Recognition: unknown
DIVERSED: Relaxed Speculative Decoding via Dynamic Ensemble Verification
Pith reviewed 2026-05-10 17:12 UTC · model grok-4.3
The pith
A dynamic ensemble verifier relaxes the exact-match rule in speculative decoding so more draft tokens get accepted while output quality stays the same.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that replacing strict verification with a dynamic ensemble that blends draft-model and target-model next-token distributions via learned, task- and context-dependent weights raises the token acceptance rate and therefore the overall speedup while leaving generation quality unchanged. The authors prove that the blended distribution remains sufficiently close to the target to avoid measurable quality loss and validate the claim with experiments on standard language-model benchmarks.
What carries the argument
Dynamic ensemble verifier that computes a context- and task-dependent weighted average of the draft and target next-token probability distributions during the verification step.
If this is right
- Higher acceptance rates produce measurably higher tokens generated per unit time.
- Quality metrics such as perplexity and human preference scores remain comparable to the unrelaxed baseline.
- The framework applies to any pair of draft and target models without requiring architectural changes.
- Theoretical bounds on distribution shift give a principled limit on how far the weights can deviate from the target.
Where Pith is reading between the lines
- The same blending idea could be tested in other acceleration settings that rely on strict verification, such as tree-based or block-wise decoding.
- In latency-sensitive deployments the reduced rejection rate would directly lower response time for interactive users.
- Making the weight predictor itself run in a single forward pass without extra parameters would further simplify integration.
- The approach suggests that other strict-matching steps in sampling pipelines might also be safely relaxed with learned ensembles.
Load-bearing premise
That a learned blend of the two distributions will not shift the overall output distribution enough to degrade generation quality.
What would settle it
If side-by-side runs on the same models and datasets show that DIVERSED produces text whose perplexity or downstream-task accuracy falls below the standard speculative-decoding baseline, the claim would be falsified.
Figures









read the original abstract
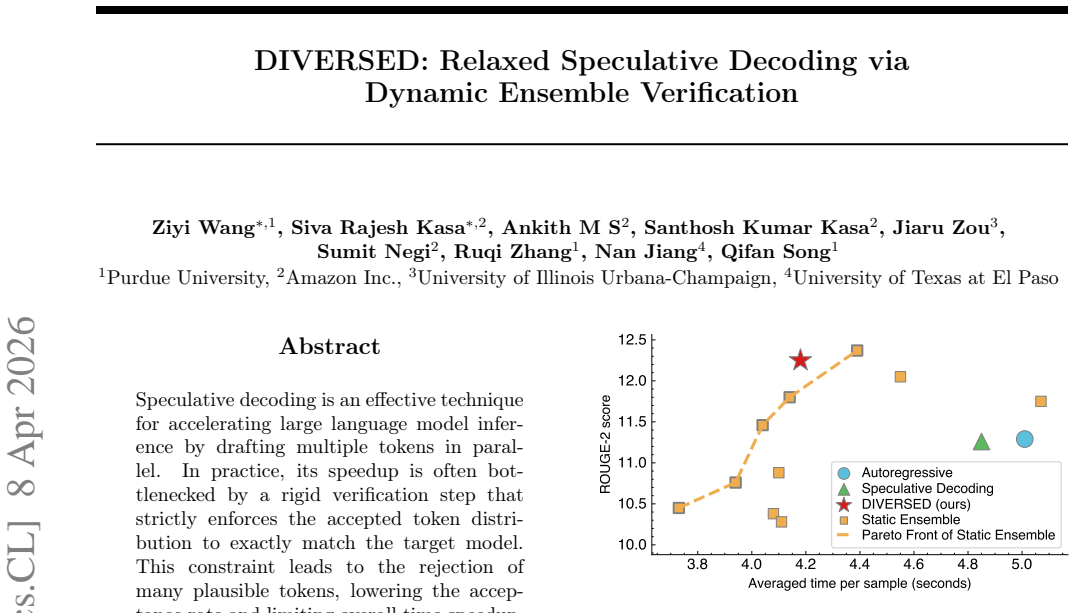
Speculative decoding is an effective technique for accelerating large language model inference by drafting multiple tokens in parallel. In practice, its speedup is often bottlenecked by a rigid verification step that strictly enforces the accepted token distribution to exactly match the target model. This constraint leads to the rejection of many plausible tokens, lowering the acceptance rate and limiting overall time speedup. To overcome this limitation, we propose Dynamic Verification Relaxed Speculative Decoding (DIVERSED), a relaxed verification framework that improves time efficiency while preserving generation quality. DIVERSED learns an ensemble-based verifier that blends the draft and target model distributions with a task-dependent and context-dependent weight. We provide theoretical justification for our approach and demonstrate empirically that DIVERSED achieves substantially higher inference efficiency compared to standard speculative decoding methods. Code is available at: https://github.com/comeusr/diversed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DIVERSED, a relaxed speculative decoding method for LLM inference acceleration. It replaces the rigid verification step (which enforces exact matching to the target distribution) with a dynamic ensemble verifier that blends the draft and target model distributions via a learned task- and context-dependent scalar weight. The authors claim this yields higher acceptance rates and time speedup while preserving generation quality, supported by theoretical justification and empirical results. Code is released at a public GitHub repository.
Significance. If the blending mechanism can be shown to preserve output quality without measurable distributional drift, the method would address a core limitation of standard speculative decoding and enable meaningfully faster inference for large models. The public code release is a positive factor for reproducibility. However, the significance is tempered by the absence of explicit divergence bounds or detailed quality metrics in the core claims.
major comments (3)
- [Theoretical Justification] The theoretical justification for the dynamic ensemble verifier does not derive or cite bounds on distributional divergence (e.g., total variation distance or KL divergence) between the blended distribution and the pure target distribution. Without such a bound, the claim that generation quality is preserved cannot be rigorously assessed, especially for long sequences where small per-step shifts may accumulate.
- [Method] The learning procedure for the task- and context-dependent blending weight is presented only at a high level. It is unclear whether the weight is optimized under an objective that controls for generalization or whether it is fitted on data that overlaps with evaluation, which risks the efficiency gain reducing to a reparameterization of the acceptance criterion rather than a true relaxation.
- [Experiments] Empirical claims of 'substantially higher inference efficiency' and quality preservation lack concrete numbers (acceptance rates, wall-clock speedups, perplexity or downstream metrics) and ablations on the dynamic weighting component. This makes it impossible to verify that the observed gains exceed those of simpler relaxed baselines.
minor comments (2)
- [Abstract] The abstract would be strengthened by including at least one quantitative result (e.g., acceptance-rate improvement or speedup factor) alongside the qualitative claims.
- [Notation and Method] Notation for the blending weight, draft distribution, and target distribution should be introduced once and used consistently; currently the high-level description leaves the exact functional form of the ensemble ambiguous.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify the presentation of our theoretical and empirical contributions. We address each major comment below and indicate the revisions planned for the manuscript.
read point-by-point responses
-
Referee: [Theoretical Justification] The theoretical justification for the dynamic ensemble verifier does not derive or cite bounds on distributional divergence (e.g., total variation distance or KL divergence) between the blended distribution and the pure target distribution. Without such a bound, the claim that generation quality is preserved cannot be rigorously assessed, especially for long sequences where small per-step shifts may accumulate.
Authors: We appreciate the referee's emphasis on rigorous distributional analysis. Our current theoretical justification shows that the dynamic blending preserves the target distribution in expectation and increases acceptance probability without introducing systematic bias, but we acknowledge the absence of explicit per-step divergence bounds such as total variation or KL. In the revised manuscript, we will add a dedicated subsection deriving a simple bound on the total variation distance between the blended and target distributions and include a discussion of error accumulation over long sequences, supported by additional experiments measuring quality degradation as a function of sequence length. revision: yes
-
Referee: [Method] The learning procedure for the task- and context-dependent blending weight is presented only at a high level. It is unclear whether the weight is optimized under an objective that controls for generalization or whether it is fitted on data that overlaps with evaluation, which risks the efficiency gain reducing to a reparameterization of the acceptance criterion rather than a true relaxation.
Authors: The blending weight is optimized on a held-out validation set that is disjoint from all evaluation benchmarks, using an objective that maximizes expected acceptance rate subject to a KL-divergence regularization term toward the target model. This ensures the relaxation is not merely a reparameterization. We will revise the method section to include the full training objective, pseudocode for the optimization procedure, and explicit details on the data partitioning to demonstrate generalization and rule out overlap with evaluation data. revision: yes
-
Referee: [Experiments] Empirical claims of 'substantially higher inference efficiency' and quality preservation lack concrete numbers (acceptance rates, wall-clock speedups, perplexity or downstream metrics) and ablations on the dynamic weighting component. This makes it impossible to verify that the observed gains exceed those of simpler relaxed baselines.
Authors: We agree that the main text would benefit from more explicit quantitative reporting and component ablations. In the revision, we will move key experimental results (acceptance rates, wall-clock speedups, perplexity, and downstream task metrics) into the main body, add a dedicated ablation study isolating the dynamic weighting component, and include direct comparisons against simpler static relaxed baselines to substantiate the efficiency claims. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces DIVERSED as a new relaxed verification framework that learns task- and context-dependent blending weights between draft and target distributions, states that theoretical justification is provided, and reports empirical efficiency gains while claiming quality preservation. No equations, acceptance criteria, or derivation steps are exhibited that reduce the central claims (efficiency improvement or quality preservation) to a fitted parameter by construction, a self-citation chain, or a renaming of inputs. The learning procedure is presented as an integral part of the proposed method rather than a hidden tautology, and the empirical demonstration stands as independent validation outside any definitional loop. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- task- and context-dependent blending weight
axioms (1)
- domain assumption The ensemble-blended distribution preserves the target model's generation quality
invented entities (1)
-
Dynamic ensemble verifier
no independent evidence
Reference graph
Works this paper leans on
-
[1]
[Yes] (b) An analysis of the properties and complexity (time, space, sample size) of any algorithm
For all models and algorithms presented, check if you include: (a) A clear description of the mathematical set- ting, assumptions, algorithm, and/or model. [Yes] (b) An analysis of the properties and complexity (time, space, sample size) of any algorithm. [Yes] (c) (Optional) Anonymized source code, with specification of all dependencies, including extern...
-
[2]
[Yes] (b) Complete proofs of all theoretical results
For any theoretical claim, check if you include: (a) Statements of the full set of assumptions of all theoretical results. [Yes] (b) Complete proofs of all theoretical results. [Yes] (c) Clear explanations of any assumptions. [Yes]
-
[3]
[Yes] (b) All the training details (e.g., data splits, hy- perparameters, how they were chosen)
For all figures and tables that present empirical results, check if you include: (a) The code, data, and instructions needed to reproduce the main experimental results (ei- ther in the supplemental material or as a URL). [Yes] (b) All the training details (e.g., data splits, hy- perparameters, how they were chosen). [Yes] (c) A clear definition of the spe...
-
[4]
[Yes] (b) The license information of the assets, if ap- plicable
If you are using existing assets (e.g., code, data, models) or curating/releasing new assets, check if you include: (a) Citations of the creator If your work uses ex- isting assets. [Yes] (b) The license information of the assets, if ap- plicable. [Yes] (c) New assets either in the supplemental mate- rial or as a URL, if applicable. [No] (d) Information a...
-
[5]
NX t=1 tY i=1 min 1, p(xi |x 0:i−1) q(xi |x 0:i−1) # q(x1:N ) = X x1:N
If you used crowdsourcing or conducted research with human subjects, check if you include: (a) The full text of instructions given to partici- pants and screenshots. [Not Applicable] (b) Descriptions of potential participant risks, with links to Institutional Review Board (IRB) approvals if applicable. [Not Appli- cable] (c) The estimated hourly wage paid...
2004
-
[6]
Obama’s trip to Florida on Air Force One used 9,000 gallons of fuel, which he acknowledges, but the White House defends it as part of the effort to reduce emissions
-
[7]
Obama urges Americans to take environmentally-conscious actions to save the Everglades and other natural gems. SD 1. President Obama highlights Florida Everglades as proof of climate change impact
-
[8]
Obama criticizes climate change as a current issue, not a future threat
-
[9]
SD (Lossy) 1
White House defends gas-guzzling trip to Florida for Earth Day, linking it to efforts to reduce pollutants. SD (Lossy) 1. President Obama highlights shrinking Florida Everglades as proof climate change is real and threatening national treasures and local economies
-
[10]
Obama’s trip to Florida, which required 9,000 gallons of fuel for Air Force One, drew criticism over its environmental impact
-
[11]
Obama emphasizes that climate change is a current issue with serious implications, not a problem for future generations
-
[12]
Obama’s administration is committed to leading the world in combating climate change through reducing carbon emissions
-
[13]
SpecCascade 1
Obama’s Earth Day visit to the Everglades was meant to inspire environmentally-conscious decisions to protect natural treasures. SpecCascade 1. President Obama highlights climate change as a threat to the Everglades and national treasures
-
[14]
The president says climate change is not a problem for another generation
-
[15]
Obama’s trip to Florida was criticized for being gas-guzzling, but the White House said it would not undermine his Earth Day message
-
[16]
The White House said that climate change is affecting iconic places like the Everglades and Glacier National Park
-
[17]
Static Ensemble 1) President Barack Obama visits Florida Everglades as part of Earth Day message
Obama emphasizes the need for action to protect natural monuments as a birthright for future generations. Static Ensemble 1) President Barack Obama visits Florida Everglades as part of Earth Day message
-
[18]
Obama and Bill Nye ’the Science Guy’ on trip
-
[19]
Obama addresses climate change as a threat to national treasures and economies
-
[20]
Obama mentions the impact of climate change on the Everglades and surrounding towns
-
[21]
Diversed1
Obama emphasizes the need to take action on climate change. Diversed1. President Obama highlights Florida Everglades as proof of climate change’s real and threatening impact
-
[22]
to lead in combatting climate change and reducing carbon emissions
Obama commits U.S. to lead in combatting climate change and reducing carbon emissions
-
[23]
DIVERSED: Relaxed Speculative Decoding via Dynamic Ensemble Verification Case Study on the CNNDM dataset using Gemma model
Obama’s trip to Florida, accompanied by Bill Nye ’the Science Guy,’ was seen as a challenge to his Earth Day message. DIVERSED: Relaxed Speculative Decoding via Dynamic Ensemble Verification Case Study on the CNNDM dataset using Gemma model. News: President Barack Obama held up the shrinking Florida Everglades today as proof positive that climate change i...
-
[24]
Obama’s trip to Florida included a walking tour of the Everglades and a speech on Earth Day
-
[25]
The trip highlighted the administration’s efforts to reduce carbon emissions
-
[26]
Obama’s gas-guzzling trip to Florida was criticized, but the White House defended it
-
[27]
Obama uses Everglades as proof of climate change’s impact
Obama emphasized the urgency of addressing climate change and its impact on communi- ties." Diversed1. Obama uses Everglades as proof of climate change’s impact
-
[28]
Trip highlights shrinking Everglades and economic impact on surrounding towns
-
[29]
Obama’s Air Force One trip uses 9,000 gallons of fuel, raising questions about hypocrisy
-
[30]
Bill Nye ’the Science Guy’ accompanies Obama
-
[31]
Obama emphasizes the urgency of addressing climate change and its impact on future generations." DIVERSED: Relaxed Speculative Decoding via Dynamic Ensemble Verification C.5 XSum Case Study Case Study on the XSum dataset using Llama model. Gao Yu, 71, was found guilty last April and challenged her conviction at a closed hearing in Beijing on Thurs- day.Th...
1989
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.