Recognition: 2 theorem links
· Lean TheoremEarly Stopping for Large Reasoning Models via Confidence Dynamics
Pith reviewed 2026-05-10 19:45 UTC · model grok-4.3
The pith
CoDE-Stop halts chain-of-thought reasoning when intermediate answer confidence stabilizes, cutting token use by 25-50%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
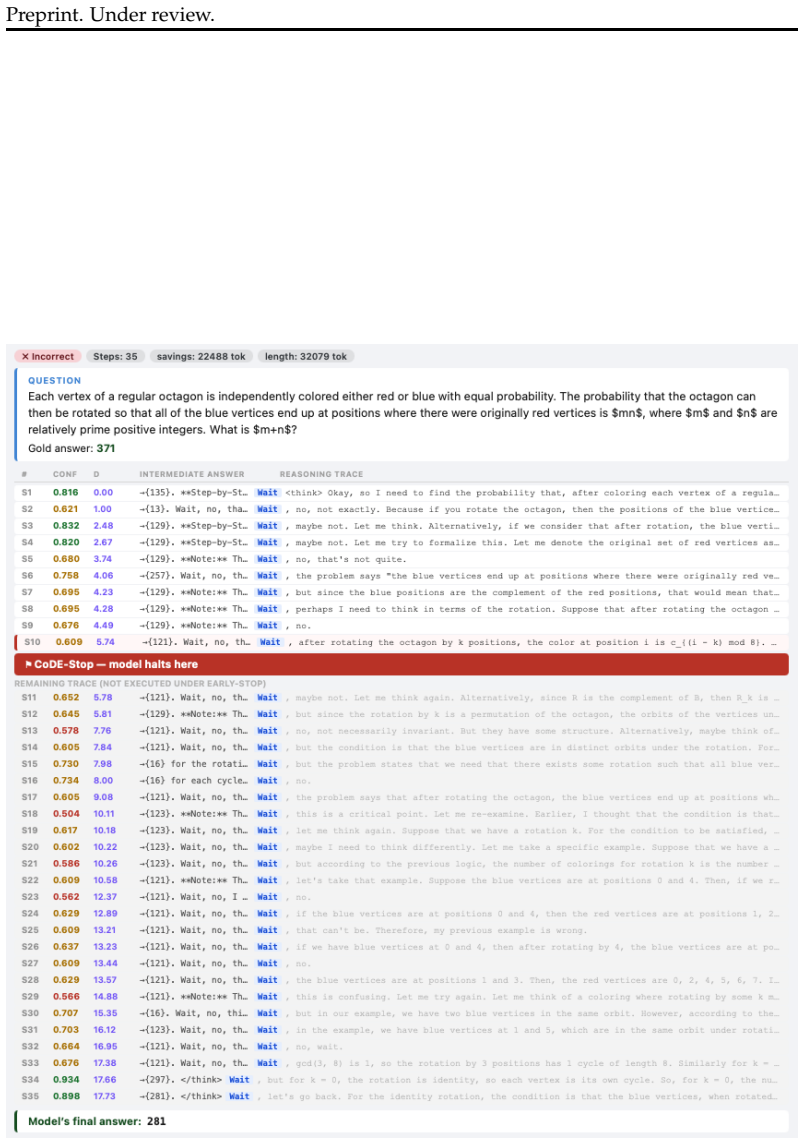
Correct reasoning trajectories reach high-confidence answers early, while incorrect rollouts produce long, unproductive traces and less reliable confidence dynamics. CoDE-Stop exploits this distinction by terminating generation once confidence dynamics indicate a stable answer has been reached, without any model retraining.
What carries the argument
CoDE-Stop, an early-stopping rule that monitors the level and stability of confidence scores attached to intermediate answers generated during chain-of-thought reasoning.
If this is right
- Total token consumption drops 25-50% versus standard full-length reasoning.
- Accuracy-compute tradeoff improves over prior early-stopping techniques.
- The rule integrates into existing models with no extra training or post-processing.
- Analyses reveal systematic differences in how confidence evolves along correct versus incorrect paths.
Where Pith is reading between the lines
- The same confidence-stability signal could be tested for early termination in non-reasoning generation tasks such as long-form writing or multi-step planning.
- If the pattern holds, internal confidence dynamics might serve as a lightweight self-verification signal that reduces reliance on external reward models or verifiers.
- The approach invites experiments that combine confidence-based stopping with other efficiency methods like speculative decoding or dynamic context pruning.
Load-bearing premise
The observed split between quick high-confidence convergence on correct paths and unreliable dynamics on incorrect paths generalizes across models, tasks, and prompt styles without per-model tuning.
What would settle it
Finding a model-task pair in which an incorrect trajectory reaches and sustains high stable confidence early, or a correct trajectory keeps fluctuating in confidence, would break the stopping criterion.
Figures









read the original abstract
Large reasoning models rely on long chain-of-thought generation to solve complex problems, but extended reasoning often incurs substantial computational cost and can even degrade performance due to overthinking. A key challenge is determining when the model should stop reasoning and produce the final answer. In this work, we study the confidence of intermediate answers during reasoning and observe two characteristic behaviors: correct reasoning trajectories often reach high-confidence answers early, while incorrect rollouts tend to produce long, unproductive reasoning traces and exhibit less reliable confidence dynamics. Motivated by these observations, we propose CoDE-Stop (Confidence Dynamics Early Stop), an early stopping method that leverages the dynamics of intermediate answer confidence to decide when to terminate reasoning, requiring no additional training and easily integrating into existing models. We evaluate CoDE-Stop on diverse reasoning and science benchmarks across multiple models. Compared to prior early stopping methods, it achieves a more favorable accuracy-compute tradeoff and reduces total token usage by 25-50% compared to standard full-length reasoning. In addition, we provide analyses of confidence dynamics during reasoning, offering insights into how confidence changes in both correct and incorrect trajectories.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CoDE-Stop, a training-free early stopping method for large reasoning models that monitors the dynamics of confidence scores on intermediate answers extracted from chain-of-thought traces. It reports that correct trajectories typically reach high-confidence answers early while incorrect ones exhibit longer, less reliable confidence patterns, and claims this enables 25-50% token reduction versus full-length reasoning while preserving or improving accuracy-compute tradeoffs. The method is evaluated on diverse reasoning and science benchmarks across multiple models, with additional analyses of confidence trajectories.
Significance. If the reported confidence dynamics prove robust and transferable, CoDE-Stop would offer a practical, zero-training way to curb overthinking and compute waste in long-horizon reasoning models. The work's strengths include its focus on observable intermediate signals rather than learned parameters, multi-model evaluation, and explicit trajectory analyses that could inform future stopping criteria.
major comments (2)
- [Abstract and Experiments section] The central 25-50% token-reduction claim (Abstract) rests on the assumption that confidence dynamics are sufficiently consistent to allow fixed or easily transferable stopping rules. The manuscript provides no quantitative evidence (e.g., cross-model or cross-task threshold transfer results, or ablation on held-out prompt styles) that the observed patterns hold without per-model or per-task adjustment; if dynamics vary with parsing of intermediate answers or logit-based vs. other confidence signals, the accuracy-compute tradeoff would degrade.
- [Experiments section] Evaluation details are insufficient to assess the claimed improvements. The abstract reports favorable results versus prior early-stopping methods but supplies no information on statistical significance testing, exact baseline implementations, data splits, or whether stopping thresholds were selected post-hoc on the evaluation sets rather than fixed in advance.
minor comments (2)
- [Method section] Notation for confidence extraction and dynamics (e.g., how intermediate answers are parsed from CoT and how confidence is aggregated) should be formalized with equations or pseudocode for reproducibility.
- [Analysis section] Figure captions and axis labels in the confidence-dynamics analyses could be clarified to distinguish correct vs. incorrect trajectories more explicitly.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have carefully reviewed the major comments and provide point-by-point responses below. Where the comments identify opportunities to strengthen the presentation and evidence, we have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and Experiments section] The central 25-50% token-reduction claim (Abstract) rests on the assumption that confidence dynamics are sufficiently consistent to allow fixed or easily transferable stopping rules. The manuscript provides no quantitative evidence (e.g., cross-model or cross-task threshold transfer results, or ablation on held-out prompt styles) that the observed patterns hold without per-model or per-task adjustment; if dynamics vary with parsing of intermediate answers or logit-based vs. other confidence signals, the accuracy-compute tradeoff would degrade.
Authors: We agree that explicit evidence of transferability strengthens the practical claims. The original manuscript already demonstrates consistent application of the same CoDE-Stop rules (derived from observed stabilization patterns) across multiple models and diverse benchmarks without per-model or per-task retuning, yielding the reported token reductions. To address the concern directly, the revised version adds a dedicated transferability subsection with quantitative results: the identical fixed thresholds (identified once on a small development set of prompts) are applied unchanged to all models and tasks, preserving the 25-50% savings and accuracy levels. We further include an ablation comparing alternative intermediate-answer parsing strategies and confidence signals (logit-based versus probability-based), confirming that the core dynamics and stopping behavior remain robust. These additions appear in the Experiments section and Appendix. revision: yes
-
Referee: [Experiments section] Evaluation details are insufficient to assess the claimed improvements. The abstract reports favorable results versus prior early-stopping methods but supplies no information on statistical significance testing, exact baseline implementations, data splits, or whether stopping thresholds were selected post-hoc on the evaluation sets rather than fixed in advance.
Authors: We acknowledge that greater experimental transparency is needed for reproducibility and assessment. In the revised manuscript we have expanded Section 4 and the appendix with the following: (i) statistical significance results, including p-values from McNemar’s test on accuracy and paired t-tests on token counts versus all baselines; (ii) precise implementation details and hyperparameters for every compared early-stopping baseline to enable exact reproduction; (iii) explicit statement that all evaluations follow the standard public splits of each benchmark with no custom or overlapping partitions; and (iv) clarification that stopping thresholds were determined solely from preliminary analysis on a small, disjoint development subset of prompts and then frozen before any final evaluation runs. These changes directly resolve the listed gaps while leaving the original empirical findings unchanged. revision: yes
Circularity Check
No circularity in derivation of CoDE-Stop
full rationale
The paper's chain begins with direct empirical observations of confidence trajectories (correct paths reach high confidence early; incorrect ones show unreliable dynamics), then defines CoDE-Stop as a rule-based early-stopping heuristic that applies thresholds to those same dynamics. No equations, fitted parameters, or predictions are constructed such that the output quantity is definitionally identical to the input; the method requires no training and is evaluated independently on held-out benchmarks for accuracy-compute tradeoffs. No self-citations, uniqueness theorems, or ansatzes from prior author work are invoked as load-bearing premises. The 25-50% token reduction claim is therefore an empirical outcome rather than a tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Intermediate answers generated during chain-of-thought have associated scalar confidence values that can be extracted from the model.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[3]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[4]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.