Asynchronous Reasoning: Training-Free Interactive Thinking LLMs
Pith reviewed 2026-05-16 22:52 UTC · model grok-4.3
The pith
Modifying positional embeddings lets existing LLMs reason asynchronously while generating responses without any retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By leveraging properties of positional embeddings, LLMs built for sequential generation can be made to perform asynchronous reasoning: they simultaneously maintain internal thinking tokens, listen to additional inputs, and write output tokens, all without additional training, while still producing accurate reasoning-augmented answers on math, commonsense, and safety benchmarks.
What carries the argument
Positional embedding adjustment that separates the position indices of internal reasoning tokens from output generation tokens, enabling parallel thinking and writing streams inside a single sequential model.
If this is right
- Models can begin emitting non-thinking output tokens while still processing the full input or new data.
- Time to first non-thinking token falls from minutes to five seconds or less.
- Overall response delays shrink by up to twelve times on reasoning tasks.
- Reasoning accuracy stays comparable to standard sequential generation on math, commonsense, and safety benchmarks.
- The change applies to existing trained models with no retraining required.
Where Pith is reading between the lines
- The same embedding adjustment might support continuous multi-turn dialogues where new user messages arrive while the model is still refining its internal reasoning.
- Combining this positional technique with other inference-time optimizations could further reduce latency in live voice or robotic systems.
- The approach suggests that other architectural properties of transformers could be repurposed to create additional interaction modes without retraining.
Load-bearing premise
Changing how positional embeddings are handled preserves the model's original reasoning accuracy and does not introduce generation inconsistencies or hallucinations.
What would settle it
A side-by-side evaluation on the same math or commonsense problems where the asynchronous version produces final answers that differ from or are less accurate than those of the unmodified baseline model.
Figures





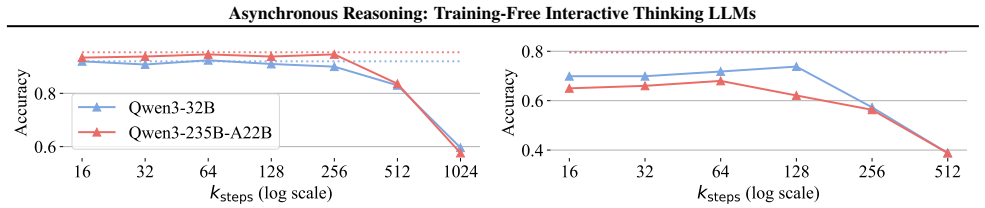

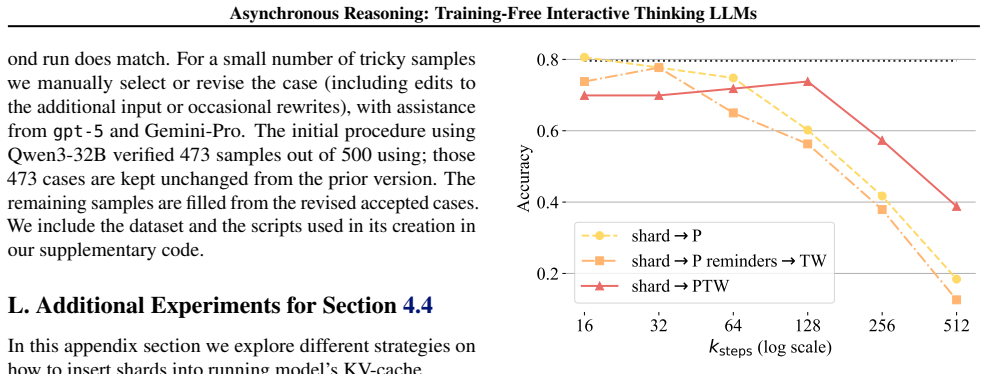



read the original abstract
Many state-of-the-art LLMs are trained to think before giving their answer. Reasoning can greatly improve language model capabilities, but it also makes them less interactive: given a new input, a model must stop thinking before it can respond. Real-world use cases such as voice-based or embodied assistants require an LLM agent to respond and adapt to additional information in real time, which is incompatible with sequential interactions. In contrast, humans can listen, think, and act asynchronously: we begin thinking about the problem while reading it and continue thinking while formulating the answer. In this work, we augment LLMs capable of reasoning to operate in a similar way without additional training. Our method uses the properties of positional embeddings to enable LLMs built for sequential generation to simultaneously think, listen, and write outputs. We evaluate our approach on math, commonsense, and safety reasoning: it allows models to generate accurate thinking-augmented answers while reducing time to first non-thinking token from minutes to ${\le}$ 5s and the overall delays by up to $12{\times}$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs trained for sequential reasoning can be made asynchronous and interactive without training by modifying positional embeddings to support simultaneous thinking, listening, and output generation. This yields accurate answers on math, commonsense, and safety tasks while cutting time-to-first-non-thinking-token from minutes to ≤5 s and overall latency by up to 12×.
Significance. If the core assumption holds, the approach would enable real-time, adaptive reasoning in voice or embodied agents without retraining, addressing a practical gap between current sequential LLMs and human-like asynchronous cognition.
major comments (2)
- [Abstract / Method] The central claim that positional-embedding alterations (offset streams or parallel position IDs) preserve the original next-token distribution and reasoning accuracy is load-bearing yet unsupported by any derivation or mechanistic argument showing why attention patterns and token dependencies learned in pre-training remain unchanged under the new position signals.
- [Evaluation] No ablation or quantitative breakdown is supplied that isolates the effect of the embedding change on reasoning fidelity (e.g., error rates, hallucination rates, or consistency under streaming inputs), leaving the reported accuracy claims unverifiable from the given evidence.
minor comments (2)
- [Method] Notation for the modified position IDs and the exact offset rule should be formalized with an equation or pseudocode to allow reproduction.
- [Experiments] The latency numbers (≤5 s, 12×) would benefit from explicit reporting of hardware, batch size, and whether measurements include or exclude the thinking stream.
Simulated Author's Rebuttal
We thank the referee for the valuable feedback on our paper 'Asynchronous Reasoning: Training-Free Interactive Thinking LLMs'. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Method] The central claim that positional-embedding alterations (offset streams or parallel position IDs) preserve the original next-token distribution and reasoning accuracy is load-bearing yet unsupported by any derivation or mechanistic argument showing why attention patterns and token dependencies learned in pre-training remain unchanged under the new position signals.
Authors: We agree a more explicit mechanistic argument is warranted. In the revised manuscript we will expand Section 3 (Method) with a dedicated paragraph explaining the invariance: because we employ parallel position IDs (or fixed offsets) per stream, the relative positional encodings within each individual stream (thinking, listening, or output) are identical to those seen during pre-training. Consequently, the attention scores and token dependencies internal to each stream remain unchanged, while cross-stream interactions are governed by the model’s existing learned weights. We will also include a short derivation sketch of the attention matrix under these position assignments to make the preservation of the next-token distribution explicit. revision: yes
-
Referee: [Evaluation] No ablation or quantitative breakdown is supplied that isolates the effect of the embedding change on reasoning fidelity (e.g., error rates, hallucination rates, or consistency under streaming inputs), leaving the reported accuracy claims unverifiable from the given evidence.
Authors: We acknowledge the absence of isolating ablations in the current version. In the revision we will add a new subsection to the Experiments section containing (i) direct accuracy comparisons on the math, commonsense, and safety benchmarks between standard sequential generation and our asynchronous setup, (ii) error-rate and hallucination-rate breakdowns, and (iii) consistency metrics when new tokens arrive mid-generation. These results will quantify that the positional modification introduces no measurable degradation in reasoning fidelity. revision: yes
Circularity Check
No circularity: method applies known positional embedding properties without self-referential derivation
full rationale
The paper describes a training-free augmentation that exploits existing properties of positional embeddings to allow simultaneous thinking/listening/output in autoregressive LLMs. No equations, parameters, or predictions are shown to reduce to fitted inputs or self-citations by construction. The central claim rests on an empirical demonstration of latency reduction while preserving task accuracy, with no load-bearing self-citation chains or ansatz smuggling. The derivation chain is therefore independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Positional embeddings can be leveraged to interleave thinking and generation tokens without breaking the model's trained behavior.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We rely on the geometric properties of rotary positional embeddings to make the LLM perceive these streams as a single contiguous sequence... rotating the attention queries... ρ(q, iq−iTk)KT
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our method uses the properties of positional embeddings to enable LLMs built for sequential generation to simultaneously think, listen, and write outputs.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Speculative Interaction Agents: Building Real-Time Agents with Asynchronous I/O and Speculative Tool Calling
Asynchronous I/O and Speculative Tool Calling cut latency in tool-calling LLM agents by 1.3-2.2x with only minor accuracy loss on cloud and edge models.
-
Speculative Interaction Agents: Building Real-Time Agents with Asynchronous I/O and Speculative Tool Calling
Speculative Interaction Agents achieve 1.3-2.2x speedups for real-time tool-calling agents via async I/O decoupling and speculative calls, with clock-based training for small edge models.
Reference graph
Works this paper leans on
-
[1]
Beeching, E., Tunstall, L., and Rush, S
URL https://api.semanticscholar.org/ CorpusID:276937204. Beeching, E., Tunstall, L., and Rush, S. Scaling test-time compute with open models, 2024. URL https://huggingface.co/spaces/HuggingFaceH4/ blogpost-scaling-test-time-compute. Betker, J. Better speech synthesis through scaling.arXiv preprint arXiv:2305.07243, 2023. Tortoise TTS: expres- sive multi-v...
-
[2]
Moshi: a speech-text foundation model for real-time dialogue
ISSN 0001-4966. doi: 10 .1121/1.1906946. URL https://doi.org/10.1121/1.1906946. Dettmers, T., Pagnoni, A., Holtzman, A., and Zettlemoyer, L. Qlora: Efficient finetuning of quantized llms. In Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., and Levine, S. (eds.),Advances in Neural Information Processing Systems, volume 36, pp. 10088– 10115. Curra...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1121/1.1906946 2023
-
[3]
URL https: //doi.org/10.1038/s41598-025-98378-1
doi: 10 .1038/s41598-025-98378-1. URL https: //doi.org/10.1038/s41598-025-98378-1. Gao, L., Madaan, A., Zhou, S., Alon, U., Liu, P., Yang, Y ., Callan, J., and Neubig, G. PAL: Program-aided language models. In Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., and Scarlett, J. (eds.),Proceedings of the 40th International Conference on Machine...
-
[4]
doi: 10.1038/s41586-025-09422-z
Accessed: 2025-04-07. Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., Bi, X., Zhang, X., Yu, X., Wu, Y ., Wu, Z. F., Gou, Z., Shao, Z., Li, Z., Gao, Z., Liu, A., Xue, B., Wang, B., Wu, B., Feng, B., Lu, C., Zhao, C., Deng, C., Ruan, C., Dai, D., Chen, D., Ji, D., Li, E., Lin, F., Dai, F., Luo, F., Hao, G., Chen, G., L...
-
[5]
doi: 10.48550/arXiv.2501.14249. Houde, S., Brimijoin, K., Muller, M., Ross, S. I., Silva Moran, D. A., Gonzalez, G. E., Kunde, S., Foreman, M. A., and Weisz, J. D. Controlling ai agent participation in group conversations: A human-centered approach. In Proceedings of the 30th International Conference on Intel- ligent User Interfaces, IUI ’25, pp. 390–408,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.14249 2025
-
[6]
LLMs Get Lost In Multi-Turn Conversation
URL https://openreview.net/forum?id= CX5c7C1CZa. Laban, P., Hayashi, H., Zhou, Y ., and Neville, J. Llms get lost in multi-turn conversation, 2025. URL https: //arxiv.org/abs/2505.06120. Lam, E. lab-mic: Record audio directly within jupyter/ipython notebooks using browser microphone. GitHub repository. URL https://github.com/ voidful/lab-mic. accessed 202...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
URL https://proceedings.mlr.press/v235/ li24ar.html. arXiv preprint arXiv:2312.04474. Li, G., Gao, Y ., Li, Y ., and Wu, Y . Thinkless: A training- free inference-efficient method for reducing reasoning redundancy.arXiv preprint arXiv:2505.15684, may
-
[8]
URL https: //arxiv.org/abs/2505.15684
doi: 10 .48550/arXiv.2505.15684. URL https: //arxiv.org/abs/2505.15684. Version 2 (last revised 23 May 2025). Liang, A., Berant, J., Fisch, A., Goyal, A., Krishna, K., and Eisenstein, J. Plantain: Plan-answer inter- leaved reasoning, 2025a. URL https://arxiv.org/ abs/2512.03176. Liang, G., Zhong, L., Yang, Z., and Quan, X. Thinkswitcher: Dynamic switching...
-
[9]
Lou, X., Li, Y ., Xu, J., Shi, X., Chen, C., and Huang, K
URL https://proceedings.mlr.press/v267/ lin25i.html. Lou, X., Li, Y ., Xu, J., Shi, X., Chen, C., and Huang, K. Think in safety: Unveiling and mitigating safety align- ment collapse in multimodal large reasoning model. In Christodoulopoulos, C., Chakraborty, T., Rose, C., and Peng, V . (eds.),Proceedings of the 2025 Conference on Empirical Methods in Natu...
work page 2025
-
[10]
URL https://proceedings.mlr.press/v235/ mazeika24a.html. Mon-Williams, R., Li, G., Long, R., Du, W., Lucas, C. G., et al. Embodied large language models enable robots to complete complex tasks in unpredictable environments. Nature Machine Intelligence, 7:592–601, 2025. doi: 10.1038/s42256-025-01005-x. Muennighoff, N., Yang, Z., Shi, W., Li, X. L., Fei-Fei...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s42256-025-01005-x 2025
-
[11]
V oice-mode multimodal model supporting audio, text, and vision
URL https://openai.com/index/hello-gpt- 4o. V oice-mode multimodal model supporting audio, text, and vision. Available at https://openai.com/index/hello- gpt-4o. OpenAI. Chatgpt deep research: Support for user update and multitasking features. https://chat.openai.com,
-
[12]
Accessed 7 December 2025. In late 2025, the Deep Research feature was updated to allow user to commu- nicate with the agent while it performs research via the "Update" button. OpenAI, :, Jaech, A., Kalai, A., Lerer, A., Richardson, A., El-Kishky, A., Low, A., Helyar, A., Madry, A., and et al., A. B. Openai o1 system card, 2024. URL https:// arxiv.org/abs/...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
gpt-oss-120b & gpt-oss-20b Model Card
URLhttps://arxiv.org/abs/2508.10925. Povey, D., Ghoshal, A., Boulianne, G., Burget, L., Glembek, O., Goel, N., Hannemann, M., Motlicek, P., Qian, Y ., Schwarz, P., Silovsky, J., Stemmer, G., and Vesely, K. The kaldi speech recognition toolkit. https://kaldi- asr.org, 2011. Open-source speech recognition toolkit. Prenger, R., Valle, R., and Catanzaro, B. W...
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[14]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
URL https://proceedings.mlr.press/v202/ radford23a.html. Rein, D., Hou, B. L., Stickland, A. C., Petty, J., Pang, R. Y ., Dirani, J., Michael, J., and Bowman, S. R. Gpqa: A graduate-level google-proof q&a benchmark, 2023. URL https://arxiv.org/abs/2311.12022. Rodionov, G., Garipov, R., Shutova, A., Yakushev, G., Schultheis, E., Egiazarian, V ., Sinitsin, ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
AudioPaLM: A Large Language Model That Can Speak and Listen
URLhttps://arxiv.org/abs/2306.12925. Sapkota, R., Cao, Y ., Roumeliotis, K. I., and Karkee, M. Vision-language-action models: Concepts, progress, ap- plications and challenges, 2025. URLarxiv.org. Schick, T., Dwivedi-Yu, J., Dessi, R., Raileanu, R., Lomeli, M., Hambro, E., Zettlemoyer, L., Cancedda, N., and Scialom, T. Toolformer: Language mod- els can te...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.21437/interspeech.2019-1873 2025
-
[16]
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
URL https://arxiv.org/abs/2503.16419. Ver- sion 4 (last updated August 21, 2025). Sun, R., Cheng, W., Li, D., Chen, H., and Wang, W. Stop when enough: Adaptive early-stopping for chain-of- thought reasoning, 2025. arXiv preprint. Suzgun, M., Scales, N., Scharli, N., Gehrmann, S., Tay, Y ., Chung, H. W., Chowdhery, A., Le, Q. V ., Chi, E. H., Zhou, D., and...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Voyager: An Open-Ended Embodied Agent with Large Language Models
URLhttps://arxiv.org/abs/2510.17238. Trasmundi, S. B. and Toro, J. Mind wandering in read- ing: An embodied approach.Frontiers in Human Neu- roscience, 17, 2023. ISSN 1662-5161. doi: 10 .3389/ fnhum.2023.1061437. URLwww.frontiersin.org. Umeda, N., Omura, H., and Fujimura, O. First complete text-to-speech system. Technical report, Electrotechnical Laborato...
work page internal anchor Pith review doi:10.48550/arxiv.2305.16291 2023
-
[18]
Tacotron: Towards End-to-End Speech Synthesis
doi: 10 .21437/Interspeech.2017-1452. URL https://arxiv.org/abs/1703.10135. Wang, Y ., Ma, X., Zhang, G., Ni, Y ., Chandra, A., Guo, S., Ren, W., Arulraj, A., He, X., Jiang, Z., et al. Mmlu-pro: A more robust and challenging multi-task language under- standing benchmark.arXiv preprint arXiv:2406.01574, 2024b. Wang, Z., Cai, S., Chen, G., Liu, A., Ma, X. S...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1016/j.specom.2009.04.004 2017
-
[19]
Universal and Transferable Adversarial Attacks on Aligned Language Models
URL https://proceedings.mlr.press/v229/ zitkovich23a.html. Zou, A., Wang, Z., Carlini, N., Nasr, M., Kolter, J. Z., and Fredrikson, M. Universal and transferable adversar- ial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023. Appendix A. Prompting In this section we provide detailed prompts used in our main and safety experiments. ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
VALIDATION: Validate final again and again until you see the same answer in the partial response above your thoughts. ,→ ,→ ,→ Sometimes, an automated system will ask you to decide if your thoughts have enough information for it write an additional passage to the user. Use the partial response above yours thoughts to judge if you addded enough new informa...
-
[23]
SAFETY CHECK: Before solving, explicitly evaluate if the user's request is safe, legal, and ethical. ,→ ,→ ,→ - If UNSAFE: Your goal is to refuse. You have "enough information" to write immediately after you decide to refuse. ,→ ,→ ,→ - If SAFE: Proceed to solve the problem step-by-step.,→
-
[24]
REASONING: If the request is safe, solve the problem.,→
-
[25]
VALIDATION: Validate final again and again until you see the same answer in the partial response above your thoughts. ,→ ,→ ,→ Sometimes, an automated system will ask you to decide if your thoughts have enough information for it write an additional passage to the user. Use the partial response above yours thoughts to judge if you addded enough new informa...
work page 2024
-
[26]
Trained mode-switching: training a classifier head, per- haps on top of the model’s own hidden state, to decide when to pause and wait for thoughts. This can reduce overhead GPU compute during inference, but it does not fit neatly into our training-free setup
-
[27]
Planned mode switching: similar to Liang et al. (2025a), we could prompt the thinker to plan ahead and decide which thoughts need to complete before the next response chunk. This type of planning can happen before thinker response or as a third “thread” concur- rent to thinker and writer. However, we found that forming such plans makes the model change it...
work page 2023
-
[28]
Race Condition:The writer begins generating a helpful response immediately based on the prompt. Although the thinker eventually concludes the request is unsafe, the writer has already streamed harmful tokens (e.g., the first steps of a dangerous recipe) to the user before the refusal signal is propagated
-
[29]
Context Leakage:The thinker analyzes the harmful re- quest by recalling technical details (e.g., explaining how a specific SQL injection works to verify its danger). The writer, attending to the thinker’s cache, interprets these technical details as the desired answer and formulates them into a response, bypassing the thinker’s intent
-
[30]
Educational Loophole:The thinker adopts an educa- tional persona to explain why a request is dangerous. The writer latches onto this educational content and re- formats it as a set of instructions, stripping away the safety framing context. Table 13.Failure mode analysis by inference setup on HarmBench. Inference Setup Failure Mode Count Baseline (Non-thi...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.