RenderFlow: Single-Step Neural Rendering via Flow Matching
Pith reviewed 2026-05-16 14:57 UTC · model grok-4.3
The pith
Flow matching enables single-step deterministic neural rendering from geometry buffers that reaches near real-time photorealistic quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
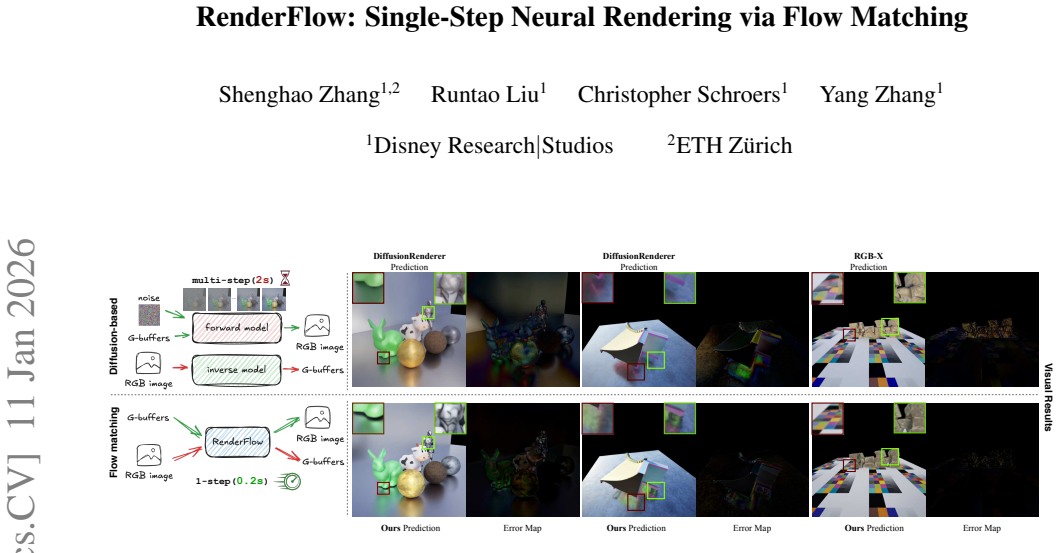
RenderFlow is an end-to-end deterministic single-step neural rendering framework built on a flow matching paradigm. An efficient sparse keyframe guidance module further strengthens rendering quality and generalization. The resulting pipeline reaches near real-time speeds with photorealistic output and can be repurposed, via a lightweight adapter, for inverse rendering tasks such as intrinsic decomposition.
What carries the argument
Flow matching paradigm that maps geometry buffers to images in one deterministic step, augmented by a sparse keyframe guidance module.
Load-bearing premise
That a flow-matching model trained on geometry buffers and optional sparse keyframes can produce outputs that are simultaneously photorealistic, physically plausible, and temporally consistent without the stochasticity of diffusion processes.
What would settle it
Run the model on a held-out scene with known ground-truth physically based renders and measure whether perceptual error stays below a small threshold while a moving-camera sequence shows no visible temporal flicker or inconsistency.
Figures















read the original abstract
Conventional physically based rendering (PBR) pipelines generate photorealistic images through computationally intensive light transport simulations. Although recent deep learning approaches leverage diffusion model priors with geometry buffers (G-buffers) to produce visually compelling results without explicit scene geometry or light simulation, they remain constrained by two major limitations. First, the iterative nature of the diffusion process introduces substantial latency. Second, the inherent stochasticity of these generative models compromises physical accuracy and temporal consistency. In response to these challenges, we propose a novel, end-to-end, deterministic, single-step neural rendering framework, RenderFlow, built upon a flow matching paradigm. To further strengthen both rendering quality and generalization, we propose an efficient and effective module for sparse keyframe guidance. Our method significantly accelerates the rendering process and, by optionally incorporating sparsely rendered keyframes as guidance, enhances both the physical plausibility and overall visual quality of the output. The resulting pipeline achieves near real-time performance with photorealistic rendering quality, effectively bridging the gap between the efficiency of modern generative models and the precision of traditional physically based rendering. Furthermore, we demonstrate the versatility of our framework by introducing a lightweight, adapter-based module that efficiently repurposes the pretrained forward model for the inverse rendering task of intrinsic decomposition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RenderFlow, a deterministic single-step neural rendering framework based on flow matching. Conditioned on geometry buffers (G-buffers) and optional sparse rendered keyframes, the method aims to produce photorealistic images at near real-time speeds while improving physical plausibility and temporal consistency over stochastic diffusion approaches. It further introduces a lightweight adapter module to repurpose the pretrained model for inverse rendering tasks such as intrinsic decomposition.
Significance. If the empirical claims hold, the work would be significant for real-time graphics and vision applications by offering a faster, deterministic bridge between generative neural renderers and traditional physically based rendering. The sparse keyframe guidance and adapter for inverse tasks are practical additions that could improve generalization and enable new workflows without retraining from scratch.
major comments (2)
- [Abstract] Abstract: the claim that sparse keyframe guidance 'enhances both the physical plausibility and overall visual quality' is load-bearing for the central contribution, yet the abstract provides no description of how the flow-matching velocity field or loss incorporates explicit light-transport constraints (energy conservation, view-consistent BRDFs, or radiative transfer); without such mechanisms the outputs remain purely statistical and may fail on novel lighting or materials.
- [Abstract] Abstract: no quantitative results, error metrics, baselines, ablation studies, or runtime measurements are referenced to support the assertions of 'near real-time performance' and 'photorealistic rendering quality'; this absence prevents assessment of whether the single-step deterministic pipeline actually closes the gap with PBR precision.
minor comments (1)
- The abstract would benefit from a brief statement of the training dataset, resolution, and hardware used for the reported near-real-time performance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each comment below and will revise the manuscript accordingly to strengthen clarity and support for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that sparse keyframe guidance 'enhances both the physical plausibility and overall visual quality' is load-bearing for the central contribution, yet the abstract provides no description of how the flow-matching velocity field or loss incorporates explicit light-transport constraints (energy conservation, view-consistent BRDFs, or radiative transfer); without such mechanisms the outputs remain purely statistical and may fail on novel lighting or materials.
Authors: We appreciate this observation. RenderFlow is trained end-to-end on image pairs generated by a physically based renderer, so the learned velocity field implicitly encodes light-transport statistics present in the training data. The sparse keyframe guidance module conditions the flow on additional G-buffer and radiance information rendered from the same PBR pipeline at selected viewpoints; this conditioning injects explicit physical observations into the generation process without requiring hand-crafted constraints inside the velocity field or loss. We acknowledge that this remains a data-driven rather than explicitly constrained approach and will revise the abstract to clarify the mechanism and note the reliance on PBR-generated training data. revision: yes
-
Referee: [Abstract] Abstract: no quantitative results, error metrics, baselines, ablation studies, or runtime measurements are referenced to support the assertions of 'near real-time performance' and 'photorealistic rendering quality'; this absence prevents assessment of whether the single-step deterministic pipeline actually closes the gap with PBR precision.
Authors: We agree that the abstract would benefit from explicit quantitative anchors. In the revised version we will add concise references to the key metrics reported in Section 4 (e.g., PSNR/SSIM gains over diffusion baselines, runtime in milliseconds on consumer GPUs, and ablation results on keyframe density) while remaining within the abstract length limit. revision: yes
Circularity Check
No significant circularity in RenderFlow derivation
full rationale
The paper introduces RenderFlow as a novel deterministic single-step neural rendering framework built on the established external flow-matching paradigm, augmented by an optional sparse-keyframe guidance module. The provided abstract and description contain no equations, no fitted parameters relabeled as predictions, no self-citations invoked for uniqueness or load-bearing premises, and no ansatzes or known results renamed as new derivations. All central claims (near-real-time performance, improved physical plausibility via guidance) are presented as consequences of the architectural choices rather than reductions to the inputs by construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formulate neural rendering as a conditional flow-based generative modeling problem... LFlow = E ||vθ(xt,t)−(x1−x0)||² (Eq. 3); single-step inference ˆz1=zt+vθ(zt,t)(1−t) (Eq. 6)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_fourth_deriv_at_zero unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Bridge matching... Brownian bridge zt=(1−t)z0+tz1+σ√t(1−t)ϵ (Eq. 4)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
D-Rex : Diffusion Rendering for Relightable Expressive Avatars
D-Rex applies a LoRA-fine-tuned video diffusion model as an image-space post-process to add consistent relighting to any expressive full-body avatar pipeline while preserving motion and facial detail.
Reference graph
Works this paper leans on
-
[1]
Attila T. ´Afra. Intel ® Open Image Denoise, 2025.https: //www.openimagedenoise.org. 6, 14
work page 2025
-
[2]
Stochastic Interpolants: A Unifying Framework for Flows and Diffusions
Michael S Albergo, Nicholas M Boffi, and Eric Vanden- Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions.arXiv preprint arXiv:2303.08797,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Physically-based shading at disney
Brent Burley and Walt Disney Animation Studios. Physically-based shading at disney. InAcm siggraph, pages 1–7. vol. 2012, 2012. 3
work page 2012
-
[4]
Flash diffusion: Accelerating any conditional diffusion model for few steps image generation
Clement Chadebec, Onur Tasar, Eyal Benaroche, and Ben- jamin Aubin. Flash diffusion: Accelerating any conditional diffusion model for few steps image generation. InProceed- ings of the AAAI Conference on Artificial Intelligence, pages 15686–15695, 2025. 7
work page 2025
-
[5]
Cl ´ement Chadebec, Onur Tasar, Sanjeev Sreetharan, and Benjamin Aubin. Lbm: Latent bridge match- ing for fast image-to-image translation.arXiv preprint arXiv:2503.07535, 2025. 2, 5
-
[6]
Scaling recti- fied flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Muller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling recti- fied flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning,
-
[7]
arXiv preprint arXiv:2506.15673 , year=
Kai He, Ruofan Liang, Jacob Munkberg, Jon Hasselgren, Nandita Vijaykumar, Alexander Keller, Sanja Fidler, Igor Gilitschenski, Zan Gojcic, and Zian Wang. Unirelight: Learning joint decomposition and synthesis for video relight- ing.arXiv preprint arXiv:2506.15673, 2025. 2
-
[8]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 3
work page 2020
-
[9]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022. 8
work page 2022
-
[10]
Henrik Wann Jensen.Realistic image synthesis using photon mapping. Ak Peters Natick, 2001. 1
work page 2001
-
[11]
Zeyinzi Jiang, Chaojie Mao, Ziyuan Huang, Ao Ma, Yiliang Lv, Yujun Shen, Deli Zhao, and Jingren Zhou. Res-tuning: A flexible and efficient tuning paradigm via unbinding tuner from backbone.Advances in Neural Information Processing Systems, 36:42689–42716, 2023. 8
work page 2023
-
[12]
VACE: All-in-One Video Creation and Editing
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu. Vace: All-in-one video creation and editing.arXiv preprint arXiv:2503.07598, 2025. 4, 5, 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Real Shading in Unreal Engine 4
Brian Karis. Real Shading in Unreal Engine 4. 2013. 3
work page 2013
-
[14]
Flux.1 kontext: Flow matching for in-context image generation and editing in latent space,
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dock- horn, Jack English, Zion English, Patrick Esser, Sumith Ku- lal, Kyle Lacey, Yam Levi, Cheng Li, Dominik Lorenz, Jonas M¨uller, Dustin Podell, Robin Rombach, Harry Saini, Axel Sauer, and Luke Smith. Flux.1 kontext: Flow matching for in-context i...
-
[15]
Diffusion- renderer: Neural inverse and forward rendering with video diffusion models
Ruofan Liang, Zan Gojcic, Huan Ling, Jacob Munkberg, Jon Hasselgren, Zhi-Hao Lin, Jun Gao, Alexander Keller, Nan- dita Vijaykumar, Sanja Fidler, and Zian Wang. Diffusion- renderer: Neural inverse and forward rendering with video diffusion models. InThe IEEE Conference on Computer Vi- sion and Pattern Recognition (CVPR), 2025. 2, 4, 6, 7, 14
work page 2025
-
[16]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022. 2, 3, 8
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 11
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
Structure-preserving super resolution with gradient guidance
Cheng Ma, Yongming Rao, Yean Cheng, Ce Chen, Jiwen Lu, and Jie Zhou. Structure-preserving super resolution with gradient guidance. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 7769–7778, 2020. 5
work page 2020
-
[19]
Deep shading: convolutional neural networks for screen space shading
Oliver Nalbach, Elena Arabadzhiyska, Dushyant Mehta, H- P Seidel, and Tobias Ritschel. Deep shading: convolutional neural networks for screen space shading. InComputer graphics forum, pages 65–78. Wiley Online Library, 2017. 2
work page 2017
-
[20]
One-Step Image Translation with Text-to- Image Models, 2024
Gaurav Parmar, Taesung Park, Srinivasa Narasimhan, and Jun-Yan Zhu. One-Step Image Translation with Text-to- Image Models, 2024. 2, 5
work page 2024
-
[21]
Matt Pharr, Wenzel Jakob, and Greg Humphreys.Physi- cally based rendering: From theory to implementation. MIT Press, 2023. 1
work page 2023
-
[22]
Poly Haven: The public 3d asset library
Poly Haven. Poly Haven: The public 3d asset library. https://polyhaven.com/, 2025. Accessed: August 3, 2025. 14
work page 2025
-
[23]
Ren ´e Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.IEEE transactions on pattern analysis and machine intelligence, 44(3):1623–1637, 2020. 5, 11
work page 2020
-
[24]
Photographic tone reproduction for digital images
Erik Reinhard, Michael Stark, Peter Shirley, and James Fer- werda. Photographic tone reproduction for digital images. In Seminal Graphics Papers: Pushing the Boundaries, Volume 2, pages 661–670. 2023. 4
work page 2023
-
[25]
Haocheng Ren, Yuchi Huo, Yifan Peng, Hongtao Sheng, Hongxiang Huang, Weidong Xue, Jingzhen Lan, Rui Wang, and Hujun Bao. Lightformer: Light-oriented global neural rendering in dynamic scene.ACM Transactions on Graph- ics, 43(4):1–14, 2024. 2
work page 2024
-
[26]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 1
work page 2022
-
[27]
Fast high- resolution image synthesis with latent adversarial diffusion distillation
Axel Sauer, Frederic Boesel, Tim Dockhorn, Andreas Blattmann, Patrick Esser, and Robin Rombach. Fast high- resolution image synthesis with latent adversarial diffusion distillation. InSIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024. 7
work page 2024
-
[28]
Adversarial diffusion distillation
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. Adversarial diffusion distillation. InEuropean 9 Conference on Computer Vision, pages 87–103. Springer,
-
[29]
Diffusion schr ¨odinger bridge matching
Yuyang Shi, Valentin De Bortoli, Andrew Campbell, and Arnaud Doucet. Diffusion schr ¨odinger bridge matching. Advances in Neural Information Processing Systems, 36: 62183–62223, 2023. 3
work page 2023
-
[30]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
-
[31]
Deep Illumination: Approximating Dynamic Global Illumination with Generative Adversarial Network
Manu Mathew Thomas and Angus G Forbes. Deep illumination: Approximating dynamic global illumina- tion with generative adversarial network.arXiv preprint arXiv:1710.09834, 2017. 2
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
Unreal engine marketplace.https:// www.fab.com/channels/unreal- engine, 2025
Unreal Engine. Unreal engine marketplace.https:// www.fab.com/channels/unreal- engine, 2025. Accessed: August 3, 2025. 13
work page 2025
-
[33]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianx- iao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jin- gren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fan...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Difix3d+: Improving 3d reconstruc- tions with single-step diffusion models
Jay Zhangjie Wu, Yuxuan Zhang, Haithem Turki, Xuanchi Ren, Jun Gao, Mike Zheng Shou, Sanja Fidler, Zan Goj- cic, and Huan Ling. Difix3d+: Improving 3d reconstruc- tions with single-step diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 26024–26035, 2025. 2
work page 2025
-
[35]
Rongyuan Wu, Lingchen Sun, Zhiyuan Ma, and Lei Zhang. One-step effective diffusion network for real-world image super-resolution.Advances in Neural Information Process- ing Systems, 37:92529–92553, 2024. 2
work page 2024
-
[36]
Jingjing Xu, Xu Sun, Zhiyuan Zhang, Guangxiang Zhao, and Junyang Lin. Understanding and improving layer normaliza- tion.Advances in neural information processing systems, 32,
-
[37]
One-step diffusion with distribution matching distillation
Tianwei Yin, Micha ¨el Gharbi, Richard Zhang, Eli Shecht- man, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 6613–6623, 2024. 2
work page 2024
-
[38]
Renderformer: Transformer-based neural rendering of triangle meshes with global illumination
Chong Zeng, Yue Dong, Pieter Peers, Hongzhi Wu, and Xin Tong. Renderformer: Transformer-based neural rendering of triangle meshes with global illumination. InACM SIG- GRAPH 2025 Conference Papers, 2025. 2
work page 2025
-
[39]
Rgbx: Image decomposition and synthesis us- ing material- and lighting-aware diffusion models
Zheng Zeng, Valentin Deschaintre, Iliyan Georgiev, Yannick Hold-Geoffroy, Yiwei Hu, Fujun Luan, Ling-Qi Yan, and Miloˇs Haˇsan. Rgbx: Image decomposition and synthesis us- ing material- and lighting-aware diffusion models. InACM SIGGRAPH 2024 Conference Papers, New York, NY , USA,
work page 2024
-
[40]
Association for Computing Machinery. 2, 6, 7
-
[41]
Instantrestore: Single-step personalized face restoration with shared-image attention,
Howard Zhang, Yuval Alaluf, Sizhuo Ma, Achuta Kadambi, Jian Wang, and Kfir Aberman. Instantrestore: Single-step personalized face restoration with shared-image attention,
-
[42]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR, 2018. 5, 6 10 RenderFlow: Single-Step Neural Rendering via Flow Matching Supplementary Material A. Implementation Details A.1. Forward Rendering Our model is fine-tuned from the pre-trained Wan2.1 (1...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.