Recognition: no theorem link
From Table to Cell: Attention for Better Reasoning with TABALIGN
Pith reviewed 2026-05-15 01:25 UTC · model grok-4.3
The pith
TABALIGN pairs a diffusion language model planner that emits binary cell masks with an attention verifier trained on human standards to enforce cell grounding in table reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
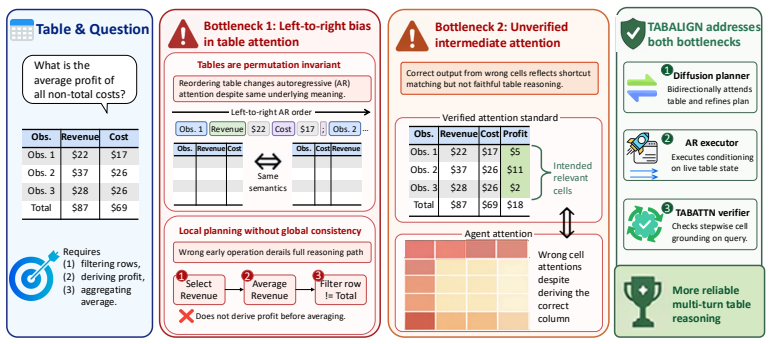
TABALIGN operationalizes a cell-grounding contract by pairing a masked diffusion language model planner, whose bidirectional denoising emits plan steps as binary cell masks, with TABATTN, a verifier trained on 1,600 human-verified attention standards that scores each step by attention overlap with the designated mask. This yields 15.76 percentage point gains in average accuracy across eight table question answering and fact verification benchmarks over the strongest open-source baseline at comparable scale, with 2.87 points attributable to the DLM planner itself.
What carries the argument
The masked DLM planner emitting binary cell masks, paired with the TABATTN verifier that scores attention overlap against human-verified standards.
If this is right
- Cleaner plans from the DLM planner accelerate downstream reasoning execution by 44.64 percent.
- Matched-backbone ablation shows 2.87 percentage points of the gain come from using DLM over AR planner on fixed reasoner.
- The approach improves both table question answering and fact verification tasks.
- Human-aligned attention standards enable reliable scoring beyond content generation alone.
Where Pith is reading between the lines
- Similar cell-mask planning could extend to other structured inputs like knowledge graphs where grounding matters.
- Training larger verifiers on more attention standards might further reduce variance across table layouts.
- The permutation stability of DLM attention suggests broader use in any data with no natural order.
Load-bearing premise
The 1,600 human-verified attention standards used to train the verifier are representative of how humans attend to cells across varied table layouts, domains, and scales.
What would settle it
Measuring attention-AUROC variability under row reordering on a new set of tables and checking whether it exceeds the reported 40.2 percent median reduction would test the stability claim.
Figures








read the original abstract
Multi-step LLM reasoning over structured tables fails because planning and execution share no explicit cell-grounding contract. Existing methods constrain the planner to a left-to-right factorization at odds with table permutation invariance, and score intermediate states by generated content alone, overlooking cell grounding. We conduct a pilot study showing that diffusion language models (DLMs) produce more human-aligned and permutation-stable cell attention on tables than autoregressive models, with a 40.2% median reduction in attention-AUROC variability under row reordering. Motivated by this, we propose TABALIGN, a planned table reasoning framework that operationalizes the contract. TABALIGN pairs a masked DLM planner, whose bidirectional denoising emits plan steps as binary cell masks, with TABATTN, a lightweight verifier trained on 1,600 human-verified attention standards to score each step by its attention overlap with the plan-designated mask. Across eight benchmarks covering table question answering and fact verification, TABALIGN improves average accuracy by 15.76 percentage points over the strongest open-source baseline at comparable 8B-class scale, with a matched-backbone ablation attributing 2.87 percentage points of this gain to the DLM planner over an AR planner on a fixed reasoner. Cleaner DLM plans also accelerate downstream reasoning execution by 44.64%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TABALIGN, a planned table reasoning framework that pairs a masked diffusion language model (DLM) planner emitting binary cell masks with TABATTN, a verifier trained on 1,600 human-verified attention standards to score plan steps by attention overlap. Motivated by a pilot study showing DLMs yield 40.2% median reduction in attention-AUROC variability under row reordering, the approach claims a 15.76 percentage point average accuracy improvement over the strongest open-source 8B-scale baseline across eight table QA and fact verification benchmarks, with a matched-backbone ablation attributing 2.87 pp of the gain to the DLM planner and 44.64% faster downstream execution.
Significance. If the results hold, the work is significant for operationalizing an explicit cell-grounding contract in table reasoning via attention overlap, addressing permutation invariance limitations of autoregressive planners. The ablation isolating the DLM planner's contribution and the reported execution speedup provide concrete evidence of practical benefit; the pilot study's stability metric further supports the motivation for diffusion-based planning over standard AR approaches.
major comments (2)
- [§4.1] §4.1 (TABATTN training): The sampling procedure for the 1,600 human-verified attention standards is not described with respect to table structures (wide vs. tall, merged cells), domains, or row/column permutation distributions. This is load-bearing for the verifier's overlap metric reliably enforcing the cell-grounding contract on out-of-distribution tables, which directly affects the attribution of the 2.87 pp ablation gain to the DLM planner.
- [§5] §5 (Experiments): The reported 15.76 pp average accuracy lift and ablation results provide no statistical significance tests, variance across runs, or exact data split details, despite the abstract claiming concrete improvements. This limits assessment of whether the gains are robust or could be explained by benchmark-specific factors.
minor comments (1)
- [§2] The abstract and §2 pilot study describe the 40.2% median reduction but do not specify the exact AUROC variability computation or number of reordering trials, which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and rigor.
read point-by-point responses
-
Referee: [§4.1] §4.1 (TABATTN training): The sampling procedure for the 1,600 human-verified attention standards is not described with respect to table structures (wide vs. tall, merged cells), domains, or row/column permutation distributions. This is load-bearing for the verifier's overlap metric reliably enforcing the cell-grounding contract on out-of-distribution tables, which directly affects the attribution of the 2.87 pp ablation gain to the DLM planner.
Authors: We agree that a detailed account of the sampling procedure is required to substantiate generalization claims. In the revised manuscript we will expand §4.1 with a full description of how the 1,600 standards were obtained, including the distribution of table widths and heights, presence of merged cells, domain coverage, and the row/column permutation rates used during collection. This addition will directly support the reliability of the attention-overlap metric and the 2.87 pp ablation attribution. revision: yes
-
Referee: [§5] §5 (Experiments): The reported 15.76 pp average accuracy lift and ablation results provide no statistical significance tests, variance across runs, or exact data split details, despite the abstract claiming concrete improvements. This limits assessment of whether the gains are robust or could be explained by benchmark-specific factors.
Authors: We acknowledge the absence of statistical tests and variance reporting in the original submission. In the revised §5 we will report standard deviations across multiple runs, include paired statistical significance tests for the accuracy improvements, and provide exact train/validation/test split details for all eight benchmarks in the appendix. These additions will allow readers to evaluate the robustness of the reported gains. revision: yes
Circularity Check
No circularity: gains measured on held-out benchmarks independent of training standards
full rationale
The paper reports accuracy improvements and ablation gains on eight external benchmarks. These quantities are not defined by or fitted to the 1,600 human-verified attention standards used only to train the TABATTN verifier. No equations, self-citations, or renamings reduce the claimed 15.76 pp or 2.87 pp deltas to quantities constructed from the verifier training data itself. The derivation chain therefore remains self-contained against external evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human-verified attention standards on 1,600 examples constitute a reliable and generalizable proxy for correct cell grounding.
invented entities (2)
-
TABALIGN framework
no independent evidence
-
TABATTN verifier
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Adapting autoregressive vision language models for parallel diffusion decoding, 2025
Marianne Arriola, Naveen Venkat, Jonathan Granskog, and Anastasis Germanidis. Adapting autoregressive vision language models for parallel diffusion decoding, 2025. URL https: //runwayml.com/research/autoregressive-to-diffusion-vlms
work page 2025
-
[2]
Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg
Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. Structured denoising diffusion models in discrete state-spaces. In A. Beygelzimer, Y . Dauphin, P. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems,
-
[3]
URLhttps://openreview.net/forum?id=h7-XixPCAL
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report.Ar...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Lina Berrayana, Ahmed Heakl, Muhammad Abdullah Sohail, Thomas Hofmann, Salman Khan, and Wei Chen. Planner and executor: Collaboration between discrete diffusion and auto-regressive models in reasoning, 2026. URL https://openreview.net/forum?id= AhggxqDQCb
work page 2026
-
[7]
LLaDA2.0: Scaling Up Diffusion Language Models to 100B
Tiwei Bie, Maosong Cao, Kun Chen, Lun Du, Mingliang Gong, Zhuochen Gong, Yanmei Gu, Jiaqi Hu, Zenan Huang, Zhenzhong Lan, Chengxi Li, Chongxuan Li, Jianguo Li, Zehuan Li, Huabin Liu, Lin Liu, Guoshan Lu, Xiaocheng Lu, Yuxin Ma, Jianfeng Tan, Lanning Wei, Ji-Rong Wen, Yipeng Xing, Xiaolu Zhang, Junbo Zhao, Da Zheng, Jun Zhou, Junlin Zhou, Zhanchao Zhou, Li...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
CQA-Eval: Designing Reliable Evaluations of Multi-paragraph Clinical QA under Resource Constraints
Federica Bologna, Tiffany Pan, Matthew Wilkens, Yue Guo, and Lucy Lu Wang. Cqa-eval: Designing reliable evaluations of multi-paragraph clinical qa under resource constraints, 2026. URLhttps://arxiv.org/abs/2510.10415
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Tabfact: A large-scale dataset for table-based fact verification
Wenhu Chen, Hongmin Wang, Jianshu Chen, Yunkai Zhang, Hong Wang, Shiyang Li, Xiyou Zhou, and William Yang Wang. Tabfact: A large-scale dataset for table-based fact verification. InInternational Conference on Learning Representations, 2020. URL https://openreview. net/forum?id=rkeJRhNYDH. 10
work page 2020
-
[10]
HiTab: A hierarchical table dataset for question an- swering and natural language generation
Zhoujun Cheng, Haoyu Dong, Zhiruo Wang, Ran Jia, Jiaqi Guo, Yan Gao, Shi Han, Jian- Guang Lou, and Dongmei Zhang. HiTab: A hierarchical table dataset for question an- swering and natural language generation. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, editors,Proceedings of the 60th Annual Meeting of the Association for Com- putational Li...
-
[11]
doi: 10.18653/v1/2022.acl-long.78
Association for Computational Linguistics. doi: 10.18653/v1/2022.acl-long.78. URL https://aclanthology.org/2022.acl-long.78/
-
[12]
Planu: Large language model reasoning through planning under uncertainty
Ziwei Deng, Mian Deng, Chenjing Liang, Zeming Gao, Chennan Ma, Chenxing Lin, Haipeng Zhang, Songzhu Mei, Siqi Shen, and Cheng Wang. Planu: Large language model reasoning through planning under uncertainty. InThe Thirty-ninth Annual Conference on Neural Informa- tion Processing Systems, 2026. URLhttps://openreview.net/forum?id=r3LYE0Ct3G
work page 2026
-
[13]
Theoretical ben- efit and limitation of diffusion language model
Guhao Feng, Yihan Geng, Jian Guan, Wei Wu, Liwei Wang, and Di He. Theoretical ben- efit and limitation of diffusion language model. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id= fGBCRZQVse
work page 2026
-
[14]
Scaling diffusion language models via adaptation from autoregressive models
Shansan Gong, Shivam Agarwal, Yizhe Zhang, Jiacheng Ye, Lin Zheng, Mukai Li, Chenxin An, Peilin Zhao, Wei Bi, Jiawei Han, Hao Peng, and Lingpeng Kong. Scaling diffusion language models via adaptation from autoregressive models. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum? id=j1tSLYKwg8
work page 2025
-
[15]
Google. Gemini 3 flash. https://blog.google/products-and-platforms/products/ gemini/gemini-3-flash/, 2025. Accessed: 2026-04-22
work page 2025
-
[16]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ah- mad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Yu Guo, Shenghao Ye, Shuangwu Chen, Zijian Wen, Tao Zhang, Qirui Bai, Dong Jin, Yunpeng Hou, Huasen He, Jian Yang, and Xiaobin Tan. Rethinking table pruning in tableqa: From sequential revisions to gold trajectory-supervised parallel search, 2026. URL https://arxiv. org/abs/2601.03851
-
[18]
INFOTABS: Inference on tables as semi-structured data
Vivek Gupta, Maitrey Mehta, Pegah Nokhiz, and Vivek Srikumar. INFOTABS: Inference on tables as semi-structured data. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault, editors,Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 2309–2324, Online, July 2020. Association for Computational Linguistic...
-
[19]
UltraLLaDA: Scaling the context length to 128k for diffusion large language models
Guangxin He, Shen Nie, Fengqi Zhu, Yuankang Zhao, Tianyi Bai, Ran Yan, Jie Fu, Chongxuan Li, and Binhang Yuan. UltraLLaDA: Scaling the context length to 128k for diffusion large language models. InThe Fourteenth International Conference on Learning Representations,
-
[20]
URLhttps://openreview.net/forum?id=68DGlhlvD9
-
[21]
TaPas: Weakly supervised table parsing via pre-training
Jonathan Herzig, Pawel Krzysztof Nowak, Thomas Müller, Francesco Piccinno, and Julian Eisenschlos. TaPas: Weakly supervised table parsing via pre-training. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault, editors,Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4320–4333, Online, July
-
[22]
doi: 10.18653/v1/2020.acl-main.398
Association for Computational Linguistics. doi: 10.18653/v1/2020.acl-main.398. URL https://aclanthology.org/2020.acl-main.398/
-
[23]
Tree-of- table: Unleashing the power of LLMs for enhanced large-scale table understanding, 2025
Deyi Ji, Lanyun Zhu, Siqi Gao, Peng Xu, Hongtao Lu, Jieping Ye, and Feng Zhao. Tree-of- table: Unleashing the power of LLMs for enhanced large-scale table understanding, 2025. URL https://openreview.net/forum?id=Yv8FrCY87H
work page 2025
-
[24]
Kakade, Timothy Ngotiaoco, Sitan Chen, and Michael Samuel Albergo
Jaeyeon Kim, Lee Cheuk Kit, Carles Domingo-Enrich, Yilun Du, Sham M. Kakade, Timothy Ngotiaoco, Sitan Chen, and Michael Samuel Albergo. Any-order flexible length masked diffusion. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=ttuNnMRI6H
work page 2026
-
[25]
Tabddpm: modelling tabular data with diffusion models
Akim Kotelnikov, Dmitry Baranchuk, Ivan Rubachev, and Artem Babenko. Tabddpm: modelling tabular data with diffusion models. InProceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023. URLhttps://dl.acm.org/doi/10.5555/ 3618408.3619133
-
[26]
Kalpesh Krishna, Erin Bransom, Bailey Kuehl, Mohit Iyyer, Pradeep Dasigi, Arman Cohan, and Kyle Lo. LongEval: Guidelines for human evaluation of faithfulness in long-form summariza- tion. In Andreas Vlachos and Isabelle Augenstein, editors,Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 16...
-
[27]
Enhancing tableqa through verifiable reasoning trace reward, 2026
Tung Sum Thomas Kwok, Xinyu Wang, Hengzhi He, Xiaofeng Lin, Peng Lu, Liheng Ma, Chunhe Wang, Ying Nian Wu, Lei Ding, and Guang Cheng. Enhancing tableqa through verifiable reasoning trace reward, 2026. URLhttps://arxiv.org/abs/2601.22530
-
[28]
TABQAWORLD: Optimizing Multimodal Reasoning for Multi-Turn Table Question Answering
Tung Sum Thomas Kwok, Xinyu Wang, Xiaofeng Lin, Peng Lu, Chunhe Wang, Changlun Li, Hanwei Wu, Nan Tang, Elisa Kreiss, and Guang Cheng. Tabqaworld: Optimizing multimodal reasoning for multi-turn table question answering, 2026. URL https://arxiv.org/abs/ 2604.03393
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Beyond fixed: Training-free variable-length denoising for diffusion large language models
Jinsong Li, Xiaoyi Dong, Yuhang Zang, Yuhang Cao, Jiaqi Wang, and Dahua Lin. Beyond fixed: Training-free variable-length denoising for diffusion large language models. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=Ic2A2gCseC. 13
work page 2026
-
[30]
Diffusion-LM improves controllable text generation
Xiang Lisa Li, John Thickstun, Ishaan Gulrajani, Percy Liang, and Tatsunori Hashimoto. Diffusion-LM improves controllable text generation. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors,Advances in Neural Information Processing Systems,
-
[31]
URLhttps://openreview.net/forum?id=3s9IrEsjLyk
-
[32]
Yang Li, Zhichen Dong, Yuhan Sun, Weixun Wang, Shaopan Xiong, Yijia Luo, Jiashun Liu, Han Lu, Jiamang Wang, Wenbo Su, Bo Zheng, and Junchi Yan. Attention illuminates llm reasoning: The preplan-and-anchor rhythm enables fine-grained policy optimization, 2025. URLhttps://arxiv.org/abs/2510.13554
-
[33]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=v8L0pN6EOi
work page 2024
-
[34]
CTSyn: A foundation model for cross tabular data generation
Xiaofeng Lin, Chenheng Xu, Matthew Yang, and Guang Cheng. CTSyn: A foundation model for cross tabular data generation. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=Sh4FOyZRpv
work page 2025
-
[35]
Tianyang Liu, Fei Wang, and Muhao Chen. Rethinking tabular data understanding with large language models. In Kevin Duh, Helena Gomez, and Steven Bethard, editors,Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 450–482, Mexico City,...
-
[36]
Longllada: Unlocking long context capabilities in diffusion llms
Xiaoran Liu, Yuerong Song, Zhigeng Liu, Zengfeng Huang, Qipeng Guo, Ziwei He, and Xipeng Qiu. Longllada: Unlocking long context capabilities in diffusion llms. InProceedings of the AAAI Conference on Artificial Intelligence, 2026. URLhttps://doi.org/10.1609/aaai. v40i38.40491
-
[37]
Discrete diffusion modeling by estimating the ratios of the data distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution. InProceedings of the 41st International Conference on Machine Learning, ICML’24, 2024. URLhttps://dl.acm.org/doi/10.5555/3692070.3693403
-
[38]
AutoPSV: Automated process-supervised verifier
Jianqiao Lu, Zhiyang Dou, Hongru W ANG, Zeyu Cao, Jianbo Dai, Yunlong Feng, and Zhijiang Guo. AutoPSV: Automated process-supervised verifier. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum? id=eOAPWWOGs9
work page 2024
-
[39]
Dynamic prompt learning via policy gradient for semi-structured mathematical reasoning
Pan Lu, Liang Qiu, Kai-Wei Chang, Ying Nian Wu, Song-Chun Zhu, Tanmay Rajpurohit, Peter Clark, and Ashwin Kalyan. Dynamic prompt learning via policy gradient for semi-structured mathematical reasoning. InThe Eleventh International Conference on Learning Representations,
-
[40]
URLhttps://openreview.net/forum?id=DHyHRBwJUTN
-
[41]
Ovis2.5 technical report.arXiv:2508.11737, 2025
Shiyin Lu, Yang Li, Yu Xia, Yuwei Hu, Shanshan Zhao, Yanqing Ma, Zhichao Wei, Yinglun Li, Lunhao Duan, Jianshan Zhao, Yuxuan Han, Haijun Li, Wanying Chen, Junke Tang, Chengkun Hou, Zhixing Du, Tianli Zhou, Wenjie Zhang, Huping Ding, Jiahe Li, Wen Li, Gui Hu, Yiliang Gu, Siran Yang, Jiamang Wang, Hailong Sun, Yibo Wang, Hui Sun, Jinlong Huang, Yuping He, S...
-
[42]
F e T a QA : Free-form Table Question Answering
Linyong Nan, Chiachun Hsieh, Ziming Mao, Xi Victoria Lin, Neha Verma, Rui Zhang, Wojciech Kry´sci´nski, Hailey Schoelkopf, Riley Kong, Xiangru Tang, Mutethia Mutuma, Ben Rosand, Isabel Trindade, Renusree Bandaru, Jacob Cunningham, Caiming Xiong, and Dragomir Radev. FeTaQA: Free-form table question answering.Transactions of the Asso- ciation for Computatio...
-
[43]
Interpretable LLM-based table question answering.Transactions on Machine Learning Research, 2025
Giang Nguyen, Ivan Brugere, Shubham Sharma, Sanjay Kariyappa, Anh Totti Nguyen, and Freddy Lecue. Interpretable LLM-based table question answering.Transactions on Machine Learning Research, 2025. ISSN 2835-8856. URL https://openreview.net/forum?id= 2eTsZBoU2W. 14
work page 2025
-
[44]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models, 2025. URL https: //arxiv.org/abs/2502.09992
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
B leu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th Annual Meeting on Association for Computational Linguistics, ACL ’02, page 311–318, USA, 2002. Association for Computational Linguistics. doi: 10.3115/1073083.1073135. URL https://doi.org/10.3115/1073083. 1073135
-
[46]
Compositional semantic parsing on semi-structured tables
Panupong Pasupat and Percy Liang. Compositional semantic parsing on semi-structured tables. In Chengqing Zong and Michael Strube, editors,Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 1470–1480, Beijing, China,...
-
[47]
Rewarding the Scientific Process: Process-Level Reward Modeling for Agentic Data Analysis
Zhisong Qiu, Shuofei Qiao, Kewei Xu, Yuqi Zhu, Lun Du, Ningyu Zhang, and Huajun Chen. Rewarding the scientific process: Process-level reward modeling for agentic data analysis, 2026. URLhttps://arxiv.org/abs/2604.24198
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[48]
Pre-act: Multi-step planning and reasoning improves acting in llm agents, 2025
Mrinal Rawat, Ambuje Gupta, Rushil Goomer, Alessandro Di Bari, Neha Gupta, and Roberto Pieraccini. Pre-act: Multi-step planning and reasoning improves acting in llm agents, 2025. URLhttps://arxiv.org/abs/2505.09970
-
[49]
Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using Siamese BERT- networks. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan, editors,Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982–3992,...
-
[50]
Simple and effective masked diffusion language models
Subham Sekhar Sahoo, Marianne Arriola, Aaron Gokaslan, Edgar Mariano Marroquin, Alexan- der M Rush, Yair Schiff, Justin T Chiu, and V olodymyr Kuleshov. Simple and effective masked diffusion language models. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URLhttps://openreview.net/forum?id=L4uaAR4ArM
work page 2024
-
[51]
Subham Sekhar Sahoo, Justin Deschenaux, Aaron Gokaslan, Guanghan Wang, Justin T Chiu, and V olodymyr Kuleshov. The diffusion duality. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=9P9Y8FOSOk
work page 2025
-
[52]
Seed Diffusion: A Large-Scale Diffusion Language Model with High-Speed Inference
Yuxuan Song, Zheng Zhang, Cheng Luo, Pengyang Gao, Fan Xia, Hao Luo, Zheng Li, Yuehang Yang, Hongli Yu, Xingwei Qu, Yuwei Fu, Jing Su, Ge Zhang, Wenhao Huang, Mingxuan Wang, Lin Yan, Xiaoying Jia, Jingjing Liu, Wei-Ying Ma, Ya-Qin Zhang, Yonghui Wu, and Hao Zhou. Seed diffusion: A large-scale diffusion language model with high-speed inference, 2025. URL h...
work page internal anchor Pith review arXiv 2025
-
[53]
Harald Steck, Chaitanya Ekanadham, and Nathan Kallus. Is cosine-similarity of embed- dings really about similarity? InCompanion Proceedings of the ACM Web Conference 2024, WWW ’24, page 887–890, New York, NY , USA, 2024. Association for Comput- ing Machinery. ISBN 9798400701726. doi: 10.1145/3589335.3651526. URL https: //doi.org/10.1145/3589335.3651526
-
[54]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Harts...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[55]
Francis Song, Noah Yamamoto Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins
Jonathan Uesato, Nate Kushman, Ramana Kumar, H. Francis Song, Noah Yamamoto Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process-based and outcome-based feedback, 2023. URL https://openreview.net/ forum?id=MND1kmmNy0O
work page 2023
-
[56]
Haolan Wang, Zhenghao Liu, Xinze Li, Xiaocui Yang, Yu Gu, Yukun Yan, Qi Shi, Fangfang Li, Chong Chen, and Ge Yu. Hippo: Enhancing the table understanding capability of llms through hybrid-modal preference optimization, 2026. URLhttps://arxiv.org/abs/2502.17315
-
[57]
Math-shepherd: Verify and reinforce LLMs step-by-step without human annotations
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce LLMs step-by-step without human annotations. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), page...
-
[58]
Diffusion LLMs can do faster-than-AR inference via discrete diffusion forcing
Xu Wang, Chenkai Xu, Yijie Jin, Jiachun Jin, Hao Zhang, Kai Yu, and Zhijie Deng. Diffusion LLMs can do faster-than-AR inference via discrete diffusion forcing. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=t5uLZSRjhF
work page 2026
-
[59]
Chain- of-table: Evolving tables in the reasoning chain for table understanding
Zilong Wang, Hao Zhang, Chun-Liang Li, Julian Martin Eisenschlos, Vincent Perot, Zifeng Wang, Lesly Miculicich, Yasuhisa Fujii, Jingbo Shang, Chen-Yu Lee, and Tomas Pfister. Chain- of-table: Evolving tables in the reasoning chain for table understanding. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview. net/...
work page 2024
-
[60]
Benjamin Warner, Antoine Chaffin, Benjamin Clavié, Orion Weller, Oskar Hallström, Said Taghadouini, Alexis Gallagher, Raja Biswas, Faisal Ladhak, Tom Aarsen, Griffin Thomas Adams, Jeremy Howard, and Iacopo Poli. Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference. In Wanxian...
-
[61]
MMQA: Evaluating LLMs with multi-table multi-hop complex questions
Jian Wu, Linyi Yang, Dongyuan Li, Yuliang Ji, Manabu Okumura, and Yue Zhang. MMQA: Evaluating LLMs with multi-table multi-hop complex questions. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum? id=GGlpykXDCa
work page 2025
-
[62]
Junjie Xing, Yeye He, Mengyu Zhou, Haoyu Dong, Shi Han, Lingjiao Chen, Dongmei Zhang, Surajit Chaudhuri, and H. V . Jagadish. MMTU: A massive multi-task table understanding and reasoning benchmark. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025. URLhttps://openreview.net/ forum?id=ryUzgwD6UQ
work page 2025
-
[63]
TableDART: Dynamic adaptive multi-modal routing for table understanding
Xiaobo Xing, Wei Yuan, Tong Chen, Quoc Viet Hung Nguyen, Xiangliang Zhang, and Hongzhi Yin. TableDART: Dynamic adaptive multi-modal routing for table understanding. InThe Fourteenth International Conference on Learning Representations, 2026. URL https:// openreview.net/forum?id=4aZTiLH3fm
work page 2026
-
[64]
Unveiling the potential of diffusion large language model in controllable generation
Zhen Xiong, Yujun Cai, Zhecheng Li, and Yiwei Wang. Unveiling the potential of diffusion large language model in controllable generation. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=qhd0qv6L0k. 16
work page 2026
-
[65]
Visual planning: Let’s think only with images
Yi Xu, Chengzu Li, Han Zhou, Xingchen Wan, Caiqi Zhang, Anna Korhonen, and Ivan Vuli´c. Visual planning: Let’s think only with images. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=wsnse46kRO
work page 2026
-
[66]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
DARE: Diffusion Large Language Models Alignment and Reinforcement Executor
Jingyi Yang, Yuxian Jiang, Xuhao Hu, Shuang Cheng, Biqing Qi, and Jing Shao. Dare: Diffusion large language models alignment and reinforcement executor, 2026. URL https: //arxiv.org/abs/2604.04215
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[68]
Tablegpt-r1: Advancing tabular reasoning through reinforcement learning, 2025
Saisai Yang, Qingyi Huang, Jing Yuan, Liangyu Zha, Kai Tang, Yuhang Yang, Ning Wang, Yucheng Wei, Liyao Li, Wentao Ye, Hao Chen, Tao Zhang, Junlin Zhou, Haobo Wang, Gang Chen, and Junbo Zhao. Tablegpt-r1: Advancing tabular reasoning through reinforcement learning, 2025. URLhttps://arxiv.org/abs/2512.20312
-
[69]
Triples as the key: Structuring makes decomposition and verification easier in LLM-based tableQA
Zhen Yang, Ziwei Du, Minghan Zhang, Wei Du, Jie Chen, Zhen Duan, and Shu Zhao. Triples as the key: Structuring makes decomposition and verification easier in LLM-based tableQA. InThe Thirteenth International Conference on Learning Representations, 2025. URL https: //openreview.net/forum?id=UwcZEoNP19
work page 2025
-
[70]
Causality meets the table: Debiasing LLMs for faithful TableQA via front-door intervention
Zhen Yang, Ziwei Du, Minghan Zhang, Wei Du, Jie Chen, Fulan Qian, and Shu Zhao. Causality meets the table: Debiasing LLMs for faithful TableQA via front-door intervention. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps: //neurips.cc/virtual/2025/loc/san-diego/poster/115020
work page 2025
-
[71]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023. URLhttps://arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[72]
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Chi Chen, Haoyu Li, Weilin Zhao, Zhihui He, Qianyu Chen, Ronghua Zhou, Zhensheng Zou, Haoye Zhang, Shengding Hu, Zhi Zheng, Jie Zhou, Jie Cai, Xu Han, Guoyang Zeng, Dahai Li, Zhiyuan Liu, and Maosong Sun. Efficient gpt-4v level multimodal large language model for deployment o...
-
[73]
Dream 7B: Diffusion Large Language Models
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models, 2025. URL https://arxiv.org/abs/ 2508.15487
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
Yunhu Ye, Binyuan Hui, Min Yang, Binhua Li, Fei Huang, and Yongbin Li. Large language models are versatile decomposers: Decomposing evidence and questions for table-based rea- soning. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’23, page 174–184, New York, NY , USA, 2023. Associa...
-
[75]
TaBERT: Pretraining for joint understanding of textual and tabular data
Pengcheng Yin, Graham Neubig, Wen-tau Yih, and Sebastian Riedel. TaBERT: Pretraining for joint understanding of textual and tabular data. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault, editors,Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8413–8426, Online, July 2020. Association for Com...
-
[76]
Hengrui Zhang, Liancheng Fang, Qitian Wu, and Philip S. Yu. TabNAT: A continuous-discrete joint generative framework for tabular data. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=WbfbT2BH6F
work page 2025
-
[77]
Tablellama: Towards open large generalist models for tables, 2024
Tianshu Zhang, Xiang Yue, Yifei Li, and Huan Sun. Tablellama: Towards open large generalist models for tables, 2024. URLhttps://arxiv.org/abs/2311.09206
-
[78]
TableLLM: Enabling tabular data manipulation by LLMs in real office usage scenarios
Xiaokang Zhang, Sijia Luo, Bohan Zhang, Zeyao Ma, Jing Zhang, Yang Li, Guanlin Li, Zijun Yao, Kangli Xu, Jinchang Zhou, Daniel Zhang-Li, Jifan Yu, Shu Zhao, Juanzi Li, and Jie Tang. TableLLM: Enabling tabular data manipulation by LLMs in real office usage scenarios. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, F...
-
[79]
Yunjia Zhang, Jordan Henkel, Avrilia Floratou, Joyce Cahoon, Shaleen Deep, and Jignesh M. Patel. Reactable: Enhancing react for table question answering.Proc. VLDB Endow., 17(8): 1981–1994, April 2024. ISSN 2150-8097. doi: 10.14778/3659437.3659452. URL https: //doi.org/10.14778/3659437.3659452
-
[80]
Multimodal table understanding
Mingyu Zheng, Xinwei Feng, Qingyi Si, Qiaoqiao She, Zheng Lin, Wenbin Jiang, and Weip- ing Wang. Multimodal table understanding. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computa- tional Linguistics (Volume 1: Long Papers), pages 9102–9124, Bangkok, Thailand, August
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.