Mitigating Distribution Sharpening in Math RLVR via Distribution-Aligned Hint Synthesis and Backward Hint Annealing
Pith reviewed 2026-05-10 17:48 UTC · model grok-4.3
The pith
Distribution-aligned hint synthesis and backward annealing improve both pass@1 and pass@2048 on AIME math benchmarks in RLVR.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
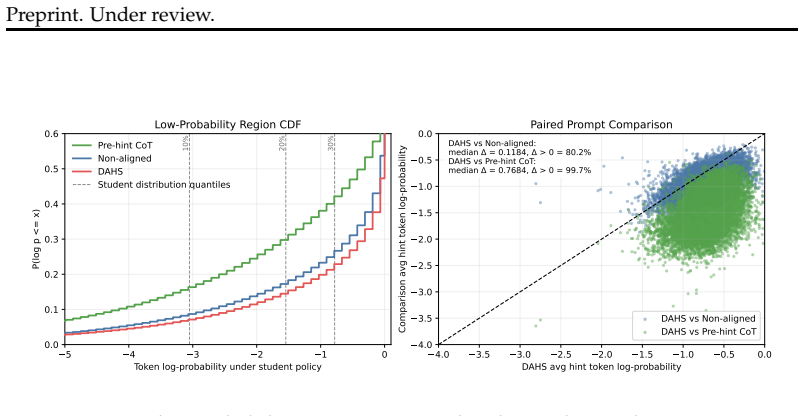
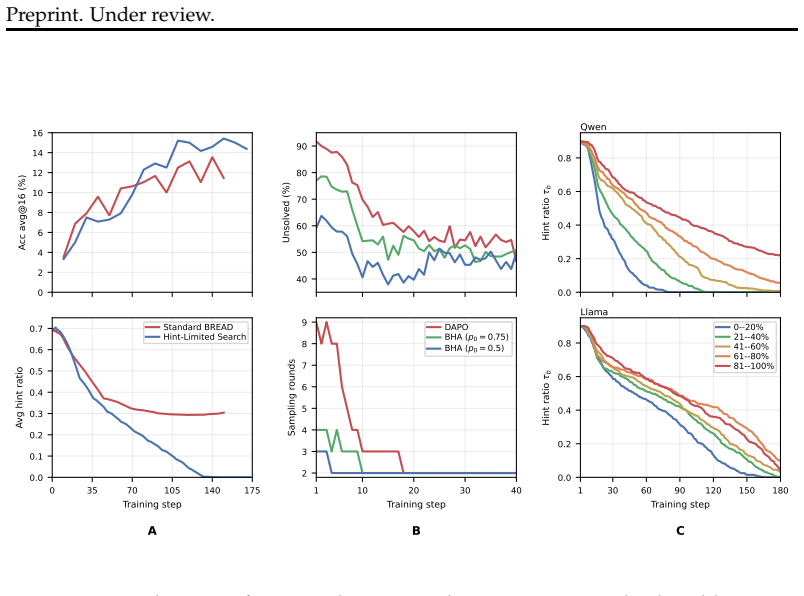
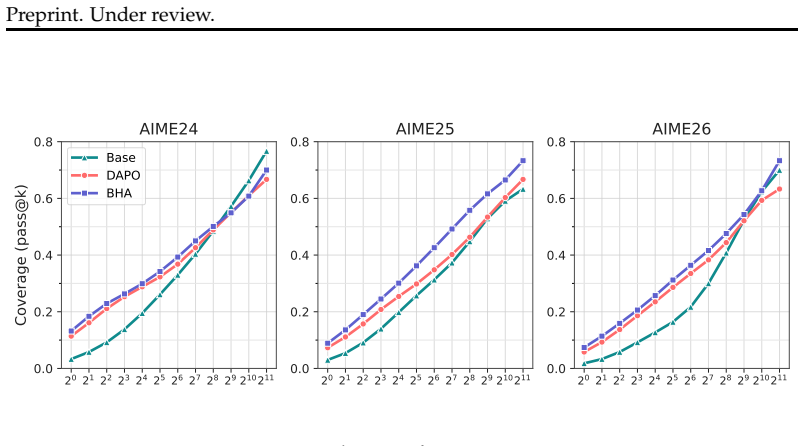
The authors claim that constructing verified teacher hints conditioned on student-style responses via DAHS and annealing hint exposure across difficulty buckets with per-question hint dropout via BHA addresses distribution mismatch and excessive hint exposure. This leads to better performance in both pass@1 and pass@2048 relative to DAPO on Qwen3-1.7B-Base across AIME24, AIME25, and AIME26, with the gains on Llama-3.2-1B-Instruct focused on the large-k regime. The results indicate that hint scaffolding works when it restores learnable updates on challenging questions early and is removed before no-hint evaluation.
What carries the argument
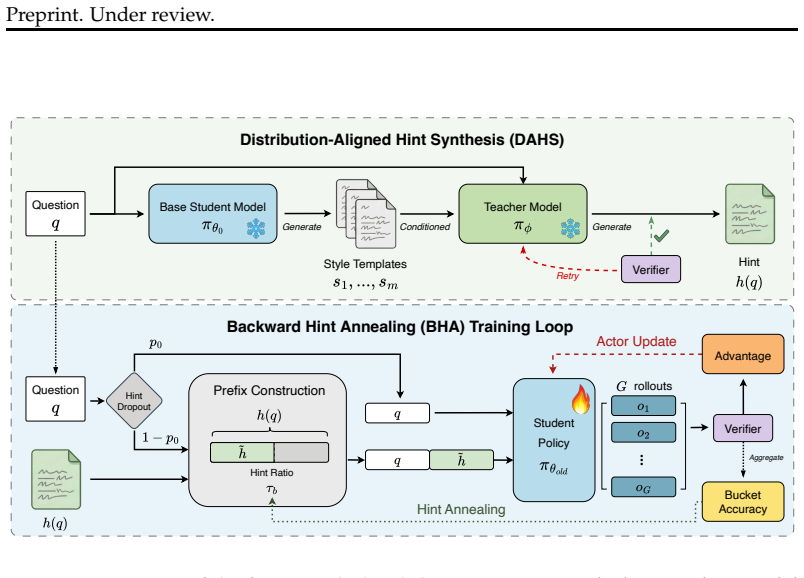
Distribution-Aligned Hint Synthesis (DAHS) that generates verified hints matching the student's response distribution and Backward Hint Annealing (BHA) that gradually reduces hint exposure over training while using dropout to keep some no-hint updates.
If this is right
- Both low-k accuracy and large-k solution coverage can be improved together in math RLVR.
- Hint-based methods require alignment to the student model and scheduled removal to avoid harming no-hint performance.
- Per-question hint dropout preserves learning signals throughout training.
- The approach shows consistent results on two different models and three recent AIME benchmarks.
Where Pith is reading between the lines
- Similar techniques could help in other domains like coding where RLVR is used and solution diversity is valuable.
- Distribution mismatch may be a general issue in teacher-student RL setups beyond math.
- Testing the method on more diverse math problems or longer training could reveal limits on generalization.
- Backward annealing might be adapted for other scaffolding methods in LLM training.
Load-bearing premise
That the distribution-aligned hints and backward annealing schedule restore learnable updates on hard questions without introducing new biases or limiting exploration in ways that harm generalization beyond the tested AIME benchmarks.
What would settle it
If applying the method to a new set of math problems outside AIME or to a different model size shows no gain in pass@2048 or a drop compared to the baseline, this would indicate the improvements do not generalize.
Figures
read the original abstract
Reinforcement learning with verifiable rewards (RLVR) can improve low-$k$ reasoning accuracy while narrowing solution coverage on challenging math questions, and pass@1 gains do not necessarily translate into better large-$k$ performance. Existing hint-based approaches can make challenging questions trainable, but they leave two issues underexplored: teacher-student distribution mismatch and the need to reduce hint exposure to match no-hint evaluation. We address these issues through two components. Distribution-Aligned Hint Synthesis (DAHS) constructs verified teacher hints conditioned on student-style responses. Backward Hint Annealing (BHA) anneals hint exposure across difficulty buckets and uses per-question hint dropout to preserve no-hint updates throughout RL training. We evaluate the method in math RLVR under the DAPO training framework across AIME24, AIME25, and AIME26 using $\texttt{Qwen3-1.7B-Base}$ and $\texttt{Llama-3.2-1B-Instruct}$. On $\texttt{Qwen3-1.7B-Base}$, our method improves both pass@1 and pass@2048 relative to DAPO across the three AIME benchmarks. On $\texttt{Llama-3.2-1B-Instruct}$, the gains are concentrated in the large-$k$ regime. These results suggest that, in math RLVR, hint scaffolding is effective when it restores learnable updates on challenging questions early in training and is then gradually removed before no-hint evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Distribution-Aligned Hint Synthesis (DAHS) to generate verified teacher hints conditioned on student-style responses and Backward Hint Annealing (BHA) that anneals hint exposure across difficulty buckets with per-question dropout. These are applied within the DAPO RLVR framework on math problems. The central empirical claim is that the combined method improves both pass@1 and pass@2048 over DAPO on AIME24/25/26 for Qwen3-1.7B-Base, with large-k gains for Llama-3.2-1B-Instruct, by restoring learnable updates on hard questions while preserving no-hint evaluation behavior.
Significance. If the results hold with proper verification, the work provides a concrete mechanism for using hints in RLVR without permanently narrowing solution distributions, addressing a key limitation where pass@1 gains fail to improve large-k coverage on challenging math problems. The emphasis on distribution alignment and gradual hint removal is a useful practical contribution for scaling RL to harder reasoning tasks.
major comments (2)
- [§3.2] §3.2 (BHA description): The claim that BHA 'preserves no-hint updates throughout RL training' is load-bearing for the pass@2048 improvements, yet the manuscript reports neither the fraction of hint-free updates per epoch nor the KL divergence between hinted and unhinted rollouts at convergence. Without these, residual distribution shift from early hint-conditioned gradients cannot be ruled out as an explanation for the reported large-k gains.
- [Experiments] Experiments section (results tables): The abstract asserts consistent improvements across AIME24/25/26 for Qwen3-1.7B-Base, but no details are provided on the number of independent runs, statistical significance tests, variance across seeds, or full hyperparameter sweeps for DAPO baselines. This undermines assessment of whether the pass@1 and pass@2048 deltas are robust.
minor comments (2)
- [§3.2] Notation for difficulty buckets in BHA should be defined explicitly with an equation or pseudocode to clarify how annealing boundaries are set.
- [Results] The abstract mentions 'three AIME benchmarks' but the full results tables should include per-benchmark breakdowns with exact pass@k values for both models to allow direct comparison.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the presentation of our contributions. We address each major point below and indicate revisions to be made in the next version of the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (BHA description): The claim that BHA 'preserves no-hint updates throughout RL training' is load-bearing for the pass@2048 improvements, yet the manuscript reports neither the fraction of hint-free updates per epoch nor the KL divergence between hinted and unhinted rollouts at convergence. Without these, residual distribution shift from early hint-conditioned gradients cannot be ruled out as an explanation for the reported large-k gains.
Authors: We agree that explicit quantification strengthens the claim. BHA applies per-question hint dropout at every training step, ensuring that a non-zero fraction of updates on each question remain hint-free; this design is described in §3.2. To address the concern directly, we will add (i) a plot and table reporting the average fraction of hint-free updates per epoch and (ii) the KL divergence between hinted and unhinted rollouts measured at convergence. These additions will appear in a revised §3.2 and the associated appendix. revision: yes
-
Referee: [Experiments] Experiments section (results tables): The abstract asserts consistent improvements across AIME24/25/26 for Qwen3-1.7B-Base, but no details are provided on the number of independent runs, statistical significance tests, variance across seeds, or full hyperparameter sweeps for DAPO baselines. This undermines assessment of whether the pass@1 and pass@2048 deltas are robust.
Authors: We acknowledge the value of statistical rigor. The experiments were conducted with three independent random seeds; we will report mean and standard deviation for all pass@1 and pass@2048 metrics and include paired t-test p-values for the deltas versus DAPO. Hyperparameters for the DAPO baseline follow the original DAPO paper with only minor adjustments for the 1B-scale models; we will list the exact values and note that a limited sensitivity study (varying learning rate and KL coefficient) was performed. A full grid search over all DAPO hyperparameters is computationally prohibitive at this scale, but the added statistics and baseline details will be incorporated into the Experiments section and a new appendix table. revision: partial
Circularity Check
No circularity: purely empirical RLVR method with independent experimental validation
full rationale
The paper describes an empirical training procedure (DAHS for hint synthesis and BHA for annealing/dropout) evaluated via pass@1 and pass@2048 on AIME benchmarks under the DAPO framework. No mathematical derivations, fitted parameters renamed as predictions, or self-citation chains are present. All load-bearing claims rest on reported training runs and benchmark scores rather than any reduction to inputs by construction. The approach is self-contained against external benchmarks with no evidence of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
URLhttps://arxiv.org/abs/2107.03374. Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021. Zhihao Dou, Qinjian Zhao, Zhongwei Wan, Dingg...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Select the Base Template:Review the provided student solutions. Choose the one that has the clearest structure and most natural flow (even if the numbers or logic are incorrect). This solution will serve as your “Base Template.”
-
[3]
Correct & Refine:Rewrite the Base Template to be mathematically perfect. • Mimicry:Keep the chosen student’s unique writing style, for- matting choices (bullet points, spacing, notation variables), and voice. • Surgical Editing:When correcting an error, change the mini- mum amount of text necessary. If a number is wrong, change only the number. If a formu...
-
[4]
No Meta-Commentary:Do not mention which student solution you picked. Do not say “fixing error” or “Student 2 wrote.” Just present the final math. 3.Rigorous Logic:The mathematical path must be flawless
-
[5]
+” actually carries out some operationop +. • The button labelled “×
Final Answer:End with the exact label “Answer:” and put the final resulton the same line immediately afterit. # Input Format Math Problem: {question} Student Solutions: {LIST OF STUDENT SOLUTIONS} # Output Format [Output only the corrected solution text here] Answer: [FINAL VALUE] 24 Preprint. Under review. D.4 Example Training Instance Below we present o...
-
[6]
Perform the multiplication: 4×3=12
-
[7]
Perform the division: 12÷2=6
-
[8]
+” key is pressed, f× =operation performed when the “×
Perform the addition: 6+1=7. Therefore 4+3×2÷1=7 on this calculator. Answer: 7 Non-aligned Hint The three keys +, ×, ÷ each now perform a different one of the three opera- tions addition(+), multiplication(×), and division(÷). Let f+ =operation performed when the “+” key is pressed, f× =operation performed when the “×” key is pressed, f÷ =operation perfor...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.