Enhancing Table Reasoning with Deterministic Table-State Rewards
Pith reviewed 2026-05-21 14:01 UTC · model grok-4.3
The pith
TABROUGE adapts longest common subsequence to give training-free rewards for intermediate table states in LLM reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
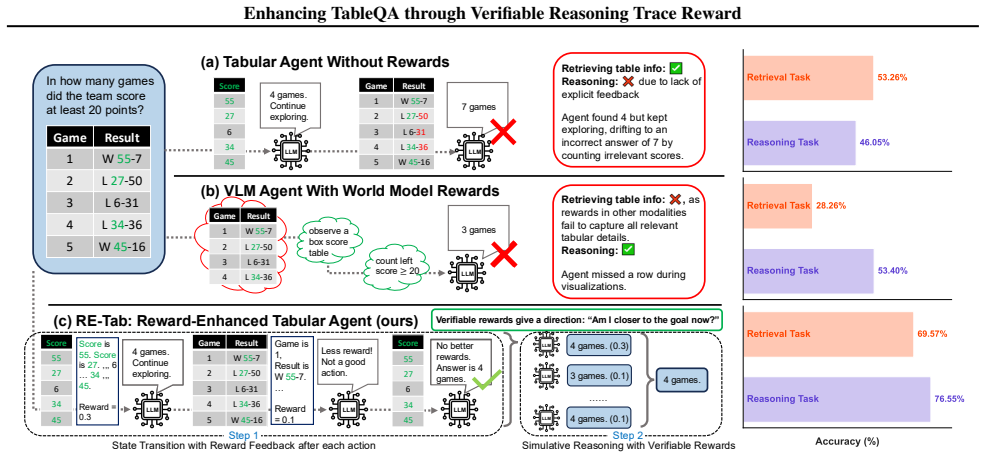
RE-TAB reframes table reasoning as deterministic control over intermediate states, utilizing TABROUGE for stepwise feedback and trajectory-level test-time scaling signals. Across six backbones and three benchmarks, RE-TAB improves accuracy by an average of 26.7 percentage points over no-reward baselines while also reducing the number of TTS samples needed by up to 33 percent. Preliminary GRPO experiments indicate TABROUGE works as a scalable post-training reward, adding 8.34 points, though the authors note failure modes such as paraphrase under-rewarding and echo-column hacking.
What carries the argument
TABROUGE, an adaptation of the Longest Common Subsequence metric that scores lexical coverage and structural integrity of intermediate tables against the input query.
If this is right
- Accuracy rises by 26.7 points on average across models and datasets when stepwise TABROUGE rewards replace no-reward baselines.
- Test-time scaling requires up to 33 percent fewer samples to reach the same performance level.
- TABROUGE can serve as a post-training reward in algorithms like GRPO, yielding an additional 8.34-point lift.
- Structure-aware lexical rewards remain reliable only when paraphrasing and column reordering stay limited.
Where Pith is reading between the lines
- The method may extend to other structured outputs such as code or database schemas if similar subsequence-based scoring is defined for those domains.
- Combining TABROUGE with small learned verifiers could address its paraphrase weaknesses while keeping most of the training-free benefit.
- Trajectory-level signals from TABROUGE might reduce the need for outcome-only supervision in broader multi-step reasoning tasks beyond tables.
Load-bearing premise
Lexical coverage and structural integrity measured by adapted LCS reliably indicate progress toward correct final answers even when queries involve paraphrasing or column reordering.
What would settle it
Run RE-TAB on a set of table queries where high TABROUGE scores on intermediate states still produce wrong final answers due to paraphrase mismatches, and check whether accuracy gains disappear.
Figures







read the original abstract
Large Language Models (LLMs) struggle with multi-step reasoning over structured tables. The primary reason is the lack of explicit supervision for intermediate reasoning states. Existing learned reward models or executor-based verifiers are either unscalable or rely on answer-checking environments unavailable for many tabular tasks. This leaves no signal that is scalable and grounded in the query. To address this, we introduce TABROUGE, a training-free and deterministic state reward. By adapting the Longest Common Subsequence (LCS) metric from text summarization to evaluate tabular states, TABROUGE assesses the lexical coverage and structural integrity of intermediate tables against the query without requiring learned models or external executors. Built upon this metric, we propose RE-TAB, a plug-and-play, training-free framework. RE-TAB reframes table reasoning as deterministic control over intermediate states, utilizing TABROUGE for stepwise feedback and trajectory-level test-time scaling (TTS) signals. Across six backbones and three benchmarks, RE-TAB improves accuracy by an average of 26.7 pp over no-reward baselines. It also reduces TTS samples by up to 33%. Preliminary GRPO experiments further indicate TABROUGE's viability as a scalable post-training reward, increasing gains by 8.34 pp. We further analyze failure modes of TABROUGE, including paraphrase under-rewarding and echo-column hacking, and identify when structure-aware lexical rewards remain reliable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TABROUGE, a training-free deterministic reward that adapts the Longest Common Subsequence (LCS) metric to evaluate lexical coverage and structural integrity of intermediate table states against the input query. It proposes the RE-TAB framework, which uses TABROUGE for stepwise supervision and trajectory-level test-time scaling (TTS) signals. Across six LLM backbones and three benchmarks, RE-TAB reports an average 26.7 pp accuracy gain over no-reward baselines, up to 33% reduction in required TTS samples, and an additional 8.34 pp gain in preliminary GRPO post-training experiments. The paper also identifies failure modes including paraphrase under-rewarding and echo-column hacking.
Significance. If the empirical results and underlying assumptions hold after addressing the noted gaps, the work provides a scalable, training-free alternative to learned reward models or executor-based verifiers for multi-step table reasoning. The deterministic formulation, explicit analysis of when structure-aware lexical rewards remain reliable, and reported efficiency gains represent a practical contribution to grounded supervision in structured reasoning tasks.
major comments (2)
- Abstract: The central accuracy claim of a 26.7 pp average improvement lacks supporting details on statistical significance testing, exact baseline implementations, and data split handling; these omissions leave the reported gains only partially substantiated from the given text.
- Abstract: The load-bearing assumption that adapted LCS reliably tracks progress toward correct final answers is undermined by the acknowledged failure mode of paraphrase under-rewarding; without a quantitative breakdown of mismatch frequency on the three benchmarks or an ablation isolating paraphrased versus lexically matched trajectories, the stepwise supervision signal's effectiveness remains insufficiently demonstrated.
minor comments (1)
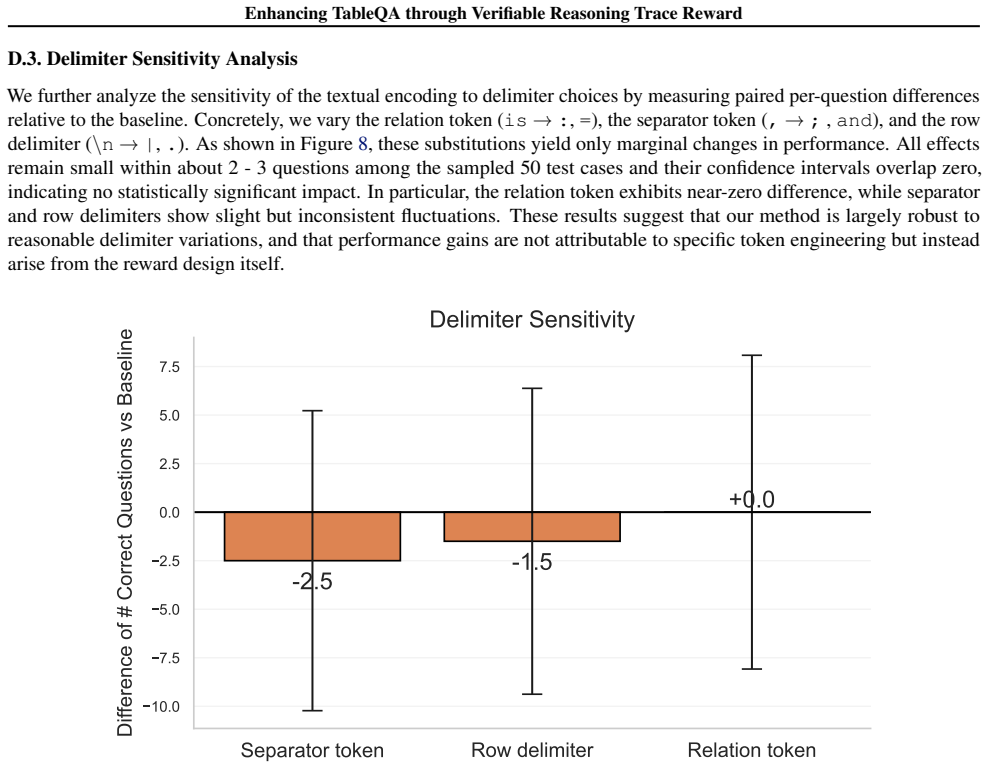
- The description of the exact LCS adaptation for tabular states (including handling of column reordering) would benefit from a dedicated methods subsection with pseudocode or a worked example to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. We address each major comment point by point below, clarifying details from the full manuscript and outlining revisions to improve substantiation of our claims.
read point-by-point responses
-
Referee: Abstract: The central accuracy claim of a 26.7 pp average improvement lacks supporting details on statistical significance testing, exact baseline implementations, and data split handling; these omissions leave the reported gains only partially substantiated from the given text.
Authors: We agree that the abstract, as a high-level summary, omits some supporting details present in the body of the paper. Section 4 specifies that baselines follow the standard implementations and prompting strategies from prior table-reasoning literature, data splits use the official benchmark partitions, and statistical significance is assessed via paired tests across five independent runs with reported standard deviations. To address the concern directly in the abstract, we will add a concise clause noting the statistical significance and reference to the experimental protocol. revision: yes
-
Referee: Abstract: The load-bearing assumption that adapted LCS reliably tracks progress toward correct final answers is undermined by the acknowledged failure mode of paraphrase under-rewarding; without a quantitative breakdown of mismatch frequency on the three benchmarks or an ablation isolating paraphrased versus lexically matched trajectories, the stepwise supervision signal's effectiveness remains insufficiently demonstrated.
Authors: We appreciate this point and the emphasis on stronger evidence for the reliability of the reward signal. The manuscript already identifies paraphrase under-rewarding as a failure mode in Section 5.3 and provides qualitative examples along with conditions under which the structure-aware lexical reward remains reliable. However, we acknowledge that a quantitative breakdown of mismatch frequency and a dedicated ablation would further substantiate the claim. We will incorporate these analyses in the revised manuscript, including mismatch rates per benchmark and performance comparison on paraphrased versus lexically aligned trajectories. revision: yes
Circularity Check
No significant circularity detected; derivation is self-contained.
full rationale
The paper introduces TABROUGE as a deterministic adaptation of the standard LCS metric to measure lexical coverage and structural integrity of intermediate table states against the query. This definition relies on an external, well-known sequence metric rather than any fitted parameters, self-referential predictions, or results from the current experiments. RE-TAB then applies this reward for stepwise feedback and TTS signals, with accuracy gains reported as empirical outcomes across backbones and benchmarks. No load-bearing self-citations, uniqueness theorems from prior author work, or ansatzes smuggled via citation appear in the provided text. The central claims rest on the independent definition of the reward and observed performance improvements, making the derivation chain self-contained without reduction to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Lexical coverage and structural integrity measured by adapted LCS serve as a reliable proxy for progress toward the correct final table answer.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We extend ROUGE-L to define TABROUGE... rTABROUGE(al, Tl+1, Q) = LCS(Q, Enc(Tl+1)) / |Enc(Tl+1)|
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
formalize the tool-based table reasoning as a Partially Observable Markov Decision Process
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
From Table to Cell: Attention for Better Reasoning with TABALIGN
TABALIGN pairs a diffusion language model planner emitting binary cell masks with a trained attention verifier, raising average accuracy 15.76 points over strong baselines on eight table benchmarks while speeding exec...
Reference graph
Works this paper leans on
-
[1]
Curran Associates Inc. ISBN 9798331314385. Basu, S., Grayson, M., Morrison, C., Nushi, B., Feizi, S., and Massiceti, D. Understanding information stor- age and transfer in multi-modal large language mod- els. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https: //openreview.net/forum?id=s63dtq0mwA. Borisov, V .,...
-
[2]
URL https://aclanthology.org/2023. findings-eacl.83/. Cheng, S., Zhuang, Z., Xu, Y ., Yang, F., Zhang, C., Qin, X., Huang, X., Chen, L., Lin, Q., Zhang, D., Rajmohan, S., and Zhang, Q. Call me when neces- sary: LLMs can efficiently and faithfully reason over structured environments. In Ku, L.-W., Martins, A., and Srikumar, V . (eds.),Findings of the Assoc...
-
[3]
Hessel, J., Holtzman, A., Forbes, M., Le Bras, R., and Choi, Y
URL https://openreview.net/forum? id=XPZIaotutsD. Hessel, J., Holtzman, A., Forbes, M., Le Bras, R., and Choi, Y . CLIPScore: A reference-free evaluation metric for image captioning. In Moens, M.-F., Huang, X., Specia, L., and Yih, S. W.-t. (eds.),Proceedings of the 2021 Con- ference on Empirical Methods in Natural Language Pro- cessing, pp. 7514–7528, On...
-
[4]
URL https://aclanthology.org/2021. emnlp-main.595/. Hollmann, N., M¨uller, S., Purucker, L., Krishnakumar, A., K¨orfer, M., Hoo, S. B., Schirrmeister, R. T., and Hutter, F. Accurate predictions on small data with a tabular foun- dation model.Nature, 637:319–326, 2025. doi: 10.1038/ s41586-024-08328-6. URL https://www.nature. com/articles/s41586-024-08328-...
work page 2021
-
[5]
Association for Computational Linguistics. ISBN 979-8-89176-256-5. doi: 10.18653/v1/2025.findings-acl
-
[6]
URL https://aclanthology.org/2025. findings-acl.1016/. Ji, D., Zhu, L., Gao, S., Xu, P., Lu, H., Ye, J., and Zhao, F. Tree-of-table: Unleashing the power of LLMs for enhanced large-scale table understanding,
work page 2025
-
[7]
doi: 10.18653/v1/2023.emnlp-main
URL https://openreview.net/forum? id=Yv8FrCY87H. Jiang, J., Zhou, K., Dong, Z., Ye, K., Zhao, X., and Wen, J.-R. StructGPT: A general framework for large language model to reason over structured data. In Bouamor, H., Pino, J., and Bali, K. (eds.),Pro- ceedings of the 2023 Conference on Empirical Meth- ods in Natural Language Processing, pp. 9237–9251, Sin...
-
[8]
URL https://aclanthology.org/2023. emnlp-main.574/. Jiang, Z., Mao, Y ., He, P., Neubig, G., and Chen, W. Om- niTab: Pretraining with natural and synthetic data for few-shot table-based question answering. In Carpuat, M., de Marneffe, M.-C., and Meza Ruiz, I. V . (eds.),Pro- ceedings of the 2022 Conference of the North American Chapter of the Association ...
-
[9]
URL https://aclanthology.org/2022. naacl-main.68/. Lee, J., Lee, J.-S., Lee, J., Choi, Y ., and Lee, J.-H. DCG- SQL: Enhancing in-context learning for text-to-SQL with deep contextual schema link graph. In Che, W., Nabende, J., Shutova, E., and Pilehvar, M. T. (eds.),Proceed- ings of the 63rd Annual Meeting of the Association for Computational Linguistics...
work page 2022
-
[10]
URL https: //aclanthology.org/2025.acl-long.748/
doi: 10.18653/v1/2025.acl-long.748. URL https: //aclanthology.org/2025.acl-long.748/. Lee, Y ., Kim, S., Rossi, R. A., Yu, T., and Chen, X. Learning to reduce: Towards improving performance of large language models on structured data, 2024. URL https://arxiv.org/abs/2407.02750. Li, B., Zhang, J., Fan, J., Xu, Y ., Chen, C., Tang, N., and Luo, Y . Alpha-SQ...
-
[11]
Cosmos World Foundation Model Platform for Physical AI
URL https://aclanthology.org/2025. findings-emnlp.1131/. Nguyen, G., Brugere, I., Sharma, S., Kariyappa, S., Nguyen, A. T., and Lecue, F. Interpretable LLM-based table question answering.Transactions on Machine Learn- ing Research, 2025. ISSN 2835-8856. URL https: //openreview.net/forum?id=2eTsZBoU2W. NVIDIA, :, Agarwal, N., Ali, A., Bala, M., Balaji, Y ....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Curran Associates Inc. ISBN 9781713871088. 11 Enhancing TableQA through Verifiable Reasoning Trace Reward Pal, V ., Yates, A., Kanoulas, E., and de Rijke, M. Multi- TabQA: Generating tabular answers for multi-table ques- tion answering. In Rogers, A., Boyd-Graber, J., and Okazaki, N. (eds.),Proceedings of the 61st Annual Meet- ing of the Association for C...
-
[13]
Association for Computational Linguistics. ISBN 979-8-89176-251-0. doi: 10.18653/v1/2025.acl-long
-
[14]
URL https://aclanthology.org/2025. acl-long.390/. Sarch, G. H., Saha, S., Khandelwal, N., Jain, A., Tarr, M. J., Kumar, A., and Fragkiadaki, K. Grounded reinforcement learning for visual reasoning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems,
work page 2025
-
[15]
Shang, Y ., Zhang, X., Tang, Y ., Jin, L., Gao, C., Wu, W., and Li, Y
URL https://openreview.net/forum? id=1amnhVRQ3l. Shang, Y ., Zhang, X., Tang, Y ., Jin, L., Gao, C., Wu, W., and Li, Y . Roboscape: Physics-informed embodied world model. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https: //openreview.net/forum?id=wbZCBBrq3W. Shrey, P. and etc. Medhallu: A comprehensive benchma...
-
[17]
URL https://aclanthology.org/2023. findings-acl.352/. Wang, K., Zhang, P., Wang, Z., Gao, Y ., Li, L., Wang, Q., Chen, H., Lu, Y ., Yang, Z., Wang, L., Krishna, R., Wu, J., Fei-Fei, L., Choi, Y ., and Li, M. V AGEN: Re- inforcing world model reasoning for multi-turn VLM agents. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems,...
work page 2023
-
[18]
Gao, S., Zhou, P., Cheng, M.-M., and Yan, S
URL https://openreview.net/forum? id=4L0xnS4GQM. Wu, J., Xu, Y ., Gao, Y ., Lou, J.-G., Karlsson, B. F., and Oku- mura, M. TACR: A table alignment-based cell selection method for HybridQA. In Rogers, A., Boyd-Graber, J., and Okazaki, N. (eds.),Findings of the Association for Computational Linguistics: ACL 2023, pp. 6535–6549, Toronto, Canada, July 2023. A...
-
[19]
In: Al-Onaizan, Y., Bansal, M., Chen, Y.-N
URL https://aclanthology.org/2023. findings-acl.409/. Wu, J., Yang, L., Li, D., Ji, Y ., Okumura, M., and Zhang, Y . MMQA: Evaluating LLMs with multi-table multi-hop complex questions. InThe Thirteenth In- ternational Conference on Learning Representations, 2025a. URL https://openreview.net/forum? id=GGlpykXDCa. Wu, J., Yin, S., Feng, N., and Long, M. RLV...
-
[20]
URL https://aclanthology.org/2024. findings-emnlp.131/. Zhang*, T., Kishore*, V ., Wu*, F., Weinberger, K. Q., and Artzi, Y . Bertscore: Evaluating text generation with bert. InInternational Conference on Learning Representations,
work page 2024
-
[21]
Zhang, Y ., Henkel, J., Floratou, A., Cahoon, J., Deep, S., and Patel, J
URL https://openreview.net/forum? id=SkeHuCVFDr. Zhang, Y ., Henkel, J., Floratou, A., Cahoon, J., Deep, S., and Patel, J. M. Reactable: Enhancing react for ta- ble question answering.Proc. VLDB Endow., 17(8): 1981–1994, April 2024b. ISSN 2150-8097. doi: 10. 14778/3659437.3659452. URL https://doi.org/ 10.14778/3659437.3659452. Zhang, Y ., Fan, M., Fan, J....
-
[22]
URL https://aclanthology.org/2025. findings-emnlp.695/. ˚Astr¨om, K. Optimal control of markov processes with incomplete state information.Journal of Mathematical Analysis and Applications, 10 (1):174–205, 1965. ISSN 0022-247X. doi: https://doi.org/10.1016/0022-247X(65)90154-X. URL https://www.sciencedirect.com/ science/article/pii/0022247X6590154X. 14 En...
-
[23]
Global State Distillation and Information CompressionIn tool-based TableQA, the observation ot is spatially limited to a small window of rows and columns, creating a significant information gap where the agent lacks visibility into the “Global Table State”Tt. Formally, the state entropy remains high given only the observation, H(T t |o t)≫0 . The scalar r...
-
[24]
Mitigation of Stochastic Drift (ϵ-Accumulation)The tool-based transition is modeled as Tt+1 =P(T t, at, θat) +ϵ t, where ϵt represents the “imagination gap” between the LLM’s predicted outcome and the actual tabular transformation. In code-based generation or unsupervised tool-calling, these discrepancies are unobserved, leading to a compounding errorPS l...
-
[25]
Convergence via Density of Search SignalsCode-based generation often suffers from sparse terminal rewards, whereas our framework utilizes rt to create adense reward environment. The trajectory reward R(τ) = P γlrl transforms the search into a directed optimization problem. The scalar rt provides a “gradient” for the agent; if an action at fails to maximiz...
-
[26]
nX i=1 Zi −E nX i=1 Zi ! ≤ −t # ≤exp − 2t2 Pn i=1(1)2 By choosingt=ϵn, Pr
Grounding of Latent State UtilityAs noted in (Wang et al., 2025b), LLMs fail to attend to all tokens, and many atomic operations (e.g., casting types or re-indexing) result in latent changes to Tt+1 that are invisible in the snapshot ot+1. In an unsupervised setting, the agent suffers fromperceptual aliasing, where it cannot distinguish between a producti...
-
[27]
Assume an answer always exists
If a name/entity mentioned in the question is not found in df, make sensible inferences to map the entity to the table. Assume an answer always exists
-
[28]
If the DataFrame contains unit symbols (e.g., $) or commas as thousand separators, use StringOperationTool()to clean the data and parse values into numbers before further computation. Tips (use if necessary). • Some columns may contain only a single group/category. • The toolset computes time differences indays. • The question may contain typos; interpret...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.