Recognition: no theorem link
LongTail Driving Scenarios with Reasoning Traces: The KITScenes LongTail Dataset
Pith reviewed 2026-05-15 00:27 UTC · model grok-4.3
The pith
New dataset supplies detailed reasoning traces for rare driving scenarios to test multimodal models on instruction following.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that supplying multi-view videos, trajectories, high-level instructions, and detailed multilingual reasoning traces for long-tail driving events creates a resource that supports in-context learning and few-shot generalization in vision-language models and vision-language-action models, while shifting evaluation from purely numeric safety metrics to explicit checks on instruction adherence and output coherence.
What carries the argument
The collection of detailed reasoning traces written by domain experts with diverse cultural backgrounds, attached to multi-view video and trajectory data for long-tail driving events.
If this is right
- Multimodal models gain access to explicit reasoning examples that can be used directly for in-context learning and few-shot adaptation.
- Evaluation expands beyond safety and comfort numbers to include measurable checks on instruction following and semantic consistency of generated outputs.
- Researchers can compare how English, Spanish, and Chinese reasoning styles affect model behavior on the same driving scenes.
- The dataset functions as a public benchmark for studying the role of human-like reasoning in end-to-end driving policies.
Where Pith is reading between the lines
- Similar trace-augmented datasets could be built for other sequential decision domains where rare events dominate risk, such as surgical robotics or industrial automation.
- The explicit traces open a route for human-in-the-loop debugging: failures can be traced back to specific reasoning steps rather than opaque policy outputs.
- Integration with online adaptation loops could let deployed vehicles request and incorporate new expert traces when they encounter novel situations.
Load-bearing premise
The reasoning traces collected from domain experts accurately capture the decision processes needed for competent driving in long-tail scenarios.
What would settle it
A controlled test in which models prompted with the dataset's reasoning traces show no measurable gain in instruction-following accuracy or semantic coherence on held-out long-tail driving clips compared with models prompted only with raw video and instructions.
Figures




read the original abstract
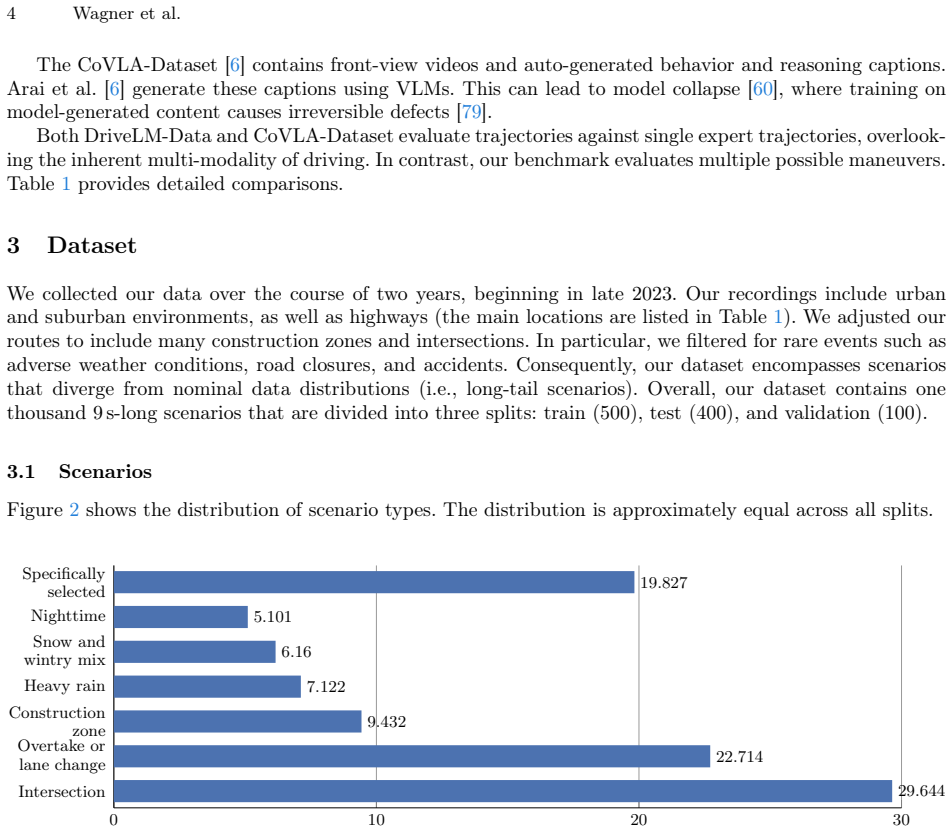
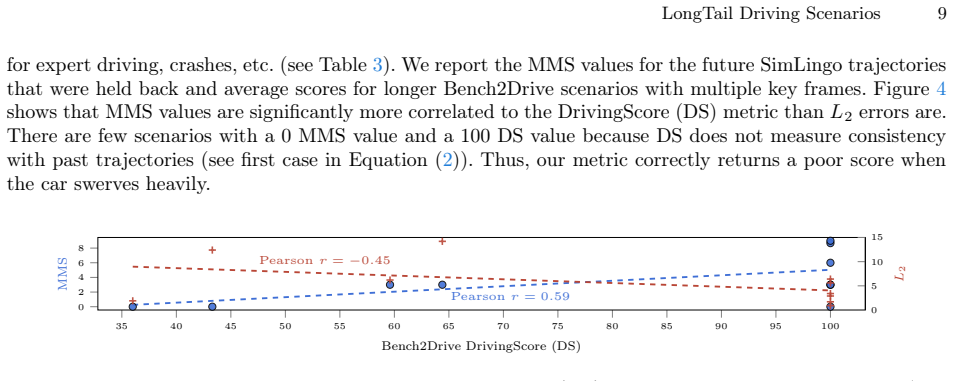
In real-world domains such as self-driving, generalization to rare scenarios remains a fundamental challenge. To address this, we introduce a new dataset designed for end-to-end driving that focuses on long-tail driving events. We provide multi-view video data, trajectories, high-level instructions, and detailed reasoning traces, facilitating in-context learning and few-shot generalization. The resulting benchmark for multimodal models, such as VLMs and VLAs, goes beyond safety and comfort metrics by evaluating instruction following and semantic coherence between model outputs. The multilingual reasoning traces in English, Spanish, and Chinese are from domain experts with diverse cultural backgrounds. Thus, our dataset is a unique resource for studying how different forms of reasoning affect driving competence. Our dataset is available at: https://hf.co/datasets/kit-mrt/kitscenes-longtail
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the KITScenes LongTail Dataset for end-to-end driving focused on long-tail scenarios. It supplies multi-view video, trajectories, high-level instructions, and detailed multilingual reasoning traces (English, Spanish, Chinese) collected from domain experts with diverse backgrounds. The resource is presented as a benchmark for VLMs and VLAs that goes beyond safety metrics to assess instruction following and semantic coherence, with the explicit goal of supporting in-context learning and few-shot generalization.
Significance. If the reasoning traces are shown to be high-quality and effective, the dataset would fill a clear gap in long-tail driving data and enable systematic study of how different reasoning forms affect driving competence in multimodal models. The multilingual expert annotations constitute a distinctive feature that could support cross-cultural analyses of model behavior.
major comments (2)
- [Abstract] Abstract: the claim that the dataset 'facilitates in-context learning and few-shot generalization' is unsupported; the manuscript contains no experiments, baselines, ablations, or quantitative results demonstrating that models conditioned on these reasoning traces outperform those using generic captions or no traces on instruction-following, semantic coherence, or driving-success metrics in long-tail cases.
- [Dataset construction] Dataset construction section: no inter-annotator agreement scores, consistency checks, or correlation with real-world driving competence are reported for the multilingual reasoning traces, leaving the assumption that expert annotations accurately capture required decision processes unverified.
minor comments (2)
- Add a short table comparing the new dataset's scale, annotation richness, and scenario coverage against existing long-tail or driving datasets to clarify its incremental contribution.
- The dataset URL is given; ensure the release includes detailed annotation guidelines and a data card describing collection protocols and potential biases.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our dataset paper. We address each major comment below and describe the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the dataset 'facilitates in-context learning and few-shot generalization' is unsupported; the manuscript contains no experiments, baselines, ablations, or quantitative results demonstrating that models conditioned on these reasoning traces outperform those using generic captions or no traces on instruction-following, semantic coherence, or driving-success metrics in long-tail cases.
Authors: We agree that the manuscript provides no empirical results or baselines demonstrating that the reasoning traces improve in-context learning or few-shot generalization. As this is a dataset introduction paper, the original phrasing was intended to describe intended use cases rather than demonstrated outcomes. We will revise the abstract to state that the dataset is designed to support studies of in-context learning and few-shot generalization in long-tail driving scenarios, removing any implication of verified performance gains. revision: yes
-
Referee: [Dataset construction] Dataset construction section: no inter-annotator agreement scores, consistency checks, or correlation with real-world driving competence are reported for the multilingual reasoning traces, leaving the assumption that expert annotations accurately capture required decision processes unverified.
Authors: We acknowledge that the current manuscript does not report inter-annotator agreement scores, formal consistency metrics, or correlations between the traces and real-world driving outcomes. The traces were produced by domain experts following a structured protocol, but no quantitative agreement analysis was performed. In revision we will expand the dataset construction section with a detailed description of the annotation guidelines, any qualitative quality controls applied, and an explicit discussion of this limitation, including plans for future verification studies. revision: partial
Circularity Check
Dataset release paper contains no derivation chain or self-referential predictions
full rationale
This is a data resource paper introducing the KITScenes LongTail Dataset with multi-view videos, trajectories, instructions, and multilingual reasoning traces. No equations, fitted parameters, predictions, or derivations appear in the abstract or described content. Claims about facilitating in-context learning and few-shot generalization are stated as intended uses of the released data rather than results derived from any internal model or computation. No self-citations, uniqueness theorems, or ansatzes are invoked to support any load-bearing step. The work is self-contained as a benchmark release with no circular reduction of outputs to inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
(2024), O.: OpenAI o1 System Card. arXiv preprint arXiv:2412.16720 (2024) 3, 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Cosmos World Foundation Model Platform for Physical AI
Agarwal, N., Ali, A., Bala, M., Balaji, Y., Barker, E., Cai, T., Chattopadhyay, P., Chen, Y., Cui, Y., Ding, Y., et al.: Cosmos World Foundation Model Platform for Physical AI. arXiv preprint arXiv:2501.03575 (2025) 2, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Agrawal, P., Antoniak, S., Hanna, E.B., Bout, B., Chaplot, D., Chudnovsky, J., Costa, D., De Monicault, B., Garg, S., Gervet, T., et al.: Pixtral 12B. arXiv preprint arXiv:2410.07073 (2024) 9, 10, 11, 16
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
AI, P.: Perplexity Pro (2025),https://www.perplexity.ai/pro, aI-powered research assistant and conversational search engine 9, 18
work page 2025
-
[5]
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Mensch, A., Millican, K., Reynolds, M., et al.: Flamingo: a Visual Language Model for Few-Shot Learning. In: NeurIPS (2022) 3
work page 2022
-
[6]
Arai, H., Miwa, K., Sasaki, K., Watanabe, K., Yamaguchi, Y., Aoki, S., Yamamoto, I.: CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving. In: WACV (2025) 3, 4
work page 2025
-
[7]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025) 9, 10, 11, 16
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language Models are Few-Shot Learners. In: NeurIPS (2020) 2
work page 2020
-
[9]
Caesar, H., Bankiti, V., et al.: nuScenes: A Multimodal Dataset for Autonomous Driving. In: CVPR (2020) 1, 2, 3, 4
work page 2020
-
[10]
NuPlan: A closed-loop ML-based planning benchmark for autonomous vehicles
Caesar, H., Kabzan, J., Tan, K.S., Fong, W.K., Wolff, E., Lang, A., Fletcher, L., Beijbom, O., Omari, S.: nuPlan: A closed-loop ML-based planning benchmark for autonomous vehicles. arXiv preprint arXiv:2106.11810 (2021) 3, 7
work page internal anchor Pith review arXiv 2021
- [11]
-
[12]
Cao, W., Hallgarten, M., Li, T., Dauner, D., Gu, X., Wang, C., Miron, Y., Aiello, M., Li, H., Gilitschenski, I., et al.: Pseudo-Simulation for Autonomous Driving. In: CoRL (2025) 2
work page 2025
-
[13]
Chang, W.J., Zhan, W., Tomizuka, M., Chandraker, M., Pittaluga, F.: LANGTRAJ: Diffusion Model and Dataset for Language-Conditioned Trajectory Simulation. In: ICCV (2025) 3
work page 2025
-
[14]
Vl-jepa: Joint em- bedding predictive architecture for vision-language,
Chen, D., Shukor, M., Moutakanni, T., Chung, W., Yu, J., Kasarla, T., Bolourchi, A., LeCun, Y., Fung, P.: Vl-jepa: Joint embedding predictive architecture for vision-language. arXiv preprint arXiv:2512.10942 (2025) 11
-
[15]
Dauner, D., Hallgarten, M., Li, T., Weng, X., Huang, Z., Yang, Z., Li, H., Gilitschenski, I., Ivanovic, B., Pavone, M., et al.: NAVSIM: Data-Driven Non-Reactive Autonomous Vehicle Simulation and Benchmarking. In: NeurIPS (2024) 2, 3, 7
work page 2024
-
[16]
Deitke, M., Clark, C., Lee, S., Tripathi, R., Yang, Y., Park, J.S., Salehi, M., Muennighoff, N., Lo, K., Soldaini, L., et al.: Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models. In: CVPR (2025) 3, 6
work page 2025
-
[17]
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In: ICLR (2021) 4
work page 2021
-
[18]
Dosovitskiy, A., Ros, G., Codevilla, F., Lopez, A., Koltun, V.: CARLA: An Open Urban Driving Simulator. In: CoRL (2017) 3
work page 2017
-
[19]
PaLM-E: An Embodied Multimodal Language Model
Driess, D., Xia, F., Sajjadi, M.S.M., Lynch, C., Chowdhery, A., Ichter, B., Wahid, A., Tompson, J., Vuong, Q., Yu, T., Huang, W., Chebotar, Y., Sermanet, P., Duckworth, D., Levine, S., Vanhoucke, V., Hausman, K., Toussaint, M., Greff, K., Zeng, A., Mordatch, I., Florence, P.: PaLM-E: An Embodied Multimodal Language Model. In: arXiv preprint arXiv:2303.033...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
In: ICCV (2021) 8 LongTail Driving Scenarios 13
Ettinger, S., Cheng, S., Caine, B., Liu, C., Zhao, H., Pradhan, S., Chai, Y., Sapp, B., Qi, C.R., Zhou, Y., et al.: Large Scale Interactive Motion Forecasting for Autonomous Driving: The Waymo Open Motion Dataset. In: ICCV (2021) 8 LongTail Driving Scenarios 13
work page 2021
-
[21]
Fent, F., Kuttenreich, F., Ruch, F., Rizwin, F., Juergens, S., Lechermann, L., Nissler, C., Perl, A., Voll, U., Yan, M., Lienkamp, M.: MAN TruckScenes: A Multimodal Dataset for Autonomous Trucking in Diverse Conditions. In: NeurIPS (2024) 2
work page 2024
-
[22]
Gao, S., Yang, J., Chen, L., Chitta, K., Qiu, Y., Geiger, A., Zhang, J., Li, H.: Vista: A Generalizable Driving World Model with High Fidelity and Versatile Controllability. In: NeurIPS (2024) 7
work page 2024
-
[23]
Geiger, A., Lenz, P., Stiller, C., Urtasun, R.: Vision meets Robotics: The KITTI Dataset. The International Journal of Robotics Research32(11), 1231–1237 (2013).https://doi.org/10.1177/0278364913491297,https: //journals.sagepub.com/doi/10.1177/02783649134912972
-
[24]
Geiger, A., Lenz, P., Urtasun, R.: Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In: CVPR (2012) 1, 2
work page 2012
-
[25]
How Long Does It Take to Stop?
Green, M.: "How Long Does It Take to Stop?" Methodological Analysis of Driver Perception-Brake Times. Transportation Human Factors2(3), 195–216 (2000) 7
work page 2000
-
[26]
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al.: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (2025),https://arxiv.org/abs/2501. 129483, 11
work page 2025
-
[27]
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring Mathematical Problem Solving With the MATH Dataset. In: NeurIPS (2021) 10
work page 2021
-
[28]
Hu, Y., Yang, J., Chen, L., Li, K., Sima, C., Zhu, X., Chai, S., Du, S., Lin, T., Wang, W., et al.: Planning-oriented Autonomous Driving. In: CVPR (2023) 2, 9, 10, 16
work page 2023
-
[29]
ACM Transactions on Information Systems43(2), 1–55 (2025) 10
Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., Chen, Q., Peng, W., Feng, X., Qin, B., et al.: A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions. ACM Transactions on Information Systems43(2), 1–55 (2025) 10
work page 2025
-
[30]
Transactions on Machine Learning Research (2025) 2, 8, 9
Hwang, J.J., Xu, R., Lin, H., Hung, W.C., Ji, J., Choi, K., Huang, D., He, T., Covington, P., Sapp, B., Zhou, Y., Guo, J., Anguelov, D., Tan, M.: EMMA: End-to-end multimodal model for autonomous driving. Transactions on Machine Learning Research (2025) 2, 8, 9
work page 2025
-
[31]
Intelligence, P., Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., et al.:π0.5: a Vision-Language-Action Model with Open-World Generalization. In: CoRL (2025) 3
work page 2025
-
[32]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Jain, N., Han, K., Gu, A., Li, W.D., Yan, F., Zhang, T., Wang, S., Solar-Lezama, A., Sen, K., Stoica, I.: Live- CodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code. arXiv preprint arXiv:2403.07974 (2024) 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Jia, X., Yang, Z., Li, Q., Zhang, Z., Yan, J.: Bench2Drive: Towards Multi-Ability Benchmarking of Closed-Loop End-To-End Autonomous Driving. In: NeurIPS (2024) 3, 5, 7, 8
work page 2024
-
[34]
Jiang, B., Chen, S., Xu, Q., Liao, B., Chen, J., Zhou, H., Zhang, Q., Liu, W., Huang, C., Wang, X.: VAD: Vectorized Scene Representation for Efficient Autonomous Driving. In: ICCV (2023) 2
work page 2023
- [35]
-
[36]
Ke, Z., Jiao, F., Ming, Y., Nguyen, X.P., Xu, A., Long, D.X., Li, M., Qin, C., Wang, P., silvio savarese, Xiong, C., Joty, S.: A Survey of Frontiers in LLM Reasoning: Inference Scaling, Learning to Reason, and Agentic Systems. TMLR (2025) 1
work page 2025
-
[37]
In: 2022 25th International Conference on Information Fusion (FUSION)
Kinzig, C., Cortés, I., Fernández, C., Lauer, M.: Real-time seamless image stitching in autonomous driving. In: 2022 25th International Conference on Information Fusion (FUSION). pp. 1–8. IEEE (2022) 5
work page 2022
-
[38]
In: Forum Bildverarbeitung 2024
Kinzig, C., Yifan, J., Lauer, M., Stiller, C.: Image stitching using gradual image warping in autonomous driving. In: Forum Bildverarbeitung 2024. p. 221. KIT Scientific Publishing (2024) 5
work page 2024
-
[39]
In: IEEE Intelligent Vehicles Symposium (IV) (2015) 11
Kong, J., Pfeiffer, M., Schildbach, G., Borrelli, F.: Kinematic and dynamic vehicle models for autonomous driving control design. In: IEEE Intelligent Vehicles Symposium (IV) (2015) 11
work page 2015
-
[40]
Measuring Faithfulness in Chain-of-Thought Reasoning
Lanham, T., Chen, A., Radhakrishnan, A., Steiner, B., Denison, C., Hernandez, D., Li, D., Durmus, E., Hubinger, E., Kernion, J., et al.: Measuring Faithfulness in Chain-of-Thought Reasoning. arXiv preprint arXiv:2307.13702 (2023) 7
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Li, D., Zhang, Y., Cao, M., Liu, D., Xie, W., Hui, T., Lin, L., Xie, Z., Li, Y.: Towards Long-Horizon Vision- Language-Action System: Reasoning, Acting and Memory. In: ICCV (2025) 3
work page 2025
-
[42]
Li, J., Li, D., Xiong, C., Hoi, S.: BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation. In: ICML (2022) 3
work page 2022
-
[43]
arXiv preprint arXiv:2506.02265 (2025) 9
Li, S., Kachana, P., Chidananda, P., Nair, S., Furukawa, Y., Brown, M.: Rig3R: Rig-Aware Conditioning for Learned 3D Reconstruction. arXiv preprint arXiv:2506.02265 (2025) 9
-
[44]
arXiv preprint arXiv:2509.19249 (2025) 7
Li, S., Li, K., Xu, Z., Huang, G., Yang, E., Li, K., Wu, H., Wu, J., Zheng, Z., Zhang, C., et al.: Reinforcement Learning on Pre-Training Data. arXiv preprint arXiv:2509.19249 (2025) 7
-
[45]
Li, Y., Fan, C., Ge, C., Zhao, Z., Li, C., Xu, C., Yao, H., Tomizuka, M., Zhou, B., Tang, C., et al.: WOMD- Reasoning: A Large-Scale Dataset for Interaction Reasoning in Driving. In: ICML (2025) 3
work page 2025
-
[46]
Li, Z., Yu, Z., Lan, S., Li, J., Kautz, J., Lu, T., Alvarez, J.M.: Is Ego Status All You Need for Open-Loop End-to-End Autonomous Driving? In: CVPR (2024) 2 14 Wagner et al
work page 2024
-
[47]
Pattern Analysis and Machine Intelligence (PAMI) (2022) 2
Liao, Y., Xie, J., Geiger, A.: KITTI-360: A Novel Dataset and Benchmarks for Urban Scene Understanding in 2D and 3D. Pattern Analysis and Machine Intelligence (PAMI) (2022) 2
work page 2022
-
[48]
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual Instruction Tuning. In: NeurIPS (2023) 3
work page 2023
-
[49]
Liu, J., Liu, M., Wang, Z., An, P., Li, X., Zhou, K., Yang, S., Zhang, R., Guo, Y., Zhang, S.: RoboMamba: Efficient Vision-Language-Action Model for Robotic Reasoning and Manipulation. In: NeurIPS (2024) 3
work page 2024
-
[50]
Ljungbergh, W., Tonderski, A., Johnander, J., Caesar, H., Åström, K., Felsberg, M., Petersson, C.: Neuroncap: Photorealistic closed-loop safety testing for autonomous driving. In: ECCV (2024) 2, 7
work page 2024
-
[51]
Madan, A., Peri, N., Kong, S., Ramanan, D.: Revisiting Few-Shot Object Detection with Vision-Language Models. In: NeurIPS (2024) 1
work page 2024
-
[52]
Manning, C.D., Raghavan, P., Schütze, H.: Introduction to Information Retrieval. Cambridge University Press (2008),http://nlp.stanford.edu/IR-book/html/htmledition/rocchio-classification-1.html6
work page 2008
-
[53]
Mousakhan, A., Mittal, S., Galesso, S., Farid, K., Brox, T.: Orbis: Overcoming Challenges of Long-Horizon Prediction in Driving World Models. In: NeurIPS (2025) 2, 7
work page 2025
-
[54]
Mu, Y., Zhang, Q., Hu, M., Wang, W., Ding, M., Jin, J., Wang, B., Dai, J., Qiao, Y., Luo, P.: EmbodiedGPT: Vision-Language Pre-Training via Embodied Chain of Thought. In: NeurIPS (2023) 3
work page 2023
-
[55]
Muennighoff, N., Tazi, N., Magne, L., Reimers, N.: MTEB: Massive Text Embedding Benchmark. In: EACL (2023) 6
work page 2023
-
[56]
Radford, A., Kim, J., Xu, T., Brockman, G., McLeavey, C., Sutskever, I.: Robust Speech Recognition via Large- Scale Weak Supervision. In: ICML (2023) 6
work page 2023
-
[57]
Renz, K., Chen, L., Arani, E., Sinavski, O.: Simlingo: Vision-only closed-loop autonomous driving with language- action alignment. In: CVPR (2025) 8
work page 2025
-
[58]
Luke Rowe, Rodrigue de Schaetzen, Roger Girgis, Christopher Pal, and Liam Paull
Rowe, L., de Schaetzen, R., Girgis, R., Pal, C., Paull, L.: Poutine: Vision-Language-Trajectory Pre-Training and Reinforcement Learning Post-Training Enable Robust End-to-End Autonomous Driving. arXiv preprint arXiv:2506.11234 (2025) 2, 8, 10
-
[59]
Shen, Y., Tas, O.S., Wang, K., Wagner, R., Stiller, C.: Divide and Merge: Motion and Semantic Learning in End-to-End Autonomous Driving. TMLR (2025) 9, 10, 16
work page 2025
-
[60]
Nature631(8022), 755–759 (2024) 4
Shumailov, I., Shumaylov, Z., Zhao, Y., Papernot, N., Anderson, R., Gal, Y.: Ai models collapse when trained on recursively generated data. Nature631(8022), 755–759 (2024) 4
work page 2024
-
[61]
Sima, C., Renz, K., Chitta, K., Chen, L., Zhang, H., Xie, C., Beißwenger, J., Luo, P., Geiger, A., Li, H.: DriveLM: Driving with Graph Visual Question Answering. In: ECCV (2024) 2, 3, 10
work page 2024
-
[62]
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al.: OpenAI GPT-5 System Card. arXiv preprint arXiv:2601.03267 (2025) 9, 10, 16
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Sun, P., Kretzschmar, H., Dotiwalla, X., Chouard, A., Patnaik, V., Tsui, P., Guo, J., Zhou, Y., Chai, Y., Caine, B., et al.: Scalability in Perception for Autonomous Driving. In: CVPR (2020) 1, 2
work page 2020
-
[64]
Sun, W., Lin, X., Shi, Y., Zhang, C., Wu, H., Zheng, S.: SparseDrive: End-to-End Autonomous Driving via Sparse Scene Representation. In: ICRA (2025) 2
work page 2025
-
[65]
Tas, O.S., Wagner, R.: Words in Motion: Extracting Interpretable Control Vectors for Motion Transformers. In: ICLR (2025) 6
work page 2025
-
[66]
Team, G.R.: Gemini Robotics 1.5: Pushing the Frontier of Generalist Robots with Advanced Embodied Reasoning, Thinking, and Motion Transfer. arXiv (2025) 9, 10, 16
work page 2025
-
[67]
Team, G., Kamath, A., Ferret, J., Pathak, S., Vieillard, N., Merhej, R., Perrin, S., Matejovicova, T., Ramé, A., Rivière, M., et al.: Gemma 3 Technical Report. arXiv preprint arXiv:2503.19786 (2025) 9, 10, 11, 16
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[68]
EmbeddingGemma: Powerful and Lightweight Text Representations
Vera, H.S., Dua, S., Zhang, B., Salz, D., Mullins, R., Panyam, S.R., Smoot, S., Naim, I., Zou, J., Chen, F., et al.: EmbeddingGemma: Powerful and Lightweight Text Representations. arXiv preprint arXiv:2509.20354 (2025) 6
work page internal anchor Pith review arXiv 2025
-
[69]
Wang, S., Yu, Z., Jiang, X., Lan, S., Shi, M., Chang, N., Kautz, J., Li, Y., Alvarez, J.M.: OmniDrive: A Holistic Vision-Language Dataset for Autonomous Driving with Counterfactual Reasoning. In: CVPR (2025) 3
work page 2025
- [70]
-
[71]
Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., Zhou, D.: Self-Consistency Improves Chain of Thought Reasoning in Language Models. In: ICLR (2023) 3
work page 2023
-
[72]
Wang, Y., Zhu, H., Liu, M., Yang, J., Fang, H.S., He, T.: VQ-VLA: Improving Vision-Language-Action Models via Scaling Vector-Quantized Action Tokenizers. In: ICCV (2025) 3
work page 2025
-
[73]
Waymo Open Dataset: Vision-based End-to-End Driving Challenge 2025.https://waymo.com/open/challenges/ 2025/e2e-driving(2025), accessed: 2025-11-01 3, 5, 7
work page 2025
-
[74]
Wei, J., Bosma, M., Zhao, V., Guu, K., Yu, A.W., Lester, B., Du, N., Dai, A.M., Le, Q.V.: Finetuned Language Models are Zero-Shot Learners. In: ICLR (2022) 9
work page 2022
-
[75]
In: NeurIPS (2022) 2, 3, 9 LongTail Driving Scenarios 15
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q.V., Zhou, D., et al.: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. In: NeurIPS (2022) 2, 3, 9 LongTail Driving Scenarios 15
work page 2022
-
[76]
Argoverse 2: Next Generation Datasets for Self-Driving Perception and Forecasting
Wilson, B., Qi, W., Agarwal, T., Lambert, J., Singh, J., Khandelwal, S., Pan, B., Kumar, R., Hartnett, A., Pontes, J.K., et al.: Argoverse 2: Next Generation Datasets for Self-Driving Perception and Forecasting. arXiv:2301.00493 (2023) 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[77]
arXiv preprint arXiv:2510.26909 (2025) 8
Windecker, T., Patel, M., Reuss, M., Schwarzkopf, R., Cadena, C., Lioutikov, R., Hutter, M., Frey, J.: NaviTrace: Evaluating Embodied Navigation of Vision-Language Models. arXiv preprint arXiv:2510.26909 (2025) 8
-
[78]
Xia, Z., Li, J., Lin, Z., Wang, X., Wang, Y., Yang, M.H.: OpenAD: Open-world autonomous driving benchmark for 3d object detection. In: NeurIPS (2025) 1
work page 2025
-
[79]
LLMs Can Get "Brain Rot": A Pilot Study on Twitter/X
Xing, S., Hong, J., Wang, Y., Chen, R., Zhang, Z., Grama, A., Tu, Z., Wang, Z.: LLMs Can Get" Brain Rot"! arXiv preprint arXiv:2510.13928 (2025) 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[80]
Xu, R., Qi, Z., Guo, Z., Wang, C., Wang, H., Zhang, Y., Xu, W.: Knowledge Conflicts for LLMs: A Survey. In: EMPL (2024) 10
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.