Recognition: 2 theorem links
· Lean TheoremFedSQ: Optimized Weight Averaging via Fixed Gating
Pith reviewed 2026-05-13 20:06 UTC · model grok-4.3
The pith
FedSQ freezes structural gating from pretrained models to stabilize federated averaging of quantitative weights under data heterogeneity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
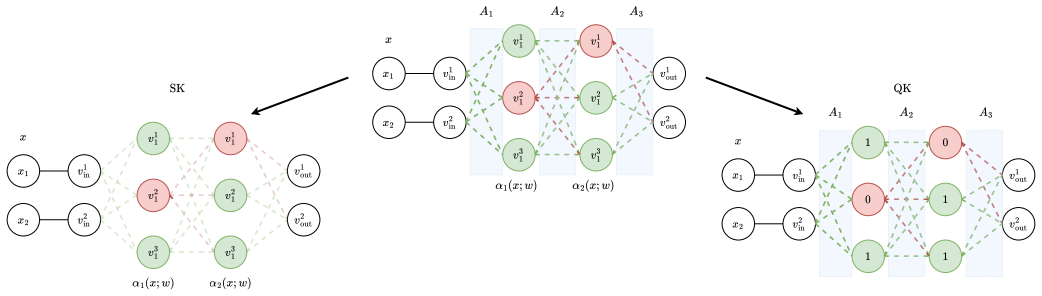
FedSQ freezes a structural copy of the pretrained model to induce fixed binary gating masks during federated fine-tuning, while only a quantitative copy is optimized locally and aggregated across rounds. Fixing the gating reduces learning to within-regime affine refinements, which stabilizes aggregation under heterogeneous partitions.
What carries the argument
The DualCopy view that separates a frozen structural copy supplying fixed binary gating masks from an optimizable quantitative copy whose weights are averaged each round.
If this is right
- Client drift is reduced because updates remain inside fixed linear pieces rather than crossing regime boundaries.
- Fewer communication rounds are required to reach peak validation performance in the transfer setting.
- Final accuracy is preserved while robustness to non-i.i.d. partitions increases.
- The approach applies directly to standard convolutional networks pretrained on ImageNet-scale data.
Where Pith is reading between the lines
- The structural-quantitative split may improve efficiency in centralized transfer learning as well as federated settings.
- Slowly adapting rather than fully fixed gates could be a natural next step if early stabilization is only approximate.
- Similar fixed-structure ideas might help other aggregation-based algorithms that suffer from parameter drift.
Load-bearing premise
ReLU-like gating regimes stabilize earlier than the remaining quantitative parameters, so the structural copy can safely be frozen without losing needed adaptability.
What would settle it
An experiment in which the structural copy is unfrozen after the first few rounds and the resulting model reaches higher validation accuracy or converges in fewer rounds than the fixed-gating version under the same Dirichlet partitions would falsify the claim.
Figures

read the original abstract
Federated learning (FL) enables collaborative training across organizations without sharing raw data, but it is hindered by statistical heterogeneity (non-i.i.d.\ client data) and by instability of naive weight averaging under client drift. In many cross-silo deployments, FL is warm-started from a strong pretrained backbone (e.g., ImageNet-1K) and then adapted to local domains. Motivated by recent evidence that ReLU-like gating regimes (structural knowledge) stabilize earlier than the remaining parameter values (quantitative knowledge), we propose FedSQ (Federated Structural-Quantitative learning), a transfer-initialized neural federated procedure based on a DualCopy, piecewise-linear view of deep networks. FedSQ freezes a structural copy of the pretrained model to induce fixed binary gating masks during federated fine-tuning, while only a quantitative copy is optimized locally and aggregated across rounds. Fixing the gating reduces learning to within-regime affine refinements, which stabilizes aggregation under heterogeneous partitions. Experiments on two convolutional neural network backbones under i.i.d.\ and Dirichlet splits show that FedSQ improves robustness and can reduce rounds-to-best validation performance relative to standard baselines while preserving accuracy in the transfer setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FedSQ, a federated learning procedure for transfer settings that maintains a frozen structural copy of a pretrained model to induce fixed binary gating masks (via a DualCopy piecewise-linear view of networks) while only optimizing and averaging a quantitative copy of the parameters across clients. Motivated by the claim that ReLU-like gating regimes stabilize earlier than quantitative values, this is argued to reduce local learning to within-regime affine refinements that stabilize FedAvg-style aggregation under non-i.i.d. partitions. Experiments on two CNN backbones under i.i.d. and Dirichlet splits are reported to show improved robustness and fewer rounds to best validation performance while preserving accuracy.
Significance. If the core premise on differential stabilization of gating versus weights holds and is properly validated, FedSQ offers a lightweight, communication-efficient modification to standard federated averaging that could improve stability in cross-silo transfer learning without introducing new hyperparameters or auxiliary models. The structural-quantitative separation provides a clean conceptual framing, but its impact is currently limited by the absence of direct supporting analysis or quantitative experimental detail.
major comments (2)
- [Abstract] Abstract and motivation: the central claim that fixing binary gating masks reduces learning to within-regime affine refinements and thereby stabilizes aggregation rests entirely on the unverified premise that ReLU-like gating regimes stabilize earlier than quantitative parameters; this is introduced as external motivation but receives no derivation, no ablation on mask evolution across rounds, and no comparison of stabilization timelines for structural versus quantitative components within the manuscript.
- [Experiments] Experiments description: the reported improvements in robustness and rounds-to-best performance are stated without any quantitative metrics, error bars, ablation tables, or baseline comparisons, rendering it impossible to assess effect sizes or confirm that gains are attributable to the fixed-gating mechanism rather than other factors.
minor comments (1)
- The DualCopy construction and piecewise-linear view are referenced but not formally defined or illustrated with a diagram or pseudocode in the provided abstract-level description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below and will incorporate revisions to strengthen the motivation and experimental reporting.
read point-by-point responses
-
Referee: [Abstract] Abstract and motivation: the central claim that fixing binary gating masks reduces learning to within-regime affine refinements and thereby stabilizes aggregation rests entirely on the unverified premise that ReLU-like gating regimes stabilize earlier than quantitative parameters; this is introduced as external motivation but receives no derivation, no ablation on mask evolution across rounds, and no comparison of stabilization timelines for structural versus quantitative components within the manuscript.
Authors: The premise draws from established observations in the literature on piecewise-linear network dynamics, where gating (structural) components converge faster than quantitative weights under gradient flow. In revision we will (i) add explicit citations to the supporting studies, (ii) include a short derivation sketch showing how fixed binary masks reduce the effective optimization to affine refinements within each linear region, and (iii) add an ablation plot tracking mask stability versus weight drift across federated rounds on the reported CNN backbones. This will directly verify the differential stabilization timeline. revision: yes
-
Referee: [Experiments] Experiments description: the reported improvements in robustness and rounds-to-best performance are stated without any quantitative metrics, error bars, ablation tables, or baseline comparisons, rendering it impossible to assess effect sizes or confirm that gains are attributable to the fixed-gating mechanism rather than other factors.
Authors: We acknowledge that the current experimental narrative relies on qualitative statements and figures without accompanying numerical tables. In the revised manuscript we will add (i) a results table reporting mean accuracy, rounds-to-best validation, and robustness metrics (e.g., performance drop under Dirichlet splits) with standard deviations over multiple seeds, (ii) explicit baseline comparisons against FedAvg, FedProx, and a non-fixed-gating ablation, and (iii) an additional table isolating the contribution of the fixed masks. These additions will allow direct assessment of effect sizes. revision: yes
Circularity Check
No significant circularity; method is a procedural design choice motivated externally
full rationale
The paper presents FedSQ as a transfer-initialized FL procedure that freezes a structural copy to induce fixed binary gating masks, reducing learning to within-regime affine refinements. This is explicitly motivated by external recent evidence on stabilization timelines rather than derived from any equation or self-referential definition within the paper. No fitted parameters are renamed as predictions, no self-citation chains bear the central claim, and no ansatz or uniqueness theorem is smuggled in. The derivation chain consists of a design decision grounded outside the manuscript, with the stabilization benefit treated as a consequence of the procedure rather than a tautological input. This qualifies as a standard non-circular presentation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption ReLU-like gating regimes stabilize earlier than the remaining parameter values
invented entities (1)
-
DualCopy piecewise-linear view of deep networks
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Motivated by recent evidence that ReLU-like gating regimes (structural knowledge) stabilize earlier than the remaining parameter values (quantitative knowledge)... freezes a structural copy... induces fixed binary gating masks... reduces learning to within-regime affine refinements
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
DualCopy, piecewise-linear view of deep networks... structural component... quantitative component... within-regime affine map
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Communication-efficient learning of deep networks from decentralized data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y. Arcas, “Communication-efficient learning of deep networks from decentralized data,” inProceedings of the 20th International Conference on Artificial Intelligence and Statistics, 2017
work page 2017
-
[2]
Advances and open problems in federated learning,
P. Kairouz and H. B. McMahan, “Advances and open problems in federated learning,”Foundations and trends in machine learning, vol. 14, no. 1-2, pp. 1–210, 2021
work page 2021
-
[3]
FedBN: Federated learning on non-IID features via local batch normalization,
X. Li, M. Jiang, X. Zhang, M. Kamp, and Q. Dou, “FedBN: Federated learning on non-IID features via local batch normalization,” inInterna- tional Conference on Learning Representations, 2021
work page 2021
-
[4]
Exploiting shared representations for personalized federated learning,
L. Collins, H. Hassani, A. Mokhtari, and S. Shakkottai, “Exploiting shared representations for personalized federated learning,” inInterna- tional Conference on Machine Learning (ICML), 2021
work page 2021
-
[5]
M. Reisser, C. Louizos, E. Gavves, and M. Welling, “Federated mixture of experts,”arXiv preprint arXiv:2107.06724, 2021
-
[6]
Federated learning: Strategies for improving communication efficiency,
J. Kone ˇcn´y, H. B. McMahan, F. X. Yu, P. Richtarik, A. T. Suresh, and D. Bacon, “Federated learning: Strategies for improving communication efficiency,” inNIPS Workshop on Private Multi-Party Machine Learning, 2016
work page 2016
-
[7]
QSGD: Communication-efficient SGD via gradient quantization and encoding,
D. Alistarhet al., “QSGD: Communication-efficient SGD via gradient quantization and encoding,” inAdvances in Neural Information Process- ing Systems (NeurIPS), 2017
work page 2017
-
[8]
Deep gradient compression: Reducing the communica- tion bandwidth for distributed training,
Y . Lin, S. Han, H. Mao, Y . Wang, and W. J. Dally, “Deep gradient compression: Reducing the communication bandwidth for distributed training,”arXiv preprint arXiv:1712.01887, 2017
-
[9]
Robust and communication-efficient federated learning from non-iid data,
F. Sattler, S. Wiedemann, K.-R. M ¨uller, and W. Samek, “Robust and communication-efficient federated learning from non-iid data,”IEEE transactions on neural networks and learning systems, 2019
work page 2019
-
[10]
Where to begin? on the impact of pre-training and initialization in federated learning,
J. Nguyen, J. Wang, K. Malik, M. Sanjabi, and M. Rabbat, “Where to begin? on the impact of pre-training and initialization in federated learning,” inWorkshop on Federated Learning: Recent Advances and New Challenges (in Conjunction with NeurIPS 2022), 2022
work page 2022
-
[11]
On the importance and applicability of pre-training for federated learning,
H.-Y . Chen, C.-H. Tu, Z. Li, H. W. Shen, and W.-L. Chao, “On the importance and applicability of pre-training for federated learning,” in The Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[12]
Federated learning for medical image classification: A comprehensive benchmark,
Z. Zhou, G. Luo, M. Chen, Z. Weng, and Y . Zhu, “Federated learning for medical image classification: A comprehensive benchmark,”IEEE journal of biomedical and health informatics, 2025
work page 2025
-
[13]
How transferable are features in deep neural networks?
J. Yosinski, J. Clune, Y . Bengio, and H. Lipson, “How transferable are features in deep neural networks?”Advances in neural information processing systems, vol. 27, 2014
work page 2014
-
[14]
Regime change hypothesis: Foun- dations for decoupled dynamics in neural network training,
C. P ´erez-Corral, A. Fern ´andez-Hern´andez, J. I. Mestre, M. F. Dolz, J. Duato, and E. S. Quintana-Ort ´ı, “Regime change hypothesis: Foun- dations for decoupled dynamics in neural network training,” 2026
work page 2026
-
[15]
Decoupling structural and quantitative knowledge in ReLU-based deep neural networks,
J. Duato, J. I. Mestre, M. F. Dolz, E. S. Quintana-Ort ´ı, and J. Cano, “Decoupling structural and quantitative knowledge in ReLU-based deep neural networks,” inProceedings of the 5th Workshop on Machine Learning and Systems, ser. EuroMLSys ’25, 2025
work page 2025
-
[16]
Federated optimization in heterogeneous networks,
T. Li, A. K. Sahu, and Z. et al., “Federated optimization in heterogeneous networks,” inProceedings of Machine Learning and Systems, 2020
work page 2020
-
[17]
Adaptive federated optimization,
S. J. Reddi, Z. Charles, M. Zaheer, Z. Garrett, K. Rush, J. Kone ˇcn´y, S. Kumar, and H. B. McMahan, “Adaptive federated optimization,” in International Conference on Learning Representations, 2021
work page 2021
-
[18]
FedBABU: Toward enhanced representa- tion for federated image classification,
J. Oh, S. Kim, and S.-Y . Yun, “FedBABU: Toward enhanced representa- tion for federated image classification,” inInternational Conference on Learning Representations, 2022
work page 2022
-
[19]
Imagenet classification with deep convolutional neural networks,
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” inAdvances in Neural Infor- mation Processing Systems. Curran Associates, Inc., 2012
work page 2012
-
[20]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016
work page 2016
-
[21]
Cinic-10 is not imagenet or cifar-10,
L. N. Darlow, E. J. Crowley, A. Antoniou, and A. J. Storkey, “Cinic-10 is not imagenet or cifar-10,” 2018
work page 2018
-
[22]
Learning multiple layers of features from tiny images,
A. Krizhevsky, “Learning multiple layers of features from tiny images,” Tech. Rep., 2009
work page 2009
-
[23]
Bayesian nonparametric federated learning of neural networks,
M. Yurochkin, M. Agarwal, S. Ghosh, K. Greenewald, T. N. Hoang, and Y . Khazaeni, “Bayesian nonparametric federated learning of neural networks,” 2019
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.