but does not constitute circularity in any derivation step.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MLLMs are trained to represent vision and language in the same embedding space, yet they cannot perform the same tasks in both modalities
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce REST and REST+ ... measure whether models produce consistent outputs regardless of modality ... consistency score correlates with the modality gap between text and images
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the cross-modal cosine similarity in embedding space
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadal- lah, Ammar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jianmin Bao, Harkirat Behl, et al. Phi-3 technical report: A highly capable language model locally on your phone, 2024.URL https://arxiv. org/abs/2404.14219, 2: 6, 2024. 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Marah Abdin, Jyoti Aneja, Harkirat Behl, S ´ebastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J Hewett, Mojan Javaheripi, Piero Kauffmann, et al. Phi-4 technical report.arXiv preprint arXiv:2412.08905, 2024. 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Men- sch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736,
-
[5]
I ˜nigo Alonso, Gorka Azkune, Ander Salaberria, Jeremy Barnes, and Oier Lopez de Lacalle. Vision-language models struggle to align entities across modalities.arXiv preprint arXiv:2503.03854, 2025. 1, 8
-
[6]
Claude haiku 4.5.https : / / www
Anthropic. Claude haiku 4.5.https : / / www . anthropic.com, 2025. Large language model by An- thropic. 3, 4, 8
work page 2025
-
[7]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Lichang Chen, Hexiang Hu, Mingda Zhang, Yiwen Chen, Zifeng Wang, Yandong Li, Pranav Shyam, Tianyi Zhou, Heng Huang, Ming-Hsuan Yang, et al. Omnixr: Evaluating omni-modality language models on reasoning across modal- ities.arXiv preprint arXiv:2410.12219, 2024. 1, 4, 8
-
[10]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Instructblip: Towards general- purpose vision-language models with instruction tuning
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. Instructblip: Towards general- purpose vision-language models with instruction tuning. In Advances in Neural Information Processing Systems, 2023. 1
work page 2023
-
[12]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. IEEE, 2009. 7
work page 2009
-
[13]
Mitigate the gap: In- vestigating approaches for improving cross-modal alignment in clip, 2024
Sedigheh Eslami and Gerard de Melo. Mitigate the gap: In- vestigating approaches for improving cross-modal alignment in clip, 2024. 1, 8
work page 2024
-
[14]
Making the v in vqa matter: Elevating the role of image understanding in visual question answer- ing
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Ba- tra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answer- ing. InCVPR, 2017. 8
work page 2017
-
[16]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Mea- suring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020. 1, 4, 7
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[17]
Gqa: A new dataset for real-world visual reasoning and compositional question answering
Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. InCVPR, 2019. 8
work page 2019
-
[18]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InPro- ceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023. 2
work page 2023
-
[20]
Victor Weixin Liang, Yuhui Zhang, Yongchan Kwon, Ser- ena Yeung, and James Y Zou. Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning.Advances in Neural Information Processing Sys- tems, 35:17612–17625, 2022. 1, 8
work page 2022
-
[21]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 1
work page 2023
-
[22]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024. 1
work page 2024
-
[23]
MMBench: Is Your Multi-modal Model an All-around Player?
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player?arXiv preprint arXiv:2307.06281, 2023. 1, 8
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathemat- ical reasoning of foundation models in visual contexts.ICLR, 2024.https://arxiv.org/abs/2310.02255. 8
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Chartqa: A benchmark for question an- swering about charts with visual and logical reasoning
Ahmed Masry, Do Xuan Long, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question an- swering about charts with visual and logical reasoning. In Findings of the Association for Computational Linguistics: ACL 2022, pages 2263–2279, 2022. 1
work page 2022
-
[26]
Docvqa: A dataset for vqa on document images
Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. Docvqa: A dataset for vqa on document images. InProceed- ings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2200–2209, 2021. 1
work page 2021
-
[27]
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models
Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, On- cel Tuzel, Samy Bengio, and Mehrdad Farajtabar. Gsm- symbolic: Understanding the limitations of mathemati- cal reasoning in large language models.arXiv preprint arXiv:2410.05229, 2024. 1, 2, 4, 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Mistral AI. Mistral-small-3.1-24b-instruct.https:// huggingface.co/mistralai/Mistral- Small- 3.1-24B-Instruct-2503, 2025. Version 2503. 4
work page 2025
-
[29]
Gpt-5 mini.https://openai.com, 2025
OpenAI. Gpt-5 mini.https://openai.com, 2025. Compact large language model by OpenAI. 3, 4, 8
work page 2025
-
[30]
Isabel Papadimitriou, Huangyuan Su, Thomas Fel, Sham M. Kakade, and Stephanie Gil. Interpreting the linear structure of vision-language model embedding spaces. InSecond Con- ference on Language Modeling, 2025. 1, 8
work page 2025
-
[31]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 1
work page 2021
-
[32]
Privacy-aware visual language models.arXiv e-prints, pages arXiv–2405, 2024
Laurens Samson, Nimrod Barazani, Sennay Ghebreab, and Yuki M Asano. Privacy-aware visual language models.arXiv e-prints, pages arXiv–2405, 2024. 1, 8
work page 2024
-
[33]
Large vision-language model alignment and misalignment: A survey through the lens of explainability,
Dong Shu, Haiyan Zhao, Jingyu Hu, Weiru Liu, Ali Payani, Lu Cheng, and Mengnan Du. Large vision-language model alignment and misalignment: A survey through the lens of explainability.arXiv preprint arXiv:2501.01346, 2025. 1, 8
-
[34]
Mustafa Shukor and Matthieu Cord. Implicit multimodal alignment: On the generalization of frozen llms to multi- modal inputs.Advances in Neural Information Processing Systems, 37:130848–130886, 2024. 1, 7, 8
work page 2024
-
[35]
Can vlms actually see and read? a survey on modality collapse in vision-language models
Mong Yuan Sim, Wei Emma Zhang, Xiang Dai, and Biaoyan Fang. Can vlms actually see and read? a survey on modality collapse in vision-language models. InFindings of the As- sociation for Computational Linguistics: ACL 2025, pages 24452–24470, 2025. 1, 8
work page 2025
-
[36]
Towards vqa models that can read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. InCVPR,
-
[37]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Ta- tiana Matejovicova, Alexandre Ram ´e, Morgane Rivi `ere, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025. 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.Advances in Neural Information Processing Sys- tems, 37:95266–95290, 2024. 8
work page 2024
-
[40]
DeepSeek-OCR: Contexts Optical Compression
Haoran Wei, Yaofeng Sun, and Yukun Li. Deepseek- ocr: Contexts optical compression.arXiv preprint arXiv:2510.18234, 2025. 1, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bingxuan Wang, et al. Deepseek-vl2: Mixture-of- experts vision-language models for advanced multimodal understanding.arXiv preprint arXiv:2412.10302, 2024. 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Qianqi Yan, Yue Fan, Hongquan Li, Shan Jiang, Yang Zhao, Xinze Guan, Ching-Chen Kuo, and Xin Eric Wang. Multi- modal inconsistency reasoning (mmir): A new benchmark for multimodal reasoning models.ACL, 2025.https: //arxiv.org/abs/2502.16033. 8
-
[43]
A survey on multimodal large language models.National Science Review, 11(12): nwae403, 2024
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models.National Science Review, 11(12): nwae403, 2024. 1
work page 2024
-
[44]
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for ex- pert agi.CVPR, 2024. 1, 8, 13
work page 2024
-
[45]
Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark
Xiang Yue, Tianyu Zheng, Yuansheng Ni, Yubo Wang, Kai Zhang, Shengbang Tong, Yuxuan Sun, Botao Yu, Ge Zhang, Huan Sun, Yu Su, Wenhu Chen, and Graham Neu- big. Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark. InProceedings of the 63rd An- nual Meeting of the Association for Computational Linguis- tics, pages 15134–15186, 2025. 1, 8
work page 2025
-
[46]
Xiang Zhang, Senyu Li, Ning Shi, Bradley Hauer, Zijun Wu, Grzegorz Kondrak, Muhammad Abdul-Mageed, and Laks V . S. Lakshmanan. Cross-modal consistency in multimodal large language models, 2024. 1, 3, 8
work page 2024
-
[47]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shen- glong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 4 Same Content, Different Answers: Cross-Modal Inconsistency in MLLMs Supplementary Material
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Benchmark Implementation Details We provide complete specifications for reproducing the RESTbenchmark experiments, including prompt templates and dataset examples. All code, data, and model outputs will be released publicly upon acceptance to facilitate fu- ture research on cross-modal consistency. 9.1. REST ImagesIn Figure 7, we show examples of both mix...
-
[49]
Open-source models follow vLLM’s recommended con- figurations for optimal performance
Despite these computational optimisations, all models receive identical Chain-of-Thought prompting instructions to ensure fair comparison. Open-source models follow vLLM’s recommended con- figurations for optimal performance. Experiments run on single-GPU systems: NVIDIA RTX 6000 Ada (48GB VRAM) for most models, and NVIDIA H100 (80GB VRAM) for larger mode...
-
[50]
Do not solve the question; just transcribe the text exactly as it appears
-
[51]
Do not add extra commentary, only transcribe. Please transcribe now. (c) OCR verification Figure 8. Prompt templates used in theRESTbenchmark for evaluating cross-modal consistency across MMLU, ARC, GSM-Symbolic. Each modality (text, image, mixed) receives task-specific instructions while maintaining consistent Chain-of-Thought reasoning require- ments an...
-
[52]
Do not solve or simplify these equations; just transcribe them exactly as they appear
-
[53]
Retain the same order and use the following numbering, (1), (2), (3) per equation
-
[54]
List 1 equation per item, for example (1) 3a + 2b + c = 11
-
[55]
Put each equation on its own line
-
[56]
Use plain text as output, the operations that you can use are ’*’, ’+’, ’-’ and ’=’
-
[57]
Format your output like so: (1) 2a + 3b = 10 (2) a + 3c = 30 (3) 2b + 5c = ? Please transcribe now
Do not add extra commentary-only transcribe equations. Format your output like so: (1) 2a + 3b = 10 (2) a + 3c = 30 (3) 2b + 5c = ? Please transcribe now. (d) OCR verification Figure 11. Prompt templates used for SOEBENCHevaluation. Each modality receives specific instructions for solving systems of equations with letter variables. For the mixed modality,...
-
[58]
Extended Results This section presents comprehensive results for theREST benchmarks, including performance metrics across all eval- uation conditions and detailed breakdowns by modality. 10.1. REST Cross-Modal Consistency AnalysisTables 7 and 8 present RER and CFR scores for the OCR-correct sub- set and the complete set, respectively. Results are given pe...
-
[59]
As mentioned in the paper, we see that fewer text tokens are needed to achieve the same level of accuracy, or more Table 14.Image performance on REST+ for different DPI lev- els(complete set of questions). Image accuracy, RER consistency and OCR correct scores stratified by resolution (50, 100, 200 DPI) for all questions. Model Img Acc. RER OCR DPI 50 100...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.