LightZeroNav: Zero-Shot Vision Language Navigation in Continuous Environments Based on Lightweight VLMs
Pith reviewed 2026-05-21 10:38 UTC · model grok-4.3
The pith
Lightweight open-source vision-language models can match much larger models at zero-shot navigation in continuous spaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By adding information filtering, progress estimation from textual memory, and action-stage separation to a lightweight VLM, LightZeroNav overcomes the limited reasoning capacity of small models and delivers competitive zero-shot performance in continuous VLN-CE tasks using only RGB observations, without any training, graph search, or waypoint predictors.
What carries the argument
The three proposed modules (information filtering to cut redundancy, progress estimation from textual memory, and action-stage separation to avoid task entanglement) that adapt a lightweight VLM for long-horizon continuous navigation.
If this is right
- Navigation agents become deployable on devices with limited compute since no large model or pre-built map is required.
- Zero-shot adaptation to new continuous environments works without retraining or additional supervision.
- Task success depends more on structured prompting and module design than on raw model scale.
- RGB-only input suffices for reliable long-horizon planning when memory and stage handling are cleaned up.
Where Pith is reading between the lines
- The same module pattern could be tested on other embodied tasks such as object rearrangement or multi-room search where long sequences matter.
- Replacing the Qwen3-VL backbone with other open 7-9B VLMs would show whether the gains are model-specific or general.
- Adding a simple geometric consistency check between consecutive RGB frames might further reduce drift without adding heavy computation.
Load-bearing premise
The three modules together are enough to compensate for the limited reasoning ability of lightweight VLMs during long-horizon navigation.
What would settle it
A side-by-side test on the same VLN-CE benchmarks showing that the full LightZeroNav system loses its performance edge when any one of the three modules is removed.
Figures



read the original abstract
Although vision-language navigation (VLN) has progressed rapidly, zero-shot VLN in continuous environments (VLN-CE) remains highly challenging when using lightweight vision-language models (VLMs), whose limited reasoning capacity makes long-horizon navigation unreliable. In this paper, we propose LightZeroNav to tackle the three major bottlenecks when using lightweight VLMs in zero-shot VLN-CE,i.e.,information redundancy from multi-source inputs, inaccurate progress estimation caused by noisy textual memory, and task entanglement between action execution and stage transition. Using only RGB observations and a lightweight open-source Qwen3-VL-8B backbone, LightZeroNav achieves competitive performance with GPT-4o (~200B) without task-specific training, graph search, or waypoint predictors, demonstrating its effectiveness in zero-shot VLN-CE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LightZeroNav, a modular pipeline for zero-shot vision-language navigation in continuous environments (VLN-CE) that relies solely on RGB observations and a lightweight open-source Qwen3-VL-8B backbone. It identifies three bottlenecks—informaton redundancy from multi-source inputs, inaccurate progress estimation from noisy textual memory, and task entanglement between action execution and stage transition—and introduces three corresponding modules (information filtering, progress estimation from textual memory, and action-stage separation) to address them. The central claim is that this approach achieves competitive performance with GPT-4o (~200B parameters) without task-specific training, graph search, or waypoint predictors.
Significance. If the empirical claims hold, the result would be significant for practical deployment of VLN systems, as it shows that lightweight open-source VLMs can close much of the performance gap to frontier models in long-horizon continuous navigation while avoiding heavy infrastructure such as graphs or waypoint predictors.
major comments (2)
- [Abstract] Abstract: the claim of competitive performance with GPT-4o is stated without any quantitative metrics, ablation results, or error analysis. This absence prevents verification that the three modules actually deliver the stated gains or close the reasoning gap for an 8B model in long-horizon VLN-CE.
- [Methods] Methods / proposed modules: the assertion that information filtering, textual-memory progress estimation, and action-stage separation together suffice to overcome the limited chain-of-thought depth and spatial precision of Qwen3-VL-8B is presented as the direct solution, yet no concrete evidence (e.g., ablation tables or failure-case analysis) is referenced to show that these modules prevent localization drift or compounding low-level action errors in continuous space.
minor comments (2)
- Clarify the exact prompting templates and memory-update rules used for the textual progress estimator, as these details are load-bearing for reproducibility.
- Add a limitations section that explicitly discusses failure modes when the lightweight VLM produces inconsistent stage transitions or hallucinates progress.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment point by point below, indicating where revisions will be made to improve clarity and substantiation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of competitive performance with GPT-4o is stated without any quantitative metrics, ablation results, or error analysis. This absence prevents verification that the three modules actually deliver the stated gains or close the reasoning gap for an 8B model in long-horizon VLN-CE.
Authors: We agree that the abstract would benefit from explicit quantitative support. In the revised version, we will incorporate key metrics (e.g., success rate and SPL on the VLN-CE benchmark) directly into the abstract, along with a brief reference to the ablation studies showing the contribution of each module. This will allow readers to immediately verify the performance claims relative to GPT-4o. revision: yes
-
Referee: [Methods] Methods / proposed modules: the assertion that information filtering, textual-memory progress estimation, and action-stage separation together suffice to overcome the limited chain-of-thought depth and spatial precision of Qwen3-VL-8B is presented as the direct solution, yet no concrete evidence (e.g., ablation tables or failure-case analysis) is referenced to show that these modules prevent localization drift or compounding low-level action errors in continuous space.
Authors: The experimental section of the manuscript already presents comparative results and module-wise ablations demonstrating reduced drift and error accumulation. To address the concern directly, we will add explicit cross-references from the methods description to the relevant ablation tables and introduce a dedicated failure-case analysis subsection that illustrates how each module mitigates the specific limitations of the 8B VLM in continuous navigation. revision: partial
Circularity Check
No circularity: empirical modules evaluated against external benchmarks
full rationale
The paper's core contribution consists of three heuristic modules (information filtering, textual-memory progress estimation, action-stage separation) applied to a fixed open-source 8B VLM backbone. Performance is reported via direct comparison to GPT-4o on standard VLN-CE metrics without any parameter fitting that re-uses the same data as a 'prediction,' without equations that define outputs in terms of themselves, and without load-bearing self-citations that close the argument. The derivation chain therefore remains open to external falsification and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Lightweight VLMs can perform the decomposed subtasks of filtering, memory-based progress estimation, and action-stage separation when given appropriate prompts.
invented entities (1)
-
LightZeroNav modular pipeline
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
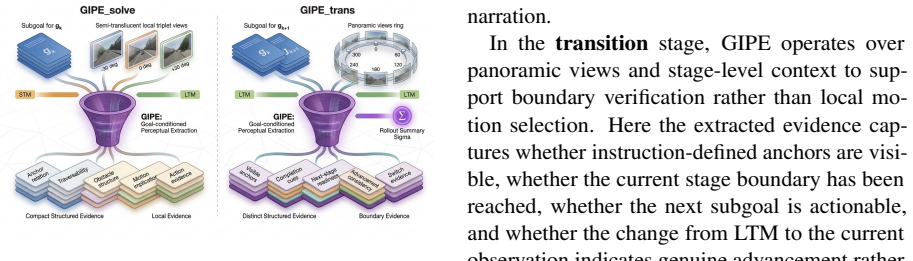
We propose EmergeNav, a zero-shot framework that formulates continuous VLN as structured embodied inference... Plan–Solve–Transition hierarchy... GIPE... contrastive dual-memory reasoning... role-separated Dual-FOV sensing
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
EmergeNav achieves 30.00 SR with Qwen3-VL-8B... without task-specific training, graph search, or waypoint predictors
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko Sünderhauf, Ian Reid, Stephen Gould, and Anton Van Den Hengel. Vision-and- language navigation: Interpreting visually-grounded navigation instructions in real environments. InPro- ceedings of the IEEE conference on computer vision and pattern recognition, pages 3674–3683, 2018
work page 2018
-
[2]
Habitat: A platform for embodied ai research
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al. Habitat: A platform for embodied ai research. InProceedings of the IEEE/CVF international con- ference on computer vision, pages 9339–9347, 2019
work page 2019
-
[3]
Beyond the nav-graph: Vision-and-language navigation in continuous envi- ronments
Jacob Krantz, Erik Wijmans, Arjun Majumdar, Dhruv Batra, and Stefan Lee. Beyond the nav-graph: Vision-and-language navigation in continuous envi- ronments. InEuropean Conference on Computer Vision, pages 104–120. Springer, 2020
work page 2020
-
[4]
Yanyuan Qiao, Wenqi Lyu, Hui Wang, Zixu Wang, Zerui Li, Yuan Zhang, Mingkui Tan, and Qi Wu. Open-nav: Exploring zero-shot vision-and-language navigation in continuous environment with open- source llms. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 6710–
-
[5]
Xiangyu Shi, Zerui Li, Wenqi Lyu, Jiatong Xia, Feras Dayoub, Yanyuan Qiao, and Qi Wu. Smart- way: Enhanced waypoint prediction and backtrack- ing for zero-shot vision-and-language navigation. In 2025 IEEE/RSJ International Conference on Intelli- gent Robots and Systems (IROS), pages 16923–16930. IEEE, 2025
work page 2025
-
[6]
Xiangyu Shi, Zerui Li, Yanyuan Qiao, and Qi Wu. Fast-smartway: Panoramic-free end-to-end zero- shot vision-and-language navigation.arXiv preprint arXiv:2511.00933, 2025
-
[7]
Kehan Chen, Dong An, Yan Huang, Rongtao Xu, Yifei Su, Yonggen Ling, Ian Reid, and Liang Wang. Constraint-aware zero-shot vision-language naviga- tion in continuous environments.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[8]
Yunheng Wang, Yuetong Fang, Taowen Wang, Yixiao Feng, Yawen Tan, Shuning Zhang, Peiran Liu, Yiding Ji, and Renjing Xu. Dreamnav: A trajectory-based imaginative framework for zero- shot vision-and-language navigation.arXiv preprint arXiv:2509.11197, 2025
-
[9]
Yuxing Long, Wenzhe Cai, Hongcheng Wang, Guanqi Zhan, and Hao Dong. Instructnav: Zero-shot system for generic instruction naviga- tion in unexplored environment.arXiv preprint arXiv:2406.04882, 2024
-
[10]
Re- act: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. Re- act: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
work page 2022
-
[11]
Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language mod- els
Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, and Ee-Peng Lim. Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language mod- els. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers), pages 2609–2634, 2023
work page 2023
-
[12]
Reflexion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning, 2023.URL https://arxiv. org/abs/2303.11366, 8, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models
Binfeng Xu, Zhiyuan Peng, Bowen Lei, Subhabrata Mukherjee, Yuchen Liu, and Dongkuan Xu. Re- woo: Decoupling reasoning from observations for efficient augmented language models.arXiv preprint arXiv:2305.18323, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Inner Monologue: Embodied Reasoning through Planning with Language Models
Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, et al. Inner monologue: Embodied reasoning through planning with language models.arXiv preprint arXiv:2207.05608, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Man- dlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended em- bodied agent with large language models, 2023.URL https://arxiv. org/abs/2305.16291, 2(11), 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Waypoint mod- els for instruction-guided navigation in continuous environments
Jacob Krantz, Aaron Gokaslan, Dhruv Batra, Ste- fan Lee, and Oleksandr Maksymets. Waypoint mod- els for instruction-guided navigation in continuous environments. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 15162–15171, 2021
work page 2021
-
[17]
Cross-modal map learning for vision and language navigation
Georgios Georgakis, Karl Schmeckpeper, Karan Wanchoo, Soham Dan, Eleni Miltsakaki, Dan Roth, and Kostas Daniilidis. Cross-modal map learning for vision and language navigation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15460–15470, 2022
work page 2022
-
[18]
Gridmm: Grid memory map for vision-and-language navigation
Zihan Wang, Xiangyang Li, Jiahao Yang, Yeqi Liu, and Shuqiang Jiang. Gridmm: Grid memory map for vision-and-language navigation. InProceedings of the IEEE/CVF International conference on computer vision, pages 15625–15636, 2023
work page 2023
-
[19]
Lingfeng Zhang, Xiaoshuai Hao, Qinwen Xu, Qiang Zhang, Xinyao Zhang, Pengwei Wang, Jing Zhang, Zhongyuan Wang, Shanghang Zhang, and Renjing Xu. Mapnav: A novel memory represen- tation via annotated semantic maps for vlm-based vision-and-language navigation. InProceedings of the 63rd Annual Meeting of the Association for Com- putational Linguistics (Volume...
work page 2025
-
[20]
Dong An, Yuankai Qi, Yangguang Li, Yan Huang, Liang Wang, Tieniu Tan, and Jing Shao. Bevbert: Multimodal map pre-training for language-guided navigation.arXiv preprint arXiv:2212.04385, 2022
-
[21]
Dong An, Hanqing Wang, Wenguan Wang, Zun Wang, Yan Huang, Keji He, and Liang Wang. Etpnav: Evolving topological planning for vision-language navigation in continuous environments.IEEE Trans- actions on Pattern Analysis and Machine Intelligence, 2024
work page 2024
-
[22]
Meng Wei, Chenyang Wan, Xiqian Yu, Tai Wang, Yuqiang Yang, Xiaohan Mao, Chenming Zhu, Wenzhe Cai, Hanqing Wang, Yilun Chen, et al. Streamvln: Streaming vision-and-language naviga- tion via slowfast context modeling.arXiv preprint arXiv:2507.05240, 2025
-
[23]
Mapgpt: Map- guided prompting with adaptive path planning for vision-and-language navigation
Jiaqi Chen, Bingqian Lin, Ran Xu, Zhenhua Chai, Xiaodan Liang, and Kwan-Yee Wong. Mapgpt: Map- guided prompting with adaptive path planning for vision-and-language navigation. InProceedings of the 62nd Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Papers), pages 9796–9810, 2024
work page 2024
-
[24]
Discuss before moving: Visual language nav- igation via multi-expert discussions
Yuxing Long, Xiaoqi Li, Wenzhe Cai, and Hao Dong. Discuss before moving: Visual language nav- igation via multi-expert discussions. In2024 IEEE International Conference on Robotics and Automa- tion (ICRA), pages 17380–17387. IEEE, 2024. 12
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.