VAN-AD: Visual Masked Autoencoder with Normalizing Flow For Time Series Anomaly Detection
Pith reviewed 2026-05-14 23:59 UTC · model grok-4.3
The pith
A visual masked autoencoder pretrained on images adapts to time series anomaly detection when augmented with distribution mapping and normalizing flow modules.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
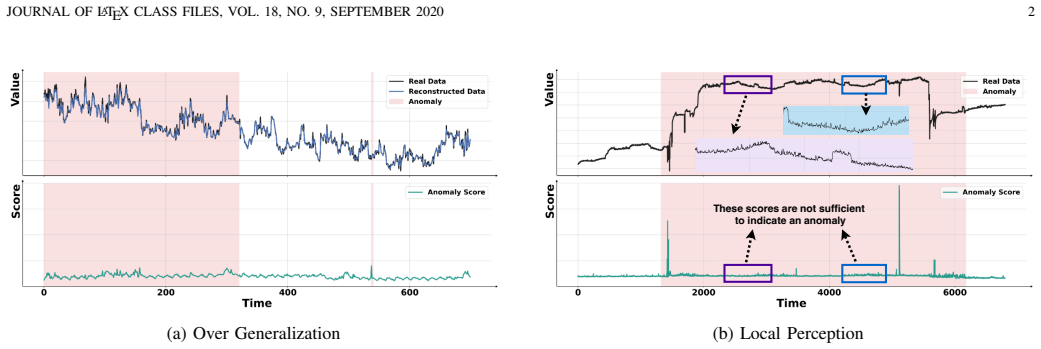
Direct transfer of a visual MAE to time series data produces overgeneralization and weak local sensitivity; these are mitigated by an Adaptive Distribution Mapping Module that projects pre- and post-MAE reconstructions into a shared statistical space to enlarge anomaly signals, and by a Normalizing Flow Module that fuses the MAE with density estimation under the global distribution, yielding higher detection scores than prior methods on nine real-world datasets.
What carries the argument
VAN-AD framework that adapts a visual Masked Autoencoder with an Adaptive Distribution Mapping Module (ADMM) to unify reconstruction statistics and a Normalizing Flow Module (NFM) to estimate window densities.
If this is right
- One pretrained vision model plus two lightweight modules can replace separate models for each time series dataset.
- Reconstruction error becomes a stronger anomaly signal once mapped into a common distribution space.
- Normalizing flow density estimation supplies the global context that pure local reconstruction lacks.
- Cross-modal foundation models become practical for sequential anomaly tasks without building new large-scale time-series pretraining corpora.
Where Pith is reading between the lines
- The same two-module pattern might allow other vision or language foundation models to transfer to time series tasks with only modest adaptation.
- If the modules prove robust across domains, anomaly detection could shift from dataset-specific training toward lightweight fine-tuning of shared backbones.
- Testing whether the density estimates remain calibrated on streams with sudden distribution shifts would clarify the limits of the global modeling step.
- Applying the same mapping-plus-flow idea to multivariate sensor data or irregularly sampled series could extend the approach beyond the univariate windows used here.
Load-bearing premise
The visual features learned from natural images transfer to time series windows in a way that the added mapping and flow modules can correct without introducing new mismatches or needing per-dataset retuning.
What would settle it
Running VAN-AD on a tenth dataset whose statistical properties differ sharply from the nine tested ones and finding that its F1 or AUC falls below a simple dataset-specific autoencoder trained from scratch on that tenth set.
Figures






read the original abstract
Time series anomaly detection (TSAD) is essential for maintaining the reliability and security of IoT-enabled service systems. Existing methods require training one specific model for each dataset, which exhibits limited generalization capability across different target datasets, hindering anomaly detection performance in various scenarios with scarce training data. To address this limitation, foundation models have emerged as a promising direction. However, existing approaches either repurpose large language models (LLMs) or construct largescale time series datasets to develop general anomaly detection foundation models, and still face challenges caused by severe cross-modal gaps or in-domain heterogeneity. In this paper, we investigate the applicability of large-scale vision models to TSAD. Specifically, we adapt a visual Masked Autoencoder (MAE) pretrained on ImageNet to the TSAD task. However, directly transferring MAE to TSAD introduces two key challenges: overgeneralization and limited local perception. To address these challenges, we propose VAN-AD, a novel MAE-based framework for TSAD. To alleviate the over-generalization issue, we design an Adaptive Distribution Mapping Module (ADMM), which maps the reconstruction results before and after MAE into a unified statistical space to amplify discrepancies caused by abnormal patterns. To overcome the limitation of local perception, we further develop a Normalizing Flow Module (NFM), which combines MAE with normalizing flow to estimate the probability density of the current window under the global distribution. Extensive experiments on nine real-world datasets demonstrate that VAN-AD consistently outperforms existing state-of-the-art methods across multiple evaluation metrics.We make our code and datasets available at https://github.com/PenyChen/VAN-AD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VAN-AD, which adapts an ImageNet-pretrained visual Masked Autoencoder (MAE) to time series anomaly detection. It introduces an Adaptive Distribution Mapping Module (ADMM) to map reconstructions into a unified statistical space and mitigate overgeneralization, plus a Normalizing Flow Module (NFM) to estimate window densities and address limited local perception. The central claim is that this yields consistent outperformance over SOTA methods across nine real-world datasets.
Significance. If the outperformance holds under rigorous evaluation and the method reduces reliance on per-dataset training, the work would demonstrate a practical route for transferring large vision foundation models to TSAD, addressing data scarcity and cross-dataset generalization. The ADMM+NFM combination with MAE is a technically coherent adaptation that could influence future cross-modal foundation-model research in anomaly detection.
major comments (3)
- [Abstract] Abstract: the claim that 'VAN-AD consistently outperforms existing state-of-the-art methods across multiple evaluation metrics' on nine datasets is unsupported by any numerical results, tables, ablation studies, or details on how overgeneralization and local-perception issues are measured. This is load-bearing for the paper's primary contribution.
- [§3] §3 (Method): the ADMM is described as mapping pre- and post-MAE reconstructions into a unified space to amplify anomalies, yet no equations or analysis show that the mapping is parameter-free or bias-free; without this, it is unclear whether the module resolves overgeneralization or merely adds tunable components that could overfit per dataset.
- [§4] §4 (Experiments): the protocol description implies standard per-dataset training on each dataset's normal split (as is conventional for reconstruction-based TSAD). If confirmed, this undermines the motivation that VAN-AD overcomes the 'one model per dataset' limitation; cross-dataset transfer, zero-shot, or few-shot results are required to substantiate the foundation-model generalization narrative.
minor comments (2)
- [Abstract] The abstract states code and datasets are released at the GitHub link, but the main text should explicitly list the nine datasets, the exact metrics (e.g., F1, AUC), and the train/validation/test splits used.
- [§3.3] Notation for the NFM density estimation should be clarified with respect to the MAE latent space; a short equation relating the flow likelihood to the reconstruction error would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, clarifying the manuscript's contributions while committing to targeted revisions where the feedback identifies gaps in presentation or evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'VAN-AD consistently outperforms existing state-of-the-art methods across multiple evaluation metrics' on nine datasets is unsupported by any numerical results, tables, ablation studies, or details on how overgeneralization and local-perception issues are measured. This is load-bearing for the paper's primary contribution.
Authors: We agree that the abstract is high-level and does not embed specific numbers, which is conventional for length constraints. The full manuscript (Section 4 and associated tables) reports quantitative results across nine datasets using standard metrics (F1-score, AUC-ROC, etc.) with direct comparisons to SOTA baselines. Overgeneralization is quantified via reconstruction error distributions before/after ADMM, and local perception via density estimation improvements from NFM; we will add a short sentence in the abstract highlighting the average performance lift and will expand the method section with explicit measurement definitions and one additional ablation table. revision: partial
-
Referee: [§3] §3 (Method): the ADMM is described as mapping pre- and post-MAE reconstructions into a unified space to amplify anomalies, yet no equations or analysis show that the mapping is parameter-free or bias-free; without this, it is unclear whether the module resolves overgeneralization or merely adds tunable components that could overfit per dataset.
Authors: We appreciate this observation. The current description is textual; we will insert the precise equations for the adaptive mapping (mean/variance normalization computed on-the-fly from the reconstruction statistics of each window) and provide a short bias analysis showing that the transformation is invertible and preserves relative ordering without introducing dataset-specific learned parameters beyond the pretrained MAE weights. To directly address overfitting concerns, the revised version will include an ablation isolating ADMM and reporting performance variance across random seeds and dataset splits. revision: yes
-
Referee: [§4] §4 (Experiments): the protocol description implies standard per-dataset training on each dataset's normal split (as is conventional for reconstruction-based TSAD). If confirmed, this undermines the motivation that VAN-AD overcomes the 'one model per dataset' limitation; cross-dataset transfer, zero-shot, or few-shot results are required to substantiate the foundation-model generalization narrative.
Authors: The experimental protocol is indeed the standard per-dataset training on normal splits, as is required for fair comparison with prior TSAD literature. However, the core advantage stems from initializing with ImageNet-pretrained MAE weights, which demonstrably reduces the volume of target data and training epochs needed for convergence relative to training from scratch. This partially mitigates the data-scarcity aspect of the 'one model per dataset' problem. We will add a new subsection with cross-dataset transfer results (train on one dataset, evaluate on others with light fine-tuning) and few-shot settings to strengthen the generalization claim. revision: partial
Circularity Check
No significant circularity; empirical adaptation with external pretraining
full rationale
The paper describes an empirical transfer of an ImageNet-pretrained visual MAE to TSAD via two new modules (ADMM for distribution mapping and NFM for density estimation). No equations, derivations, or parameter-fitting steps are shown that reduce by construction to the inputs or to self-citations. The pretraining source is external, the modules are presented as novel additions rather than tautological redefinitions, and the central performance claims rest on experimental results across nine datasets rather than on any self-referential identity. This is the common case of a self-contained empirical proposal with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We adapt a visual Masked Autoencoder (MAE) pretrained on ImageNet... design an Adaptive Distribution Mapping Module (ADMM)... Normalizing Flow Module (NFM)... training objective min θ L(θ, X̂) = 1/T Σ −log pX̂(x̂t)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Extensive experiments on nine real-world datasets... outperforms... DADA, Timer, GPT4TS
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Deep learning for time series anomaly detection: A survey,
Z. Zamanzadeh Darban, G. I. Webb, S. Pan, C. Aggarwal, and M. Salehi, “Deep learning for time series anomaly detection: A survey,”ACM Computing Surveys, vol. 57, no. 1, pp. 1–42, 2024
work page 2024
-
[2]
Catch: Channel-aware multivariate time series anomaly detection via frequency patching,
X. Wu, X. Qiu, Z. Li, Y . Wang, J. Hu, C. Guo, H. Xiong, and B. Yang, “Catch: Channel-aware multivariate time series anomaly detection via frequency patching,” inThe Thirteenth International Conference on Learning Representations
-
[3]
Crossad: Time series anomaly detection with cross-scale associations and cross-window modeling,
B. Li, Q. Shentu, Y . Shu, H. Zhang, M. Li, N. Jin, B. Yang, and C. Guo, “Crossad: Time series anomaly detection with cross-scale associations and cross-window modeling,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[4]
Scatterad: Temporal-topological scattering mechanism for time series anomaly detection,
T. Yin, S. Fu, Z. Zhang, L. Huang, X. Zhang, Y . Yang, K. Yang, and M. Yan, “Scatterad: Temporal-topological scattering mechanism for time series anomaly detection,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[5]
Q. Shentu, B. Li, K. Zhao, Y . Shu, Z. Rao, L. Pan, B. Yang, and C. Guo, “Towards a general time series anomaly detector with adap- tive bottlenecks and dual adversarial decoders,” in13th International Conference on Learning Representations, ICLR 2025, pp. 18810–18833, International Conference on Learning Representations, ICLR, 2025
work page 2025
-
[6]
Large language model guided knowledge distillation for time series anomaly detection,
C. Liu, S. He, Q. Zhou, S. Li, and W. Meng, “Large language model guided knowledge distillation for time series anomaly detection,” inProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, pp. 2162–2170, 2024
work page 2024
-
[7]
Can llms understand time series anomalies?,
Z. Zhou and R. Yu, “Can llms understand time series anomalies?,” in The Thirteenth International Conference on Learning Representations
-
[8]
Can llms serve as time series anomaly detectors?,
M. Dong, H. Huang, and L. Cao, “Can llms serve as time series anomaly detectors?,”arXiv preprint arXiv:2408.03475, 2024
-
[9]
Visionts: Visual masked autoencoders are free-lunch zero-shot time series fore- casters,
M. Chen, L. Shen, Z. Li, X. J. Wang, J. Sun, and C. Liu, “Visionts: Visual masked autoencoders are free-lunch zero-shot time series fore- casters,” inInternational Conference on Machine Learning, pp. 8979– 9007, PMLR, 2025
work page 2025
-
[10]
Visionts++: Cross-modal time series foundation model with continual pre-trained vision backbones,
L. Shen, M. Chen, X. Liu, H. Fu, X. Ren, J. Sun, Z. Li, and C. Liu, “Visionts++: Cross-modal time series foundation model with continual pre-trained vision backbones,”arXiv preprint arXiv:2508.04379, 2025
-
[11]
Time series as images: Vision transformer for irregularly sampled time series,
Z. Li, S. Li, and X. Yan, “Time series as images: Vision transformer for irregularly sampled time series,”Advances in Neural Information Processing Systems, vol. 36, pp. 49187–49204, 2023
work page 2023
-
[12]
Masked au- toencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick, “Masked au- toencoders are scalable vision learners,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 16000– 16009, 2022
work page 2022
-
[13]
Learn hybrid prototypes for multivariate time series anomaly detection,
K.-Y . Shen, “Learn hybrid prototypes for multivariate time series anomaly detection,” inThe Thirteenth International Conference on Learning Representations
-
[14]
Memto: Memory-guided trans- former for multivariate time series anomaly detection,
J. Song, K. Kim, J. Oh, and S. Cho, “Memto: Memory-guided trans- former for multivariate time series anomaly detection,”Advances in Neural Information Processing Systems, vol. 36, pp. 57947–57963, 2023
work page 2023
-
[15]
I. U. Haq, B. S. Lee, and D. M. Rizzo, “Transnas-tsad: harnessing transformers for multi-objective neural architecture search in time series anomaly detection,”Neural Computing and Applications, vol. 37, no. 4, pp. 2455–2477, 2025
work page 2025
-
[16]
Paano: Patch-based representation learning for time-series anomaly detection,
J. Park and S. Kang, “Paano: Patch-based representation learning for time-series anomaly detection,” inProceedings of International Confer- ence on Learning Representations, 2026
work page 2026
-
[17]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[18]
Lof: identifying density-based local outliers,
M. M. Breunig, H.-P. Kriegel, R. T. Ng, and J. Sander, “Lof: identifying density-based local outliers,” inProceedings of the 2000 ACM SIGMOD international conference on Management of data, pp. 93–104, 2000
work page 2000
-
[19]
Discovering cluster-based local outliers,
Z. He, X. Xu, and S. Deng, “Discovering cluster-based local outliers,” Pattern recognition letters, vol. 24, no. 9-10, pp. 1641–1650, 2003
work page 2003
-
[20]
A novel anomaly detection scheme based on principal component classifier,
M.-L. Shyu, S.-C. Chen, K. Sarinnapakorn, and L. Chang, “A novel anomaly detection scheme based on principal component classifier,” 2003
work page 2003
-
[21]
Efficient algorithms for mining outliers from large data sets,
S. Ramaswamy, R. Rastogi, and K. Shim, “Efficient algorithms for mining outliers from large data sets,” inProceedings of the 2000 ACM SIGMOD international conference on Management of data, pp. 427– 438, 2000
work page 2000
-
[22]
Graph neural network-based anomaly detection in multivariate time series,
A. Deng and B. Hooi, “Graph neural network-based anomaly detection in multivariate time series,” inProceedings of the AAAI conference on artificial intelligence, vol. 35, pp. 4027–4035, 2021
work page 2021
-
[23]
Y . Xie, H. Zhang, and M. A. Babar, “Multivariate time series anomaly detection by capturing coarse-grained intra-and inter-variate dependen- cies,” inProceedings of the ACM on Web Conference 2025, pp. 697–705, 2025
work page 2025
-
[24]
Dcdetector: Dual attention contrastive representation learning for time series anomaly detection,
Y . Yang, C. Zhang, T. Zhou, Q. Wen, and L. Sun, “Dcdetector: Dual attention contrastive representation learning for time series anomaly detection,” inProceedings of the 29th ACM SIGKDD conference on knowledge discovery and data mining, pp. 3033–3045, 2023
work page 2023
-
[25]
Causality- aware contrastive learning for robust multivariate time-series anomaly detection,
H. Kim, J. Mok, D. Lee, J. Lew, S. Kim, and S. Yoon, “Causality- aware contrastive learning for robust multivariate time-series anomaly detection,”arXiv preprint arXiv:2506.03964, 2025
-
[26]
Time-moe: Billion-scale time series foundation models with mixture of experts,
S. Xiaoming, W. Shiyu, N. Yuqi, L. Dianqi, Y . Zhou, W. Qingsong, and M. Jin, “Time-moe: Billion-scale time series foundation models with mixture of experts,” inICLR 2025: The Thirteenth International Conference on Learning Representations, International Conference on Learning Representations, 2025
work page 2025
-
[27]
Chronos: Learning the language of time series,
A. F. Ansari, L. Stella, C. Turkmen, X. Zhang, P. Mercado, H. Shen, O. Shchur, S. S. Rangapuram, S. P. Arango, S. Kapoor,et al., “Chronos: Learning the language of time series,”Transactions on Machine Learn- ing Research, vol. 2024, 2024
work page 2024
-
[28]
Timer: generative pre-trained transformers are large time series models,
Y . Liu, H. Zhang, C. Li, X. Huang, J. Wang, and M. Long, “Timer: generative pre-trained transformers are large time series models,” in Proceedings of the 41st International Conference on Machine Learning, pp. 32369–32399, 2024
work page 2024
-
[29]
One fits all: Power general time series analysis by pretrained lm,
T. Zhou, P. Niu, L. Sun, R. Jin,et al., “One fits all: Power general time series analysis by pretrained lm,”Advances in neural information processing systems, vol. 36, pp. 43322–43355, 2023
work page 2023
-
[30]
Large language models for spatial trajectory patterns mining,
Z. Zhang, H. Amiri, Z. Liu, L. Zhao, and A. Z ¨ufle, “Large language models for spatial trajectory patterns mining,” inProceedings of the 1st ACM SIGSPATIAL International Workshop on Geospatial Anomaly Detection, pp. 52–55, 2024
work page 2024
-
[31]
Ast: Audio spectrogram transformer,
Y . Gong, Y .-A. Chung, and J. Glass, “Ast: Audio spectrogram trans- former,”arXiv preprint arXiv:2104.01778, 2021
-
[32]
Training data-efficient image transformers & distillation through attention,
H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, and H. J ´egou, “Training data-efficient image transformers & distillation through attention,” inInternational conference on machine learning, pp. 10347–10357, PMLR, 2021
work page 2021
-
[33]
Harnessing vision models for time series analysis: A survey,
J. Ni, Z. Zhao, C. A. Shen, H. Tong, D. Song, W. Cheng, D. Luo, and H. Chen, “Harnessing vision models for time series analysis: A survey,” in34th Internationa Joint Conference on Artificial Intelligence, IJCAI 2025, pp. 10612–10620, International Joint Conferences on Artificial Intelligence, 2025
work page 2025
-
[34]
From images to signals: Are large vision models useful for time series analysis?,
Z. Zhao, C. Shen, H. Tong, D. Song, Z. Deng, Q. Wen, and J. Ni, “From images to signals: Are large vision models useful for time series analysis?,”arXiv preprint arXiv:2505.24030, 2025
-
[35]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in2009 IEEE conference on computer vision and pattern recognition, pp. 248–255, Ieee, 2009
work page 2009
-
[36]
Graph-augmented normalizing flows for anomaly detection of multiple time series,
E. Dai and J. Chen, “Graph-augmented normalizing flows for anomaly detection of multiple time series,” inInternational Conference on Learning Representations, 2022
work page 2022
-
[37]
Label-free multivariate time series anomaly detection,
Q. Zhou, S. He, H. Liu, J. Chen, and W. Meng, “Label-free multivariate time series anomaly detection,”IEEE Transactions on Knowledge and Data Engineering, vol. 36, no. 7, pp. 3166–3179, 2024. JOURNAL OF LATEX CLASS FILES, VOL. 18, NO. 9, SEPTEMBER 2020 13
work page 2024
-
[38]
Masked autoregressive flow for density estimation,
G. Papamakarios, T. Pavlakou, and I. Murray, “Masked autoregressive flow for density estimation,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[39]
Calf: Aligning llms for time series forecasting via cross- modal fine-tuning,
P. Liu, H. Guo, T. Dai, N. Li, J. Bao, X. Ren, Y . Jiang, and S.- T. Xia, “Calf: Aligning llms for time series forecasting via cross- modal fine-tuning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, pp. 18915–18923, 2025
work page 2025
-
[40]
itrans- former: Inverted transformers are effective for time series forecasting,
Y . Liu, T. Hu, H. Zhang, H. Wu, S. Wang, L. Ma, and M. Long, “itrans- former: Inverted transformers are effective for time series forecasting,” inThe Twelfth International Conference on Learning Representations
-
[41]
Moderntcn: A modern pure convolution structure for general time series analysis.,
D. Luo and X. Wang, “Moderntcn: A modern pure convolution structure for general time series analysis.,”
-
[42]
Breaking the time-frequency granularity discrepancy in time-series anomaly detection,
Y . Nam, S. Yoon, Y . Shin, M. Bae, H. Song, J.-G. Lee, and B. S. Lee, “Breaking the time-frequency granularity discrepancy in time-series anomaly detection,” inProceedings of the ACM Web Conference 2024, pp. 4204–4215, 2024
work page 2024
-
[43]
Noise matters: Cross contrastive learning for flink anomaly detection,
Z. Zhuang, Y . Zhang, K. Zhao, C. Guo, B. Yang, Q. Wen, and L. Fan, “Noise matters: Cross contrastive learning for flink anomaly detection,” Proceedings of the VLDB Endowment, vol. 18, no. 4, pp. 1159–1168, 2024
work page 2024
-
[44]
C. Wang, Z. Zhuang, Q. Qi, J. Wang, X. Wang, H. Sun, and J. Liao, “Drift doesn’t matter: Dynamic decomposition with diffusion reconstruc- tion for unstable multivariate time series anomaly detection,” inThirty- seventh Conference on Neural Information Processing Systems, 2023
work page 2023
-
[45]
Local evaluation of time series anomaly detection algorithms,
A. Huet, J. M. Navarro, and D. Rossi, “Local evaluation of time series anomaly detection algorithms,” inProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 635–645, 2022
work page 2022
-
[46]
The elephant in the room: Towards a reliable time-series anomaly detection benchmark,
Q. Liu and J. Paparrizos, “The elephant in the room: Towards a reliable time-series anomaly detection benchmark,”Advances in Neural Information Processing Systems, vol. 37, pp. 108231–108261, 2024
work page 2024
-
[47]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark,et al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning, pp. 8748–8763, PmLR, 2021
work page 2021
-
[48]
Towards multimodal time series anomaly detection with semantic alignment and condensed interaction,
S. Hu, J. Jin, Y . Shu, P. Chen, B. Yang, and C. Guo, “Towards multimodal time series anomaly detection with semantic alignment and condensed interaction,” 2026
work page 2026
-
[49]
Harnessing vision-language models for time series anomaly detection,
Z. He, S. Alnegheimish, and M. Reimherr, “Harnessing vision-language models for time series anomaly detection,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, pp. 21690–21698, 2026
work page 2026
-
[50]
T3time: Tri-modal time series forecasting via adaptive multi-head alignment and residual fusion,
A. M. Chowdhury, R. Akter, and S. H. Arib, “T3time: Tri-modal time series forecasting via adaptive multi-head alignment and residual fusion,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, pp. 20597–20605, 2026
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.