Remember Me, Refine Me: A Dynamic Procedural Memory Framework for Experience-Driven Agent Evolution
Pith reviewed 2026-05-16 23:16 UTC · model grok-4.3
The pith
ReMe lets smaller LLM agents outperform larger ones by dynamically distilling, reusing, and refining procedural experiences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
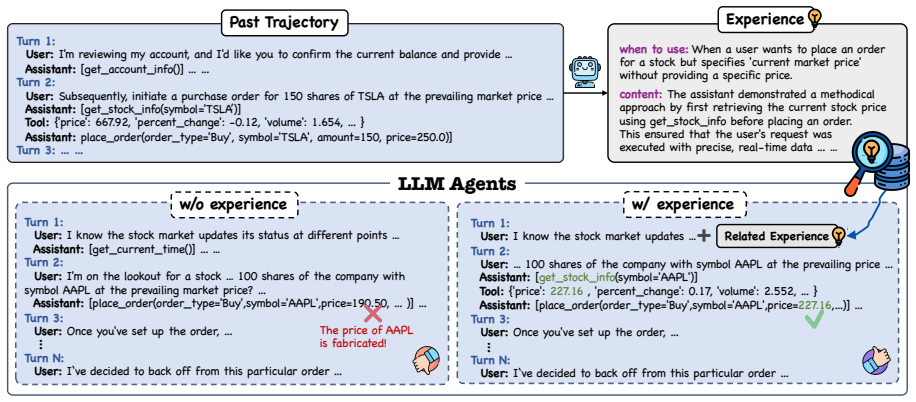
ReMe implements procedural memory through three linked processes: multi-faceted distillation that pulls out success patterns, failure triggers, and comparative insights; context-adaptive reuse that indexes memories for new scenarios; and utility-based refinement that adds helpful memories while pruning outdated ones to keep the pool compact. On BFCL-V3 and AppWorld, the full system sets a new state-of-the-art, and the memory-scaling result shows Qwen3-8B with ReMe surpassing a memoryless Qwen3-14B.
What carries the argument
The ReMe framework's three mechanisms—multi-faceted distillation, context-adaptive reuse, and utility-based refinement—that together turn raw interaction history into an evolving, high-quality experience pool.
If this is right
- Agents reduce redundant trial-and-error by internalizing reliable how-to knowledge.
- Smaller models with ReMe can surpass larger memoryless models on agent benchmarks.
- Autonomous addition and pruning keeps the experience pool compact and high-quality.
- Self-evolving memory supplies a computation-efficient route to lifelong agent learning.
- The same mechanisms deliver state-of-the-art results on BFCL-V3 and AppWorld.
Where Pith is reading between the lines
- Memory scaling could become a cheaper alternative to model scaling for improving agent reliability over long horizons.
- The distillation and refinement loop might transfer to domains outside the two tested benchmarks without major redesign.
- Combining ReMe-style memory with other agent training signals could produce even stronger compounding gains.
- In extended deployments the compact memory pool would lower token costs and latency compared with growing static archives.
Load-bearing premise
The utility-based refinement step can correctly judge which memories remain valid and which have become outdated without task-specific tuning or systematic mistakes.
What would settle it
A controlled run on BFCL-V3 where the refinement step is disabled or replaced with random pruning, showing whether performance falls below the reported ReMe baseline or memory quality degrades over repeated tasks.
Figures






read the original abstract
Procedural memory enables large language model (LLM) agents to internalize "how-to" knowledge, theoretically reducing redundant trial-and-error. However, existing frameworks predominantly suffer from a "passive accumulation" paradigm, treating memory as a static append-only archive. To bridge the gap between static storage and dynamic reasoning, we propose $\textbf{ReMe}$ ($\textit{Remember Me, Refine Me}$), a comprehensive framework for experience-driven agent evolution. ReMe innovates across the memory lifecycle via three mechanisms: 1) $\textit{multi-faceted distillation}$, which extracts fine-grained experiences by recognizing success patterns, analyzing failure triggers and generating comparative insights; 2) $\textit{context-adaptive reuse}$, which tailors historical insights to new contexts via scenario-aware indexing; and 3) $\textit{utility-based refinement}$, which autonomously adds valid memories and prunes outdated ones to maintain a compact, high-quality experience pool. Extensive experiments on BFCL-V3 and AppWorld demonstrate that ReMe establishes a new state-of-the-art in agent memory system. Crucially, we observe a significant memory-scaling effect: Qwen3-8B equipped with ReMe outperforms larger, memoryless Qwen3-14B, suggesting that self-evolving memory provides a computation-efficient pathway for lifelong learning. We release our code and the $\texttt{reme.library}$ dataset to facilitate further research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ReMe, a dynamic procedural memory framework for LLM agents with three mechanisms: multi-faceted distillation (extracting success/failure patterns and comparative insights), context-adaptive reuse (scenario-aware indexing), and utility-based refinement (autonomous addition/pruning of memories). It claims new state-of-the-art results on BFCL-V3 and AppWorld benchmarks, plus a memory-scaling effect in which Qwen3-8B equipped with ReMe outperforms the larger memoryless Qwen3-14B model.
Significance. If the results hold under scrutiny, ReMe would demonstrate that dynamic, self-refining procedural memory can enable smaller models to surpass larger memoryless ones, offering a compute-efficient route to agent evolution and lifelong learning. The public release of code and the reme.library dataset is a clear strength that supports reproducibility and follow-on work.
major comments (2)
- [Methods (utility-based refinement)] The utility-based refinement mechanism (described in the methods section) is presented only at a high level as 'autonomously adds valid memories and prunes outdated ones' with no explicit utility scoring function, equation, pseudocode, LLM-as-judge prompt, or reported metric (e.g., success-rate delta or recency-weighted score). This is load-bearing for the headline scaling claim, as the 8B+ReMe > 14B result depends on the refinement step reliably improving memory quality without systematic bias or hidden task-specific tuning.
- [Experiments and Results] The experiments section reports SOTA performance and a 'significant memory-scaling effect' but provides no error bars, standard deviations across runs, number of trials, statistical significance tests, or detailed ablations that isolate the contribution of each of the three mechanisms. Without these, it is impossible to determine whether the observed gains are robust or sensitive to post-hoc choices in memory extraction and refinement.
minor comments (1)
- [Abstract and Introduction] The abstract and introduction would benefit from a concise table or diagram summarizing the three mechanisms and their inputs/outputs to improve readability before the detailed methods.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that additional technical detail and statistical rigor are needed to support the core claims. We outline our planned revisions below.
read point-by-point responses
-
Referee: [Methods (utility-based refinement)] The utility-based refinement mechanism (described in the methods section) is presented only at a high level as 'autonomously adds valid memories and prunes outdated ones' with no explicit utility scoring function, equation, pseudocode, LLM-as-judge prompt, or reported metric (e.g., success-rate delta or recency-weighted score). This is load-bearing for the headline scaling claim, as the 8B+ReMe > 14B result depends on the refinement step reliably improving memory quality without systematic bias or hidden task-specific tuning.
Authors: We agree the current description is high-level and insufficient to substantiate the scaling result. In the revision we will add the explicit utility scoring function (including its equation), the full pseudocode for the add/prune procedure, the complete LLM-as-judge prompt, and quantitative metrics (pre-/post-refinement success-rate deltas and any bias diagnostics). We will also state explicitly that no task-specific tuning beyond the published mechanisms was used. revision: yes
-
Referee: [Experiments and Results] The experiments section reports SOTA performance and a 'significant memory-scaling effect' but provides no error bars, standard deviations across runs, number of trials, statistical significance tests, or detailed ablations that isolate the contribution of each of the three mechanisms. Without these, it is impossible to determine whether the observed gains are robust or sensitive to post-hoc choices in memory extraction and refinement.
Authors: We acknowledge the absence of these statistical elements. We will rerun all main experiments with a fixed number of independent trials (reporting the exact count and seeds), add error bars and standard deviations, and include statistical significance tests for the key comparisons. We will also insert comprehensive ablation tables that isolate each of the three mechanisms (multi-faceted distillation, context-adaptive reuse, utility-based refinement) and quantify their individual contributions to both absolute performance and the memory-scaling effect. revision: yes
Circularity Check
No circularity: empirical framework with independent benchmark validation
full rationale
The paper describes ReMe as a procedural memory framework with three qualitative mechanisms (multi-faceted distillation, context-adaptive reuse, utility-based refinement) and supports its claims exclusively through experimental results on BFCL-V3 and AppWorld benchmarks. No equations, fitted parameters, or derivations are presented that could reduce outputs to inputs by construction. The reported memory-scaling effect (Qwen3-8B+ReMe outperforming Qwen3-14B) is an observed empirical outcome, not a self-referential prediction. Self-citations, if present, are not load-bearing for any central claim, and the framework remains self-contained against external benchmarks without renaming known results or smuggling ansatzes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents can extract fine-grained success patterns, failure triggers, and comparative insights from interaction traces
Forward citations
Cited by 14 Pith papers
-
MedMemoryBench: Benchmarking Agent Memory in Personalized Healthcare
MedMemoryBench supplies a 2,000-session synthetic medical trajectory dataset and an evaluate-while-constructing streaming protocol to expose memory saturation and reasoning failures in current agent architectures for ...
-
EXG: Self-Evolving Agents with Experience Graphs
EXG is an experience graph framework for self-evolving LLM agents that supports online real-time growth and offline reuse to enhance solution quality and efficiency on code generation and reasoning benchmarks.
-
Evolving-RL: End-to-End Optimization of Experience-Driven Self-Evolving Capability within Agents
Evolving-RL jointly optimizes experience extraction and utilization in LLM agents via RL with separate evaluation signals, delivering up to 98.7% relative gains on out-of-distribution tasks in ALFWorld and Mind2Web.
-
MemCompiler: Compile, Don't Inject -- State-Conditioned Memory for Embodied Agents
MemCompiler reframes memory use as state-conditioned compilation, delivering relevant guidance via text and latent channels to improve embodied agent performance up to 129% and cut latency 60% versus static injection.
-
MemCompiler: Compile, Don't Inject -- State-Conditioned Memory for Embodied Agents
MemCompiler introduces state-conditioned memory compilation that dynamically selects and compiles relevant memory into text and latent guidance, yielding up to 129% gains over no-memory baselines and 60% lower latency...
-
LMEB: Long-horizon Memory Embedding Benchmark
LMEB benchmark shows that embedding models' performance on traditional retrieval does not transfer to long-horizon memory tasks, larger models do not always perform better, and LMEB measures capabilities orthogonal to MTEB.
-
EvoIR-Agent: Self-Evolving Image Restoration Agentic System via Experience-Driven Learning
EvoIR-Agent formulates experience components into a hierarchical pool with a self-evolving update mechanism to improve performance and efficiency of training-free MLLM image restoration agents over prior paradigms.
-
MAP: A Map-then-Act Paradigm for Long-Horizon Interactive Agent Reasoning
MAP improves LLM agent reasoning by constructing a structured cognitive map of the environment before task execution, yielding performance gains on benchmarks like ARC-AGI-3 and superior training data via the new MAP-...
-
EmbodiSkill: Skill-Aware Reflection for Self-Evolving Embodied Agents
EmbodiSkill uses skill-aware reflection on execution trajectories to update skills in embodied agents, achieving 93.28% success on ALFWorld with a frozen Qwen3.5-27B model, outperforming direct GPT-5.2 use by 31.58%.
-
When Continual Learning Moves to Memory: A Study of Experience Reuse in LLM Agents
External memory does not eliminate continual learning challenges in LLM agents but reshapes them into issues of memory representation and retrieval design, with abstract memories aiding transfer while organization cho...
-
WorkflowGen:an adaptive workflow generation mechanism driven by trajectory experience
WorkflowGen reuses trajectory experiences via node-level and workflow-level extraction plus three-tier semantic routing to cut token use over 40% and raise success 20% on medium-similarity queries versus real-time pla...
-
SkillsVote: Lifecycle Governance of Agent Skills from Collection, Recommendation to Evolution
SkillsVote is a governance system for agent skills that profiles corpora, recommends via search, and gates updates on successful reusable outcomes, yielding benchmark gains without model changes.
-
Evo-MedAgent: Beyond One-Shot Diagnosis with Agents That Remember, Reflect, and Improve
Evo-MedAgent adds three evolving memory stores to LLM agents for chest X-ray diagnosis, raising MCQ accuracy from 0.68 to 0.79 on GPT-5-mini and 0.76 to 0.87 on Gemini-3 Flash without any training.
-
ActionNex: A Virtual Outage Manager for Cloud Computing
ActionNex is an agentic system for cloud outage management that compresses multimodal signals into critical events, uses hierarchical memory for reasoning, and recommends actions with 71.4% precision on real Azure outages.
Reference graph
Works this paper leans on
-
[1]
Exploring large language model based intelligent agents: Definitions, methods, and prospects
Exploring large language model based intel- ligent agents: Definitions, methods, and prospects. arXiv preprint arXiv:2401.03428. Han Ding, Yinheng Li, Junhao Wang, and Hang Chen
-
[2]
Large language model agent in financial trading: A survey,
Large language model agent in financial trad- ing: A survey.arXiv preprint arXiv:2408.06361. Jinyuan Fang, Yanwen Peng, Xi Zhang, Yingxu Wang, Xinhao Yi, Guibin Zhang, Yi Xu, Bin Wu, Siwei Liu, Zihao Li, and 1 others. 2025. A comprehensive survey of self-evolving ai agents: A new paradigm bridging foundation models and lifelong agentic sys- tems.arXiv pre...
-
[3]
Mark: Memory augmented refinement of knowledge.arXiv preprint arXiv:2505.05177. Huan-ang Gao, Jiayi Geng, Wenyue Hua, Mengkang Hu, Xinzhe Juan, Hongzhang Liu, Shilong Liu, Jiahao Qiu, Xuan Qi, Yiran Wu, and 1 others. 2025. A survey of self-evolving agents: On path to artificial super intelligence.arXiv preprint arXiv:2507.21046. Mengkang Hu, Tianxing Chen...
-
[4]
Agent kb: Leveraging cross-domain experience for agentic problem solving
In prospect and retrospect: Reflective mem- ory management for long-term personalized dialogue agents. InProceedings of the 63rd Annual Meet- ing of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8416–8439. Xiangru Tang, Tianrui Qin, Tianhao Peng, Ziyang Zhou, Daniel Shao, Tingting Du, Xinming Wei, Peng Xia, Fang Wu, He Zhu, ...
-
[5]
Large language models for education: A survey and outlook
Appworld: A controllable world of apps and people for benchmarking interactive coding agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16022–16076. Shen Wang, Tianlong Xu, Hang Li, Chaoli Zhang, Joleen Liang, Jiliang Tang, Philip S Yu, and Qing- song Wen. 2024. Large language ...
-
[6]
How memory management impacts llm agents: An empirical study of experience-following behavior. arXiv preprint arXiv:2505.16067. Wujiang Xu, Kai Mei, Hang Gao, Juntao Tan, Zu- jie Liang, and Yongfeng Zhang. 2025. A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110. Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang,...
-
[7]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems, 36:46595–46623. Longtao Zheng, Rundong Wang, Xinrun Wang, and Bo An. 2024. Synapse: Trajectory-as-exemplar prompting with memory for computer control. In The Twelfth International Conference on Learning Representations. A Dataset Details BFCL-V3Berk...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.