FormulaCode: Evaluating Agentic Optimization on Large Codebases
Pith reviewed 2026-05-21 10:38 UTC · model grok-4.3
The pith
FormulaCode shows that frontier LLM agents still struggle to optimize entire real-world codebases under multiple performance goals at once.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FormulaCode comprises 957 performance bottlenecks mined from scientific Python repositories on GitHub, each paired with expert-authored patches and on average 264.6 community-maintained performance workloads per task, and evaluations on this benchmark reveal that repository-scale, multi-objective optimization remains a major challenge for frontier LLM agents.
What carries the argument
The FormulaCode benchmark of 957 mined bottlenecks, each supplied with expert patches and hundreds of community workloads for multi-objective scoring.
If this is right
- Agent designs must incorporate mechanisms that handle repository-wide changes while tracking multiple performance metrics simultaneously.
- Future benchmarks should move away from single-objective or synthetic tasks toward real mined workloads with expert reference solutions.
- Progress on agentic code optimization will require new methods for balancing correctness constraints against speed and resource goals at scale.
- Developers relying on agents for performance work will continue to need substantial human oversight on large codebases.
Where Pith is reading between the lines
- The benchmark could be extended to other languages or application domains by applying the same mining and workload collection process.
- Success on FormulaCode tasks might serve as a training signal for fine-tuning agents specifically on performance-tuning behavior.
- If agents improve here, the same evaluation approach could be reused to measure gains in related areas such as security hardening or memory reduction.
Load-bearing premise
The 957 mined bottlenecks, expert-authored patches, and average 264.6 community workloads per task accurately capture holistic optimization challenges under realistic correctness and performance constraints.
What would settle it
A frontier LLM agent that produces changes matching or exceeding the expert patches on correctness and performance metrics for a large majority of the 957 tasks across their respective community workloads would falsify the central claim.
Figures


























read the original abstract
Large language model (LLM) coding agents increasingly operate at the repository level, motivating benchmarks that evaluate their ability to optimize entire codebases under realistic constraints. Existing code benchmarks largely rely on synthetic tasks, binary correctness signals, or single-objective evaluation, limiting their ability to assess holistic optimization behavior. We introduce FormulaCode, a benchmark for evaluating agentic optimization on large, real-world codebases with fine-grained, multi-objective performance metrics. FormulaCode comprises 957 performance bottlenecks mined from scientific Python repositories on GitHub, each paired with expert-authored patches and, on average, 264.6 community-maintained performance workloads per task, enabling the holistic ability of LLM agents to optimize codebases under realistic correctness and performance constraints. Our evaluations reveal that repository-scale, multi-objective optimization remains a major challenge for frontier LLM agents. Project website at: https://formula-code.github.io
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FormulaCode, a benchmark for evaluating LLM coding agents on repository-scale optimization. It comprises 957 performance bottlenecks mined from scientific Python GitHub repositories, each paired with expert-authored patches and an average of 264.6 community-maintained performance workloads per task. The work evaluates frontier agents under multi-objective correctness and performance constraints and concludes that such optimization remains a major challenge.
Significance. If the benchmark tasks prove representative, this provides a valuable advance over synthetic or single-objective code benchmarks by grounding evaluation in real repositories, expert patches, and community workloads. The multi-objective framing and scale could help identify concrete limitations in current agentic systems and motivate more robust optimization techniques.
major comments (2)
- [§3] §3 (Benchmark Construction): The description of mining the 957 bottlenecks, validating expert patches (correctness tests plus measured speedup), and selecting the 264.6 workloads per task lacks explicit criteria, filtering rules, or statistical justification for representativeness. This is load-bearing for the central claim, as the reported agent failures only demonstrate a general challenge if the tasks are authentic proxies rather than biased toward easily detectable or low-impact cases.
- [§5] §5 (Evaluations): The manuscript does not report the number of independent runs, error bars, statistical significance tests, or the precise aggregation method for multi-objective scores (e.g., how correctness, speedup, and other metrics are combined). Without these, it is difficult to verify that the data robustly supports the conclusion that repository-scale optimization is a major challenge for frontier agents.
minor comments (2)
- [Introduction] The abstract and introduction should include a brief comparison table or explicit discussion of how FormulaCode differs from related benchmarks such as SWE-bench in terms of objectives and scale.
- [Results] Figure captions and axis labels in the results section could be clarified to indicate whether reported metrics are averages across workloads or per-bottleneck aggregates.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. The comments highlight important aspects of benchmark construction and evaluation reporting that we will address in revision. We respond to each major comment below.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The description of mining the 957 bottlenecks, validating expert patches (correctness tests plus measured speedup), and selecting the 264.6 workloads per task lacks explicit criteria, filtering rules, or statistical justification for representativeness. This is load-bearing for the central claim, as the reported agent failures only demonstrate a general challenge if the tasks are authentic proxies rather than biased toward easily detectable or low-impact cases.
Authors: We agree that the current description in §3 would benefit from greater explicitness. In the revised manuscript we will add a new subsection that specifies the exact mining criteria (performance bottlenecks identified via profiling with measurable speedup potential and at least one community workload), the filtering rules applied (e.g., exclusion of tasks without reproducible correctness tests or with <5% potential improvement), the patch validation protocol (unit-test passage plus measured wall-clock speedup on held-out workloads), and statistical justification for representativeness (distribution of repository sizes, scientific domains, and performance-impact quantiles across the 957 tasks). These additions will clarify that the tasks constitute authentic proxies rather than a biased subset. revision: yes
-
Referee: [§5] §5 (Evaluations): The manuscript does not report the number of independent runs, error bars, statistical significance tests, or the precise aggregation method for multi-objective scores (e.g., how correctness, speedup, and other metrics are combined). Without these, it is difficult to verify that the data robustly supports the conclusion that repository-scale optimization is a major challenge for frontier agents.
Authors: We acknowledge that these methodological details were omitted. In the revised §5 we will report the exact number of independent runs per agent-task pair, include error bars on all figures and tables, describe the statistical tests performed (e.g., Wilcoxon signed-rank tests with Bonferroni correction for pairwise agent comparisons), and provide the precise multi-objective aggregation formula (a weighted combination of correctness rate and geometric-mean speedup, with sensitivity analysis to alternative weightings). These changes will allow readers to assess the robustness of the reported challenge. revision: yes
Circularity Check
No circularity: benchmark paper with external grounding and no derivations or self-referential predictions
full rationale
The paper introduces FormulaCode, a benchmark of 957 bottlenecks mined from GitHub scientific Python repositories, paired with expert patches and community workloads (average 264.6 per task). The central claim—that repository-scale multi-objective optimization remains a major challenge—is an empirical observation from agent evaluations on these externally sourced tasks. No equations, fitted parameters, predictions, uniqueness theorems, or self-citations are described that would reduce any result to the inputs by construction. The work is self-contained as a benchmark introduction relying on independent GitHub data and community contributions rather than internal definitions or load-bearing self-references.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mined performance bottlenecks from GitHub scientific Python repositories, paired with expert patches and community workloads, constitute a valid test of holistic agentic optimization.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
FormulaCode comprises 957 performance bottlenecks mined from scientific Python repositories... each paired with expert-authored patches and, on average, 264.6 community-maintained performance workloads
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
overall speedup is the geometric mean... Stratified Advantage... Normalized Advantage
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Kung, Geert Janssen, Wei Zhang, Giacomo Domeniconi, Vladimir Zolotov, and et al
URLhttps://arxiv.org/abs/2105.12655. Romera-Paredes, B., Barekatain, M., Novikov, A., Balog, M., Kumar, M. P., Dupont, E., Ruiz, F. J., Ellenberg, J. S., Wang, P., Fawzi, O., et al. Mathematical discoveries from program search with large language models.Nature, 625 (7995):468–475, 2024. Sasnauskas, R., Chen, Y ., Collingbourne, P., Ketema, J., Lup, G., Ta...
-
[2]
ISSN 01761714, 1432217X. URL http://www. jstor.org/stable/41105866. Tratt, L. Four kinds of optimisation, November 2023. URL https://tratt.net/laurie/blog/2023/four_ kinds_of_optimisation.html. Tratt, L. The fifth kind of optimisation, April
-
[3]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
URL https://tratt.net/laurie/blog/2025/ the_fifth_kind_of_optimisation.html. Waghjale, S., Veerendranath, V ., Wang, Z., and Fried, D. ECCO: Can we improve model-generated code efficiency without sacrificing functional correctness? In Al-Onaizan, Y ., Bansal, M., and Chen, Y .-N. (eds.),Proceedings of the 2024 Conference on Empirical Methods in Natural La...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.emnlp-main.859 2025
-
[4]
GPT-5.GPT-5 (Singh et al., 2025) is OpenAI’s flagship general-purpose model in this study, and we use the standard API configuration with built-in “thinking” enabled. It is a multimodal, tool-using model with strong performance on code, math, and long-context reasoning benchmarks, and is widely deployed in agentic coding systems. We use the gpt-5-2025-08-...
work page 2025
-
[5]
Claude 4.0 Sonnet.Claude 4.0 Sonnet (Anthropic, 2025) is Anthropic’s top-end general-purpose model at the time of 27 Task Metadata Docker script library
work page 2025
-
[6]
Generate Script with LLM Agent Reasoning Module Docker script Error log Previous attempt log
-
[7]
Sample chronologically adjacent scripts. Verifier Successful build unsuccessful build Docker script Docker script Figure 14: Overview of the pipeline for Docker environment synthesis. The system reuses chronologically adjacent build scripts when possible, otherwise invoking an LLM agent that generates and refines Docker scripts using build logs and reposit...
work page 2025
-
[8]
Gemini 2.5 Pro.Gemini 2.5 Pro (Comanici et al., 2025) is Google DeepMind’s latest high-end model at the time of writing, introduced as the first member of the Gemini 2 series and optimized for complex multimodal reasoning. It offers a very large context window (up to 1M tokens in the preview configuration) and supports advanced tool-calling and code execu...
work page 2025
-
[9]
Qwen 3 Coder.Qwen 3 Coder is a large open Mixture-of-Experts model explicitly optimized for agentic coding tasks rather than general conversation. Qwen 3 Coder (in particular, the qwen3-coder-480b-a35b-instruct model) combines 480 B total parameters with sparse expert activation (35 B active parameters per forward pass) and a context window of roughly 262...
work page 2025
-
[10]
Terminus 2.Terminus 2 is a reference agent for Terminal-Bench (Merrill et al., 2026). It is intentionally minimal: the agent spawns a single tmux session and exposes the raw shell to the model, which issues commands as plain text and receives the terminal output verbatim, without additional structured tools or high-level abstractions. This architecture ca...
work page 2026
-
[11]
""Get an empty query compiler for the default backend
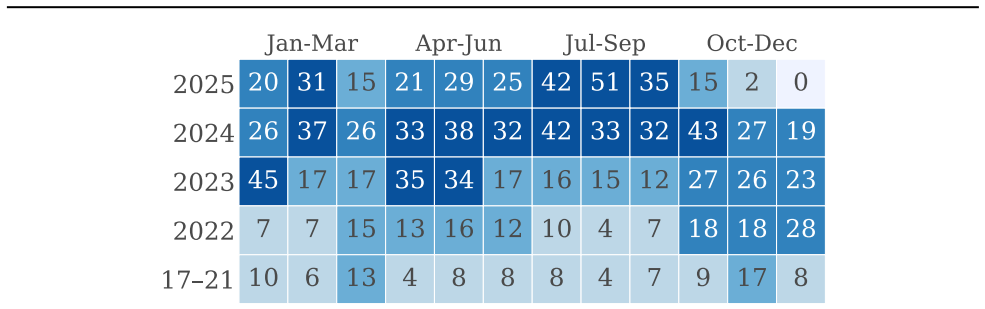
OpenHands.OpenHands is a widely used open-source framework for AI-driven software development (Wang et al., 28 Jan-Mar Apr-Jun Jul-Sep Oct-Dec 2025 2024 2023 2022 17 21 20 31 15 21 29 25 42 51 35 15 2 0 26 37 26 33 38 32 42 33 32 43 27 19 45 17 17 35 34 17 16 15 12 27 26 23 7 7 15 13 16 12 10 4 7 18 18 28 10 6 13 4 8 8 8 4 7 9 17 8 Figure 15: Timeline of ...
work page 2025
-
[12]
as described in §A.1.2. We also showcase the number of tasks, the date of creation of the latest task, and additional information about the functionality and popularity of the repository. Most repositories are software tools used extensively within scientific communities. Repository Name #Stars #Forks Filter Stage 1 Filter Stage 2 Latest Task Date Description
-
[13]
scikit-learn/scikit-learn 63792 26359 2434 243 2025-10-31 scikit-learn: machine learning in Python
work page 2025
-
[14]
pandas-dev/pandas 46922 19184 3298 560 2025-11-11 Flexible and powerful data analysis / manipulation library for Python, provid- ing labeled data structures similar to R data.frame objects, statistical functions, and much more
work page 2025
-
[15]
scipy/scipy 14120 5516 1454 209 2025-10-29 SciPy library main repository
work page 2025
-
[16]
apache/arrow 16089 3884 1988 267 2025-07-22 Apache Arrow is the universal columnar format and multi-language toolbox for fast data interchange and in-memory analytics
work page 1988
-
[17]
networkx/networkx 16277 3415 288 44 2025-09-16 NetworkX is a Python package for the creation, manipulation, and study of the structure, dynamics, and functions of complex networks
work page 2025
-
[18]
Qiskit/qiskit 6598 2659 717 212 2025-11-19 Qiskit is an open-source SDK for work- ing with quantum computers at the level of pulses, circuits, and application mod- ules
work page 2025
-
[19]
scikit-image/scikit-image 6371 2320 458 54 2025-11-18 Image processing in Python
work page 2025
-
[20]
pymc-devs/pymc 9322 2146 685 45 2025-09-23 PyMC (formerly PyMC3) is a Python package for Bayesian statistical model- ing focusing on advanced Markov chain Monte Carlo (MCMC) and variational inference (VI) algorithms
work page 2025
-
[21]
Textualize/rich 54172 1920 165 11 2025-07-25 Rich is a Python library for rich text and beautiful formatting in the terminal
work page 1920
-
[22]
tqdm/tqdm 30580 1402 12 1 2022-03-24 Fast, extensible progress bar for Python and CLI
work page 2022
-
[23]
pydata/xarray 4004 1192 609 101 2025-11-21 N-D labeled arrays and datasets in Python
work page 2025
-
[24]
optuna/optuna 12922 1177 719 112 2025-11-05 A hyperparameter optimization frame- work
work page 2025
-
[25]
quantumlib/Cirq 4772 1151 10 3 2025-11-18 Python framework for creating, editing, and invoking Noisy Intermediate-Scale Quantum (NISQ) circuits
work page 2025
-
[26]
pvlib/pvlib-python 1424 1126 110 8 2025-10-03 A set of documented functions for sim- ulating the performance of photovoltaic energy systems
work page 2025
-
[27]
ipython/ipyparallel 2626 1006 65 6 2024-10-28 IPython Parallel: Interactive Parallel Computing in Python
work page 2024
-
[28]
geopandas/geopandas 4940 981 314 22 2025-05-22 Python tools for geographic data Continued on next page 40 Repository Name #Stars #Forks Filter Stage 1 Filter Stage 2 Latest Task Date Description
work page 2025
-
[29]
kedro-org/kedro 10593 971 41 4 2025-07-17 Kedro is a toolbox for production-ready data science. It uses software engineer- ing best practices to help you create data engineering and data science pipelines that are reproducible, maintainable, and modular
work page 2025
-
[30]
HIPS/autograd 7379 928 13 1 2017-10-21 Efficiently computes derivatives of NumPy code
work page 2017
-
[31]
MDAnalysis/mdanalysis 1477 733 196 23 2025-10-13 MDAnalysis is a Python library to ana- lyze molecular dynamics simulations
work page 2025
-
[32]
pybamm-team/PyBaMM 1387 692 218 17 2025-04-29 PyBaMM (Python Battery Mathemati- cal Modelling) is an open-source battery simulation package written in Python
work page 2025
-
[33]
modin-project/modin 10332 669 50 8 2025-09-30 Speed up your Pandas workflows by changing a single line of code
work page 2025
-
[34]
nilearn/nilearn 1322 631 138 2 2025-10-09 Machine learning for NeuroImaging in Python
work page 2025
-
[35]
sunpy/sunpy 971 626 663 22 2025-05-16 sunpy is a Python software package that provides fundamental tools for accessing, loading and interacting with solar physics data in Python
work page 2025
-
[36]
shapely/shapely 4284 600 150 21 2025-05-03 Manipulation and analysis of geometric objects
work page 2025
-
[37]
dedupeio/dedupe 4387 568 25 4 2023-12-19 A python library for accurate and scal- able data deduplication and entity- resolution
work page 2023
-
[38]
h5py/h5py 2174 547 263 35 2025-08-10 h5py is a thin, pythonic wrapper around HDF5
work page 2025
-
[39]
PyWavelets/pywt 2294 517 12 1 2024-07-16 PyWavelets - Wavelet Transforms in Python
work page 2024
-
[40]
pydicom/pydicom 2070 508 86 7 2025-05-12 Read, modify and write DICOM files with python code
work page 2070
-
[41]
arviz-devs/arviz 1737 458 107 5 2025-10-21 Exploratory analysis of Bayesian mod- els
work page 2025
-
[42]
napari/napari 2512 454 849 69 2025-09-30 napari: a fast, interactive, multi- dimensional image viewer for python
work page 2025
-
[43]
tardis-sn/tardis 225 446 268 13 2025-09-16 TARDIS - Temperature And Radiative Diffusion In Supernovae
work page 2025
-
[44]
dipy/dipy 787 446 194 16 2025-11-18 DIPY is the paragon 3D/4D+ medical imaging library in Python. Contains generic methods for spatial normal- ization, signal processing, machine learning, statistical analysis and visual- ization of medical images. Additionally, it contains specialized methods for com- putational anatomy including diffusion, perfusion and...
work page 2025
-
[45]
python-control/python- control 1908 444 117 6 2025-06-21 The Python Control Systems Library is a Python module that implements basic operations for analysis and design of feedback control systems
work page 1908
-
[46]
SciTools/cartopy 1545 389 74 6 2025-04-26 Cartopy is a Python package designed for geospatial data processing in order to produce maps and other geospatial data analyses
work page 2025
-
[47]
holoviz/datashader 3467 377 90 19 2025-10-09 Quickly and accurately render even the largest data
work page 2025
-
[48]
microsoft/Qcodes 396 335 187 10 2025-09-05 Modular data acquisition framework
work page 2025
-
[49]
mars-project/mars 2748 326 164 51 2023-02-16 Mars is a tensor-based unified frame- work for large-scale data computation which scales numpy, pandas, scikit- learn and Python functions
work page 2023
-
[50]
pytroll/satpy 1146 320 520 45 2025-08-02 Python package for reading, manipulat- ing and writing satellite data
work page 2025
-
[51]
SciTools/iris 692 297 109 23 2025-10-31 A powerful, format-agnostic, and community-driven Python package for analysing and visualising Earth science data
work page 2025
-
[52]
lmfit/lmfit-py 1164 290 205 8 2022-09-05 Non-Linear Least Squares Minimiza- tion, with flexible Parameter settings, based on scipy.optimize, and with many additional classes and methods for curve fitting
work page 2022
-
[53]
deepchecks/deepchecks 3924 286 99 9 2023-12-06 Deepchecks: Tests for Continuous Validation of ML Models & Data. Deepchecks is a holistic open-source solution for all of your AI & ML valida- tion needs, enabling to thoroughly test your data and models from research to production
work page 2023
-
[54]
devitocodes/devito 632 242 99 7 2025-07-24 DSL and compiler framework for au- tomated finite-differences and stencil computation
work page 2025
-
[55]
danielgtaylor/python- betterproto 1733 233 42 1 2023-12-07 Better Protobuf / gRPC code generator and library for Python
work page 2023
-
[56]
scikit-learn-contrib/metric- learn 1425 229 6 1 2017-11-27 Metric Learning in Python
work page 2017
-
[57]
pydicom/pynetdicom 551 188 24 1 2025-05-24 A Python implementation of the DI- COM networking protocol
work page 2025
-
[58]
scverse/anndata 667 175 142 17 2025-07-23 Annotated data matrix for single-cell genomics
work page 2025
-
[59]
apache/arrow-adbc 498 160 571 63 2025-11-07 Database connectivity API standard and libraries for Apache Arrow
work page 2025
-
[60]
man-group/ArcticDB 2102 153 11 2 2025-11-19 ArcticDB is a high performance data store for time series and tick data
work page 2025
-
[61]
stac-utils/pystac 412 127 48 1 2023-03-31 Python library for working with Spa- tioTemporal Asset Catalog (STAC) Continued on next page 42 Repository Name #Stars #Forks Filter Stage 1 Filter Stage 2 Latest Task Date Description
work page 2023
-
[62]
xdslproject/xdsl 433 125 2136 236 2025-11-04 A Python compiler design toolkit
work page 2025
-
[63]
ActivitySim/activitysim 217 117 51 10 2025-11-12 An open platform for activity-based travel behavior modeling
work page 2025
-
[64]
OGGM/oggm 245 115 484 36 2025-04-01 Open Global Glacier Model (OGGM): a modular framework for glacier model- ing
work page 2025
-
[65]
datalad/datalad 613 115 426 31 2024-09-10 Keep code, data, containers under con- trol with git and git-annex
work page 2024
-
[66]
pydata/bottleneck 1144 112 61 20 2025-04-29 Fast NumPy array functions written in C
work page 2025
-
[67]
wmayner/pyphi 406 100 25 1 2024-09-24 A toolbox for integrated information theory
work page 2024
-
[68]
django-components/ django-components 1463 100 53 3 2025-09-30 Reusable, composable components for Django templates
work page 2025
-
[69]
sourmash-bio/sourmash 524 88 297 27 2025-01-09 Quickly search, compare, and analyze genomic and metagenomic data sets
work page 2025
-
[70]
tskit-dev/msprime 201 88 209 9 2025-07-24 Simulate genealogical trees and ge- nomic sequence data using population genetic models
work page 2025
-
[71]
numpy/numpy-financial 384 87 13 4 2024-04-04 Financial functions for NumPy
work page 2024
-
[72]
makepath/xarray-spatial 894 85 38 9 2023-02-16 Spatial analysis algorithms for xarray implemented in numba
work page 2023
-
[73]
dwavesystems/dimod 135 84 152 20 2024-06-13 dimod is a shared API for samplers
work page 2024
-
[74]
python-hyper/h11 530 83 18 2 2025-01-12 A pure-Python, bring-your-own-I/O implementation of HTTP/1.1
work page 2025
-
[75]
bjodah/chempy 611 81 69 1 2018-03-24 A package useful for chemistry written in Python
work page 2018
-
[76]
holoviz/param 497 79 85 10 2025-02-27 Declarative parameters for robust Python classes and a rich API for re- active programming
work page 2025
-
[77]
inducer/loopy 615 78 172 15 2023-07-27 A code generator for array computations on CPUs and GPUs
work page 2023
-
[78]
holgern/beem 138 75 75 5 2020-12-22 A Python library for Hive and Steem
work page 2020
-
[79]
scverse/spatialdata 329 75 20 2 2025-09-29 An open and interoperable data frame- work for spatial omics data
work page 2025
-
[80]
pysb/pysb 188 71 107 7 2021-01-20 PySB is a framework for building math- ematical models of biochemical systems as Python programs
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.