Failure Modes in Multi-Hop QA: The Weakest Link Effect and the Recognition Bottleneck
Pith reviewed 2026-05-16 12:55 UTC · model grok-4.3
The pith
Multi-hop reasoning in LLMs collapses to the visibility level of its weakest evidence piece, set by absolute position rather than distance between facts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
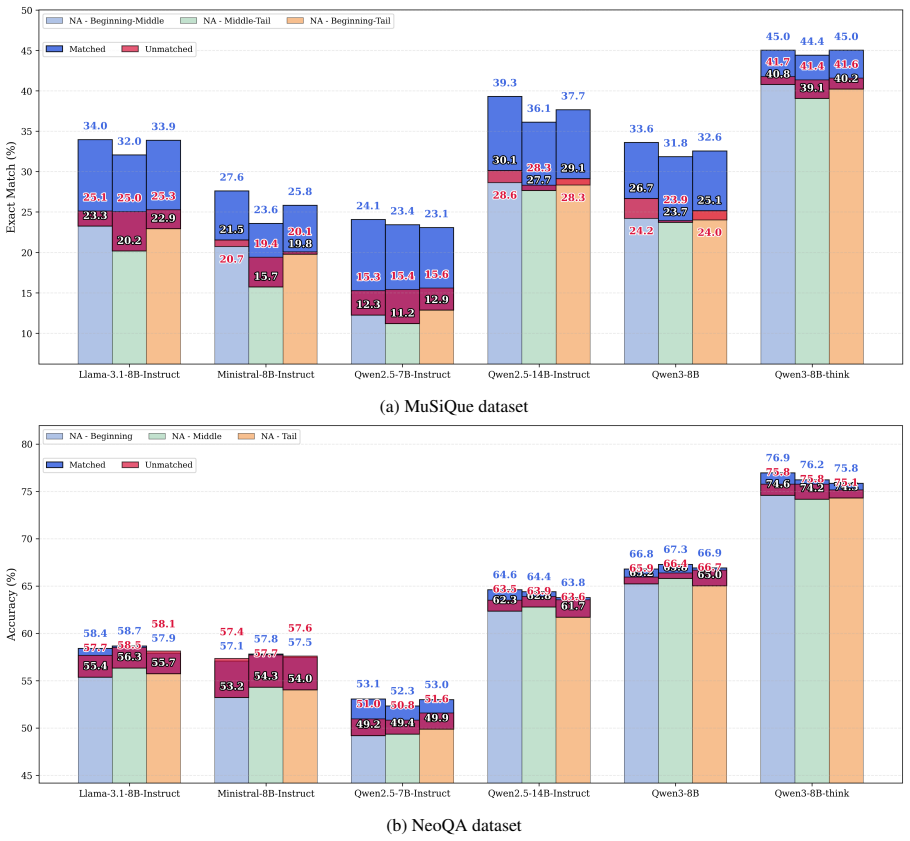
In an 18-document, 3-bucket position setup on MuSiQue and NeoQA, multi-hop QA performance drops to the level of the least visible evidence bucket. The governing factor is absolute position of the facts rather than their linear separation. The Multi-Focus Attention Instruction probe shows these drops are mainly recognition failures that can be corrected by explicit attention steering, with gains up to 11.49 percent in low-visibility positions, while misleading instructions reveal task-topology differences and System-2 reasoning models match gold-only baselines.
What carries the argument
Multi-Focus Attention Instruction (MFAI), a semantic probe that explicitly steers attention to chosen document positions to isolate recognition failure from synthesis failure.
If this is right
- Overall accuracy equals the performance on the single lowest-visibility evidence piece.
- Matched MFAI recovers up to 11.49 percent accuracy lost to poor positioning.
- Misleading MFAI hurts entity-centric vertical reasoning chains more than event-centric horizontal structures.
- System-2 thinking models locate and integrate evidence without special steering, matching gold-only results even in noisy long contexts.
Where Pith is reading between the lines
- Position bias may limit gains from simply enlarging context windows unless models are trained to treat positions uniformly.
- Reordering retrieved documents to place key facts in high-visibility slots could bypass the weakest-link limit in retrieval-augmented systems.
- The same effect likely appears in practical long-document tasks such as legal review or scientific summarization, where facts are scattered across many pages.
Load-bearing premise
The MFAI probe successfully isolates recognition failure from synthesis failure without adding its own position or semantic biases.
What would settle it
An experiment placing all required facts in high-visibility positions yet still observing accuracy collapse, or an MFAI run that fails to improve performance when recognition is confirmed as the bottleneck.
Figures






read the original abstract
Despite scaling to massive context windows, Large Language Models (LLMs) struggle with multi-hop reasoning due to inherent position bias, which causes them to overlook information at certain positions. Whether these failures stem from an inability to locate evidence (recognition failure) or integrate it (synthesis failure) is unclear. We introduce Multi-Focus Attention Instruction (MFAI), a semantic probe to disentangle these mechanisms by explicitly steering attention towards selected positions. Across 5 LLMs on two multi-hop QA tasks (MuSiQue and NeoQA), we identify the "Weakest Link Effect": in our 18-document, 3-bucket setting, multi-hop reasoning performance collapses to the level of the least visible evidence, governed by absolute position rather than the linear distance between facts. While matched MFAI resolves recognition bottlenecks, improving accuracy by up to 11.49% in low-visibility positions, misleading MFAI yields divergent effects modulated by task topology: entity-centric tasks with vertical reasoning chains are vulnerable, whereas event-centric tasks with horizontal evidence structures are more resilient. Finally, we demonstrate that thinking models utilizing System-2 reasoning effectively locate and integrate the required information, matching gold-only baselines even in noisy, long-context settings. Supplementary experiments on 2WikiMultiHopQA, extended 3-4 hop counts, and a 32B model confirm these findings generalize across datasets, reasoning depths, and model scales.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates failure modes in multi-hop QA for LLMs, attributing struggles to position bias causing recognition failures rather than synthesis failures. It introduces Multi-Focus Attention Instruction (MFAI) to steer attention to selected positions and identifies the 'Weakest Link Effect' in an 18-document, 3-bucket setting where performance collapses to the level of the least visible evidence governed by absolute position. Experiments across 5 LLMs on MuSiQue and NeoQA show matched MFAI improves accuracy by up to 11.49% in low-visibility positions, with misleading MFAI effects varying by task topology (entity-centric vs event-centric); thinking models with System-2 reasoning match gold baselines even in noisy long contexts. Findings are claimed to generalize across datasets, hops, and scales.
Significance. If the MFAI probe validly disentangles recognition from synthesis without confounding effects, the work provides concrete evidence of position-based bottlenecks in long-context reasoning and demonstrates actionable mitigations via attention steering and advanced reasoning, with quantified gains and topology-dependent patterns that could inform LLM architecture and prompting improvements.
major comments (2)
- [Experimental Setup] Experimental setup (18-document, 3-bucket design): The central Weakest Link Effect claim—that performance is governed by absolute position rather than linear distance between facts—requires explicit ablations or controls to separate position from semantic content and task topology, as the current coupling of bucket visibility with absolute position leaves the governance claim under-supported.
- [MFAI Probe] MFAI probe description and results: The assumption that MFAI isolates recognition failure is load-bearing for attributing gains (up to 11.49%) solely to overcoming position-based bottlenecks; however, the divergent effects of misleading MFAI across vertical entity chains vs horizontal event structures suggest the instructions may modulate synthesis independently, and this interaction is not controlled for or quantified.
minor comments (2)
- [Results] Results and supplementary sections: Include details on statistical tests, exact bucket definitions, confidence intervals, and full controls for the reported patterns across models and tasks to allow assessment of consistency.
- [Supplementary Experiments] The paper mentions generalization to 2WikiMultiHopQA, 3-4 hops, and 32B models; ensure all tables clearly report per-model, per-task metrics with reproducibility details.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our work. We provide detailed responses to the major comments below, defending our experimental design and MFAI probe while committing to revisions where they will strengthen the claims.
read point-by-point responses
-
Referee: [Experimental Setup] Experimental setup (18-document, 3-bucket design): The central Weakest Link Effect claim—that performance is governed by absolute position rather than linear distance between facts—requires explicit ablations or controls to separate position from semantic content and task topology, as the current coupling of bucket visibility with absolute position leaves the governance claim under-supported.
Authors: Our 18-document setup with 3 buckets was specifically designed to isolate the effect of absolute position by placing the critical evidence in different fixed position ranges (early, middle, late) while keeping the semantic content of the facts consistent across rotations. The linear distances between facts vary depending on which buckets are used, yet the performance consistently tracks the visibility of the lowest-visibility bucket, supporting that absolute position governs the weakest link rather than distance. We controlled for semantic content by using equivalent facts in different positions. For task topology, we separately analyze entity-centric vs. event-centric tasks and report the differences as findings. However, we agree that additional explicit ablations (e.g., fixing distances while varying positions) would provide stronger support, and we will include these in the revised manuscript. revision: yes
-
Referee: [MFAI Probe] MFAI probe description and results: The assumption that MFAI isolates recognition failure is load-bearing for attributing gains (up to 11.49%) solely to overcoming position-based bottlenecks; however, the divergent effects of misleading MFAI across vertical entity chains vs horizontal event structures suggest the instructions may modulate synthesis independently, and this interaction is not controlled for or quantified.
Authors: MFAI serves as a targeted probe to direct model attention to specific positions, and the substantial gains in matched MFAI conditions (up to 11.49%) in low-visibility spots indicate it primarily addresses recognition by making the evidence more salient. The divergent effects of misleading MFAI are presented as an important result rather than a limitation: they demonstrate topology-dependent vulnerabilities, with entity-centric vertical chains being more affected due to reliance on precise linking, while event-centric horizontal structures show resilience. This interaction is quantified in our results and discussed in the context of how attention steering interacts with reasoning structure. To further isolate any synthesis effects, we will add comparisons with neutral attention instructions in the revision. revision: partial
Circularity Check
No circularity: purely empirical measurements with no derivations or self-referential reductions
full rationale
The paper reports controlled experiments across LLMs and datasets using the MFAI probe to measure accuracy changes under position and visibility manipulations. No equations, fitted parameters, or derivation chains are present that could reduce claims to inputs by construction. The Weakest Link Effect is an observed pattern in accuracy data, not a computed result from prior self-citations or ansatzes. Self-citations, if any, are not load-bearing for the central empirical findings, which remain falsifiable via the reported accuracy deltas.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MuSiQue and NeoQA are representative proxies for multi-hop reasoning under position bias.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We establish the 'Weakest Link Law': multi-hop reasoning performance collapses to the performance level of the least visible evidence bucket... governed by absolute position rather than the linear distance between facts
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
George Arthur Baker, Ankush Raut, Sagi Shaier, Lawrence E Hunter, and Katharina von der Wense
Why does the effective context length of llms fall short? InThe Thirteenth International Confer- ence on Learning Representations. George Arthur Baker, Ankush Raut, Sagi Shaier, Lawrence E Hunter, and Katharina von der Wense
-
[2]
Jiabei Chen, Guang Liu, Shizhu He, Kun Luo, Yao Xu, Jun Zhao, and Kang Liu
Lost in the middle, and in-between: Enhancing language models’ ability to reason over long contexts in multi-hop qa.arXiv preprint arXiv:2412.10079. Jiabei Chen, Guang Liu, Shizhu He, Kun Luo, Yao Xu, Jun Zhao, and Kang Liu. 2025. Search-in-context: Efficient multi-hop qa over long contexts via monte carlo tree search with dynamic kv retrieval. InFind- in...
-
[3]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
The power of noise: Redefining retrieval for rag systems. InProceedings of the 47th International ACM SIGIR Conference on Research and Develop- ment in Information Retrieval, pages 719–729. Max Glockner, Xiang Jiang, Leonardo F. R. Ribeiro, Iryna Gurevych, and Markus Dreyer. 2025. NeoQA: Evidence-based question answering with generated news events. InFind...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Sohee Yang, Elena Gribovskaya, Nora Kassner, Mor Geva, and Sebastian Riedel. 2024. Do large language models latently perform multi-hop reasoning? In Proceedings of the 62nd Annual Meeting of the As- sociation for Computational Linguistics (V olume 1: Long Papers), pages 10210–10229. Zhilin Yang, Peng...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
to perform inference in the default bf16 pre- cision on A6000, 2x3090, and A100 GPUs. For all experiments, the temperature was set to 0 to enforce greedy sampling, with the random seed fixed at 42 for reproducibility. Inference on the full dataset required approximately 0.5 hours for standard instruction-following models on 2x3090, faster on A100 and A600...
work page 2024
-
[6]
We use a logarithmic scale to account for the heavy-tailed distribution of attention
Full-Span Heatmaps:These visualize the mean attention mass Ml,σ (or Hσ,h) across the sampled instances. We use a logarithmic scale to account for the heavy-tailed distribution of attention
-
[7]
This reveals relative focus regardless of the total mass assigned to the context
Document-Only Heatmaps:To isolate evidence-seeking behavior, we normalize at- tention such that the documents’ shares sum to 1 for each layer. This reveals relative focus regardless of the total mass assigned to the context
-
[8]
Difference Maps:These show the point-wise difference between conditions (e.g.,Matched minusNA) to reveal shifts in focus. Standard errors are calculated across the N in- stances to provide 95% confidence intervals for the focus curves. Gold documents are marked with an asterisk (*) and instruction-targeted documents are highlighted in red. Density(σ,A) = ...
-
[9]
Middle Mirror:The instruction points to doc- uments in the Middle bucket that share the same local indices as the gold documents
-
[10]
Tail Mirror:The instruction points to docu- ments in the Tail bucket that share the same local indices. Cross Test Variants:When G is split across two buckets (e.g., Beginning and Middle), we use three unmatched variants to average out the effects of partial correctness:
-
[11]
Partial Erroneous Mirror (Gold-1 correct): The instruction correctly points to the gold document in the first bucket (Beginning) but points to a mirrored distractor in the non-gold bucket (Tail)
-
[12]
Partial Erroneous Mirror (Gold-2 correct): The instruction correctly points to the gold 14 document in the second bucket (Middle) but points to a mirrored distractor in the non-gold bucket (Tail)
-
[13]
Random Distractor:The instruction points to two randomly selected documents within the non-gold bucket (Tail), ensuring no over- lap with the gold indices. A.6 Ablation Gold-Only Ablation.To establish an upper bound on model performance and isolate the impact of distractors, we conducted a gold-only ablation where models receive only the two gold document...
work page 2025
-
[14]
- Compare the information in the articles with the question
**Analyze the news articles:** - Carefully read all the news articles. - Compare the information in the articles with the question. - Check if the combined information from the articles confirms all the details required to answer the question
-
[15]
**Select an Answer:** - Choose the correct answer if all necessary details are provided. - If the articles lack information or any important detail is missing, select the option for "Unanswerable"
-
[16]
**Submit your Answer** - Select the answer option that correctly answers the question. If the question cannot be answered with certainty based on the news articles, choose "Unanswerable" (if it is one of the options). In the final line of your response, provide the number of the correct answer option using the format: "Answer: [answer number]" ( for examp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.