Recognition: no theorem link
ReplicatorBench: Benchmarking LLM Agents for Replicability in Social and Behavioral Sciences
Pith reviewed 2026-05-16 01:52 UTC · model grok-4.3
The pith
LLM agents design and run replication experiments effectively but fail to retrieve necessary new data for social and behavioral science claims.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
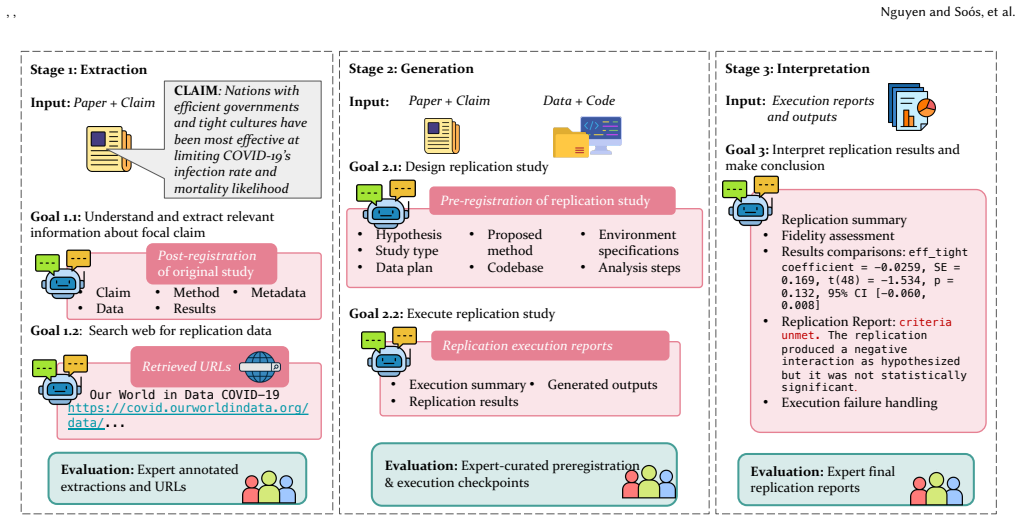
ReplicatorBench supplies human-verified replicable and non-replicable claims and measures agent performance across three stages: extraction and retrieval of replication data, design and execution of computational experiments, and interpretation of results. When tested with ReplicatorAgent using tools for web search and sandboxed code execution, agents succeed at designing and running experiments but fail at retrieving new data required to replicate claims.
What carries the argument
ReplicatorBench benchmark with human-verified replicable and non-replicable claims, structured around three replication stages, paired with ReplicatorAgent framework that uses web search and iterative sandboxed code execution.
If this is right
- Agents achieve higher success when given partial code access than when starting from no code.
- Performance varies across underlying LLMs, with some models handling experiment execution more reliably.
- The benchmark distinguishes retrieval failures from execution failures, allowing targeted diagnosis of agent weaknesses.
- Struggles with new data retrieval limit agents to reproduction tasks rather than true replication.
Where Pith is reading between the lines
- Better integration with external databases or search APIs could close the main performance gap identified.
- The same three-stage structure could be adapted to test replication in other disciplines with sparse data.
- Agents that improve on retrieval might enable automated screening of large literatures for questionable findings.
Load-bearing premise
The human-verified labels correctly identify which claims are replicable in practice and the chosen examples represent the range of social and behavioral science research.
What would settle it
An experiment in which the tested agents successfully retrieve new external datasets for non-replicable claims and correctly conclude that replication fails, using only the benchmark's provided tools.
Figures



















read the original abstract
The literature has witnessed an emerging interest in AI agents for automated assessment of scientific papers. Existing benchmarks focus primarily on the computational aspect of this task, testing agents' ability to reproduce or replicate research outcomes when having access to the code and data. This setting, while foundational, (1) fails to capture the inconsistent availability of new data for replication as opposed to reproduction, and (2) lacks ground-truth diversity by focusing only on reproducible papers, thereby failing to evaluate an agent's ability to identify non-replicable research. Furthermore, most benchmarks only evaluate outcomes rather than the replication process. In response, we introduce ReplicatorBench, an end-to-end benchmark, including human-verified replicable and non-replicable research claims in social and behavioral sciences for evaluating AI agents in research replication across three stages: (1) extraction and retrieval of replication data; (2) design and execution of computational experiments; and (3) interpretation of results, allowing a test of AI agents' capability to mimic the activities of human replicators in real world. To set a baseline of AI agents' capability, we develop ReplicatorAgent, an agentic framework equipped with necessary tools, like web search and iterative interaction with sandboxed environments, to accomplish tasks in ReplicatorBench. We evaluate ReplicatorAgent across four underlying large language models (LLMs), as well as different design choices of programming language and levels of code access. Our findings reveal that while current LLM agents are capable of effectively designing and executing computational experiments, they struggle with retrieving resources, such as new data, necessary to replicate a claim. All code and data are publicly available at https://github.com/CenterForOpenScience/llm-benchmarking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ReplicatorBench, an end-to-end benchmark for LLM agents performing research replication in social and behavioral sciences. It supplies human-verified replicable and non-replicable claims and structures evaluation across three stages—resource extraction and retrieval, computational experiment design and execution, and result interpretation—while releasing ReplicatorAgent as a baseline agent equipped with web-search and sandbox tools. Experiments across four LLMs, programming languages, and code-access levels show agents succeed at design/execution but fail at retrieving new data needed for replication.
Significance. If the ground-truth labels are robust, the work supplies a more realistic testbed than prior reproduction-only benchmarks by including non-replicable claims and retrieval demands that mirror real-world replication. Public release of code, data, and the agent framework enables direct follow-on research and provides concrete comparative data on current LLM limitations.
major comments (1)
- [Human-verification section (methods)] Human-verification section (methods): the central performance differential—strong design/execution, weak retrieval—rests on the assumption that human labels correctly isolate retrieval difficulty as the decisive barrier. The manuscript states that claims were human-verified but supplies no protocol, inter-rater reliability statistics, or explicit criteria for attributing non-replicability to missing resources versus statistical, design, or ethical factors. Without this documentation the reported gap cannot be confidently attributed to agent capability rather than benchmark construction.
minor comments (2)
- [Abstract] Abstract: the claim that the benchmark captures 'inconsistent availability of new data' would be strengthened by a single sentence summarizing the verification protocol.
- [Evaluation tables] Evaluation tables: report the exact number of replicable versus non-replicable claims and their distribution across fields to allow readers to assess whether the retrieval-failure result generalizes or is driven by a narrow subset of tasks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human experts can accurately and consistently label research claims as replicable or non-replicable based on available materials.
Forward citations
Cited by 1 Pith paper
-
ARA: Agentic Reproducibility Assessment For Scalable Support Of Scientific Peer-Review
ARA extracts workflow graphs from papers and scores reproducibility, reaching 61% accuracy on 213 ReScience C articles and outperforming priors on ReproBench and GoldStandardDB.
Reference graph
Works this paper leans on
-
[1]
Nazanin Alipourfard, Beatrix Arendt, Daniel M Benjamin, Noam Benkler, Michael Bishop, Mark Burstein, Martin Bush, James Caverlee, Yiling Chen, Chae Clark, et al. 2021. Systematizing confidence in open research and evidence (SCORE). SocArXiv(2021)
work page 2021
-
[2]
2024.Mass Reproducibility and Replicability: A New Hope
Abel Brodeur, Derek Mikola, Nikolai Cook, Thomas Brailey, Ryan Briggs, Alexan- dra de Gendre, Yannick Dupraz, Lenka Fiala, Jacopo Gabani, Romain Gauriot, et al. 2024.Mass Reproducibility and Replicability: A New Hope. Technical Report. The Institute for Replication (I4R)
work page 2024
-
[3]
Colin F Camerer, Anna Dreber, Eskil Forsell, Teck-Hua Ho, Jürgen Huber, Magnus Johannesson, Michael Kirchler, Johan Almenberg, Adam Altmejd, Taizan Chan, et al. 2016. Evaluating replicability of laboratory experiments in economics. Science351, 6280 (2016), 1433–1436
work page 2016
-
[4]
Open Science Collaboration. 2015. Estimating the reproducibil- ity of psychological science.Science349, 6251 (2015), aac4716. arXiv:https://www.science.org/doi/pdf/10.1126/science.aac4716 doi:10.1126/ science.aac4716
-
[5]
Engineering, Medicine and National Academies of Sciences, Engineering, and Medicine and others. 2019. Reproducibility and replicability in science. (2019)
work page 2019
-
[6]
Chuxuan Hu, Liyun Zhang, Yeji Lim, Aum Wadhwani, Austin Peters, and Daniel Kang. 2025. REPRO-BENCH: Can Agentic AI Systems Assess the Reproducibility of Social Science Research?. InFindings of the Association for Computational Linguistics: ACL 2025. 23616–23626
work page 2025
- [7]
-
[8]
Chin-Yew Lin. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. InText Summarization Branches Out. Association for Computational Linguistics, Barcelona, Spain, 74–81. https://aclanthology.org/W04-1013/
work page 2004
- [9]
-
[10]
Bodhisattwa Prasad Majumder, Harshit Surana, Dhruv Agarwal, Bhavana Dalvi Mishra, Abhijeetsingh Meena, Aryan Prakhar, Tirth Vora, Tushar Khot, Ashish Sabharwal, and Peter Clark. 2024. Discoverybench: Towards data-driven discov- ery with large language models.arXiv preprint arXiv:2407.01725(2024)
-
[11]
Brian A Nosek and Timothy M Errington. 2020. What is replication?PLoS biology 18, 3 (2020), e3000691
work page 2020
-
[12]
Shuo Ren, Pu Jian, Zhenjiang Ren, Chunlin Leng, Can Xie, and Jiajun Zhang
-
[13]
arXiv preprint arXiv:2503.24047(2025)
Towards scientific intelligence: A survey of llm-based scientific agents. arXiv preprint arXiv:2503.24047(2025)
- [14]
-
[15]
Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, et al. 2025. PaperBench: Evaluating AI’s Ability to Replicate AI Research.arXiv preprint arXiv:2504.01848(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Minyang Tian, Luyu Gao, Shizhuo Zhang, Xinan Chen, Cunwei Fan, Xuefei Guo, Roland Haas, Pan Ji, Kittithat Krongchon, Yao Li, et al . 2024. Scicode: A research coding benchmark curated by scientists.Advances in Neural Information Processing Systems37 (2024), 30624–30650
work page 2024
-
[17]
Lukas Twist, Jie M Zhang, Mark Harman, Don Syme, Joost Noppen, and Detlef Nauck. 2025. LLMs Love Python: A Study of LLMs’ Bias for Programming Languages and Libraries.arXiv preprint arXiv:2503.17181(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. 2024. Executable code actions elicit better llm agents. InForty-first International Conference on Machine Learning
work page 2024
-
[19]
Emily C Willroth and Olivia E Atherton. 2024. Best laid plans: A guide to reporting preregistration deviations.Advances in Methods and Practices in Psychological Science7, 1 (2024), 25152459231213802
work page 2024
- [20]
- [21]
-
[22]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. [n. d.]. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations
- [23]
-
[24]
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. 2019. Bertscore: Evaluating text generation with bert.arXiv preprint arXiv:1904.09675(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[25]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems36 (2023), 46595–46623. A Comparisons of automated replication/reproduction benchmarks Table 4 comparesReplica...
work page 2023
-
[26]
and BERTScore [23]. According to table. 6, LLMEval has the highest alignment with human judgement of semantic matching be- tween the agent-produced post-registration and expert-annotated post-registration. Thus, we adopted LLMEval with GPT-4o as the main automated evaluation mechanism. C.2 Evaluation prompts and templates For evaluation of the extraction,...
work page 2024
-
[29]
There may also be useful code to help you with the replication
[...]/replication_data: The folder containing the data that can potentially be used for the replication. There may also be useful code to help you with the replication. But if not, you have to generate the replication code yourself in Python. You are given the following information about the replication attempt. 1.[...]/post_registration.json: A structure...
-
[30]
Focus on the logs of the design and the execute stage for this evaluation
[...]/_log/: Folder contain the logs of the agent replication attempt. Focus on the logs of the design and the execute stage for this evaluation
-
[31]
[...]/replication_info.json: Final structured report of the design stage by the agent
-
[32]
[...]/execution_results.json: Final strcuterd report of the execution stage by the agent. Your task is to score the replication attempt by filling out this structured rubric === START OF EVALUATION RUBRIC TO BE FILLED OUT === {schema for execution checkpoints} === END OF EVALUAIION RUBRIC TO BE FILLED OUT === For each leaf node in the rubric assign a scor...
-
[33]
A JSON template where each key contains a description of what is expected
-
[34]
The original paper manuscript (original_paper.pdf)
-
[35]
Initial details file (initial_details_easy.txt) containing: - Claim statement (use this directly, do not extract from paper) - Hypotheses (use these directly, do not extract from paper) Your goal is to: - For'claim.statement'field: Use the exact statement from initial_details_easy.txt - For'hypotheses'field: Use the exact list from initial_details_easy.tx...
-
[37]
[...]/initial_details.txt: Details about the claim from the original paper to be replicated
-
[39]
[...]/replication_data: The folder containing the data that can potentially be used for the replication. There may also be useful code to help you with the replication. But if not, you have to generate the replication code yourself in Python. Based on the provided documents, your goal is to plan for the replication study and fill out this JSON template: {...
-
[40]
Analyze the error message in the Observation
-
[41]
Use`write_file`to FIX the issue (e.g., rewrite`replication_info.json`to add packages, or rewrite the code files). Remember that write_file will overwrite any existing content in the provided file_path if existing. When you use the tool, the provided path file_path to the tool MUST be the study path given to you. But to access other files within the file_c...
-
[42]
RETRY the failed step. **Phases of Execution:** PHASE 1: BUILD ENVIRONMENT 1.`orchestrator_generate_dockerfile`: Creates _runtime/Dockerfile from replication_info.json. 2.`orchestrator_build_image`: Builds the image. * IF BUILD FAILS: Read the error log. It usually means a missing system package or R/Python library. Edit` replication_info.json`to add the ...
-
[43]
Ready to execute command: <COMMAND>. Approve? (yes/no)
Before running the actual analysis code, you MUST Ask the human: Action: ask_human_input: "Ready to execute command: <COMMAND>. Approve? (yes/no)" * If they say "no", stop the container and fill the output JSON with status "cancelled". * If they say "yes", proceed to Phase 4. PHASE 4: EXECUTE & DEBUG 6.`orchestrator_execute_entry`: Runs the code. * IF EXE...
-
[44]
Parse`execution_result.json`and output the Answer in the following required JSON schema. {Task schema for Generation-Execution Stage} Current Study Path: "{study_path}" Start by generating the Dockerfile. Remember, every response needs to have one of the following two formats: ----- FORMAT 1 (For when you need to call actions to help accomplish the given ...
-
[45]
[...]/original_paper.pdf: The pdf file containing the full text of the original paper
-
[46]
[...]/initial_details.txt: Details about the claim from the original paper to be replicated You are given the following information about the replication attempt
-
[47]
[...]/post_registration.json: A structured document with key extracted information about the original paper and the claim to be replicated
-
[48]
[...]/replication_info.json: Structured report of the agent at the PLANNING stage for the replication of the given claim
-
[49]
[...]/replication_data: The folder containing the data and code that were used for the replication, along with any output files generated after running the code. You MUST examine any additional execution result files not reported in execution_results.json before making your interpretataions
-
[50]
[...]/execution_results.json: Final structured report of the execution stage by the agent. If the report doesn' t have any results, look for output files generated by the code to find the execution results before making conclusions. Your task is to interpret the the replication results and fill out the following structured JSON report. === START OF INTERP...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.